Variational Relational Point Completion Network 阅读笔记
Variational Relational Point Completion Network
Abstract 摘要
Real-scanned point clouds are often incomplete due to viewpoint, occlusion, and noise. Existing point cloud completion methods tend to generate global shape skeletons and hence lack fine local details. Furthermore, they mostly learn a deterministic partial-to-complete mapping, but overlook structural relations in man-made objects. To tackle these challenges, this paper proposes a variational framework, Variational Relational point Completion network (VRCNet) with two appealing properties: 1) Probabilistic Modeling. In particular, we propose a dual-path architecture to enable principled probabilistic modeling across partial and complete clouds. One path consumes complete point clouds for reconstruction by learning a point VAE. The other path generates complete shapes for partial point clouds, whose embedded distribution is guided by distribution obtained from the reconstruction path during training. 2) Relational Enhancement. Specifically, we carefully design point selfattention kernel and point selective kernel module to exploit relational point features, which refines local shape details conditioned on the coarse completion. In addition, we contribute a multi-view partial point cloud dataset (MVP dataset) containing over 100,000 high-quality scans, which renders partial 3D shapes from 26 uniformly distributed camera poses for each 3D CAD model. Extensive experiments demonstrate that VRCNet outperforms state-of-theart methods on all standard point cloud completion benchmarks. Notably, VRCNet shows great generalizability and
robustness on real-world point cloud scans.
由于视点、遮挡和噪声,实际扫描的点云通常是不完整的。现有的点云完成方法倾向于生成全局形状骨架,因此缺乏精细的局部细节。此外,他们大多学习确定性部分到完全映射,但忽略了人造对象中的结构关系。为了应对这些挑战,本文提出了一种变分框架——变分关系点云完成网络(VRCNet),它具有两个吸引人的特性:1)概率建模。特别是,我们提出了一种双路径体系结构,以支持跨部分云和完整云的原则性概率建模。一条路径通过学习点云来消耗完整的点云进行重建。另一条路径生成部分点云的完整形状,其嵌入分布由训练期间从重建路径获得的分布引导。2) 关系增强。具体地说,我们精心设计了点自关注核和点选择核模块,利用关系点特征,在粗补全的基础上细化局部形状细节。此外,我们还提供了一个多视角部分点云数据集(MVP数据集),其中包含100000多个高质量扫描,可为每个3D CAD模型渲染26个均匀分布的摄影机姿势的部分3D形状。大量实验表明,VRCNet在所有标准点云完成基准上都优于现有方法。值得注意的是,VRCNet在现实世界的点云扫描中表现出很强的通用性和鲁棒性。
1、Introduction 介绍
3D point cloud is an intuitive representation of 3D scenes and objects, which has extensive applications in various vision and robotics tasks. Unfortunately, scanned 3D point clouds are usually incomplete owing to occlusions and missing measurements, hampering practical usages. Therefore, it is desirable and important to predict the complete 3D shape from a partially observed point cloud.
三维点云是三维场景和对象的直观表示,在各种视觉和机器人任务中有着广泛的应用。不幸的是,由于遮挡和测量缺失,扫描的三维点云通常是不完整的,妨碍了实际应用。因此,从部分观测到的点云预测完整的三维形状是可取且重要的。
The pioneering work PCN [30] uses PointNet-based encoder to generate global features for shape completion,which cannot recover fine geometric details. The followup works [14, 23, 15, 28] provide better completion results by preserving observed geometric details from the incomplete point shape using local features. However,
they [30, 14, 23, 15, 28] mostly generate complete shapes by learning a deterministic partial-to-complete mapping, lacking the conditional generative capability based on the partial observation. Furthermore, 3D shape completion is expected to recover plausible yet fine-grained complete shapes by learning relational structure properties, such as geometrical symmetries, regular arrangements and surface smoothness, which existing methods fail to capture.
PCN[30]的开创性工作使用基于PointNet的编码器生成全局特征用于形状完成,但是无法恢复精细的几何细节。后续工作[14、23、15、28]通过使用局部特征保留不完整点形状的观测几何细节,提供了更好的完成效果。然而,他们[30,14,23,15,28]大多通过学习确定性的部分到完整映射来生成完整形状,缺乏基于部分观察的条件生成能力。此外,通过学习现有方法无法捕捉的几何对称性、规则排列和表面平滑度等相关结构特性,3D形状完成有望恢复看似合理但细粒度的完整形状。
To this end, we propose Variational Relational Point Completion network (entitled as VRCNet), which consists of two consecutive encoder-decoder sub-networks that serve as “probabilistic modeling” (PMNet) and “relational enhancement” (RENet), respectively (shown in Fig. 1 (a)).
为此,我们提出了变分关系点云完成网络(称为VRCNet),该网络由两个连续的编码器-解码器子网络组成,分别用作“概率建模”(PMNet)和“关系增强”(RENet)(如图1(a)所示)。

The first sub-network, PMNet, embeds global features and latent distributions from incomplete point clouds, and predicts the overall skeletons (i.e. coarse completions, see Fig. 1 (a)) that are used as 3D adaptive anchor points for exploiting multi-scale point relations in RENet. Inspired by [33], PMNet uses smooth complete shape priors to improve the generated coarse completions using a dual-path architecture consisting of two parallel paths: 1) a reconstruction path for complete point clouds, and 2) a completion path for incomplete point clouds. During training, we regularize the consistency between the encoded posterior distributions from partial point clouds and the prior distributions from complete point clouds.
第一个子网络PMNet嵌入了不完整点云的全局特征和潜在分布,并预测了用作三维自适应锚定点的总体骨架(即粗完成,见图1(a)),以利用RENet中的多尺度点关系。受[33]的启发,PMNet使用平滑完整形状先验来改进生成的粗糙完成,使用由两条平行路径组成的双路径体系结构:1)完整点云的重建路径,2)不完整点云的完成路径。在训练过程中,我们对部分点云的编码后验分布和完整点云的先验分布之间的一致性进行正则化。
With the help of the generated coarse completions, the second sub-network RENet strives to enhance structural relations by learning multi-scale local point features. Motivated by the success of local relation operations in image recognition [32, 7], we propose the Point Self-Attention Kernel (PSA) as a basic building block for RENet. Instead of using fixed weights, PSA interleaves local point features by adaptively predicting weights based on the learned relations among neighboring points. Inspired by the Selective Kernel (SK) unit [12], we propose the Point Selective Kernel Module (PSK) that utilizes multiple branches with different kernel sizes to exploit and fuse multi-scale point features, which further improves the performance.
借助于生成的粗补全,第二个子网络RENet通过学习多尺度局部点特征,努力增强结构关系。基于图像识别中局部关系操作的成功[32,7],我们提出了点自我注意核(PSA)作为RENet的基本构建块。PSA不使用固定权重,而是根据相邻点之间的学习关系自适应预测权重,从而交错局部点特征。受选择性内核(SK)单元[12]的启发,我们提出了点选择性内核模块(PSK),该模块利用具有不同内核大小的多个分支来利用和融合多尺度点特征,从而进一步提高了性能。
Moreover, we create a large-scale Multi-View Partial point cloud (MVP) dataset with over 100,000 high-quality scanned partial and complete point clouds. For each complete 3D CAD model selected from ShapeNet [27], we randomly render 26 partial point clouds from uniformly distributed camera views on a unit sphere, which improves the data diversity. Experimental results on our MVP and Completion3D benchmark [21] show that VRCNet outperforms SOTA methods.
此外,我们还创建了一个大规模多视角局部点云(MVP)数据集,其中包含100000多个高质量扫描的局部和完整点云。对于从ShapeNet[27]中选择的每个完整3D CAD模型,我们从单位球体上均匀分布的摄影机视图中随机渲染26个部分点云,这提高了数据的多样性。在我们的MVP和Completion3D基准[21]上的实验结果表明,VRCNet优于SOTA方法。
In Fig. 1 (b), VRCNet reconstructs richer details than the other methods by implicitly learning the shape symmetry from this incomplete lamp. Given different partial observations, VRCNet can predict different plausible complete shapes (Fig. 1 ©). Furthermore, VRCNet can generate impressive complete shapes for incomplete realworld scans from KITTI [3] and ScanNet [2], which reveals its remarkable robustness and generalizability.
在图1(b)中,VRCNet通过从这个不完整的灯隐式学习形状对称性来重建比其他方法更丰富的细节。给定不同的局部观测,VRCNet可以预测不同的合理完整形状(图1(c))。此外,VRCNet可以为KITTI[3]和ScanNet[2]的不完整现实世界扫描生成令人印象深刻的完整形状,这表明了其显著的健壮性和通用性。
The key contributions can be summarized as: 1) We propose a novel Variational Relational point Completion Network (VRCNet), and it first performs probabilistic modeling using a novel dual-path network followed by a relational enhancement network. 2) We design multiple relational modules that can effectively exploit and fuse multiscale point features for point cloud analysis, such as the
Point Self-Attention Kernel and the Point Selective Kernel Module. 3) Furthermore, we contribute a large-scale multiview partial point cloud (MVP) dataset with over 100,000 high-quality 3D point shapes. Extensive experiments show that VRCNet outperforms previous SOTA methods on all evaluated benchmark datasets.
主要贡献可以总结为:1)我们提出了一种新的变分关系点云完成网络(VRCNet),它首先使用一种新的双路径网络进行概率建模,然后使用关系增强网络。2) 我们设计了多个能够有效利用和融合多尺度点特征进行点云分析的关系模块,如点自关注内核和点选择内核模块。3) 此外,我们还提供了一个大规模多视角局部点云(MVP)数据集,其中包含超过100000个高质量的3D点形状。大量实验表明,VRCNet在所有评估的基准数据集上都优于以前的SOTA方法。
2、Related Work 相关工作
Multi-scale Features Exploitation. Convolutional operations have yielded impressive results for image applications [11, 6, 19]. However, conventional convolutions cannot be directly applied to point clouds due to the absence of regular grids. Previous networks mostly exploit local point features by two operations: local pooling [24, 18, 16] and flexible convolution [4, 22, 13, 26]. Self-attention often uses linear layers, such as fully-connected (FC) layers and shared multilayer perceptron (shared MLP) layers, which are appropriate for point clouds. In particular, recent works [32, 7, 17] have shown that local self-attention (i.e. relation operations) can outperform their convolutional counterparts, which holds the exciting prospect of designing networks for point clouds.
多尺度特征开发。 卷积运算在图像应用中取得了令人印象深刻的结果[11,6,19]。然而,由于缺乏规则网格,传统卷积无法直接应用于点云。以前的网络主要通过两种操作利用局部点特征:局部池化[24,18,16]和弹性卷积[4,22,13,26]。自我关注通常使用线性层,例如完全连接(FC)层和共享多层感知器(共享MLP)层,这适用于点云。特别是,最近的工作[32,7,17]表明,局部自我注意(即关系运算)可以优于卷积运算,这在为点云设计网络方面具有令人兴奋的前景。
Point Cloud Completion. The target of point cloud completion is to recover a complete 3D shape based on a partial point cloud observation. PCN [30] first generates a coarse completion based on learned global features from the partial input point cloud, which is upsampled using folding operations [29]. Following PCN, TopNet [21] proposes a tree structured decoder to predict complete shapes. To preserve and recover local details, previous approaches [23, 15, 28] exploit local features to refine their 3D completion results. Recently, NSFA [31] recovers complete 3D shapes by combining known features and missing features. However, NSFA assumes that the ratio of the known part and the missing part is around 1 : 1 (i.e., the visible part should be roughly a half of the whole object), which does not hold for point clouds completion in most cases.
点云完成。 点云完成的目标是在部分点云观测的基础上恢复完整的三维形状。PCN[30]首先基于从部分输入点云中学习到的全局特征生成一个粗略完成,该点云使用折叠操作进行上采样[29]。继PCN之后,TopNet[21]提出了一种树形结构的解码器来预测完整的形状。为了保留和恢复局部细节,以前的方法[23、15、28]利用局部特征来优化其3D完成结果。最近,NSFA[31]通过组合已知特征和缺失特征来恢复完整的3D形状。然而,NSFA假设已知部分和缺失部分的比率约为1:1(即,可见部分应约为整个对象的一半),这在大多数情况下不适用于点云完成。
3 Our Approach 我们的方法
We define the incomplete point cloud X X X as a partial observation for a 3D object, and a complete point cloud Y Y Y is sampled from the surfaces of the object. Note that X X X need not to be a subset of Y Y Y, since X X X and Y Y Y are generated by two separate processes. The point cloud completion task aims to predict a complete shape Y ′ Y' Y′ conditioned on X X X. VRCNet generate high-quality complete point clouds in a coarse-to-fine fashion. Firstly, we predict a coarse completion Y ′ Y' Y′ based on embedded global features and an estimated parametric distribution. Subsequently, we recover relational geometries for the fine completion Y ′ Y' Y′ by exploiting multiscale point features with novel self-attention modules.
我们将不完整的点云 X X X定义为3D对象的部分观测,并从对象的表面采样完整的点云 Y Y Y。请注意, X X X不必是 Y Y Y的子集,因为 X X X和 Y Y Y由两个单独的进程生成。点云完成任务旨在预测以 X X X为条件的完整形状 Y ′ Y' Y′。VRCNet以由粗到精的方式生成高质量的完整点云。首先,我们基于嵌入的全局特征和估计的参数分布预测一个粗略的完成 Y ′ Y' Y′。随后,我们利用多尺度点特征和新颖的自我注意模块恢复精细完成 Y ′ Y' Y′的关系几何。
3.1. Probabilistic Modeling 概率建模
Previous networks [30, 21] tend to decode learned global features to predict overall shape skeletons as their completion results, which cannot recover fine-grained geometric details. However, it is still beneficial to first predict the shape skeletons before refining local details for the following reasons: 1) shape skeletons describe the coarse complete structures, especially for those areas that are entirely missing in the partial observations; 2) shape skeletons can be regarded as adaptive 3D anchor points for exploiting local point features in incomplete point clouds [15]. With these benefits, we propose the Probabilistic Modeling network (PMNet) to generate the overall skeletons (i.e. coarse completions) for incomplete point clouds.
以前的网络[30,21]倾向于解码学习到的全局特征,以预测整体形状骨架作为其完成结果,这无法恢复细粒度的几何细节。然而,在细化局部细节之前,首先预测形状骨架仍然是有益的,原因如下:1)形状骨架描述了粗糙的完整结构,特别是对于部分观测中完全缺失的区域;2) 形状骨架可被视为自适应3D锚定点,用于利用不完整点云中的局部点特征[15]。基于这些优点,我们提出了概率建模网络(PMNet)来生成不完整点云的总体骨架(即粗略完成)。
In contrast to previous methods, PMNet employs probabilistic modeling to predict the coarse completions based on both embedded global features and learned latent distributions. Moreover, we employ a dual-path architecture (shown in Fig. 2) that contains two parallel pipelines: the upper reconstruction path for complete point clouds Y Y Y and the lower completion path for partial point clouds X X X. The reconstruction path follows a variational auto-encoder (VAE) scheme. It first encodes global features z g z_g zg and latent distributions q φ ( z g ∣ Y ) q_φ(z_g|Y) qφ(zg∣Y) for the complete shape Y Y Y, and then it uses a decoding distribution p θ r ( Y ∣ z g ) p^r_\theta(Y|z_g) pθr(Y∣zg) to recover a complete shape Y ′ Y' Y′ . The objective function for the reconstruction path can be formulated as:
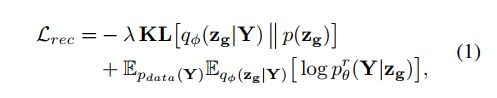
where K L KL KL is the KL divergence, E E E denotes the estimated
expectations of certain functions, p d a t a ( Y ) p_{data}(Y) pdata(Y) denotes the true
underlying distribution of data, and p ( z g ) p(z_g) p(zg) = N ( 0 ; I ) N (0; I) N(0;I) is the
conditional prior predefined as a Gaussian distribution, and
λ λ λ is a weighting parameter.

与以前的方法相比,PMNet基于嵌入的全局特征和学习的潜在分布,采用概率建模来预测粗完成。此外,我们采用了一种双路径架构(如图2所示),该架构包含两条并行管道:完整点云的上部重建路径 Y Y Y,部分点云的下部完成路径 X X X。重建路径遵循变分自动编码器(VAE)方案。它首先将全局特征 z g z_g zg和潜在分布 q φ ( z g ∣ Y ) q_φ(z_g|Y) qφ(zg∣Y)编码为完整形状 Y Y Y,然后使用解码分布 p θ r ( Y ∣ z g ) p^r_θ(Y | z_g) pθr(Y∣zg)来恢复完整形状 Y ′ Y' Y′。重建路径的目标函数可以表示为:
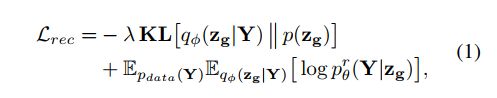
其中, K L KL KL表示KL散度, E E E表示某些函数的估计期望, p d a t a ( Y ) p{data}(Y) pdata(Y)表示数据的真实底层分布, p ( z g ) p(z_g) p(zg)= N ( 0 ; 1 ) N(0;1) N(0;1) 是预定义为高斯分布的条件先验值, λ λ λ是加权参数。
The completion path has a similar structure as the constructive path, and both two paths share weights for their encoder and decoder except the distribution inference layers. Likewise, the completion path aims to reconstruct a complete shape Y ′ Y' Y′ based on global features z g z_g zg and latent distributions p ( z g ∣ X ) p(z_g|X) p(zg∣X) from an incomplete input X X X. To exploit the most salient features from the incomplete point cloud, we use the learned conditional distribution q φ ( z g ∣ Y ) q_φ(z_g|Y) qφ(zg∣Y) encoded by its corresponding complete 3D shapes Y Y Y to regularize latent distributions p ( z g ∣ X ) p (z_g|X) p(zg∣X) during training (shown as the Distribution Link in Fig. 2, the arrow indicates that we regularize p ( z g ∣ X ) p(z_g|X) p(zg∣X) to approach q φ ( z g ∣ Y ) q_φ(z_g|Y) qφ(zg∣Y). Hence, q φ ( z g ∣ Y ) q_φ(z_g|Y) qφ(zg∣Y) constitutes the prior distributions, p ( z g ∣ X ) p(z_g|X) p(zg∣X) is the posterior importance sampling function, and the objective function for completion path is defined as follows:
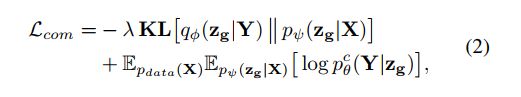
where φ, and θ represent different network weights of their corresponding functions. Notably, the reconstruction path is only used in training, and hence the dual-path architecture does not influence our inference efficiency.
完成路径具有与构造路径相似的结构,并且除了分布推理层之外,两条路径共享其编码器和解码器的权重。同样,完成路径旨在基于全局特征 z g z_g zg和潜在分布 p ( z g ∣ X ) p(z_g|X) p(zg∣X)从不完整输入 X X X重建完整形状 Y ′ Y' Y′。为了利用不完整点云的最显著特征,我们使用学习到的条件分布 q φ ( z g ∣ Y ) q_φ(z_g|Y) qφ(zg∣Y)由其相应的完整3D形状 Y Y Y编码,以在训练期间正则化潜在分布 p ( z g ∣ X ) p(z_g|X) p(zg∣X)(如图2中的分布链接所示,箭头表示我们将 p ( z g ∣ X ) p(z_g|X) p(zg∣X)正则化以接近 q φ ( z g ∣ Y ) q_φ(z_g|Y) qφ(zg∣Y)。因此, q φ ( z g ∣ Y ) q_φ(z_g|Y) qφ(zg∣Y)构成先验分布, p ( z g ∣ X ) p(z_g|X) p(zg∣X)是后验重要性抽样函数,完成路径的目标函数定义如下:

其中φ和θ表示其相应函数的不同网络权重。值得注意的是,重建路径仅用于训练,因此双路径结构不会影响我们的推理效率。
3.2. Relational Enhancement 关系增强
After obtaining coarse completions Y ′ Y' Y′ , the Relational
Enhancement network (RENet) targets at enhancing structural relations to recover local shape details. Although previous methods [23, 31, 15] can preserve observed geometric details by exploiting local point features, they cannot effectively extract structural relations (e.g. geometric symmetries) to recover those missing parts conditioned on the partial observations. Inspired by the relation operations for image recognition [7, 32], we propose the Point SelfAttention kernel (PSA) to adaptively aggregate local neighboring point features with learned relations in neighboring points (Fig. 3 (a)). The operation of PSA is formulated as:

where x N ( i ) x_{N(i)} xN(i) is the group of point feature vectors for the selected K-Nearest Neighboring (K-NN) points N ( i ) N(i) N(i). α ( x N ( i ) ) α(x_{N(i)}) α(xN(i)) is a weighting tensor for all selected feature vectors. β ( x j ) β(x_j) β(xj) is the transformed features for point j j j, which has the same spatial dimensionality with α ( x N ( i ) ) j α(x_{N(i)})_j α(xN(i))j. Afterwards, we obtain the output y i y_i yi using an element-wise product , which performs a weighted summation for all points j ∈ N ( i ) j \in N(i) j∈N(i). The weight computation α ( x N ( i ) ) α(x_{N (i)}) α(xN(i)) can be decomposed as follows:

where γ, σ and ξ are all shared MLP layers (Fig. 3 (a)), and the relation function δ combines all feature vectors x j ∈ x N ( i ) x_j \in x_{N(i)} xj∈xN(i) by using concatenation operations
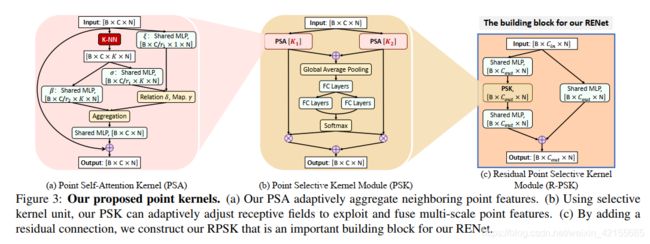
Observing that different relational structures can have different scales, we enable the neurons to adaptively adjust their receptive field sizes by leveraging the selective kernel unit [12]. Hence, we construct the Point Selective Kernel module (PSK), which adaptively fuses learned structural relations from different scales. In Fig. 3 (b), we show a two-branch case, which has two PSA kernels with different kernel (i.e. K-NN) sizes. The operations of the PSK are formulated as:

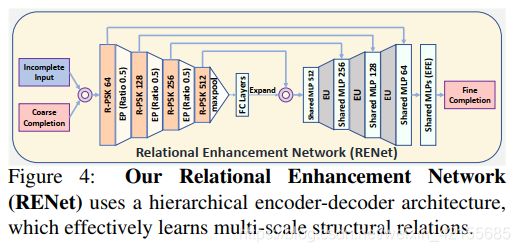
Furthermore, we add an residual path besides the main path (shown in Fig. 3 ©) and then construct the Residual Point Selective Kernel module (R-PSK) that is used as a building block for RENet. As shown in Fig. 4, RENet follows a hierarchical encoder-decoder architecture by using Edge-preserved Pooling (EP) and Edge-preserved Unpooling (EU) modules [16]. We use an Edge-aware Feature Expansion (EFE) module [15] to expand point features, which generates high-resolution complete point clouds with predicted fine local details. Consequently, multi-scale structural relations can be exploited for fine details generation.
3.3. Loss Functions 损失函数

4. Multi-View Partial Point Cloud Dataset
Towards an effort to build a more unified and comprehensive dataset for incomplete point clouds, we contribute the MVP dataset, a high-quality multi-view partial point cloud dataset, to the community. We compare the MVP dataset to previous partial point cloud benchmarks, PCN [30] and Completion3D [21] in Table 1. The MVP dataset has many advantages over the other datasets.
Diversity & Uniform Views. First, the MVP dataset consists of diverse partial point clouds. Instead of rendering partial shapes by using randomly selected camera poses [30, 21], we select 26 camera poses that are uniformly distributed on a unit sphere for each CAD model (Fig. 5 (a)). Notably, the relative poses between our 26 camera poses are fixed, but the first camera pose is randomly selected, which is equivalent to performing a random rotation to all 26 camera poses. The major advantages of using uniformly distributed camera views are threefold: 1) The MVP dataset has fewer similar rendered partial 3D shapes than the other
datasets. 2) Its partial point clouds rendered by uniformly distributed camera views can cover most parts of a complete 3D shape. 3) We can generate sufficient incompletecomplete 3D shape pairs with a relatively small number of 3D CAD models. According to Tatarchenko et. al. [20], many 3D reconstruction methods rely primarily on shape recognition; they essentially perform shape retrieval from the massive training data. Hence, using fewer complete shapes during training can better evaluate the capability of
generating complete 3D shapes conditioned on the partial observation, rather than naively retrieving a known similar complete shape. An example of 26 rendered partial point clouds are shown in Fig. 5 (b).
Large-Scale & High-Resolution. Second, the MVP dataset consists of over 100,000 high-quality incomplete and complete point clouds. Previous methods render incomplete point clouds by using small virtual camera resolutions (e.g. 160 × 120), which is much smaller than real depth cameras (e.g. both Kinect V2 and Intel RealSense are 1920 × 1080). Consequently, the rendered partial point clouds are unrealistic. In contrast, we use the resolution
1600 × 1200 to render partial 3D shapes of high quality (Fig. 5 ©). For ground truth, we employ Poisson Disk
Sampling (PDS) [1, 8] to sample non-overlapped and uniformly spaced points for complete shapes (Fig. 5 (d)). PDS
yields smoother complete point clouds than uniform sampling, making them a better representation of the underlying object CAD models. Hence, we can better evaluate network capabilities of recovering high-quality geometric details. Previous datasets provide complete shapes with only
one resolution. Unlike those datasets, we create complete
point clouds with different resolutions, including 2048(1x),
4096(2x), 8192(4x) and 16384(8x) for precisely evaluating
the completion quality at different resolutions.