Hadoop集群进行map词频统计
一、首先新建虚拟机
二、配置静态IP
1、首先查看虚拟网络编辑器 查看起始IP

2.1、修改静态IP
输入指令:vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改BOOTPROTO=static
增加IPADDR、NETWASK、GATEWAY、DNS1
![]()

2.2、输入指令:vi /etc/sysconfig/network增加以下两条
![]()

2.3、输入指令:vi /etc/hosts 添加上IP和主机名

2.4、输入:reboot 重启虚拟机
三、安装JDK
3.1、在opt目录下创建module、jdk文件夹
输入命令:cd /opt/
输入命令:mkdir module
输入命令:mkdir jdk
输入命令:mkdir hadoop
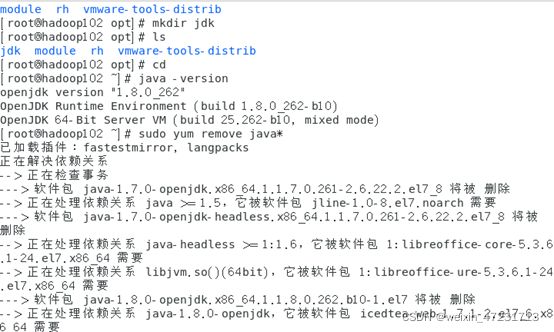
3.2、卸载当前jdk
输入命令:java -version 查看当前jdk版本
输入命令:yum remove java* 卸载所有jdk
3.3、使用FileZilla链接虚拟机
将jdk压缩包上传到hadoop102的opt/jdk目录下、
hadoop压缩包上传到hadoop102的opt/hadoop目录下。

3.4、解压压缩包到制定目录
输入指令:cd /opt/jdk
输入指令:tar -zxvf jdk(jdk压缩包) -C /opt/module/

3.5、配置profile文件并让其生效
输入指令:pwd 查看当前目录
输入指令:vi /etc/profile 在文件末尾添加JAVA_HOME

输入指令:source /etc/profile
输入指令:java -version

四、安装hadoop
4.1、解压hadoop到指定目录
切换到根目录
输入指令:mkdir kkb
输入指令:cd kkb
输入指令:mkdir install
输入指令:cd /opt/hadoop
输入指令:tar -zxvf hadoop(hadoop压缩包) -C /kkb/install

4.2、配置profile文件并使其生效
输入指令:vi /etc/profile 配置HADOOP_HOME环境

输入指令:source /etc/profile
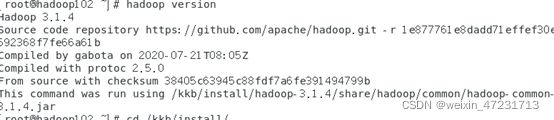
输入指令:hadoop version
五、克隆出hadoop103、hadoop104,并向hadoop102一样步骤修改静态IP
六、配置ssh免密登录
6.1、以102为例配置ssh
输入指令:cd ~/.ssh
输入指令:ssh-keygen -t rsa
连续输入三个回车,生成密匙
6.2、分发密匙,优先分发给自己,再分发给103、104
输入指令:ssh-copy-id 192.168.88.130
输入指令:ssh-copy-id 192.168.88.131
输入指令:ssh-copy-id 192.168.88.132
6.3、在103、104上按照6.1-6.2的步骤配置ssh


七、配置集群分发脚本xsync
7.1、在/usr/local/bin目录下创建xsync文件
输入指令:vi /usr/local/bin/xsync
7.2、xsync内容文件如下:
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=103; host<105; host++)); do
#echo $pdir/$fname $user@hadoop$host:$pdir
echo --------------- hadoop$host ----------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
7.3、修改文件权限
输入指令:chomd a+x xsync
八、hadoop3的集群配置
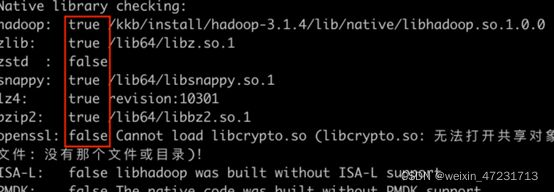
8.1、执行checknative
输入指令:cd /kkb/install/hadoop-3.1.4/
输入指令:bin/hadoop checknative
8.2、安装openssl-deve1
输入指令:yum -y install openssl-deve1
8.3、修改dfs、yarn配置文件
输入指令:cd /kkb/install/hadoop-3.1.4/etc/hadoop
输入指令:vim /hadoop-env.sh 在末尾添加以下内容
export JAVA_HOME=/kkb/install/jdk1.8.0_162输入指令:vim core-site.xml 在标签内添加以下内容
fs.defaultFS
hdfs://hadoop102:8020
hadoop.tmp.dir
/kkb/install/hadoop-3.1.4/hadoopDatas/tempDatas
io.file.buffer.size
4096
fs.trash.interval
10080
输入指令:vim /hdfs-site.xml
dfs.namenode.secondary.http-address
hadoop102:9868
dfs.namenode.http-address
hadoop102:9870
dfs.namenode.name.dir
file:///kkb/install/hadoop-3.1.4/hadoopDatas/namenodeDatas
dfs.datanode.data.dir
file:///kkb/install/hadoop-3.1.4/hadoopDatas/datanodeDatas
dfs.namenode.edits.dir
file:///kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits
dfs.namenode.checkpoint.dir
file:///kkb/install/hadoop-3.1.4/hadoopDatas/dfs/snn/name
dfs.namenode.checkpoint.edits.dir
file:///kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/edits
dfs.replication
3
dfs.permissions.enabled
false
dfs.blocksize
134217728
输入指令:vim mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.job.ubertask.enable
true
mapreduce.jobhistory.address
hadoop102:10020
mapreduce.jobhistory.webapp.address
hadoop102:19888
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.map.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
输入指令:vi yarn-site.xml
yarn.resourcemanager.hostname
hadoop102
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.pmem-check-enabled
false
输入指令:vi workers
hadoop102
hadoop103
hadoop1048.4、创建文件存放目录
输入指令:mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/tempDatas
输入指令:mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/namenodeDatas
输入指令:mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/datanodeDatas
输入指令:mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits
输入指令:mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/dfs/snn/name
输入指令:mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/edits
8.5、使用xsync分发配置文件
输入指令:xsync hadoop-3.1.4 102在install目录下将hadoop分发给103、104
九、启动hdfs、yarn
9.1、在102上格式化集群(只能格式一次、不能频繁格式)
输入指令:hdfs namenode -format
9.2、在102的hadoop-3.1.4目录下启动dfs、yarn
输入指令:sbin/start-dfs.sh
输入指令:sbin/start-yarn.sh
9.3、jps命令查看启动进程
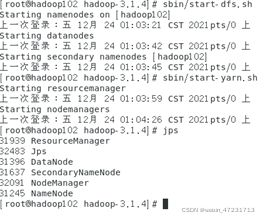
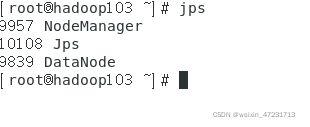

9.4、验证集群是否启动成功
在浏览器打开:192.168.88.130:8088
在浏览器打开:192.168.88.130:9870


十、在Windows中配置hadoop
10.1、修改windows的hosts文件
地址:C:\Windows\System32\drivers\etc\hosts

10.2、配置Windows本中配置hadoop环境
将集群所用的hadoop-3.1.4.tar.gz解压到一个没有中文、空格的目录下
10.3、配置hadoop的环境变量
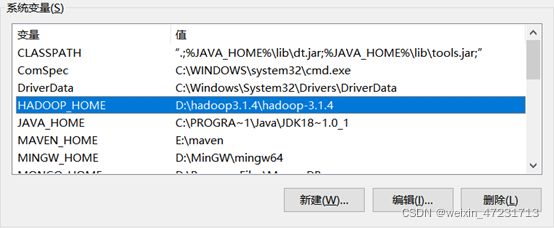

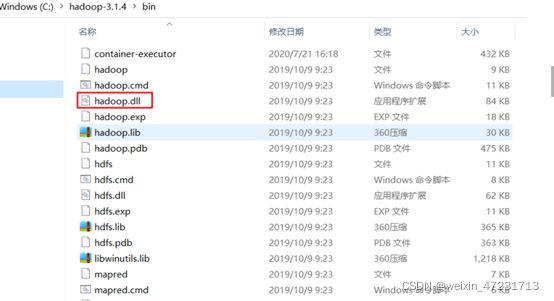
10.4、将下图的hadoop.dll文件拷贝到C:\\Windows\System32
10.5、将hadoop集群的一下5个配置文件core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers,拷贝到windows下hadoop的C:\hadoop-3.1.4\etc\hadoop目录下
10.6、打开cmd运行hadoop命令
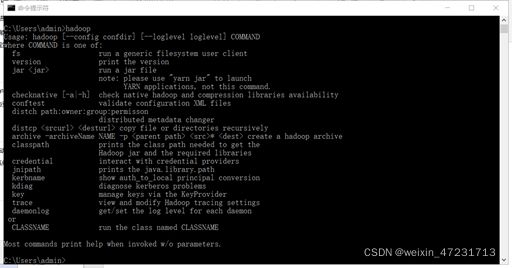
十一、安装maven
11.1、下载安装包 apache-maven-3.6.1-bin.zip 并解压到某目录、配置环境变量

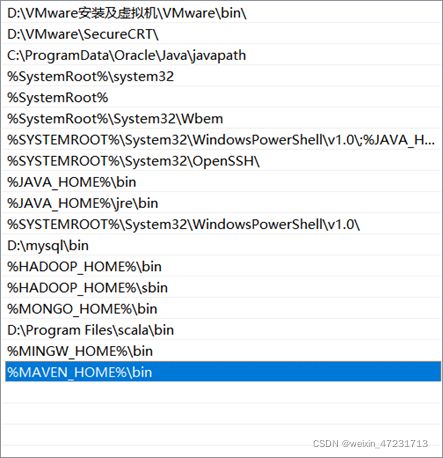
11.2、cmd中运行mvn -v
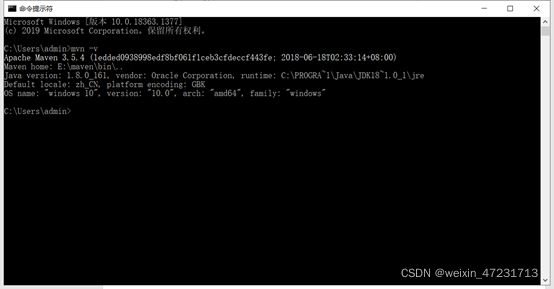
11.3、找到maven解压的目录,找到settings.xml文件,添加以下内容
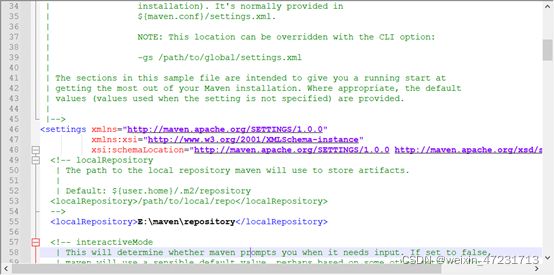

11.4、打开IDEA,新建一个maven工程,配置pom文件,内容如下:
3.1.4
org.apache.hadoop
hadoop-client
${hadoop.version}
org.apache.hadoop
hadoop-common
${hadoop.version}
org.apache.hadoop
hadoop-hdfs
${hadoop.version}
org.apache.hadoop
hadoop-mapreduce-client-core
${hadoop.version}
junit
junit
4.11
test
org.testng
testng
RELEASE
log4j
log4j
1.2.17
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
org.apache.maven.plugins
maven-shade-plugin
2.4.3
package
shade
true
十二、词频统计程序实现
12.1、编写mapper类
package wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class MyMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获得当前行的数据
String line = value.toString();
//获得一个个的单词
String lineBuffer = line;
String[] keys = new String[]{" ", "\t", " ", ".", "(", ")", "(", ")"};
for (String k : keys){
lineBuffer = lineBuffer.replace(k, ",");
}
String[] wordsBuffer = lineBuffer.split(",");
List words = new ArrayList<>();
for (String w : wordsBuffer){
if (!w.equals("")){
words.add(w);
}
}
//每个单词编程kv对
for (String word : words) {
//将kv对输出出去
context.write(new Text(word),new IntWritable(1));
}
}
}
12.2、编写Reducer类
package wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer {
//bear,List(2,3,3)
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
int count = value.get();
sum +=count;
}
context.write(key,new IntWritable(sum));
}
}
12.3、组装main程序
package wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int run = ToolRunner.run(new Configuration(), new WordCount(), args); // 集群代码
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf(), "wordcount");
job.setJarByClass(WordCount.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path(args[0]));
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path(args[1]));
job.setNumReduceTasks(Integer.parseInt(args[2]));
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
}
12.4、将程序打包、点击maven的package
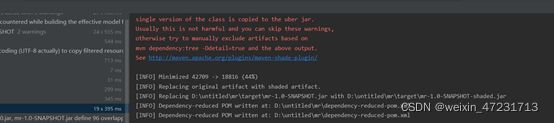
十三、在集群中实现
13.1、使用FileZilla链接hadoop102
找到打包文件,和测试文件,一起上传到hadoop102

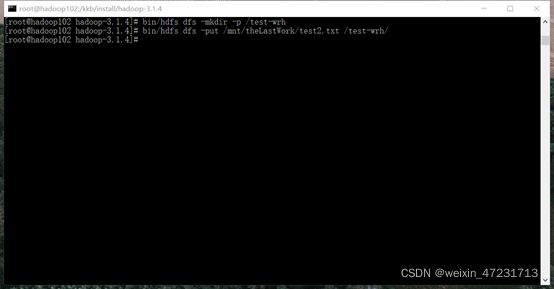
13.2、将测试文件上传到hdfs
在hadoop-3.1.4目录下
输入指令:bin/hdfs dfs -mkdir -p /test-wrh 在hdfs上创建test-wrh文件夹
输入指令:bin/hdfs dfs -put 测试文件地址 /test-wrh/ 将测试文件上传到test-wrh

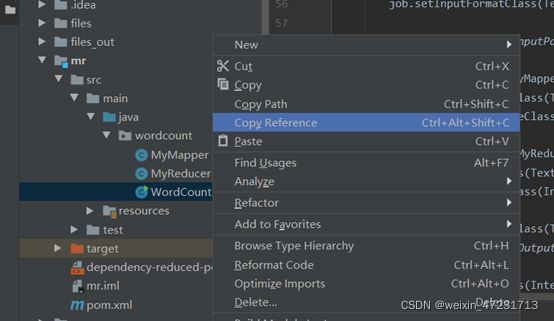
13.3、在IDEA中拷贝地址
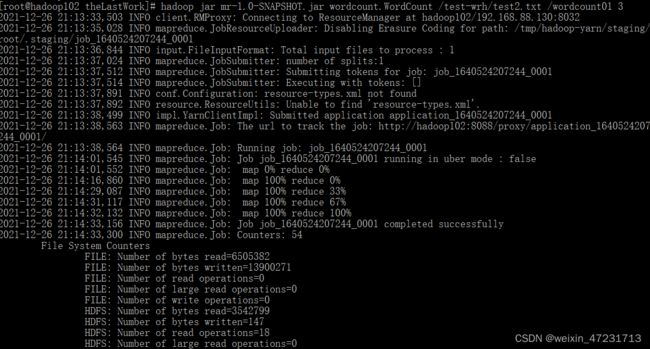
13.4、运行程序
在包含程序的目录中:
输入指令:hadoop jar jar包名 Reference /输入路径 /输出路径 3个节点

 13.5、将结果从hdfs上下载
13.5、将结果从hdfs上下载
![]()
输入指令:hadoop fs -get /输出路径/part-r-00000 /下载路径
![]()
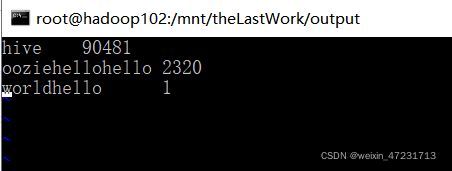
13.6、查看结果
输入指令:vim part-r-00000