小白都能学会的python+opencv,带你从人脸识别做到车牌识别,成为别人口中赞叹的高手!
一.第一步,对于小白来说,用什么编辑很难选择,怎么下载免费的编辑器也不会,会用电脑下载的又总是被下载许多附带的垃圾软件,这个问题让我来解决,这里我们首先需要安装两个软件以及配置一个pip豆瓣源,第一个python 3.6.5的软件,然后安装pycharm-community编辑软件。
给上百度网盘链接,绝对无垃圾软件安装,小白们放心安装:
链接:https://pan.baidu.com/s/1WKpEG9qBPRZW-V1UTemUpQ
提取码:y6z2
pip豆瓣源配置
介绍:
pip豆瓣源配置是为了之后在搭环境时候可以直接用pip install xxx(这里写python库的名字)的命令加速下载所需要的各种python库,如果不配置pip源的话,直接下载库速度会很慢,而且还会经常下载失败,pip源也分为阿里云、豆瓣、清华大学、中国科学技术大学四种,在这里我们配置pip豆瓣源,豆瓣源内python库比较种类全而且相对较稳定。
步骤:
1.下载好网盘内的三个文件后,找到pip文件夹
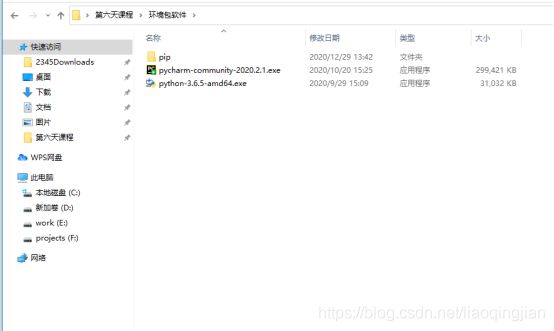
2.将pip文件复制后,找到C盘的用户文件夹
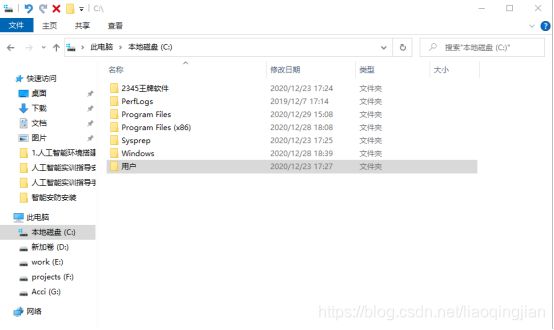
3.将用户文件夹打开,找到Administrator文件夹
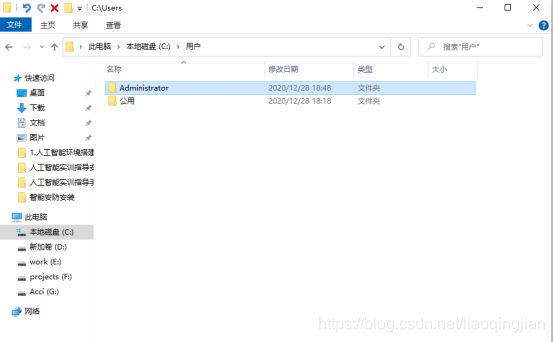
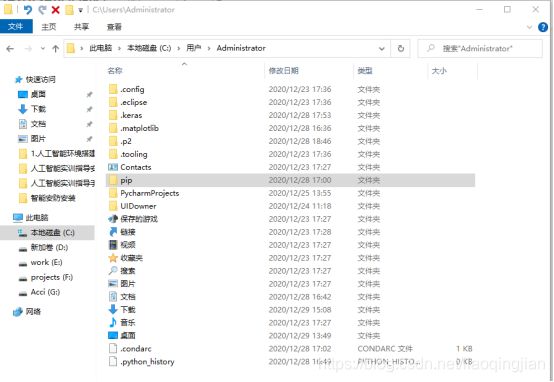
4.打开Administrator文件夹,将复制的pip文件夹放入该Administrator目录下,完成pip豆瓣源的配置。

python软件安装
介绍:
python软件是最基础的python运行的软件,安装python能够实现一般的python程序运行。
步骤:
1.找到python-3.6.5-amd64.exe软件,点击开始安装python3.6.5软件

2.勾上Add Python 3.6 to PATH

3.点击Install Now

4.出现Close说明安装完成,点击Close完成安装
Pycharm-Community软件安装
介绍:
pycharm-community软件是python的可视化软件,能够在其中展现运行的界面和运行的过程,并且能够在其中配置python软件的环境,实现两个软件同时实现可视化编程。
步骤:
1.找到pycharm-community-2020.2.1.exe文件,点击开始安装pycharm-community软件。

2.点击Next

3.选择你安装的路径,在这里我安装在默认的路径中,继续点击Next

4.勾选64-bit launcher和Add launchers dir to the PATH,继续点击Next
在这里插入图片描述


5.点击Install
6.等待安装
7.出现Finish,说明完成安装,点击Finish结束安装

8.在桌面找到pycharm图标,双击图标

9.选择New Project,打开新项目

10.选择Esting interpreter,选择python路径
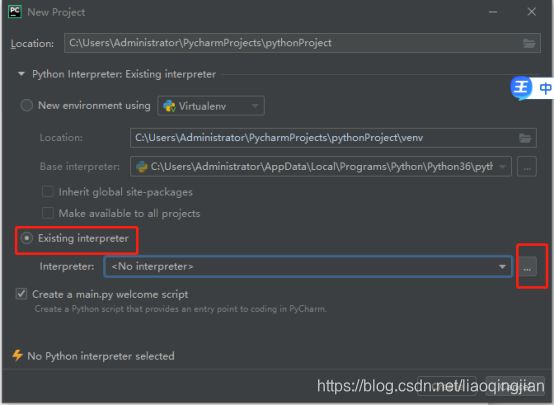
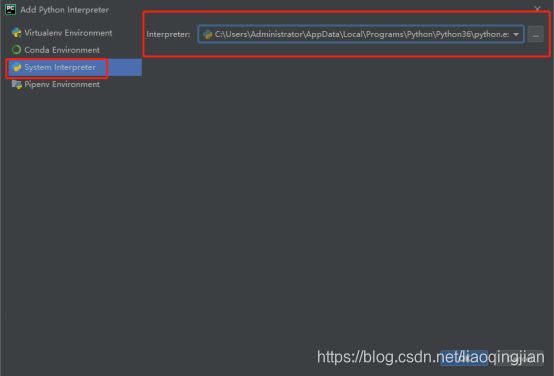

11.点击Creat创建第一个新项目
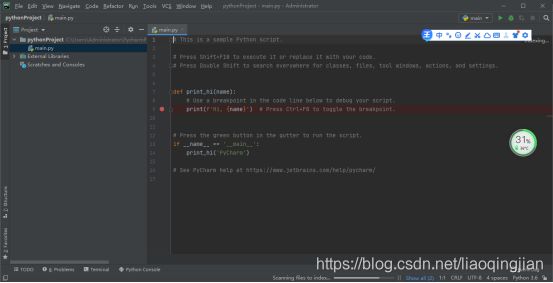
二.环境终于安装成功了吧,现在开始我们的项目实操,从人脸识别做到车牌识别。
人脸识别部分,素材和模型我们需要获取,同样给你们网盘链接,永久有效
链接:https://pan.baidu.com/s/1iRwQ1pLTErgrwohzqH_V8A
提取码:5w1s
人脸图片识别
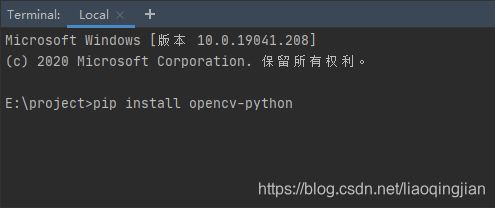
1.下载opencv-python库,在Terminal中使用命令pip install opencv-python
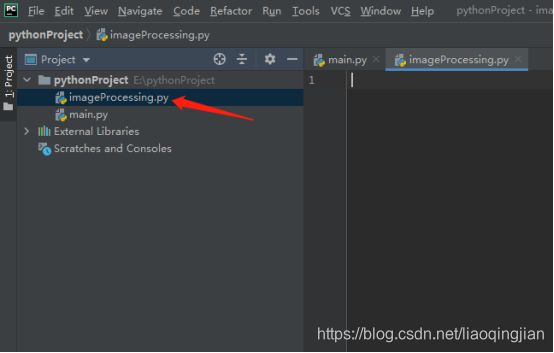
2.右键点击pythonProject,新建一个imageProcessing.py文件,如下图
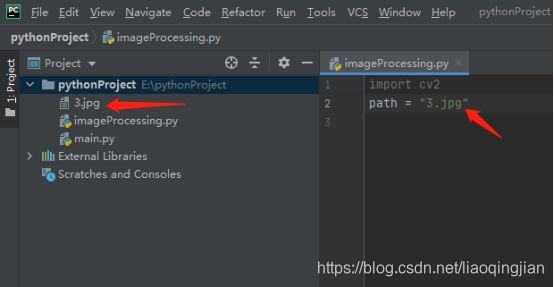
3.在imageProcessing.py文件中开始写代码,首先导入cv2库,如下图

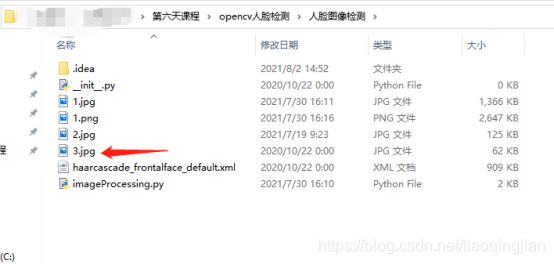
4.输入素材图片的路径,素材在发的文档里面找,名字是3.jpg
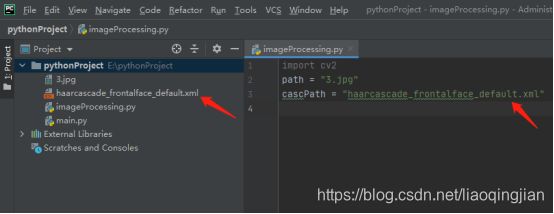
5.找到人脸识别的类型器,将类型器复制到项目中,写入类型器的路径并赋予变量cascPath

6.使用cv2库读取图片的路径
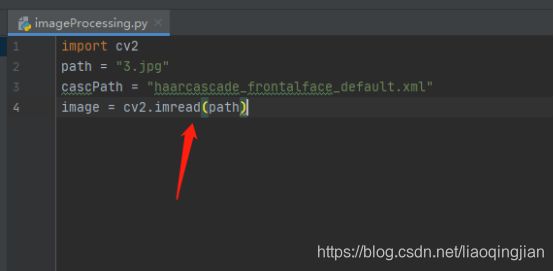
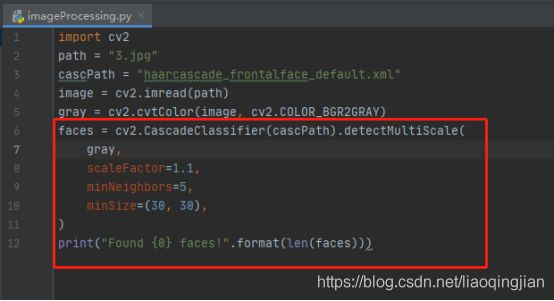
7.将图片从rgb颜色格式转成gray灰色格式

8.通过cv2.CascadeClassifier(cascPath).detectMultiScale函数进行人脸识别处理,并且输出该图片有几张人脸。参数scaleFactor是图像长宽同时按照一定比例(默认1.1)逐步缩小,然后检测,参数设置的越大,计算速度越快,参数minNeighbors 是模糊度参数,设置越小越容易识别,越大越不容易识别,参数minSize是最小的长和宽像素。
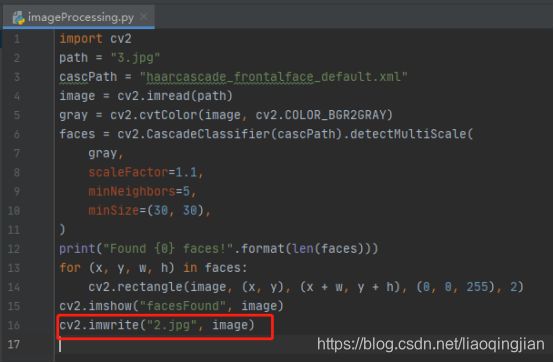
9.在原图的人脸上画出识别的矩形区域,(0, 0, 255)是红色、(0, 255, 0)是绿色、(255, 0, 0)是蓝色。

10.展示识别出人脸的图片

11.将识别人脸后的图片保存成2.jpg文件
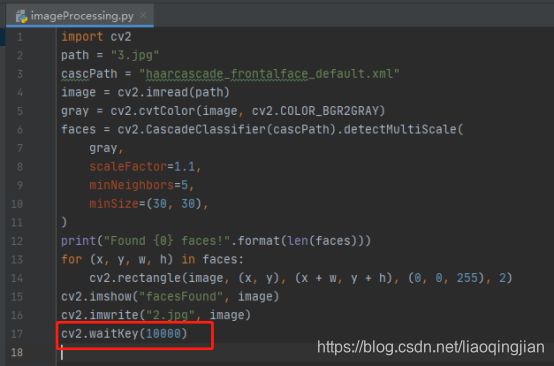
12.等待窗口展示10秒
13.销毁所有的窗口,避免占用内存
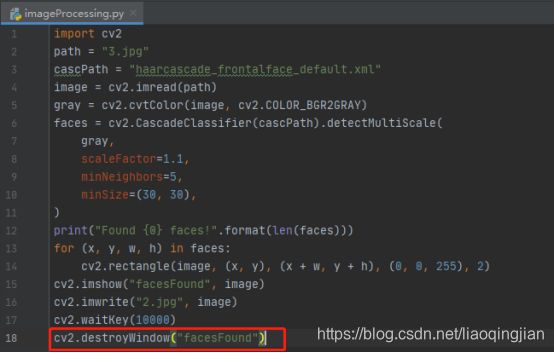
14.运行展示

完整代码展示
import cv2 # 导入opencv-python库即cv2库
path = "3.jpg" # 写入图片的路径并赋予变量path
cascPath = "haarcascade_frontalface_default.xml" # 写入类型器的路径并赋予变量cascPath
image = cv2.imread(path) # 读取图片的路径
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 把图片转为灰色以便进行人脸识别处理
# scaleFactor 图像长宽同时按照一定比例(默认1.1)逐步缩小,然后检测,参数设置的越大,计算速度越快
# minNeighbors 模糊度参数,设置越小越容易识别,越大越不容易识别
# minSize是最小的长和宽像素
faces = cv2.CascadeClassifier(cascPath).detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30),
)
print("Found {0} faces!".format(len(faces)))
# 通过cv2.CascadeClassifier(cascPath).detectMultiScale函数进行人脸识别处理,并且输出该图片有几张人脸
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2) # (0, 0, 255)红色、(0, 255, 0)绿色、(255, 0, 0)蓝色
# 在原图的人脸上画出识别的矩形区域
cv2.imshow("facesFound", image) # 展示识别出人脸的图片
cv2.imwrite("2.jpg", image) # 将识别人脸后的图片写入该路径的2.jpg文件
cv2.waitKey(10000) # 等待窗口展示,防止一闪而过
cv2.destroyWindow("facesFound") # 销毁创造的facesFound窗口
人脸视频检测
1.重新创建一个项目,从File->New Project
2.项目名字可以自己取,这里我默认
3.开始创建的时候这里我们选择This Window,This Window和New Window的区别就是This Window覆盖原先的窗口、New Window是新打开一个窗口。

4.打开项目后右键点击pythonProjec1,新建一个videoProcessing.py文件

5.导入cv2库

6.找到1.mp4素材,复制在项目中

7.写入视频的路径并赋予变量cap

8.找到人脸识别的类型器,将类型器复制到项目中,写入类型器的路径并赋予变量cascPath
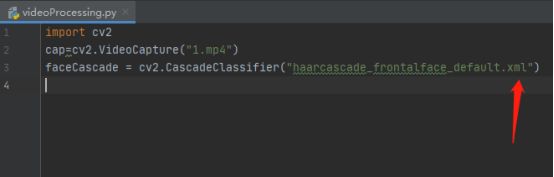
9.写一个视频播放的循环while函数,cap.isOpened()函数是判断该视频是否正确播放

10.读取视频,第一个参数ret 为True 或者False,代表有没有读取到图片,第二个参数frame表示读取到每一帧的图片

11.判断图片是否正常读取

12.将图片从rgb格式转成gray灰色格式

13.通过cv2.CascadeClassifier(cascPath).detectMultiScale函数进行人脸识别处理,并且输出该图片有几张人脸。参数scaleFactor是图像长宽同时按照一定比例(默认1.1)逐步缩小,然后检测,参数设置的越大,计算速度越快,参数minNeighbors 是模糊度参数,设置越小越容易识别,越大越不容易识别,参数minSize是最小的长和宽像素。
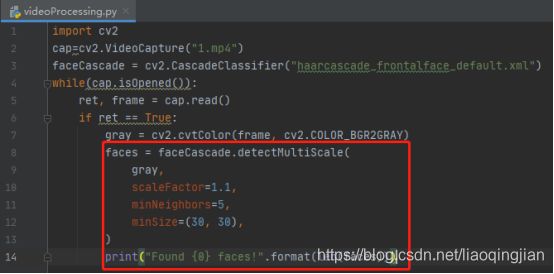
14.在视频的每一帧上画矩形
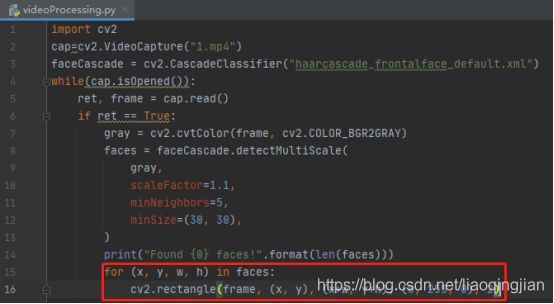
15.创建一个叫facesFound的窗口,播放处理后的视频

16.视频正常播放时等待,当按“q”键时停止运行
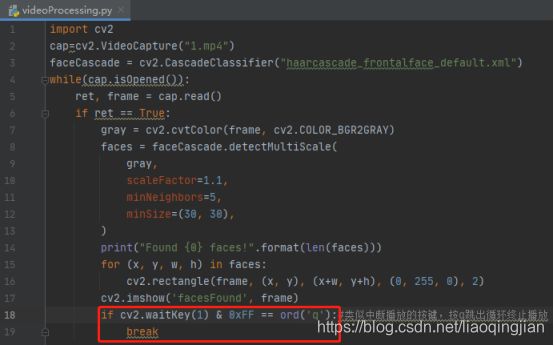
17.如果读取的视频帧不正常将会自动停止运行,不会报错

18.运行完成,将所有的视频释放,并且销毁所有的窗口

19.运行结果

完整代码展示
import cv2#导入opencv-python库即cv2库
# cap = cv2.VideoCapture(0)#打开内置摄像头
cap=cv2.VideoCapture("1.mp4")#写入视频的路径并赋予变量cap
faceCascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")#写入类型器的路径并给cv2.CascadeClassifier函数进行处理
while(cap.isOpened()):#cap.isOpened()函数是判断该视频是否正确播放
ret, frame = cap.read()#读取视频,第一个参数ret 为True 或者False,代表有没有读取到图片,第二个参数frame表示截取到一帧的图片
if ret==True:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# scaleFactor 图像长宽同时按照一定比例(默认1.1)逐步缩小,然后检测,参数设置的越大,计算速度越快
# minNeighbors 模糊度参数,设置越小越容易识别,越大越不容易识别
# minSize是最小的长和宽像素
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30),
)
print("Found {0} faces!".format(len(faces)))
# 通过cv2.CascadeClassifier(cascPath).detectMultiScale函数进行人脸识别处理,并且输出每帧图片有几张人脸
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 在原图的人脸上画出识别的矩形区域
cv2.imshow('facesFound', frame)#创造一个facesFound窗口来展示每一帧的图片,使其类似以视频方式播放
if cv2.waitKey(1) & 0xFF == ord('q'):#类似中断播放的按键,按q跳出循环终止播放
break
else:
break#如果视频结束正常跳出循环终止播放
cap.release()#释放视频
cv2.destroyAllWindows()#将创建的所有的窗口毁灭
车牌识别素材网盘获取
链接:https://pan.baidu.com/s/1p82yY7X_c2tHWD9A37kk6g
提取码:p7zf
车牌图片识别
1.重新创建一个项目,从File->New Project

2.项目名字可以自己取,这里我默认
3.开始创建的时候这里我们选择This Window,This Window和New Window的区别就是This Window覆盖原先的窗口、New Window是新打开一个窗口。

4.打开项目后右键点击pythonProjec2,新建一个licenseImage.py文件
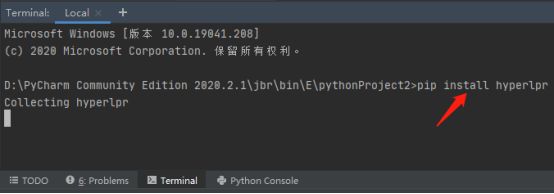
5.使用命令pip install hyperlpr下载识别车牌号码的python库
6.继续使用命令pip install opencv-python==3.4.8.29下载版本为3.4.8.29的opencv库

7.继续使用命令pip install pillow下载该python库
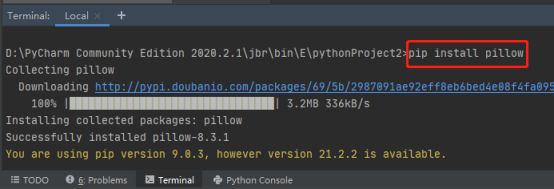
8.下载好这两个库后导入这四个库
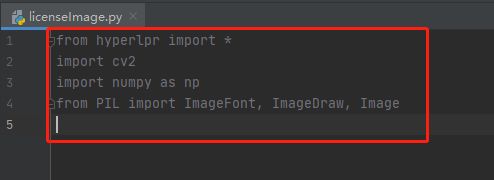
9.定义一个函数cv2AddChineseText,这个函数的目的是在图像上写出中文字符,该函数内的参数分别是图像、文本内容、像素位置,文本颜色,文本大小
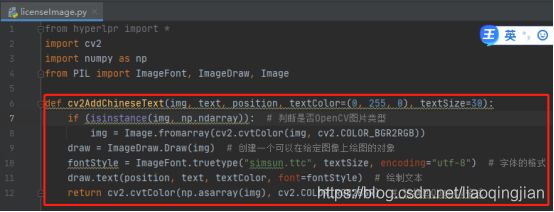
10.找到素材图片并且复制到项目中,然后读取图片

11.读取图片内车牌的识别度和车牌的号码以及车牌的位置

12.做一个判断,如果存在车牌信息的话就进行下一步操作

13.将车牌的识别度和车牌的号码以及车牌的位置分开
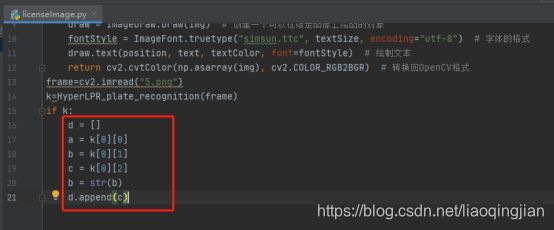
14.在车牌位置中循环
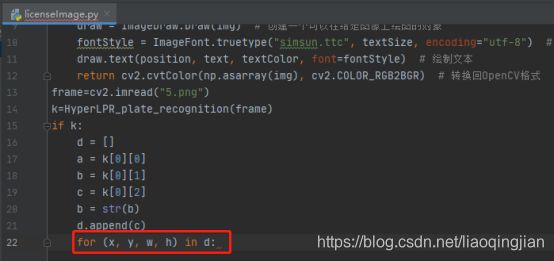
15.在车牌位置画矩形
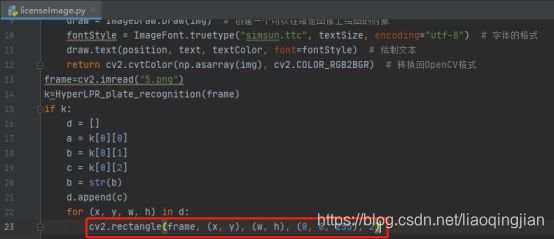
16.调用定义的函数来在图片上车牌号写进图片中
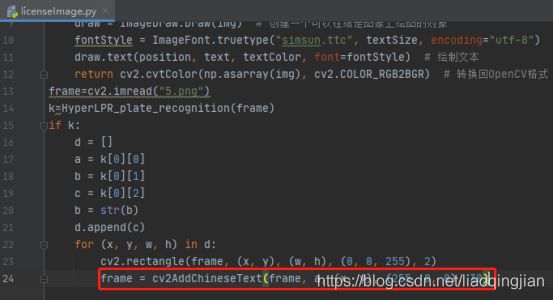
17.将图片中的识别度写进图片中,各参数依次是:图片,添加的文字,左上角坐标,字体,字体大小,颜色,字体粗细,cv2.FONT_HERSHEY_SIMPLEX:标准大小无衬线字体
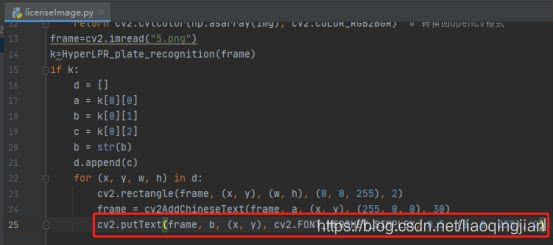
18.将图片展现出来,并且等待十秒
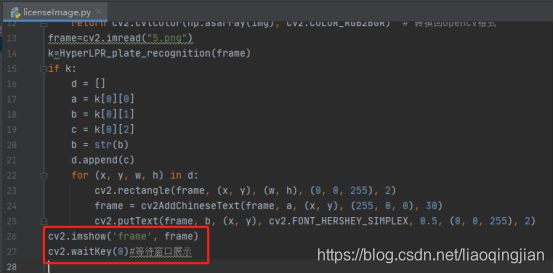
19.运行展现

完整代码展示
from hyperlpr import *#导入hyperlpr库,处理车牌识别
import cv2#导入CV2库,处理图片或视频,版本号为3.4.8.29
import numpy as np
from PIL import ImageFont, ImageDraw,Image
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img) # 创建一个可以在给定图像上绘图的对象
fontStyle = ImageFont.truetype("simsun.ttc", textSize, encoding="utf-8") # 字体的格式
draw.text(position, text, textColor, font=fontStyle) # 绘制文本
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR) # 转换回OpenCV格式
frame=cv2.imread("5.png")#读取图片
k=HyperLPR_plate_recognition(frame)#使用HyperLPR_plate_recognition函数识别图片内车牌号
print(k)
if k:
d = []
a = k[0][0]
b = k[0][1]
c = k[0][2]
b = str(b)
d.append(c)
for (x, y, w, h) in d:
cv2.rectangle(frame, (x, y), (w, h), (0, 0, 255), 2)
frame = cv2AddChineseText(frame, a, (x, y), (255, 0, 0), 30)
cv2.putText(frame, b, (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)#各参数依次是:图片,添加的文字,左上角坐标,字体,字体大小,颜色,字体粗细,cv2.FONT_HERSHEY_SIMPLEX:标准大小无衬线字体
cv2.imshow('frame', frame)
cv2.waitKey(10000)#等待窗口展示
车辆视频识别
1.重新创建一个项目,从File->New Project

2.项目名字可以自己取,这里我默认
3.开始创建的时候这里我们选择This Window,This Window和New Window的区别就是This Window覆盖原先的窗口、New Window是新打开一个窗口。

4.打开项目后右键点击pythonProjec3,新建一个licenseVideo.py文件

5.使用命令pip install hyperlpr下载识别车牌号码的python库
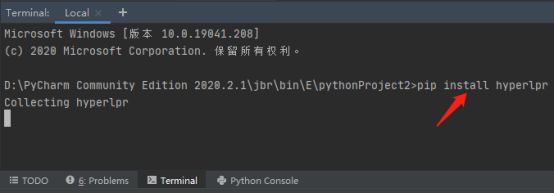
6.继续使用命令pip install opencv-python==3.4.8.29下载版本为3.4.8.29的opencv库

7.继续使用命令pip install pillow下载该python库
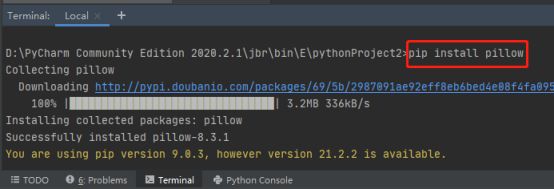
8.下载好这两个库后导入这四个库
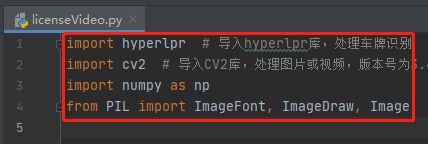
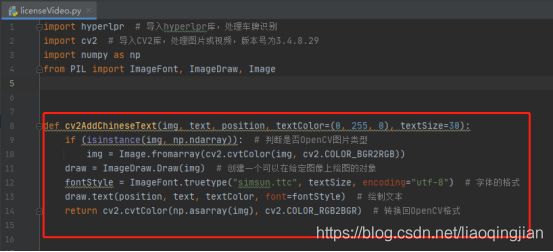
9.定义一个函数cv2AddChineseText,这个函数的目的是在图像上写出中文字符,该函数内的参数分别是图像、文本内容、像素位置,文本颜色,文本大小
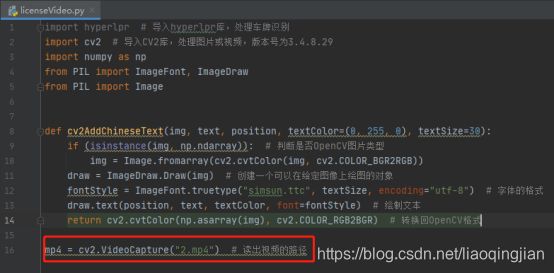
10.找到素材视频并且复制到项目中,然后读取视频

11.写一个while循环,看看能否正常读取图片

12.读取视频,第一个参数ret 为True 或者False,代表有没有读取到图片,第二个参数frame表示截取到一帧的图片

13.判断视频有没有正常读取
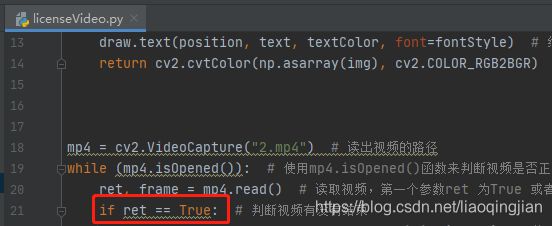
14.操作跟图片识别一样
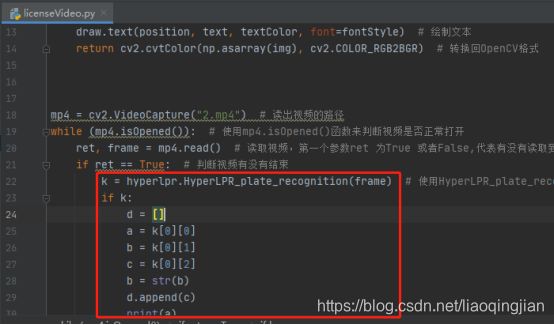
15.在每一帧图片中都进行画图操作,操作情况跟图片识别一样

16.展现每一帧图片以及增加一个中断操作
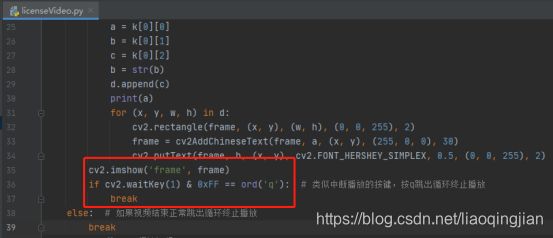
17.如果视频结束则跳出循环
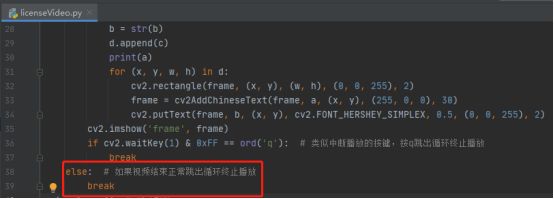
18.释放视频以及销毁窗口操作

19.运行展现

完整代码展示
import hyperlpr # 导入hyperlpr库,处理车牌识别
import cv2 # 导入CV2库,处理图片或视频,版本号为3.4.8.29
import numpy as np
from PIL import ImageFont, ImageDraw, Image
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img) # 创建一个可以在给定图像上绘图的对象
fontStyle = ImageFont.truetype("simsun.ttc", textSize, encoding="utf-8") # 字体的格式
draw.text(position, text, textColor, font=fontStyle) # 绘制文本
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR) # 转换回OpenCV格式
mp4 = cv2.VideoCapture("2.mp4") # 读出视频的路径
while (mp4.isOpened()): # 使用mp4.isOpened()函数来判断视频是否正常打开
ret, frame = mp4.read() # 读取视频,第一个参数ret 为True 或者False,代表有没有读取到图片,第二个参数frame表示截取到一帧的图片
if ret == True: # 判断视频有没有结束
k = hyperlpr.HyperLPR_plate_recognition(frame) # 使用HyperLPR_plate_recognition函数识别图片内车牌号
if k:
d = []
a = k[0][0]
b = k[0][1]
c = k[0][2]
b = str(b)
d.append(c)
print(a)
for (x, y, w, h) in d:
cv2.rectangle(frame, (x, y), (w, h), (0, 0, 255), 2)
frame = cv2AddChineseText(frame, a, (x, y), (255, 0, 0), 30)
cv2.putText(frame, b, (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'): # 类似中断播放的按键,按q跳出循环终止播放
break
else: # 如果视频结束正常跳出循环终止播放
break
mp4.release() # 释放视频
cv2.destroyAllWindows() # 将创建的所有的窗口销毁
到此结束,运行成功的小伙伴们拜托一键三连!!!
