数据结构(一)——链表与邻接表、栈与队列、KMP
前言
重学算法第3天,希望能坚持打卡不间断,从基础课开始直到学完提高课。
预计时长三个月内,明天再来!肝就完了
2月15日,day03 打卡
今日已学完y总的
算法基础课-2.1-第二章 数据结构(一)
共7题,知识点如下
链表与邻接表:
单链表、双链表
栈与队列:
模拟栈、模拟队列
单调栈、单调队列 :滑动窗口(题目名)
KMP:KMP字符串
暂时先囫囵吞枣过一遍 ,以后开始大量刷题再慢慢把没完全理解的补一补
算法早学晚学都得学,不如现在直接学。
欠下的迟早要还
链表与邻接表

上述方式太慢,一般用在面试中,笔试不用
数组表示方式

单链表
模板
// head存储链表头,e[]存储节点的值,ne[]存储节点的next指针,idx表示当前用到了哪个节点
int head, e[N], ne[N], idx;
// 初始化
void init()
{
head = -1;
idx = 0;
}
// 在链表头插入一个数a
void insert(int a)
{
e[idx] = a, ne[idx] = head, head = idx ++ ;
}
// 将头结点删除,需要保证头结点存在
void remove()
{
head = ne[head];
}
AcWing 826. 单链表
思路:
- 将x插入到头结点
先让红色指向head里面存的这个值,再让head指向红色点
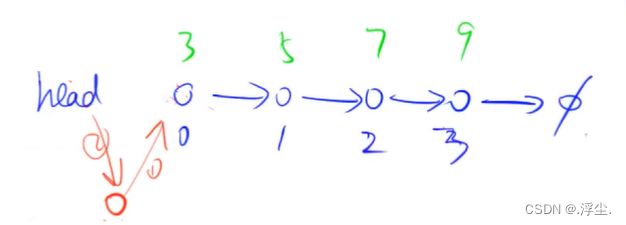
- 将x插到下标是k的点后面

- 将下标是k的点后面的点删掉
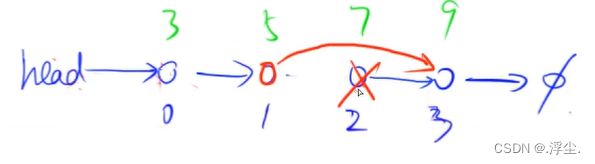
样例操作后的结果

#include 算法题不需要考虑内存泄露的问题,做项目才需要
双链表
模板
// e[]表示节点的值,l[]表示节点的左指针,r[]表示节点的右指针,idx表示当前用到了哪个节点
int e[N], l[N], r[N], idx;
// 初始化
void init()
{
//0是左端点,1是右端点
r[0] = 1, l[1] = 0;
idx = 2;
}
// 在节点a的右边插入一个数x
void insert(int a, int x)
{
e[idx] = x;
l[idx] = a, r[idx] = r[a];
l[r[a]] = idx, r[a] = idx ++ ;
}
// 删除节点a
void remove(int a)
{
l[r[a]] = l[a];
r[l[a]] = r[a];
}
AcWing 827. 双链表
思路:
-
初始化

-
在节点k的右边插入一个数x
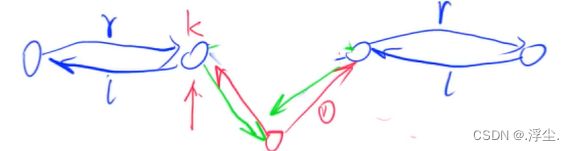
-
删除

#include 栈与队列
栈:先入后出
队列:先入先出
模板需要锻炼熟练度,多背多写(要理解+熟练)
记忆力 + 毅力(自制力)
栈和队列的操作
#include 模拟栈
模板
// tt表示栈顶
int stk[N], tt = 0;
// 向栈顶插入一个数
stk[ ++ tt] = x;
// 从栈顶弹出一个数
tt -- ;
// 栈顶的值
stk[tt];
// 判断栈是否为空
if (tt > 0)
{
}
AcWing 828. 模拟栈
思路:相出对应操作怎么处理直接写就行了
#include 模拟队列
模板
// hh 表示队头,tt表示队尾
int q[N], hh = 0, tt = -1;
// 向队尾插入一个数
q[ ++ tt] = x;
// 从队头弹出一个数
hh ++ ;
// 队头的值
q[hh];
// 判断队列是否为空
if (hh <= tt)
{
}
AcWing 829. 模拟队列
#include 单调栈
模板
常见模型:找出每个数左边离它最近的比它大/小的数
int tt = 0;
for (int i = 1; i <= n; i ++ )
{
while (tt && check(stk[tt], i)) tt -- ;
stk[ ++ tt] = i;
}
AcWing 830. 单调栈
思路:
暴力做法:找出i的左边比i小的第一个数
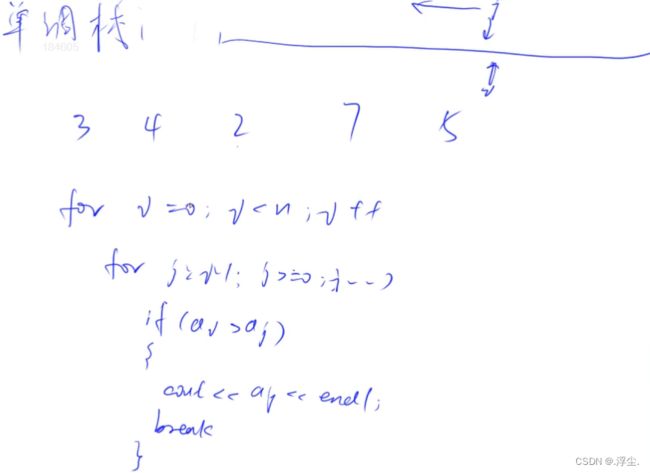
找性质

将所有离
i更远且有比它大的值都删掉,如图,1和2位置对应的点
stk1] > stk[2],且离i更远,删掉stk[1]
删掉所有这样的点,会得到一个单调递增序列
然后将
stk[tt](栈顶)所有比i所在值大的数都删掉(a[i])
直到slt[tt] < a[i]就找到了
#include 时间复杂度是
O(n)
虽然看着有两重循环,但每个数只会进栈一次,最多出栈一次,只有2N次操作,所以是O(n)
单调队列
模板
常见模型:找出滑动窗口中的最大值/最小值
int hh = 0, tt = -1;
for (int i = 0; i < n; i ++ )
{
while (hh <= tt && check_out(q[hh])) hh ++ ; // 判断队头是否滑出窗口
while (hh <= tt && check(q[tt], i)) tt -- ;
q[ ++ tt] = i;
}
AcWing 154. 滑动窗口
思路:
暴力是O(nk)
第一步:插入新元素
第二步:将划出去的从队尾弹出
依然是将逆序的全部删掉,形成单调递增序列
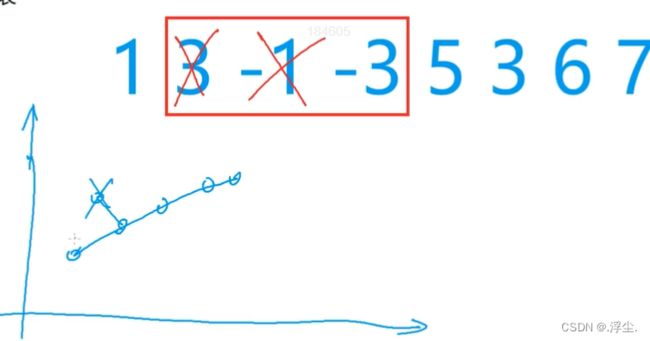
最小值就是最左边的点,
q[h][h] (队头)
最大值是一样的操作
怎么知道队首元素如何出列?
该题中
i是最右值下标,k是窗口范围
q[]中存的是下标
所以可以判断q[hh]是否超出了[i - k + 1,i]的范围
超出就把队头删掉
#include 思路总结:
先考虑暴力怎么做,再考虑把没用的元素删掉,再看有没有单调性,有就可以做优化。
取极值可以选左右两端点,找一个值可以用二分
KMP
朴素做法

kmp中
next数组的含义
对于某个点的
后缀 和 前缀 相等的长度最大是多少
红色线最少移动多少能继续匹配
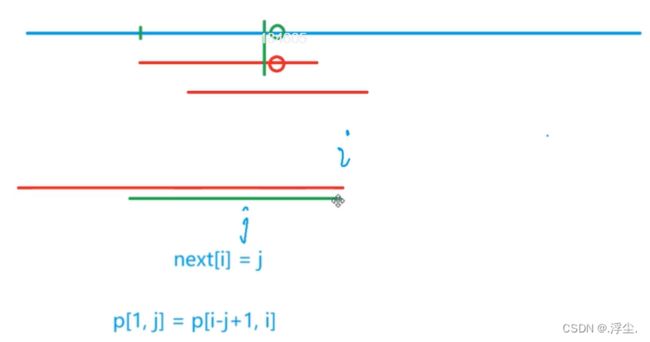
前后缀相等长度,所以下面是
next[j]
next[j]再与s[i]比看是否匹配,如果不匹配就接着找下一个next[j]
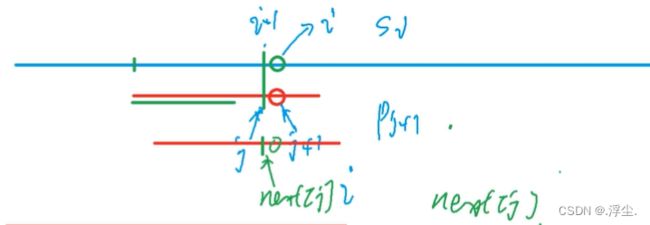
找next,看下一个是否匹配
模板
// s[]是长文本,p[]是模式串,n是s的长度,m是p的长度
求模式串的Next数组:
for (int i = 2, j = 0; i <= m; i ++ )
{
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j ++ ;
ne[i] = j;
}
// 匹配
for (int i = 1, j = 0; i <= n; i ++ )
{
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j ++ ;
if (j == m)
{
j = ne[j];
// 匹配成功后的逻辑
}
}
AcWing 831. KMP字符串
例子
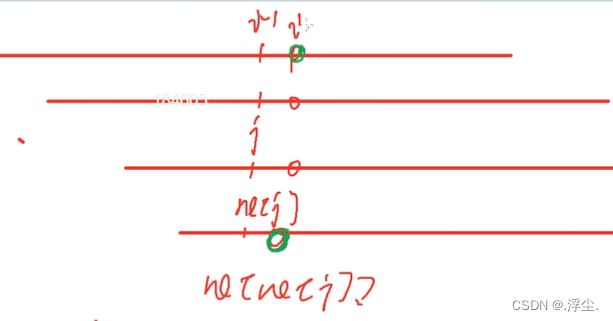
next[]是前后缀相等的 最大长度
当p[j+1] 与 S[i]不想等
就将j指到next[j]处,
如图 ,j此时 为next[6] = 4
因为是前后缀相同的最大长度,所以此时与原来的后半段值是相等的
不匹配的话接着往前跳,直到比完

#include 暂时不管了,以后遇到了kmp再补补
也不指望能一遍把所有算法学会,先过一遍,留个印象和笔记,以后遇到了再补对应的就好了