MYSQL-长事务和死锁
一、大事务
1、什么是大事务?
顾名思义就是运行时间比较长,长时间未提交的事务,也可以称之为大事务。这类事务往往会造成大量的阻塞和锁超时,容易造成主从延迟,要尽量避免使用长事务。
2、大事务一般会对数据库造成什么问题?
(1)死锁
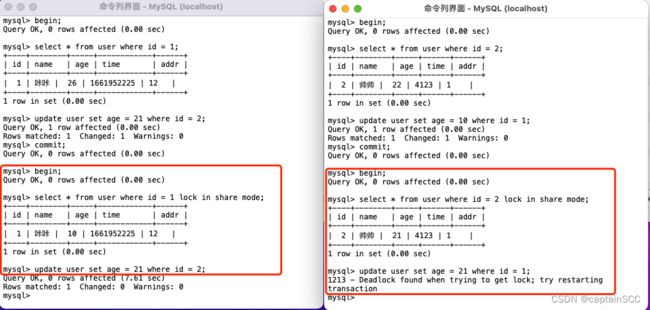
这时候,事务A在等待事务B释放id=2的行锁,而事务B在等待事务A释放id=1的行锁。 事务A和事务B在互相等待对方的资源释放,就是进入了死锁状态
首先我们知道,有两种策略可以处理死锁:
- 等待死锁超时。超时时间(innodb_lock_wait_timeout)默认是50s,这时间可以说真的是太长了,但是如果改小了吧,又可能会影响到本可以正常消除的死锁
- 死锁检测。死锁检测的配置默认是开启的。死锁检测就是每当一个事务被锁的时候,就要看看它所依赖的线程有没有被别人锁住,如此循环,最后判断是否出现了死锁
但是死锁检测可能会存在一个问题:
假如所有事务都要更新同一行的时候。每个新来的被堵住的线程,都要判断会不会由于自己的加入导致了死锁,这是一个时间复杂度是 O(n)的操作。假设有1000个并发线程要同时更新同一行,那么死锁检测操作就是100万这个量级 的。虽然最终检测的结果是没有死锁,但是这期间要消耗大量的CPU资源。因此,你就会看到 CPU利用率很高,但是每秒却执行不了几个事务。
(2)回滚记录占用大量存储空间,事务回滚时间长
在MySQL中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。
假设一个值从1被按顺序改成了2、3、4,在回滚日志里面就会有类似下面的记录。
当前值是4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的read-view。如图中看到的,在视图A、B、C里面,这一个记录的值分别是1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于read-view A,要得到1,就必须将当前值依次执行图中所有的回滚操作得到。
同时你会发现,即使现在有另外一个事务正在将4改成5,这个事务跟read-view A、B、C对应的 事务是不会冲突的。
你一定会问,回滚日志总不能一直保留吧,什么时候删除呢?答案是,在不需要的时候才删除。 也就是说,系统会判断,当没有事务再需要用到这些回滚日志时,回滚日志会被删除。
什么时候才不需要了呢?就是当系统里没有比这个回滚日志更早的read-view的时候,换一种说法就是在这些事物提交之后。
(3)执行时间长,容易造成主从延迟
因为主库上必须等事务执行完成才会写入binlog,再传给备库。所以,如果一个主库上的语句执行10分钟,那这个事务很可能就会导致从库延迟10分钟
3、解决方案
(1)基于两阶段锁协议
在InnoDB事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放
基于两阶段锁协议我们可以做这样的优化:
如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放
(2)基于事务的隔离级别
我们知道MySQL的事务隔离级别默认是可重复读,在这个隔离级别下写数据的时候会有这些问题:
- 如果有索引(包括主键索引)的时候,以索引列为条件更新数据,会存在间隙锁、行锁、下一键锁的问题,从而锁住一些行
- 如果没有索引,更新数据时会锁住整张表
但是如果把隔离级别改为读提交就不存在这两个问题了,每次写数据只会锁一行
但同时,你要解决可能出现的数据和日志不一致问题,需要把binlog格式设置 为row
关于为什么要设置binlog可以参考这篇文章为什么要把MySQL的binlog格式修改为row
(3)其它
- 一些只读的操作就没有必要开启事物了
- 通过SETMAX_EXECUTION_TIME命令, 来控制每个语句执行的最长时间,避免单个语句意外执行太长时间
- 监控 information_schema.Innodb_trx表,设置长事务阈值,超过就报警/或者kill
- 在业务功能测试阶段要求输出所有的general_log,分析日志行为提前发现问题
- 设置innodb_undo_tablespaces值,将undo log分离到独立的表空间。如果真的出现大事务导致回滚段过大,这样设置后清理起来更方便。
4、查询大事务
- 查询执行时间超过10秒的事务
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>10

- 查看事务的运行时间
mysql> select t.*,to_seconds(now())-to_seconds(t.trx_started) idle_time from INFORMATION_SCHEMA.INNODB_TRX t \G
*************************** 1. row ***************************
trx_id: 6168
trx_state: RUNNING
trx_started: 2019-09-16 11:08:27
trx_requested_lock_id: NULL
trx_wait_started: NULL
trx_weight: 3
trx_mysql_thread_id: 11
trx_query: NULL
trx_operation_state: NULL
trx_tables_in_use: 0
trx_tables_locked: 1
trx_lock_structs: 3
trx_lock_memory_bytes: 1136
trx_rows_locked: 2
trx_rows_modified: 0
trx_concurrency_tickets: 0
trx_isolation_level: REPEATABLE READ
trx_unique_checks: 1
trx_foreign_key_checks: 1
trx_last_foreign_key_error: NULL
trx_adaptive_hash_latched: 0
trx_adaptive_hash_timeout: 0
trx_is_read_only: 0
trx_autocommit_non_locking: 0
idle_time: 170复制代码- 查看长事务执行的最后一条sql
mysql> select now(),(UNIX_TIMESTAMP(now()) - UNIX_TIMESTAMP(a.trx_started)) diff_sec,b.id,b.user,b.host,b.db,d.SQL_TEXT from information_schema.innodb_trx a inner join
-> information_schema.PROCESSLIST b
-> on a.TRX_MYSQL_THREAD_ID=b.id and b.command = 'Sleep'
-> inner join performance_schema.threads c ON b.id = c.PROCESSLIST_ID
-> inner join performance_schema.events_statements_current d ON d.THREAD_ID = c.THREAD_ID;
+---------------------+----------+----+------+-----------+--------+-----------------------------------------------------+
| now() | diff_sec | id | user | host | db | SQL_TEXT |
+---------------------+----------+----+------+-----------+--------+-----------------------------------------------------+
| 2019-09-16 14:06:26 | 54 | 17 | root | localhost | testdb | select * from stu_tb where stu_id = 1006 for update |
+---------------------+----------+----+------+-----------+--------+-----------------------------------------------------+复制代码上述结果中diffsec和上面idletime表示意思相同,都是代表此事务持续的秒数。SQLTEXT表示该事务刚执行的SQL。但是呢,上述语句只能查到事务最后执行的SQL,我们知道,一个事务里可能包含多个SQL,那我们想查询这个未提交的事务执行过哪些SQL,是否可以满足呢,答案是结合eventsstatements_history系统表也可以满足需求。
- 查询事务执行过的所有SQL
mysql> SELECT
-> ps.id 'PROCESS ID',
-> ps.USER,
-> ps.HOST,
-> esh.EVENT_ID,
-> trx.trx_started,
-> esh.event_name 'EVENT NAME',
-> esh.sql_text 'SQL',
-> ps.time
-> FROM
-> PERFORMANCE_SCHEMA.events_statements_history esh
-> JOIN PERFORMANCE_SCHEMA.threads th ON esh.thread_id = th.thread_id
-> JOIN information_schema.PROCESSLIST ps ON ps.id = th.processlist_id
-> LEFT JOIN information_schema.innodb_trx trx ON trx.trx_mysql_thread_id = ps.id
-> WHERE
-> trx.trx_id IS NOT NULL
-> AND ps.USER != 'SYSTEM_USER'
-> ORDER BY
-> esh.EVENT_ID;
+------------+------+-----------+----------+---------------------+------------------------------+-----------------------------------------------------+------+
| PROCESS ID | USER | HOST | EVENT_ID | trx_started | EVENT NAME | SQL | time |
+------------+------+-----------+----------+---------------------+------------------------------+-----------------------------------------------------+------+
| 20 | root | localhost | 1 | 2019-09-16 14:18:44 | statement/sql/select | select @@version_comment limit 1 | 60 |
| 20 | root | localhost | 2 | 2019-09-16 14:18:44 | statement/sql/begin | start transaction | 60 |
| 20 | root | localhost | 3 | 2019-09-16 14:18:44 | statement/sql/select | SELECT DATABASE() | 60 |
| 20 | root | localhost | 4 | 2019-09-16 14:18:44 | statement/com/Init DB | NULL | 60 |
| 20 | root | localhost | 5 | 2019-09-16 14:18:44 | statement/sql/show_databases | show databases | 60 |
| 20 | root | localhost | 6 | 2019-09-16 14:18:44 | statement/sql/show_tables | show tables | 60 |
| 20 | root | localhost | 7 | 2019-09-16 14:18:44 | statement/com/Field List | NULL | 60 |
| 20 | root | localhost | 8 | 2019-09-16 14:18:44 | statement/com/Field List | NULL | 60 |
| 20 | root | localhost | 9 | 2019-09-16 14:18:44 | statement/sql/select | select * from stu_tb | 60 |
| 20 | root | localhost | 10 | 2019-09-16 14:18:44 | statement/sql/select | select * from stu_tb where stu_id = 1006 for update | 60 |
+------------+------+-----------+----------+---------------------+------------------------------+-----------------------------------------------------+------+复制代码从上述结果中我们可以看到该事务从一开始到现在执行过的所有SQL,当我们把该事务相关信息都查询清楚后,我们就可以判定该事务是否可以杀掉,以免影响其他事务造成等待现象。
5、查询事务阻塞
- 查询被阻塞事务
在这里稍微拓展下,长事务极易造成阻塞或者死锁现象,通常情况下我们可以首先查询 sys.innodblockwaits 视图确定有没有事务阻塞现象:
#假设一个事务执行 select * from stu_tb where stu_id = 1006 for update
#另外一个事务执行 update stu_tb set stu_name = 'wang' where stu_id = 1006
mysql> select * from sys.innodb_lock_waits\G
*************************** 1. row ***************************
wait_started: 2019-09-16 14:34:32
wait_age: 00:00:03
wait_age_secs: 3
locked_table: `testdb`.`stu_tb`
locked_index: uk_stu_id
locked_type: RECORD
waiting_trx_id: 6178
waiting_trx_started: 2019-09-16 14:34:32
waiting_trx_age: 00:00:03
waiting_trx_rows_locked: 1
waiting_trx_rows_modified: 0
waiting_pid: 19
waiting_query: update stu_tb set stu_name = 'wang' where stu_id = 1006
waiting_lock_id: 6178:47:4:7
waiting_lock_mode: X
blocking_trx_id: 6177
blocking_pid: 20
blocking_query: NULL
blocking_lock_id: 6177:47:4:7
blocking_lock_mode: X
blocking_trx_started: 2019-09-16 14:18:44
blocking_trx_age: 00:15:51
blocking_trx_rows_locked: 2
blocking_trx_rows_modified: 0
sql_kill_blocking_query: KILL QUERY 20
sql_kill_blocking_connection: KILL 20复制代码- 查询阻塞事务
上述结果显示出被阻塞的SQL以及锁的类型,更强大的是杀掉会话的语句也给出来了。但是并没有找到阻塞会话执行的SQL,如果我们想找出更详细的信息,可以使用下面语句:
SELECT
b.trx_query,
c.trx_query,
c.OBJECT_SCHEMA,
a.BLOCKING_EVENT_ID,
(select sql_text from performance_schema.events_statements_current where event_id=a.BLOCKING_EVENT_ID),
OBJECT_NAME,
INDEX_NAME
FROM
performance_schema.data_lock_waits a
LEFT JOIN
information_schema.INNODB_TRX b ON a.REQUESTING_ENGINE_TRANSACTION_ID = b.trx_id
LEFT JOIN
information_schema.INNODB_TRX c ON a.BLOCKING_ENGINE_TRANSACTION_ID = c.trx_id
LEFT JOIN
performance_schema.data_locks c ON a.REQUESTING_ENGINE_LOCK_ID = c.ENGINE_LOCK_ID;
6.监控长事务
现实工作中我们需要监控下长事务,定义一个阈值,比如说30s 执行时间超过30s的事务即为长事务,要求记录并告警出来,提醒管理人员去处理。下面给出监控脚本,各位可以参考下,根据需求改动使用:
#!/bin/bash
# -------------------------------------------------------------------------------
# FileName: long_trx.sh
# Describe: monitor long transaction
# Revision: 1.0
# Date: 2019/09/16
# Author: wang
/usr/local/mysql/bin/mysql -N -uroot -pxxxxxx -e "select now(),(UNIX_TIMESTAMP(now()) - UNIX_TIMESTAMP(a.trx_started)) diff_sec,b.id,b.user,b.host,b.db,d.SQL_TEXT from information_schema.innodb_trx a inner join
information_schema.PROCESSLIST b
on a.TRX_MYSQL_THREAD_ID=b.id and b.command = 'Sleep'
inner join performance_schema.threads c ON b.id = c.PROCESSLIST_ID
inner join performance_schema.events_statements_current d ON d.THREAD_ID = c.THREAD_ID;" | while read A B C D E F G H
do
if [ "$C" -gt 30 ]
then
echo $(date +"%Y-%m-%d %H:%M:%S")
echo "processid[$D] $E@$F in db[$G] hold transaction time $C SQL:$H"
fi
done >> /tmp/longtransaction.txt复制代码简单说明一下,这里的-gt 30是30秒钟的意思,只要超过了30秒钟就认定是长事务,可以根据实际需要自定义。将该脚本加入定时任务中即可执行。