文本向量化与文本处理(含详细代码)
提示:本文的数据集是IMDB数据集
文章目录
- 前言
- 文本向量化
-
- one-hot 编码
-
- 单词级的one-hot编码示例
- 字符级的one-hot编码示例
- 使用keras实现单词级的one-hot编码
- 词嵌入编码
-
- 使用Embedding层学习词嵌入
- 使用预训练的词嵌入
- 在keras模型中使用GloVe嵌入
前言
深度学习用于自然语言处理是将模式识别应用于单词、句子和段落。这些模型不能像人类理解文字一样去理解文本,知识映射出了书面语言的统计结果,但是这也足以解决许多简单的问题了。
深度学习不能像人类一样去理解文本,那么它是如何处理文本的呢?
模型不会接受原始文本作为输入,因为它只会处理张量。因此需要将文本转换为张量,再将转换好的张量作为输入传递给模型。那么如何将文本转换为张量呢?
文本向量化
文本转换为向量有多种形式:
可以将文本分割成单词,再将每个单词转换为一个向量;
可以将文本分割为字符,再将字符转换为向量;
也可以提取单词或字符的n-gram,并将每个n-gram转换为一个向量。n-gram是多个连续单词或字符的集合。
关于n-gram,看下面的例子:
考虑句子“The cat sat on the mat.”。它可以被分解为以下二元语法(2-grams)的集合。
{“The”, “The cat”, “cat”, “cat sat”, “sat”, “sat on”, “on”, “on the”, “the”, “the mat”, “mat”}
这个句子也可以被分解为以下三元语法(3-grams)的集合。
{“The”, “The cat”, “cat”, “cat sat”, “The cat sat”,“sat”, “sat on”, “on”, “cat sat on”, “on the”, “the”,“sat on the”, “the mat”, “mat”, “on the mat”}
编码方法此处介绍两种:one-hot编码、标记嵌入编码
one-hot 编码
one-hot编码是转换为向量的最常用、最基本的方法。它将每个单词与唯一的整数索引相关联,然后将这个整数索引i转换为长度为N的二进制向量(N是词表大小),这个向量只有第i个元素为1,其余元素均为0。
单词级的one-hot编码示例
import numpy as np
# 列举的初始数据
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
# 构建数据中所有标记的索引
token_index = {}
for sample in samples:
for word in sample.split():
if word not in token_index:
token_index[word] = len(token_index) + 1
#为每个唯一单词指定唯一的索引,并且没有索引编号为0的单词
#只考虑每个样本前max-length个单词
max_length = 10
results = np.zeros(shape=(len(samples),
max_length,
max(token_index.values()) + 1))
for i, sample in enumerate(samples):
for j, word in list(enumerate(sample.split()))[:max_length]:
index = token_index.get(word)
#将结果保存在results中
results[i, j, index] = 1.
字符级的one-hot编码示例
import string
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
# 所有可打印的ASCII码
characters = string.printable
token_index = dict(zip(range(1, len(characters) + 1), characters))
max_length = 50
results = np.zeros((len(samples), max_length, max(token_index.keys()) + 1))
for i, sample in enumerate(samples):
for j, character in enumerate(sample):
index = token_index.get(character)
results[i, j, index] = 1
使用keras实现单词级的one-hot编码
keras的内置函数可以对原始文本数据进行单词级或字符级的one-hot编码。只考虑字符的前N个单词是为了避免处理非常大的输入向量空间。
from keras.preprocessing.text import Tokenizer
samples = ['The cat sat on the mat.', 'The dog ate my homework.']
# 设置分词器,只考虑前1000个最常见的单词
tokenizer = Tokenizer(num_words=1000)
tokenizer.fit_on_texts(samples)
# 将字符串转换为整数索引组成的列表
sequences = tokenizer.texts_to_sequences(samples)
# 可以直接得到one-hot二进制表示,分词器也支持除one-hot编码外的其它向量化模式
one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary')
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
词嵌入编码
词嵌入编码是地位的浮点数向量编码形式,词嵌入是从数据中学习得到的,常见的词向量维度是256,512或1024。而作为对比的one-hot编码的词向量维度通常为20000或者更高,因此词向量可以将更多信息塞入到更低的维度中。
词嵌入有两种方法:
1、完成主任务的同时学习词嵌入,在这种情况下,一开始是随机的词向量,然后对这些词向量进行学习,其学习方式与学习神经网络的权重相同。
2、正在不同于待解决的机器学习任务上预计算好词嵌入,然后将其加载到模型中。这些词嵌入叫做预训练词嵌入。
使用Embedding层学习词嵌入
要将一个词与一个密集向量相关联,最简单的方法就是随机选择向量,这种方法的问题在于,得到的嵌入空间没有任何结构。
抽象点来说,词向量之间的几何关系应该表示这些词之间的语义关系。词嵌入的作用应该是将人类的语言映射到几何空间中。
合理的做法是每个新任务都学习一个新的嵌入空间,幸运的是,反向传播让这种学习变得很简单,而keras使其变得更简单,我们要做的就是学习一个层的权重,这个层就是embedding层。
一、将一个Embedding层实例化:
from keras.layers import Embedding
enbedding_layer=Embedding(1000,64)
embedding层至少需要两个参数,标记的个数此处为1000,嵌入的维度此处为64。
二、加载IMDB数据,准备用于Embedding层
from keras.datasets import imdb
from keras.layers import preprocessing
# 特征单词个数
max_features = 10000
maxlen = 20
# 将数据加载为整数列表
(x_train, y_train), (x_test, y_test) = imdb.load_data(
num_words=max_features)
# 将整数列表转换为形状为(samples,maxlen)的二维整数张量
x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
三、在IMDB数据上使用Embedding层和分类器
from keras.models import Sequential
from keras.layers import Flatten, Dense, Embedding
model = Sequential()
model.add(Embedding(10000, 8, input_length=maxlen))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
model.summary()
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_split=0.2)
使用预训练的词嵌入
有时候可用的训练数据很少,无法完成特定任务的词嵌入,那么应该怎么办呢?
可以从预计算的嵌入空间中加载嵌入向量,而不是在解决问题的同时学习词嵌入。在自然语言处理中使用预训练的词嵌入,其背后的原理与图像分类中使用预训练的卷积神经网络是一样的,没有足够的数据来自己学习真正强大的特征,但是需要的特征应该是非常通用的,这样就可以重复使用其他问题上学到的特征。
预训练的词嵌入数据库有许多,常用的有:word2vec、GloVe等。
在keras模型中使用GloVe嵌入
1、下载IMDB数据的原始文本
import os
imdb_dir = '/Users/fchollet/Downloads/aclImdb'
train_dir = os.path.join(imdb_dir, 'train')
labels = []
texts = []
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type)
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname))
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
2、对IMDB数据进行分词
对文本进行分词,将其划分为训练集和验证集。本文将训练数据限定为前200个样本,因此在读取200个样本后对电影评论进行分类。
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
# 在100个单词后截断评论
maxlen = 100
# 在200个样本上训练
training_samples = 200
#在10000个样本上进行验证
validation_samples = 10000
# 只考虑数据集中前10000个最常见单词
max_words = 10000
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
data = pad_sequences(sequences, maxlen=maxlen)
labels = np.asarray(labels)
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
# 打乱数据集,因为所有负面评论是在前面的
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
x_train = data[:training_samples]
y_train = labels[:training_samples]
x_val = data[training_samples: training_samples + validation_samples]
y_val = labels[training_samples: training_samples + validation_samples]
3、下载GloVe词嵌入
打开 https://nlp.stanford.edu/projects/glove,下载 2014 年英文维基百科的预计算嵌入。这是一个 822 MB 的压缩文件,文件名是glove.6B.zip,里面包含 400 000 个单词(或非单词的标记)的 100 维嵌入向量的解压文件。
4、对嵌入进行预处理
我们对解压后的文件进行解析,构建一个将单词映射为其向量表示的索引。
解析GloVe词嵌入文件程序段:
glove_dir = '/Users/fchollet/Downloads/glove.6B'
embeddings_index = {}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'))
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))
准备GloVe词嵌入矩阵
embedding_dim = 100
embedding_matrix = np.zeros((max_words, embedding_dim))
for word, i in word_index.items():
if i < max_words:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
5、定义模型
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
6、在模型中加载GloVe嵌入
embedding层只有一个权重矩阵,是一个二维的浮点数矩阵,其中每个元素i是与索引i相关联的词向量。将准备好的GloVe矩阵加载到embedding层中,即模型的第一层。
将预训练的词嵌入加载到embedding层中的代码:
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
这里需要冻结embedding层,将参数trainable属性设置为False。
7、模型的训练与评估
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_data=(x_val, y_val))
model.save_weights('pre_trained_glove_model.h5')
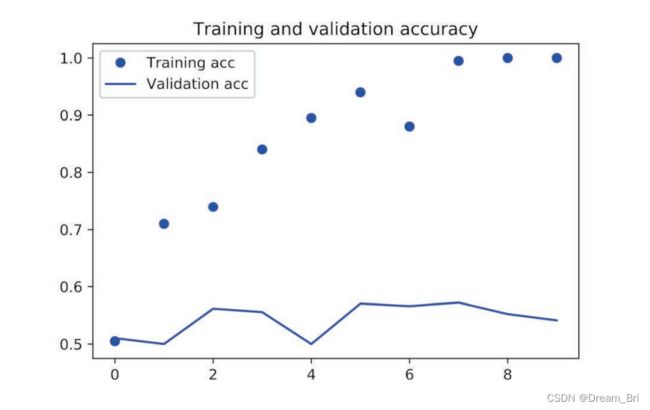
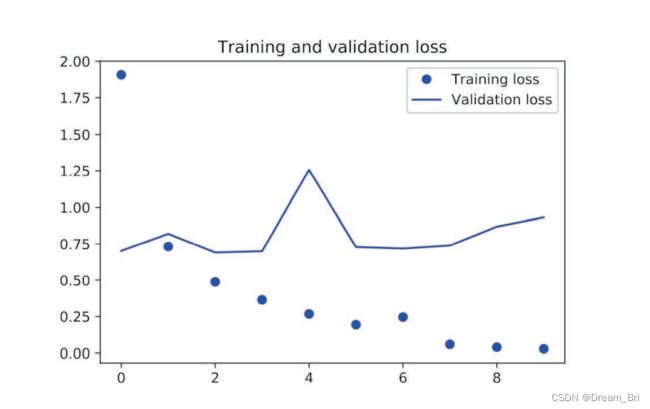
绘制模型的结果代码如下:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
8、结果展示
使用预训练嵌入时的训练损失和验证损失
 使用预训练嵌入时的训练精度和验证精度
使用预训练嵌入时的训练精度和验证精度