算法分析与设计 学习笔记
《算法分析与设计》学习笔记
- 第一章 算法概述及复杂性理论
-
- 一,问题
- 二.算法的概念
- 三,算法的正确性
- 四,算法的效率
- 五,问题的下界
- 第二章 算法的分析方法
-
- 1概率分析
- 2.合计方法
-
- 2.1合计方法
- 2.2记账方法
- 2.3势能方式
- 3.实验分析
- 第三章:递归
-
- 一,算法思想
-
- 递归的定义:
- 递归的基本思想:
- 递归算法的基本设计步骤
- 设计递归算法需要注意以下几个问题?
- 二,选择排序
- 选择排序的定义
- 选择排序的过程
- 递归方程
- 三,生成排列
-
- 问题描述:
-
- 想法一:固定位置放元素
- 想法二:固定元素找位置
- 四,递归方程的求解
-
- 公式法
- 第四章 分治法
-
- 一,算法思想
-
- 分治策略
- 分治算法总体思想
- 分治法的适用条件
- 分治法的基本步骤
- 二,二分查找
-
- 找伪币问题
- 找伪币问题的推广:二分查找
- 三,快速排序
-
- 快速排序的进一步思考
- 四,归并排序
-
- 算法描述:
- 五,覆盖残缺棋盘
- 六,大整数乘法
- 七,矩阵乘法
- 第五章 动态规划法
-
- 一,引言
《算法分析与设计》学习笔记
第一章 算法概述及复杂性理论
一,问题
在日常生活中碰到的许多实际性问题,都涉及到如何选取一个目标
在满足一定约束条件下,是目标达到最优,即f(x) x包含于S
最大值(最小值)问题,别的问题
目标函数
解空间与约束条件
可行解与不可行解
最优解和近似解
问题实例与问题规模
问题的分类:
1.可计算问题
2.困难问题
3.p np npc
二.算法的概念
算法:
解决问题的一种方法或一个过程,是一个由若干运算或指令组成的有穷序列
算法-问题:
求解问题可以看作是输入实例与输出之间函数
算法的特点:
输入 一个算法有零个或多个输入
输出 一个算法有一个或多个输出
确定性
可行性
有穷性
算法的描述:
伪代码
流程图
程序设计语言
自然语言
三,算法的正确性
正确的算法:
对于任意一个输入,算法能得到一个正确的输出
循环不变量:
与程序变量有关的一个语句,他在循环刚开始前,以及在循环的每个迭代执行后为真,特别是在循环结束后,仍然为真。
利用算法不变量检验算法的正确性。
四,算法的效率
算法效率的分析:指的是算法求解一个问题所需要的时间与空间
时间资源与空间资源
计算模型
Turing机 以及RAM(随机存储器)等
算法时间资源的估算
算法执行基本运算(或步数)的数目
度量一个算法运行时间的三种方式:
最好形式时间复杂度
最坏形式时间复杂度
平均形式时间复杂度
三种情况的比较:
最坏情形是任何规模为的问题实例运行时间的上界,即任何规模为的实例,其运行时间都不会超过最坏的情形的运行时间,知道最坏情形运行时间后,我们就知道算法最差到什么程度
对某些算法,最坏情形经常发生,例如在某个数据库中查询不存在的某条数据就是最坏的情形
平均情形有时跟最坏情形差不多
算法的时间复杂度取决于主要项
算法的效率主要取决于算法本身,与计算模型(例如计算机)无关,这样可以分析算法的运行时间,从而比较出算法之间的快慢
五,问题的下界
问题的下界:,即任何一种算法解决一个问题所必需的最小运行时间
假定一个问题的下界为F(n),而解决当前问题的最好算法为A,其最坏的时复杂度为W(n)
如果F(n)= W(n)则A为最优算法
第二章 算法的分析方法
1概率分析
平均案例分析决定算法运行平均时间
期望运行时间往往是所有n个实例运行时间的平均
平均时间分析往往需要对事件的先验概率有一个较好估计
精确的时间复杂度分析往往耗时耗力
如果你对平均情况更为感兴趣,那么可以考虑使用概率分析,并在这一过程中,认为每种情况都可能的发生
2.合计方法
分摊分析:
分摊分析:执行一系列数据结构操作所需要的时间是对所执行的所有操作的平均值
分摊分析与平均案例分析的不同之处是在于不涉及概率
摊销分析可确保在最坏情况下每项操作的平均性能
在运行分摊操作分析过程中存储的代价是用于分析,并没有实际意义,不能出现在最终代码中
2.1合计方法
在聚合方法中,我们考虑对所有的n种可能的情况的最差时间进行加和,那么平均时间就是总时间除以n
注意,即使每种操作序列中有不同种类的操作分摊代价也是对每个操作来说的
2.2记账方法
思想:为不同的操作分配不同的费用,其中某些操作的费用高于或低于实际费用,我们对这一项业务收取的额外费用称为摊余代价
须小心选择摊销的经营成本,以保证与数据结构相关的总贷款(存款)始终为非负

2.3势能方式
思想:将预先支付的代价视为潜在能量(势能),能为未来的操作支付能量
从初识的数据结构D0开始,对于i=1,2,…n,令ci为第i个操作的代价,Di为第Di-1个数据结构通过第i个操作得到的代价,Di为第Di-1个数据结构通过第i个操作得到的数据结构
势能函数Φ将每个数据结构Di映射为一个实数Φ(D1)这隐性地与D1建立了联系
3.实验分析
生成测试数据
实现算法
结果分析
实验分析往往用于复杂算法或随机算法
第三章:递归
一,算法思想
递归的定义:
计算机,数学,运筹等领域经常使用的最强大的解决问题的方法之一,它用一种简单的方式来解决那些用其他方法解起来可能很复杂的问题,也就说有些问题用递归算法来求解,则变得简单,而且容易理解。
递归的基本思想:
把一个问题划分成为一个或者多个规模更小的子问题,然后用同样的方式解规模更小的子问题。
递归算法的基本设计步骤
找到问题的初始条件(递归出口),即当问题规模小到某个值时,该问题就会变得简单,能够直接求解。
设计一个策略,用于将一个问题划分为一个或多个一步步接近递归出口的相似的规模更小的子问题
蒋所解决的各个小问题的解组合起来,即可得到原问题的解
设计递归算法需要注意以下几个问题?
如何使定义的问题规模逐步缩小,而且始终保持同一问题的类型?
每个递归求解的问题其规模如何缩小?
多大规模的问题可作为递归出口?
随着问题规模的缩小,能到达递归的出口吗?
二,选择排序
选择排序的定义
基本思想就像排列手中的扑克牌一样,
把所有的牌摊开,放在桌子上,伸出左手,开始为空,准备拿牌
将桌上最小的牌抬起,并把它插到左手所握牌的最右边
重复步骤(2),直到桌上所有牌都拿在你的左手上,此时左手上所握得牌便是排好得牌
选择排序的过程

递归方程
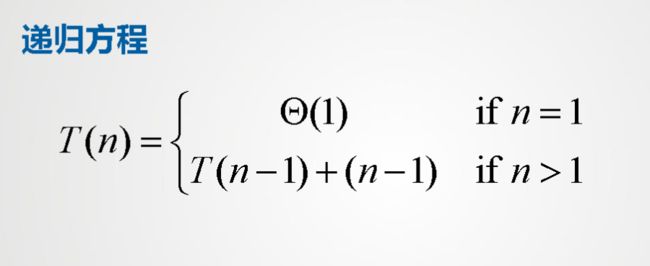
三,生成排列
问题描述:
生成{1,2…n}的所有n!个序列
想法一:固定位置放元素
假设我们能够生成n-1个元素的所有序列,我们可以得到如下算法:
1.生成元素{2,3,…n}的所有序列,并且将元素1放到每个序列的开头
2.接着,生成元素{1,3…n}的所有排列,并将数字2放在每个序列的开头
3.重复这个过程,直到元素{2,3…n-1}的所有排列都产生,并将元素n放到每个序列的开头
算法时间复杂度分析:

想法二:固定元素找位置
1.首先,我们把n放在的位置p【1】上,并且用子数组p【2…n】来产生前n-1个数的排列
2.接着,我们将n放在p【2】上,并且用子数组p【1】和p【3…n】来产生前n-1个数的排列
3.然后,我们将n放在p【3】上,并且用子数组p【1…2】和p【4…n】来产生前n-1个数的排列
4.重复上述的过程我们将n放在p【n】上,并且用子数组p【1…n】来产生前n-1个数的排列
算法的时间复杂度分析:

四,递归方程的求解
算法运行时间复杂度主要由关于问题规模的高阶项决定,因此当我们实际描述并解决一个递归方程时候,我们可以忽略递归出口,顶,底等技术细节

公式法
对于下列形式的递归方程
T(n) = aT(n/b)+f(n)
其中a>=1,b>1是常数,f(a) = aT(n/b)+f(n)
其中a>=1 b>1是常数 f(n)是一个渐近正函数,可以使用公式法(master method)方便快捷的求得递归方程得解
将一个规模为n的问题,划分为a个规模为n/b的子问题,其中a和b为正常数,分别递归的解决a个子问题,解每个子问题所需要时间的T(n/b)划分原问题和合并子问题的解所需要的时间由f(n)决定
第四章 分治法
一,算法思想
分治策略

分治算法总体思想
对这k个子问题分别求解,如果子问题的规模仍然不够小,则在划分为k个子问题,如此递归的进行下去,直到问题规模足够小,很容易求出其解为止
将求出的小规模的问题的解合并为一个更大规模的问题的解,自底向上逐步求出原来问题的解
分治法的适用条件
分治法所能解决的问题一般具有以下几个特征:
该问题的规模缩小到一定的程度就可以容易地解决。
该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质
利用该问题分解出的子问题的解可以合并为该问题的解。
该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题
分治法的基本步骤

人们从大量实践中发现,在用分治法设计算法时候,最好使子问题的规模大致相同,即将一个问题分成大小相等的k个子问题的处理方法是行之有效的,这种子问题规模大致相等的做法是出自一种平衡子问题的思想,他几乎总是比子问题规模不等的做法要好
二,二分查找
找伪币问题


找伪币问题的推广:二分查找
给定已按升序排序好的n个元素a【0:n-1】,现在要在这n个元素中找出一个特定元素x,分析:
该问题的规模缩小到一定的程度就可以容易的解决
该问题可以分解为若干个规模较小的相同问题
分解出的子问题解可以合并为原问题的解
分解出的各个子问题是相互独立的

三,快速排序
该问题是将n个元素排成非递减顺序
解题思路:快速排序基于分治思想
Divide:分割A【p…r】成为2个子集合(可以为空)A【p…q-1】和A【q+1…r】使得A【p…q-1】的每个元素都小于等于A【q】,A【q+1…r】中的每个元素都大于等于A【q】索引q作为分割点
conquer:通过递归调用快速排序对A【p…q-1】和A【q+1…r】排序
combine:每个子集合排序完成之后,整个数组的排序也完成



快速排序的进一步思考

四,归并排序
该问题是将n个元素排成非递减序列
算法描述:
若n位1,算法终止;否则,将这一元素集合分割成两个或更多个子集合,对每一个子集合分别排序,然后将排好序的子集合归并为一个集合

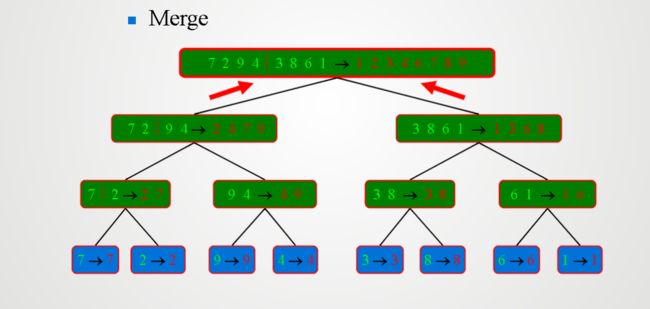
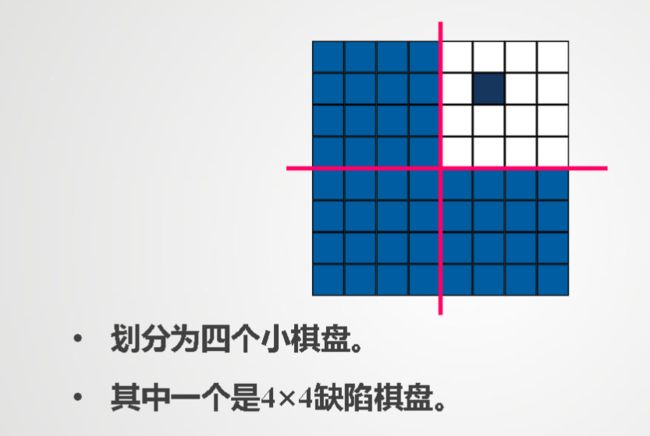
五,覆盖残缺棋盘
A是一个n×n的棋盘,n为2的整数幂

残缺棋盘:
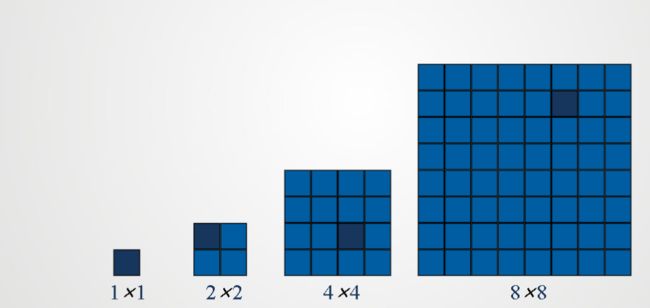
三格板:

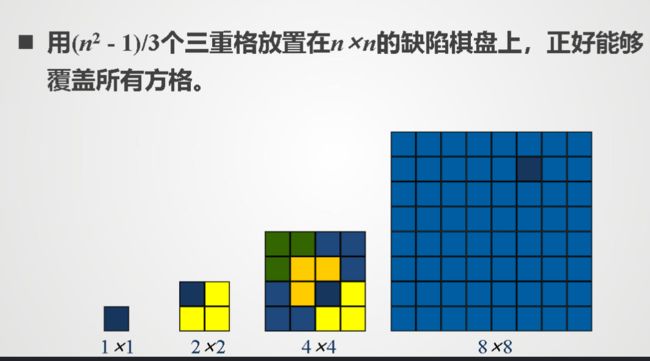


六,大整数乘法



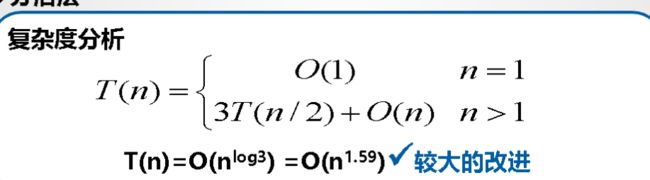
七,矩阵乘法

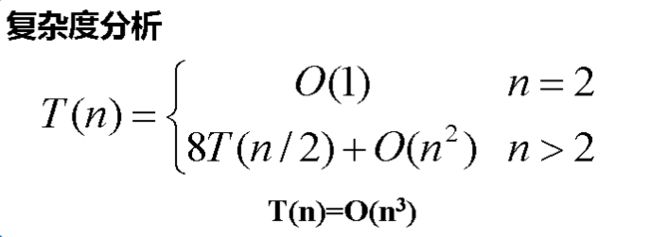

第五章 动态规划法
一,引言
自然界中的费波那契

考虑斐波那契序列F(n)


历史在重演 冗余在出现
多次重复计算 如何避免?
改进的思想:



