【论文阅读】Swin Transformer Embedding UNet用于遥感图像语义分割
【论文阅读】Swin Transformer Embedding UNet用于遥感图像语义分割
文章目录
- 【论文阅读】Swin Transformer Embedding UNet用于遥感图像语义分割
-
- 一、相应介绍
- 二、相关工作
-
- 2.1 基于CNN的遥感图像语义分割
- 2.2 Self-Attention机制
- 2.3 Vision Transformer
- 三、方法
-
- 3.1 网络结构
- 3.2 Swin Transformer BlocK
- 3.3 空间交互模块
- 3.4 特征压缩模块
- 3.5 关系聚合模块
- 四、实验结果
-
- 4.1 数据集
- 4.2 具体参数
- 4.3 消融实验
Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation
全局上下文信息是遥感图像语义分割的关键
具有强大全局建模能力的Swin transformer
提出了一种新的RS图像语义分割框架ST-UNet型网络(UNet)
解决方案:将Swin transformer嵌入到经典的基于cnn的UNet中
ST-UNet由Swin变压器和CNN并联构成了一种新型的双编码器结构
相应结构:
- 建立像素级相关性来编码Swin变压器块中的空间信息
- 构造了特征压缩模块(FCM)
- 作为双编码器之间的桥梁,设计了一个关系聚合模块(RAM)
数据集的使用:
- Vaihingen
- Potsdam
一、相应介绍
具体作用:
- 编码器用于提取特征
- 解码器在融合高级语义和低级空间信息的同时,尽可能精细地恢复图像分辨率
u型网络(UNet)[14]利用解码器通过跳过连接来学习相应编码阶段的空间相关性
利用变压器的编码器-解码器结构来模拟序列中元素之间的相互作用。
本文针对CNN在全局建模方面的不足,提出了一种新的RS图像语义分割网络框架ST-UNet
相应结构层次:
- 以UNet中的编码器为主编码器,Swin变压器为辅助编码器,形成一个并行的双编码器结构
- 设计良好的关系聚合模块(RAM)构建了从辅助编码器到主编码器的单向信息流
- RAM是ST-UNet的关键组件
- 将SIM卡附加到Swin变压器上,以探索全局特征的空间相关性
- 使用FCM提高小尺度目标的分割精度
相应贡献:
- 构建了空间交互模块(SIM),重点关注空间维度上的像素级特征相关性,SIM还弥补了Swin变压器窗口机制所限制的全局建模能力
- 提出了特征压缩模块(FCM),以缓解patch token下采样过程中小尺度特征的遗漏
- 设计了一个随机存储器,从辅助编码器中提取与chanel相关的信息作为全局线索来指导主编码器
二、相关工作
2.1 基于CNN的遥感图像语义分割
存在数据集:
- IEEE地球科学与遥感学会(IGARSS)数据融合大赛
- SpaceNet比赛
- DeepGlobe比赛
在检测方面的发展过程
(1)在最开始的发展中,多分支并行卷积结构生成多尺度特征图,并设计自适应空间池化模块聚合更多局部上下文
(2)引入了多层感知器(MLP),以产生更好的分割结果,最早是在自然语言中使用的。
(3)关注了小尺度特征的特征提取
(4)结合了基于patch的像素分类和像素到像素分割,引入了不确定映射,以实现对小尺度物体的高性能
(5) 通过密集融合策略实现小尺度特征的聚合
(6)明确引入边缘检测模块[43]来监督边界特征学习
(7)提出了两个简单的边缘损失增强模块来增强物体边界的保存
2.2 Self-Attention机制
最早的注意力在计算机视觉领域
(1)Zhao et al[45]和Li et al[46]分别给出了视频字幕的区域级注意和帧级注意
(2)SENet[48]通过全局平均池化层表示通道之间的关系,自动了解不同通道的重要性
(3)CBAM[49]将通道级注意和空间级注意应用于自适应特征细化
(4)Ding等[19]提出了patch attention module来突出feature map的重点区域
(5)在GCN[51]框架的每个阶段引入通道注意块,对特征图进行分层优化
(6)[52] 关注小批量图像中的相似对象,并通过自注意机制对它们之间的交互信息进行编码
2.3 Vision Transformer
首次提出用于机器翻译任务[53],超越了以往基于复杂递归或cnn的序列转导模型
标准transformer由多头自注意(MSA)、多层感知器(MLP)和层归一化(LN)组成
通过分割和扁平化将图像数据转化为一系列tokens
密集的预测任务,ViT仍然有巨大的训练成本,只能输出一个不能匹配预测目标(与输入图像分辨率相同)的低分辨率特征
在现在过程中的发展:
- SETR[58]将转换器视为编码器,结合简单的解码器对每一层的全局上下文进行建模,形成语义分割网络
- PVT[59]模仿CNN主干的特点,在ViT中引入金字塔结构,获得多比例尺特征图
- 基于移位窗口策略的Swin变压器,将MSA的计算限制在不重叠的窗口
- 以Swin转换器为骨干,Cao等[31]和Lin等[32]开发了医学图像语义分割的u型编码器-解码器框架
- TransUNet[20]和TransFuse[60]指出,纯transformer细分网络的效果并不理想,因为transformer只关注全局建模,缺乏定位能力
- 创建了CNN和transformer的混合结构。TransUNet将CNN和transformer依次堆叠
在本文中采用Swin变压器块组成的辅助编码器为基于cnn的主编码器提供全局上下文信息,提出的ST-UNet首次将Swin变压器应用到RS图像分割任务中,弥补了纯cnn的不足,提高了分割精度
三、方法
ST-UNet中的三个重要模块:
- RAM
- SIM
- FCM
3.1 网络结构
ST-UNet的整体架构
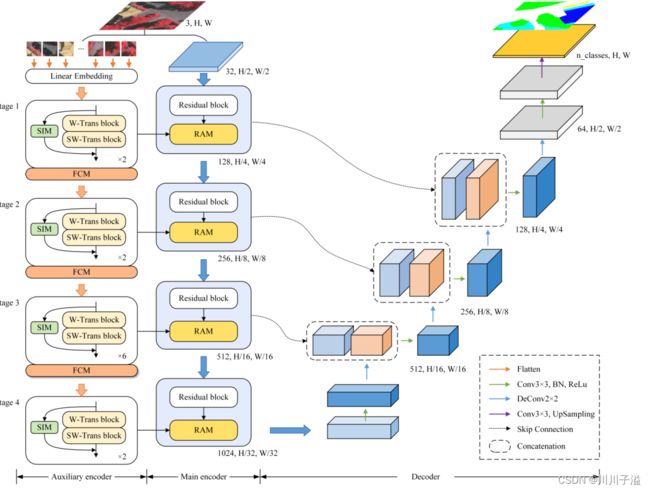
相应组成部分:
- ST-UNet是Swin transformer和UNet的混合体,它继承了UNet的优良结构,采用跳跃式连接层连接编码器和解码器
- ST-UNet构造了由基于cnn的残差网络和Swin变压器组成的双编码器
- 通过RAM传输信息,充分获取RS图像的判别特征
- 设计了SIM和FCM,进一步提高了Swin transformer的性能。
辅助 encoder部分
输入部分:
- RS图像X∈RH×W×3
- 数据划分为不重叠的patch,以模拟序列数据的“token”
- 通过卷积从每张图像中获取重叠的patch token
- patch尺寸为8 × 8,重叠率为50%。然后将线性嵌入层压平
- patch投影到C1维
- patch token被放入Swin变压器块堆叠的辅助编码器
辅助编码器有四个特征提取阶段,每个阶段的输出定义为Sn, n = 1,2,3,4。标准的Swin变压器块包括两种类型,即基于窗口的变压器(W-Trans)和移位的W-Trans (SW-Trans)。
提出在SIM卡上建立像素级的信息交换,加在Swin transformer块上
SIM可以有效地弥补基于窗口的自我注意的局限性,缓解遮挡引起的语义模糊问题
通过缩短patch令牌长度构建FCM
为了在与主编码器的特征分辨率匹配的同时获得多尺度特征,FCM的提出可以减少小尺度物体特征的遗漏
阶段n的输出分辨率为(H/(2n+1) × (W/(2n+1),维度为(2n−1)*C1
主要encode部分
输入部分:
- 原始RS图像X先在通道上压缩一半后馈送到ResNet50
- 第n个残差块的输出特征图可表示为An∈R(H/(2n+1))×(W/(2n+1))×2n−1C2
- 将An和辅助编码器对应级的输出Sn送入RAM,融合结果返回主编码器。
- RAM模块作为主辅编码器之间的桥梁,通过可变形卷积和通道注意机制建立连接。
解码部分
具体操作:
- 特征F∈R(H/32)×(W/32)×1024,经过卷积层后送入解码器。然后,我们将其输入到2 × 2反卷积层以扩大分辨率
- UNet之后,ST-UNet利用跳过连接层来连接编码器和解码器特性
- 3×3卷积层的减少通道数量
- 每个卷积层都伴随着一个批处理归一层和一个ReLU层
- 最后,对特征F进行3 × 3卷积层和线性插值上采样,得到最终的预测掩码。
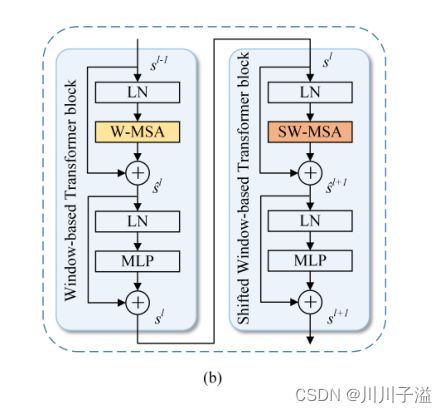
3.2 Swin Transformer BlocK
为了高效建模,Swin变压器提出了具有两种分区配置的W-MSA来替代普通MSA
MSA变化:
- 常规窗口配置(W-MSA)
- 移位窗口配置(SW-MSA)
每个窗口只覆盖D × D补丁,将D设为8,将两个Swin变压器块重命名为W-Trans块和SW-Trans块

相应的结构图
3.3 空间交互模块
Swin transformer块在有限的窗口内建立patch token关系,有效地减少内存开销
具体操作:
- 采用了规则窗口和移位窗口的交替执行策略
- 提出了跨W-Trans和SW-Trans区块的SIM,以进一步增强信息交换
- SIM在两个空间维度上引入注意力,考虑像素之间的关系,而不仅仅是patch token
- 在输入阶段将输入数据转化为一维
SIM结构框图
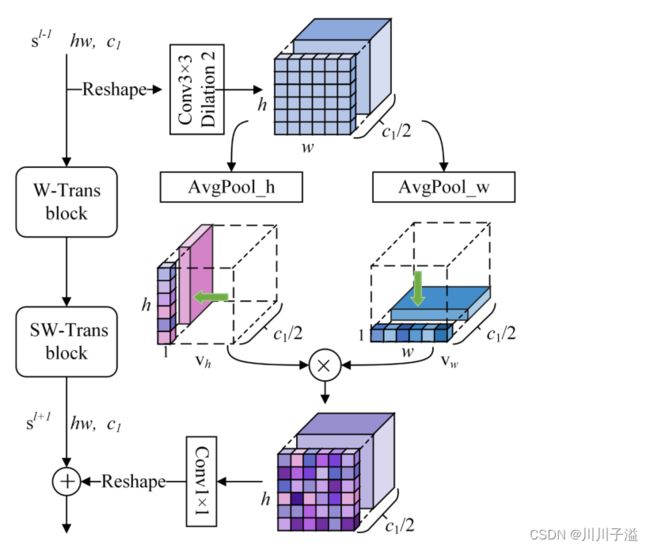
SIM操作:
- 通过一个大的接受场,将特征向量以2的扩张速率
- 在一个3 × 3的扩张卷积层上进行卷积
- 将通道数缩减为c1/2。然后,采用全局平均池化操作
在竖直方向和水平方向上的总张量分别记为 h×1×(c1/2)和1×w×(c1/2),因此我们将两者相乘得到与位置相关的注意力图M, 张量h×w×(c1/2),最后,将M与SW-Trans块的输出sl+1相加。
M的维数需要通过卷积层增加,以匹配特征sl+1的维数(所以进行了1X1卷积来改变通道数)
3.4 特征压缩模块
在transformer的前期工作中,通过将图像补丁[27]、[59]平化投影或合并2个×2相邻补丁的特征,并对[30]进行线性处理,形成了一个层次网络。
在Swin变压器的patch token下采样中设计了FCM
FCM避免了大量细节和结构信息的丢失,物体密集、小尺度的RS图像的语义分割,提高了小尺度对象的分割效果。
FCM结构框图
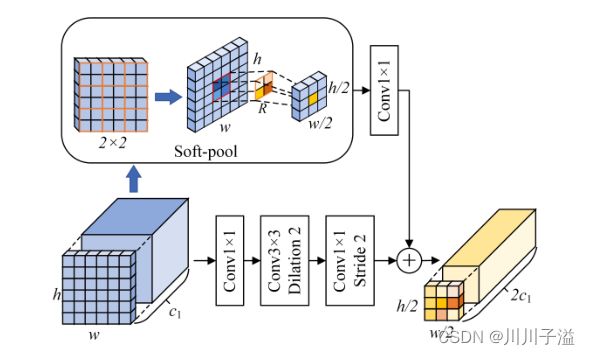
一种分支是扩大卷积的块:
- 扩大卷积的接受场,广泛地收集小尺度物体的特征和结构信息
- 采用前1 × 1卷积层增维
- 中间3 × 3扩张卷积层获取广泛的结构信息
- 后1 × 1卷积层降低特征尺度
- 输出结构(h/2)×(w/2)×2c1
另一个分支:
- 引入了软池[61]操作,以获得更精细的下采样
- 软池可以以指数加权的方式激活池化内核中的像素
- 将软池后的特征输入到卷积层(增维)
- 输出结构(h/2)×(w/2)×2c1
两个分支按等比例合并为FCM的输出L
3.5 关系聚合模块
基于cnn的主编码器在空间维度上提取了受卷积核限制的局部信息,缺乏对channel维度[48]之间关系的显式建模
提出了RAM,为了从整个特征图中强调重要且更具代表性的channel,从辅助编码器的全局特征中提取channel依赖关系,然后将其嵌入到从主编码器获得的局部特征中。
RAM结构特征图

RAM引入了可变形卷积[63]以适应不同形状的目标区域
具体操作:
- An和Sn分别表示第n阶段主编码器和辅助编码器的输出
- An输入到可变形卷积中,An = δ(An)。这里δ是一个3 × 3的可变形卷积
- Sn被发送到卷积层以改变维数,由于特征图的每个通道都可以看作是一个特征检测器
- 我们应用average-和max-pool层来计算通道上特征映射的统计特征,
- 发送到共享的全连接层,PA&M结构数为 1×1×(c1/2)
- σ代表ReLu函数,$1被设置为一个大小减半的全连接层
- PA&M与PS相乘来优化每个通道
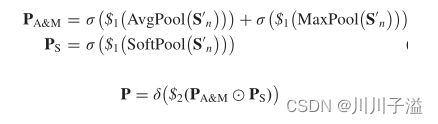
δ代表sigmoid函数,$2是一个大小增加的完全连接层,并表示元素级乘法。
我们将Channel依赖P作为权值与变形卷积运算的结果An相乘,得到了细化的特征。最后,将细化后的特征与残差结构相连接,形成RAM的输出特征Tn
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CTuozDn2-1678889215950)(C:\Users\isipa\AppData\Roaming\Typora\typora-user-images\image-20230204103550475.png)]](http://img.e-com-net.com/image/info8/1c3d60da9c8142849405a22c42a3bd20.jpg)
四、实验结果
4.1 数据集
Vaihingen Dataset
包含33张由先进机载传感器采集的真正射影像(TOP)图像,每个TOP图像都有红外(IR)、红色®和绿色(G)通道。
相应参数:
- 图像被标记为sic类别
- 11张图像用于训练(图像id: 1、3、5、7、13、17、21、23、26、32和37)
- 5张图像用于测试(图像id: 11、15、28、30和34),
- 裁剪为256 × 256
Potsdam Dataset
有38个相同大小的patch (6000 × 6000),都是从高分辨率TOP提取
相应参数:
- 数据集进行了六个类别的标注,用于语义分割研究
- 每张图像都有三种通道组合,即IR-R-G、R-G-B和R-G-B- ir
- 使用14张带有R-G-B的图像进行测试
- (图像id: 2_13, 2_14, 3_13, 3_14, 4_13, 4_14, 4_15, 5_13, 5_14, 5_15, 6_14, 6_15, 7_13)
- 其余24张带有R-G-B的图像进行训练
- 我们将这些原始图像切割为256 × 256
4.2 具体参数
实验具体参数:
- 动量项为0.9,权重衰减为1e−4
- SGD优化器
- 初始学习率设置为0.01
- 批处理大小设置为8
- 最大epoch为100
采用联合损失 dice loss [71] LDice与骰子损失cross-entropy loss LCE
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Azsim0fx-1678889215950)(C:\Users\isipa\AppData\Roaming\Typora\typora-user-images\image-20230204111154155.png)]](http://img.e-com-net.com/image/info8/cf5edf1f6227472799c0ae78e52a8633.jpg)
评价指标:
- 平均交叉over联合(MIoU)
- 平均F1 (Ave.F1)
4.3 消融实验
为了评估所提出的网络结构和三个重要模块的性能,我们将UNet作为基线网络
采用Vaihingen数据集
步骤:
- 在我们的ST-UNet中,主编码器采用半压缩的ResNet50
- 辅助编码器采用“Tiny”配置的Swin变压器
主要分为两种:
AddLS,即在编码的最后阶段才合并辅助编码器和主编码器的特征
AddES,辅助编码器和主编码器在每个编码阶段的特征,通过元素相加。