MySQL进阶_8.数据库其他调优策略
文章目录
- 第一节、数据库调优的步骤
-
- 1.1、选择合适的DBMS
- 1.2、优化表设计
- 1.3、优化逻辑查询
- 1.4、优化物理查询
- 1.5、使用 Redis 或 Memcached 作为缓存
- 1.6、库级优化
- 第二节、优化MySQL服务器
- 第三节、优化数据库结构
-
- 3.1 拆分表:冷热数据分离
- 3.2 增加中间表
- 3.3 增加冗余字段
- 3.4 优化数据类型
- 3.5 优化插入记录的速度
- 3.6 小结
- 第四节、大表优化
-
- 4.1、限定查询的范围
- 4.2、读/写分离
- 4.3、垂直拆分
- 4.4、水平拆分
第一节、数据库调优的步骤
1.1、选择合适的DBMS
- 如果对事务性处理以及安全性要求高的话,可以选择商业的数据库产品。这些数据库在事务处理和查询性能上都比较强,比如采用
SQL Server、Oracle,那么单表存储上亿条数据是没有问题的。如果数据表设计得好,即使不采用分库分表的方式,查询效率也不差。 - 除此以外,你也可以采用开源的
MySQL进行存储,它有很多存储引擎可以选择,如果进行事务处理的话可以选择lnnoDB,非事务处理可以选择MylSAM。 NoSQL阵营包括键值型数据库、文档型数据库、搜索引擎、列式存储和图形数据库。这些数据库的优缺点和使用场景各有不同,比如列式存储数据库可以大幅度降低系统的IO,适合于分布式文件系统,但如果数据需要频繁地增删改,那么列式存储就不太适用了。
1.2、优化表设计
1.3、优化逻辑查询
SQL查询优化,可以分为逻辑查询优化和物理查询优化。逻辑查询优化就是通过改变SQL语句的内容让SQL执行效率更高效,采用的方式是对SQL语句进行等价变换,对查询进行重写。
1.4、优化物理查询
物理查询优化是在确定了逻辑查询优化之后,采用物理优化技术(比如索引等), 通过计算代价模型对各种可能的访问路径进行估算,从而找到执行方式中代价最小的作为执行计划。在这个部分中,我们需要掌握的重点是对索弓|的创建和使用。
1.5、使用 Redis 或 Memcached 作为缓存
常用的键值存储数据库有 Redis 和 Memcached,它们都可以将数据存放到内存中。
1.6、库级优化
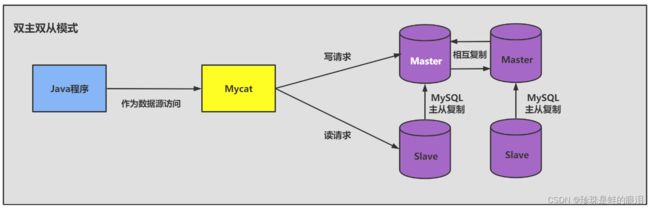
库级优化是站在数据库的维度上进行的优化策略,比如控制一个库中的数据表数量。另外,单一的数据库总会遇到各种限制,不如取长补短,利用"外援"的方式。通过主从架构优化我们的读写策略,通过对数据库进行垂直或者水平切分,突破单一数据库或数据表的访问限制, 提升查询的性能。
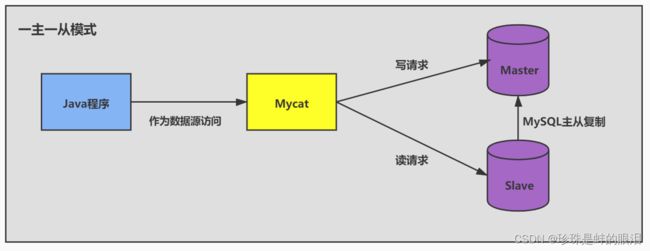
- 读写分离
如果读和写的业务量都很大,并且它们都在同一个数据库服务器中进行操作,那么数据库的性能就会出现瓶颈,这时为了提升系统的性能,优化用户体验,我们可以采用读写分离的方式降低主数据库的负载,比如用主数据库(master)完成写操作,用从数据库(slave) 完成读操作。
- 数据分片
对数据库分库分表。当数据量级达到千万级以上时,有时候我们需要把一个数据库切成多份,放到不同的数据库服务器上,减少对单一数据库服务器的访问压力。如果你使用的是MySQL,就可以使用MySQL自带的分区表功能,当然你也可以考虑自己做垂直拆分(分库)、水平拆分 (分表)、垂直+水平拆分 (分库分表)。
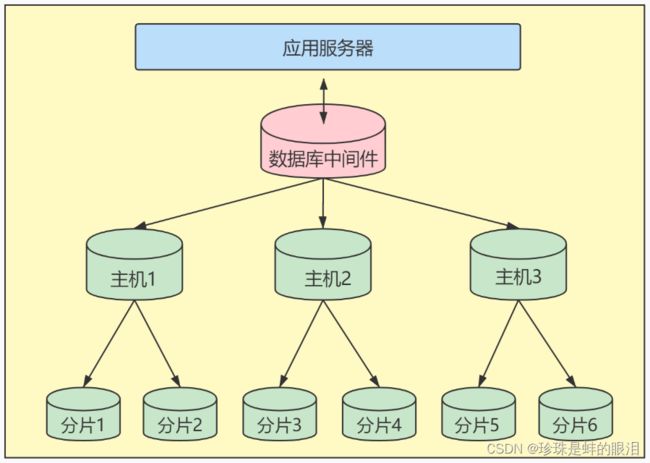
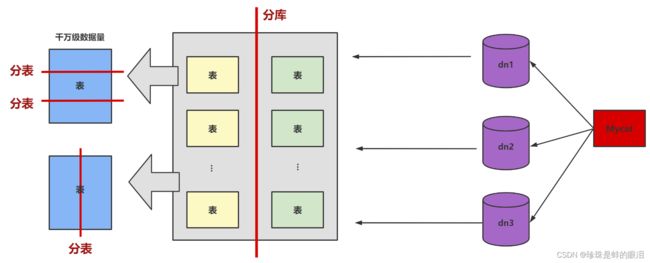
但需要注意的是,分拆在提升数据库性能的同时,也会增加维护和使用成本。
第二节、优化MySQL服务器
优化MySQL服务器主要从两个方面来优化,一方面是对 硬件进行优化;另一方面是对MySQL 服务的参数进行优化。这部分的内容需要较全面的知识,一般只有专业的数据库管理员才能进行这一类的优化。 对于可以定制参数的操作系统,也可以针对MySQL进行操作系统优化。
- 优化MySQL参数这里,需要在配置文件中设置参数值,目前在公司里不需要开发人员做,所以以后用到再来学习。
第三节、优化数据库结构
3.1 拆分表:冷热数据分离
拆分表的思路是,把1个包含很多字段的表拆分成2个或者多个相对较小的表。这样做的原因是,这些表中某些字段的操作频率很高( 热数据),经常要进行查询或者更新操作,而另外一些字段的使用频率却很低(冷数据),冷热数据分离,可以减小表的宽度。如果放在一个表里面, 每次查询都要读取大记录,会消耗较多的资源。
MySQL限制每个表最多存储4096列,并且每一行数据的大小不能超过65535字节。表越宽,把表装载进内存缓冲池时所占用的内存也就越大,也会消耗更多的I0。冷热数据 分离的目的是:①减少磁盘I0,保证热数据的内存缓存命中率。②更有效的利用缓存,避免读入无用的冷数据。
举例: 会员members表存储会员登录认证信息,该表中有很多字段,如id、姓名、密码、地址、电话、个人描述字段。其中地址、电话、个人描述等字段并不常用,可以将这些不常用的字段分解出另一个表。将这个表取名叫members_detail,表中有member_id、address、telephone、description等字段。这样就把会员表分成了两个表,分别为members表 和 members_detail表 。
3.2 增加中间表
举例:假设存在a和b两张表,需要的信息必须通过a表和b表联合查询得到;可以新建一个中间表c,将需要的信息从a和b表中提出并存到c中,后续直接从c中查询即可。
3.3 增加冗余字段
设计数据库表时应尽量遵循范式理论的规约,尽可能减少冗余字段,让数据库设计看起来精致、优雅。但是,合理地加入冗余字段可以提高查询速度。表的规范化程度越高,表与表之间的关系就越多,需要连接查询的情况也就越多。尤其在数据量大,而
且需要频繁进行连接的时候,为了提升效率,我们也可以考虑增加冗余字段来减少连接。
3.4 优化数据类型
改进表的设计时,可以考虑优化字段的数据类型。这个问题在大家刚从事开发时基本不算是问题。但是,随着你的经验越来越丰富,参与的项目越来越大,数据量也越来越多的时候,你就不能只从系统稳定性的角度来思考问题了,还要考虑到系统整体的稳定性和效率。此时,优先选择符合存储需要的最小的数据类型。
列的字段越大,建立索引时所需要的空间也就越大,这样一页中所能存储的索引节点的数量也就越少,在遍历时所需要的IO次数也就越多,索引的性能也就越差 。
- 对整数类型数据进行优化
遇到整数类型的字段可以用INT型 。 - 既可以使用文本类型也可以使用整数类型的字段,要选择使用整数类型
- 避免使用TEXT、BLOB数据类型
- 避免使用ENUM类型
- 使用
TIMESTAMP存储时间 - 用
DECIMAL代替FLOAT和DOUBLE存储精确浮点数
3.5 优化插入记录的速度
//1. 第一种方式
insert into student values(1,'zhangsan',18,1);
insert into student values(2,'lisi',17,1);
insert into student values(3,'wangwu',17,1);
insert into student values(4,'zhaoliu',19,1);
//2. 第二种方式:使用一条INSERT语句插入多条记录
insert into student values
(1,'zhangsan',18,1),
(2,'lisi',17,1),
(3,'wangwu',17,1),
(4,'zhaoliu',19,1);
第2种情形的插入速度要比第1种情形快
3.6 小结
上述这些方法都是有利有弊的。比如:
- 修改数据类型,节省存储空间的同时,你要考虑到数据不能超过取值范围;
- 增加冗余字段的时候,不要忘了确保数据一致性;
- 把大表拆分,也意味着你的查询会增加新的连接,从而增加额外的开销和运维的成本。
因此,一定要结合实际的业务需求进行权衡。
第四节、大表优化
4.1、限定查询的范围
禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内;
4.2、读/写分离
经典的数据库拆分方案,主库负责写,从库负责读。
4.3、垂直拆分
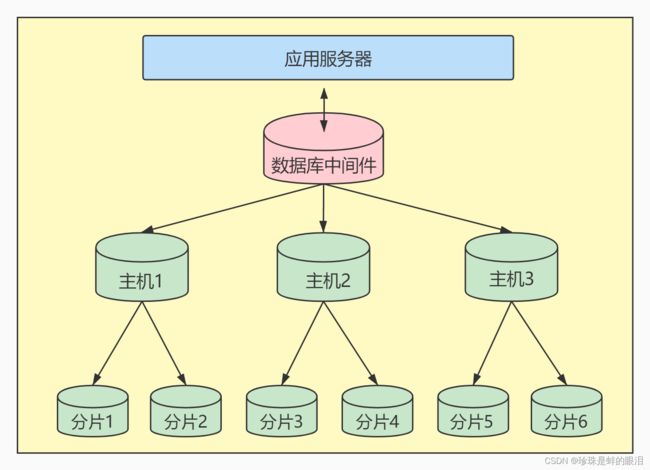
- 如果数据库中的数据表过多,可以采用垂直分库的方式,将表分散到不同的主机上。但是需要注意的是:可以将关联的数据表部署在同个数据库上。
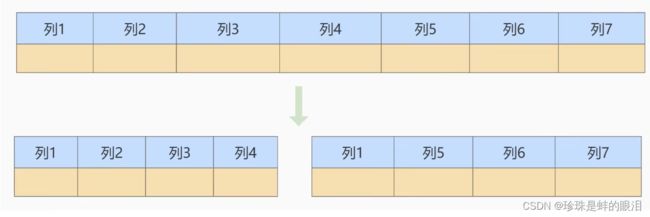
- 如果数据表中的列过多,可以采用垂直分表的方式,将一张数据表分拆成多张数据表,把经常一起使用的列
放到同一张表里。