【博弈论】【第五章】不完全信息动态博弈
不完全信息动态博弈
- 【引入】
-
- 在位者低成本
- 在位者高成本
- 总结
- 一、不完全信息动态博弈 (动态贝叶斯博弈) :
-
- 引入精炼贝叶斯纳什均衡的意义
- 贝叶斯法则
- 精炼贝叶斯均衡(perfect Bayesian equilibrium)
- 二、不完美信息博弈的精炼贝叶斯均衡
-
- 【例题】二手车交易市场
- 【例题】单一价格二手车交易模型(好车差车卖的价格都一样)
- 三、信号传递博弈
-
- 信号传递博弈的精炼贝叶斯均衡定义
-
- ①分离均衡(separating equilibrium)
- ②混同均衡(pooling equilibrium)
- ③准分离均衡(semi-separating equilibrium)
- 【例题】求下列信号博弈的纳什均衡(解法一)
-
- ①混同于 m 1 m^1 m1:发送者在类型 θ 1 \theta^1 θ1和 θ 2 \theta^2 θ2下均选择信号 m 1 m^1 m1。
- ②混同于 m 2 m^2 m2:发送者在类型 θ 1 \theta^1 θ1和 θ 2 \theta^2 θ2下均选择信号 m 2 m^2 m2。
- ③分离均衡: θ 1 \theta^1 θ1选择 m 1 m^1 m1, θ 2 \theta^2 θ2选择 m 2 m^2 m2
- ④分离均衡: θ 1 \theta^1 θ1选择 m 2 m^2 m2, θ 2 \theta^2 θ2选择 m 1 m^1 m1
- 【例题】求下列信号博弈的纳什均衡(解法二)
- 【例题】二手车交易博弈模型
- 作业题:求解如图所示的信号博弈的纯战略精炼贝叶斯纳什均衡
【引入】
市场中在位者与进入者的博弈过程
在位者低成本
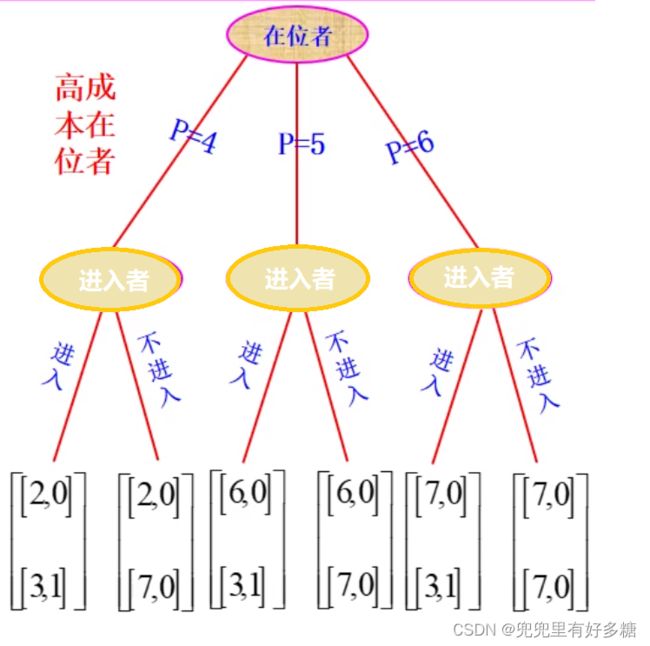
先看一个完全信息的动态博弈过程:
本题的描述为:
已经在市场中进行销售行为的是在位者,他会通过调整价格来达到两个结果:在下一轮影响进入者是否进入的决策;以及影响自己在本轮的收益情况。
最下面给出了竖着的两行得益,第一行是在第一阶段,进入者还没有进入的时候,在位者的收益,可以看到由于在位者不同的价格选择,他的得益值会有所波动。并且由于第一轮进入者还没有进入,所以进入者的收益一直为0。
第二阶段进入者会根据上一轮在位者的定价选择是否进入市场,然后第二行所显示的收益就是第二轮进入者决定了进入市场与否之后在位者与进入者的收益。
横着看第二行的得益我们可以得出:不论在位者的定价是多少,只要进入者进入市场,他第二阶段就会得到1的利润,不进入的话只能得到0。所以我们知道,如果进入者是一个理性人的话,他一定会选择进入。
如果再竖着看在位者两期的总收益的话,在位者定价为4,总收益是2+3=5;定价为5.总收益为9,定价为6,总收益为10,所以如果在位者是一个理性人,她一定会选择利益最大化,也就是定价为6的这个决策。
在位者高成本

这个我们同样分析也可以得到结论:进入者如果选择进入,则总会得到-1的收益,而如果选择不进入,会得到0的收益,所以我们可以得知进入者肯定会选择不进入。
而在位者在定价为4的时候,得益为15,定价为5,得益为18,定价为6,得益为17。所以最终结果一定是在位者把价格定为5。
总结
在本题中我们是明确知道在位者的类型究竟是高成本还是低成本,然后才判断出高成本两者分别会选择什么策略,低成本两者分别会选择什么策略。
但是如果我们现在进入者只能观察到在位者定的价格,但是无法观测到或者了解到在位者到底是高成本类型还是低成本类型,也就是不知道自己进入之后得到的收益到底是0还是1。也就是我们观察到定价为4的时候,其实不知道这时高成本类型的在位者定的还是低成本类型的在位者定的。所以这就是一个不完全信息问题,但他又带有先后的行为选择的不同,就把它定义为不完全信息动态博弈。

根据第三章,动态博弈可以划分为子博弈,然后根据子博弈精炼纳什均衡来找到均衡解,但是这个不完全信息动态博弈并不存在子博弈,因此第三章的从后往前的倒退的求解方法无法用于不完全信息动态博弈的求解。
所以我们就考虑能不能从开始向后进行分析。那么从前往后分析的话我们要考虑到开始行动的人他可能会有哪些选择:其实就是在位者定的价格。但是这里面就涉及到如果我们定一个价格使对方能够感觉到或者从中分析出我们是一种什么类型的话那就有可能会影响我们的利润,
在完全信息动态博弈下,如果是高成本在位者,她一定会定价为6,低成本在位者一定为定价为5.
但是在不完全信息动态博弈下在位者可以通过定价来伪装自己从而是自己得到更大的收益值。
比如在位者如果不伪装直接定价为6的话,进入者一看就知道他是高成本类型,因为高成本类型定价为6会使得在位者收益最大,所以进入者此时就会选择进入市场,所以此时在位者只能得到10的收益。
但如果高成本在位者不定价为6,反而定价为5,那么进入者有可能被误导觉得在位者是低成本类型,所以选择不进入。那么此时高成本在位者会得到13的收益。
所以在这种信息不完全的情况下,先行动者不一定按照完全信息情况下的方案进行选择,他有可能隐藏自己的真实类型也有可能是明确的展示自己的类型从而达到更高的收益,。
一、不完全信息动态博弈 (动态贝叶斯博弈) :
定义:至少部分博弈方没有关于博弈的全部信息的动态博弈。(全部信息其实就是指博弈对方的类型)
“自然”首先选择参与人的类型,参与人自己知道,其他参与人不知道: 之后参与人开始先后行动,后行动者能观测到先行动者的行动,但不能观测到先行动者的类型。
参与人的行动是类型依存的,后行动者可通过观察先行动者所选择的行动来推断其类型或修正对其类型的先验信念(概率分布),然后选择最优行动。先行动者预测到自己的行动将被后行动者所利用,就会设法选择传递对自己最有利的信息。
因此,博弈过程不仅是参与人选择行动的过程,而且是参与人不断修正“信念”的过程。
所以先行动者可以对自己的类型进行伪装从而达到对自己更有利的获益水平。
所以不完全信息动态博弈大致有这么几个特点:
- 参与人不一定再选择完全信息下的最优方案。
- 参与人不仅仅是选择行动方案的问题,还要做的是根据对方的行动来调节自己对对方的类型的判断,只有这个判断是对的,他才可能做出最有利于自己的决策。
在每一个信息集上,决策者必须有一个定义在属于该信息集的所有决策结上的一个概率分布(信念);
给定该信息集上的概率分布和其他参与人的后续战略,参与人的行动必须是最优的:每一个参与人根据贝叶斯法则和均衡战略修正后验概率。
这样的均衡我们称之为精炼贝叶斯纳什均衡
引入精炼贝叶斯纳什均衡的意义

- 在每一个信息集上,决策者必须有一个定义在属于该信息集的所有决策结上的一个概率分布(信念)
- 给定该信息集上的概率分布和其他参与人的后续战略,参与人的行动必须是最优的
- 每一个参与人根据贝叶斯法则和均衡战略修正后验概率。
贝叶斯法则
- 先验概率(prior probability):修正之前的判断
- 后验概率(posterior probability) :修正之后的判断
- 设参与人 i i i有 K K K个可能类型,有 H H H个可能行动,用 θ k \theta^k θk和 a h a^h ah分别表示一个特定的类型和行动。
- 假定 i i i属于类型 θ k \theta^k θk的先验概率是: p ( θ k ) ≥ 0 , ∑ k = 1 K p ( θ k ) = 1 p(\theta^k)≥0,\sum_{k=1}^Kp(\theta^k)= 1 p(θk)≥0,∑k=1Kp(θk)=1
- 给定 i i i属于 θ k \theta^k θk, i i i选择 a h a^h ah的条件概率为: p ( a h ∣ θ k ) ≥ 0 , ∑ k = 1 K p ( a h ∣ θ k ) = 1 p(a^h|\theta^k)≥0,\sum_{k=1}^Kp(a^h|\theta^k)= 1 p(ah∣θk)≥0,∑k=1Kp(ah∣θk)=1(比如:我们看到在位者定价为5,那可能是低成本类型的在位者的定价,也有可能是高成本类型的在位者的定价,而这两种类型做出定价为5的这一行为的概率总和应该为1)
- 那么, i i i选择 a h a^h ah的边缘概率(总概率)是:
Prob { a h } = p ( a h ∣ θ 1 ) p ( θ 1 ) + ⋯ + p ( a h ∣ θ K ) p ( θ K ) = ∑ k = 1 K p ( a h ∣ θ k ) p ( θ k ) \operatorname{Prob}\left\{a^h\right\}=p\left(a^h \mid \theta^1\right) p\left(\theta^1\right)+\cdots+p\left(a^h \mid \theta^K\right) p\left(\theta^K\right)=\sum_{k=1}^K p\left(a^h \mid \theta^k\right) p\left(\theta^k\right) Prob{ah}=p(ah∣θ1)p(θ1)+⋯+p(ah∣θK)p(θK)=k=1∑Kp(ah∣θk)p(θk) - 即参与人 i i i选择行动 a h a^h ah的“总”概率是每一种类型的 i i i选择 a h a^h ah的条件概率 p ( a h ∣ θ k ) p(a^h|\theta^k) p(ah∣θk)的加权平均,权数是他属于每种类型的先验概率 p ( θ k ) p(\theta^k) p(θk)。
若观测到 i i i选择了 a h a^h ah, i i i属于类型 θ k \theta^k θk的后验概率是多少? - 后验概率: P r o b { θ k ∣ a h } Prob\left\{\theta^k|a^h\right\} Prob{θk∣ah}即给定 a h a^h ah的情况下 i i i属于类型 θ k \theta^k θk的概率。根据概率公式
Prob { a h , θ k } ≡ p ( a h ∣ θ k ) p ( θ k ) ≡ Prob { θ k ∣ a h } Prob { a h } \operatorname{Prob}\left\{a^h, \theta^k\right\} \equiv p\left(a^h \mid \theta^k\right) p\left(\theta^k\right) \equiv \operatorname{Prob}\left\{\theta^k \mid a^h\right\} \operatorname{Prob}\left\{a^h\right\} Prob{ah,θk}≡p(ah∣θk)p(θk)≡Prob{θk∣ah}Prob{ah} - 即 i i i属于 θ k \theta^k θk并选择 a h a^h ah的联合概率等于 i i i属于 θ k \theta^k θk的先验概率乘以 θ k \theta^k θk类型的参与人选择 a h a^h ah的概率,或等于 i i i选择 a k a^k ak的总概率乘以给定 a h a^h ah情况下 i i i属于 θ k \theta^k θk的后验概率。 因此有:
Prob { θ k ∣ a h } ≡ p ( a h ∣ θ k ) p ( θ k ) Prob { a h } ≡ p ( a h ∣ θ k ) p ( θ k ) ∑ j = 1 K p ( a h ∣ θ j ) p ( θ j ) \operatorname{Prob}\left\{\theta^k \mid a^h\right\} \equiv \frac{p\left(a^h \mid \theta^k\right) p\left(\theta^k\right)}{\operatorname{Prob}\left\{a^h\right\}} \equiv \frac{p\left(a^h \mid \theta^k\right) p\left(\theta^k\right)}{\sum_{j=1}^K p\left(a^h \mid \theta^j\right) p\left(\theta^j\right)} Prob{θk∣ah}≡Prob{ah}p(ah∣θk)p(θk)≡∑j=1Kp(ah∣θj)p(θj)p(ah∣θk)p(θk)
(好人可能做好事,坏人也可能做好事,只是概率不同罢了,所以现在是知道了有人做好事,要去推断这个人是好人还是坏人。那么这个公式的分母就是好人做好事和坏人做好事的概率之和,分子是好事的概率)
精炼贝叶斯均衡(perfect Bayesian equilibrium)
精炼贝叶斯均衡是战略组合 s ∗ ( θ ) = [ s i ∗ ( θ i ) , ⋯ , s n ∗ ( θ n ) ] s^*(\theta)=\left[s_i^*\left(\theta_i\right), \cdots, s_n^*\left(\theta_n\right)\right] s∗(θ)=[si∗(θi),⋯,sn∗(θn)]和后验概率组合 p ~ = ( p 1 ~ , . . . p 2 ~ ) \widetilde{p}=(\widetilde{p_1},...\widetilde{p_2}) p =(p1 ,...p2 ),满足:
- 对于所有的参与人 i i i,在每个信息集 h h h,
s i ∗ ( s − i , θ i ) ∈ a r g m a x s i ∑ θ − i p ~ i ( θ − i ∣ a − i h ) u i ( s i , s − i , θ i ) s_i^*\left(s_{-i}, \theta_i\right) \in \operatorname{argmax_{s_i}} \sum_{\theta_{-i}} \widetilde{p}_i\left(\theta_{-i} \mid a_{-i}^h\right) u_i\left(s_i, s_{-i}, \theta_i\right) si∗(s−i,θi)∈argmaxsiθ−i∑p i(θ−i∣a−ih)ui(si,s−i,θi)
- p i ~ ( θ − i ∣ a − i h ) \widetilde{p_i}(\theta_{-i}|a_{-i}^h) pi (θ−i∣a−ih)是使用贝叶斯法则从先验 p ( θ − i ∣ θ i ) p(\theta_{-i}|\theta_i) p(θ−i∣θi)、 a − i h a_{-i}^h a−ih和最优战略 s − i ∗ = ( . ) s_{-i}^*=(.) s−i∗=(.)得到的。
`PBE要求均衡战略在每个“后续博弈(continuation game)”上构成贝叶斯均衡。
`不完全信息博弈中必须使用前向法(forward manner)进行贝叶斯修正.
- 不论先验概率 μ μ μ是多少,在第一阶段,高成本在位者选择单阶段最优垄断价格 p = 6 p =6 p=6和低成本在位者选择单阶段最优垄断价格 p = 5 p=5 p=5不是精炼贝叶斯均衡。
因为如果在位者这样选择,进入者观测到 p = 6 p=6 p=6就知道在位者是高成本,即 p ( 6 ) = 1 p(6)= 1 p(6)=1;观测到 p = 5 p =5 p=5就知道在位者是低成本, u ( 5 ) = 0 u(5)=0 u(5)=0。给定这个后验信念,进入者将进入,当且仅当他观测到 p = 6 p = 6 p=6
- 如果高成本在位者选择 p = 6 p = 6 p=6,第一阶段得到7单位的垄断利润,第二阶段得到3单位的寡头利润,总利润为10单位(假定没有贴现)。
如果高成本在位者模仿低成本企业选择 p = 5 p=5 p=5,第一阶段的利润为6单位,第二阶段的利润是7单位,总利润是13单位。
因此, p = 6 p=6 p=6不是高成本在位者的最优选择,上述战略不构成精炼贝叶斯均衡。
我们说不完全信息动态博弈中参与人通常不再采用完全信息动态博弈中的最优解,这个通常指的是先行动者,因为他们需要考虑自己的行动对后行动者的概率判断。
不完全信息动态博弈的解法我们通常是提出一个均衡,然后证明他是否成立,比如:
(1) 当 μ < 1 / 2 μ<1/2 μ<1/2时(高成本在位者的可能性低于1/2),精炼贝叶斯均衡是:不论高成本还是低成本,在位者选择 p = 5 p =5 p=5。当且仅当观测到 p = 6 p = 6 p=6(基于 μ ( 6 ) = 1 μ(6)=1 μ(6)=1),进入者将进入。
证明:假设给定进入者的先验概率和战略
证明过程就是要看给定了进入者的先验概率和战略之后,高成本在位者是不是他的最优选择,低成本是不是他的最优选择,然后证明如果在位者是这样的选择,再分析进入者是不是他的最优反应,如果双方都是最优反应,那么它符合纳什均衡要求,以及贝叶斯法则要求,那么就是这一章的精炼贝叶斯纳什均衡。
-
高成本在位者
如果选择 p = 6 p = 6 p=6,进入者进入,总利润为10;如果选择 p = 5 p = 5 p=5,进入者不进入。总利润为13。因此, p = 5 p=5 p=5是最优的。 -
低成本在位者
如果选择 p = 5 p =5 p=5的总利润为18,大于其他任何价格的总利润。因此 p = 5 p=5 p=5也是其最伏选择. -
因此综上可以看到,两类型的在位者都认为 p = 5 p = 5 p=5是最优反应,那么接下来就看在在位者是这个反应的前提下,进入者的反应是不是能达到最优:
-
给定两类型的在位者都选择 p = 5 p = 5 p=5,并且进入者不能从观测到的价格中得到任何新的信息,即
进入的期望利润 μ ′ ( 5 ) = ( μ × 1 ) / [ 1 × μ + ( 1 − μ ) × 1 ] = μ < 1 / 2 μ'(5)=(μ×1)/[1×μ+(1-μ)×1]=μ<1/2 μ′(5)=(μ×1)/[1×μ+(1−μ)×1]=μ<1/2
不进入的期望利润是0,因此不进入是最优的。 μ x 1 + ( 1 − μ ) × ( − 1 ) = 2 μ − 1 < 0 μx1+(1- μ)×(-1)=2μ-1<0 μx1+(1−μ)×(−1)=2μ−1<0
所以上述的提出的均衡确实是精炼贝叶斯纳什均衡。
上面这样的均衡也叫做混同均衡(pooling equilibrium):两类在位者选择相同的价格。(不同类型的先行动者选择相同的方案)
(2) 当 μ ≥ 1 / 2 μ≥1/2 μ≥1/2时,精炼贝叶斯均衡:低成本的在位者选择 p = 4 p=4 p=4,高成本的在位者选择 p = 6 p = 6 p=6;进入者选择不进入,如果观测到 p = 4 p=4 p=4(基于 μ ( 4 ) = 0 μ (4)=0 μ(4)=0);进入者选择进入,如果观测到 p = 6 p =6 p=6或 p = 5 p =5 p=5(基于 μ ( 6 ) = 1 μ(6)= 1 μ(6)=1)。
如果不同类型的在位者选择相同的价格,进入者得不到新的信息。
进入的斯望利润是 μ × 1 + ( 1 − μ ) × ( − 1 ) = 2 μ − 1 > 0 μ×1+(1-μ)×(-1)= 2μ -1>0 μ×1+(1−μ)×(−1)=2μ−1>0,不进入的期望利润是0。因此进入是最优的。
给定进入者一定会进入,在位者的最优选择是单阶段最优垄断价格,即高成本在位者选择 p = 6 p=6 p=6,低成本在位者选择 p = 5 p = 5 p=5。但是,已经证明这不可能是一个均衡。
证明:
给定进入者的先验概率和战略·低成本在位者
-如果选择 p = 4 p =4 p=4,进入者不进入,总利润为15;
-如果选择 p = 5 p=5 p=5,进入者进入,总利润为14。因此, p = 4 p=4 p=4是最优选择·高成本在位者
-如果选择 p = 4 p =4 p=4,进入者不进入,总利润为9
-如果选择 p = 6 p =6 p=6,进入者进入,总利润为10。-因此 p = 6 p = 6 p=6是最优选择。
·给定在位者战略和 μ ( 6 ) = 1 μ(6)=1 μ(6)=1和 μ ( 4 ) = 0 μ(4)=0 μ(4)=0是正确的
-如果观测到 p = 4 p =4 p=4进入者选择不进入;如果观测到 p = 6 p =6 p=6进入者选择进入。
分离均衡(separating equilibrium):不同类型的在位者选择不同的价格
二、不完美信息博弈的精炼贝叶斯均衡
这个是后行动的参与人对先行动的参与人的行动不完全了解,而之前的不完全信息博弈指的是后行动的参与人对线行动的参与人的类型不完全了解。
要求1: 在每一信息集中,应该行动的参与人必须对博弈进行到该信息集中的哪个节有一个推断。对于非单节信息集,推断是在信息集中不同节点的一个概率分布;对于单节的信息集,参与人的推断就是到达单一决策节的概率为1。
要求2: 给定参与人的推断,参与人的战略必须满足序贯理性的要求,即在每一个信息集中应该行动的参与人(以及参与人随后的战略),对于给定的该参与人在此信息集中的推断,以及其他参与人随后的战略必须是最优反应。
-定义: 对于一个扩展式博弈中给定的均衡,如果博弈根据均衡战略进行时将以正的概率达到某信息集,称此信息集处于均衡路径之上。反之,如果博弈根据均衡战略进行时,肯定不会达到某信息集,称之为处于均衡战略路径之外的信息集。
·要求3: 在处于均衡路径之上的信息集中,推断由贝叶斯法则及参与人的均衡战略给出。
·要求4: 对处于均衡路径之外的信息集,推断由贝叶斯法则以及可能情况下的参与人的均衡战略决定。
【例题】二手车交易市场
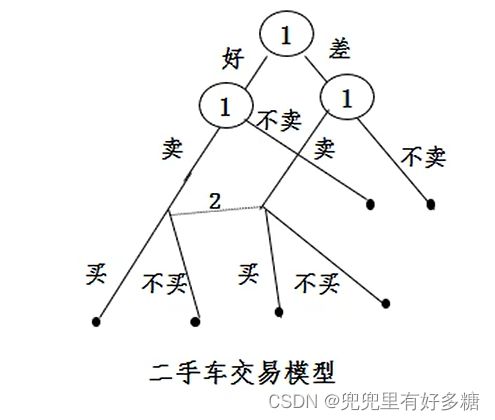
二手车质量有可能号有可能坏,卖方可以选择卖也可以选择不卖,买方可以选择买也可以选择不买。
我们此处用 r r r表示买方, s s s表示卖方, g g g表示好车, b b b表示其他车。
卖的车当中属于好车的概率:等于好车拿出来卖的概率乘以好车的先验概率,除以卖的车的总概率(全概率)。
p ( g ∣ s ) = p ( g ) p ( s ∣ g ) p ( s ) = p ( g ) p ( s ∣ g ) p ( g ) p ( s ∣ g ) + p ( b ) p ( s ∣ b ) \begin{aligned} & p(g \mid s)=\frac{p(g) p(s \mid g)}{p(s)} \\ & =\frac{p(g) p(s \mid g)}{p(g) p(s \mid g)+p(b) p(s \mid b)} \end{aligned} p(g∣s)=p(s)p(g)p(s∣g)=p(g)p(s∣g)+p(b)p(s∣b)p(g)p(s∣g)
我们给定初始条件:
p ( s ∣ g ) = 1 p ( s ∣ b ) = 0.5 p ( g ) = p ( b ) = 0.5 \begin{aligned} & p(s \mid g)=1 \\ & p(s \mid b)=0.5 \\ & p(g)=p(b)=0.5 \end{aligned} p(s∣g)=1p(s∣b)=0.5p(g)=p(b)=0.5
得到卖的车当中属于好车的概率:
p ( g ∣ s ) = p ( g ) p ( s ∣ g ) p ( s ) = p ( g ) p ( s ∣ g ) p ( g ) p ( s ∣ g ) + p ( b ) p ( s ∣ b ) = 0.5 × 1 0.5 × 1 + 0.5 × 0.5 = 2 3 p(g \mid s)=\frac{p(g) p(s \mid g)}{p(s)}=\frac{p(g) p(s \mid g)}{p(g) p(s \mid g)+p(b) p(s \mid b)}=\frac{0.5 \times 1}{0.5 \times 1+0.5 \times 0.5}=\frac{2}{3} p(g∣s)=p(s)p(g)p(s∣g)=p(g)p(s∣g)+p(b)p(s∣b)p(g)p(s∣g)=0.5×1+0.5×0.50.5×1=32
【例题】单一价格二手车交易模型(好车差车卖的价格都一样)

上图显示的收益是:(卖方收益,买方收益)
好车交易成功时,卖方获得 P P P的货币收益,买方获得的收益是好车的价值 V V V减去支付的货币价值 P P P,也就是 V − P V-P V−P。好车没有交易成功的时候双方既没有收益也没有损失。
如果差车成交的话,买方得到的价值是差车的价值 W W W减去支付的货币价值 P P P。而卖方由于想要差车和好车卖一个价格,所以他会对差车进行一个伪装,所以对于差车,卖方会有一个伪装成本 C C C,所以如果差车交易成功,卖方得到的收益是货币价值减去支付出去的伪装成本,即 P − C P-C P−C。如果差车没有交易成功,那么买家没有任何损失或者收益,但是卖方会有 − C -C −C的伪装成本损失。
特别要注意本题的假设: P > C P>C P>C才能激励卖方对差车进行伪装, V > P V>P V>P就是买方买到好车的价值是高于他付出的货币的价值的,这是符合一般规律的,并且还有就是 P > W P>W P>W,也就是买方买到坏车,坏车的价值是低于买方支付的货币的价值的,这也是符合一般规律的。
这个均衡问题也没有子博弈,所以我们仍需要从前往后进行求解,从前面提出一种均衡策略,然后证明她是否成立,那么提出均衡的时候有这么几种均衡:
均衡类型:
- 市场完全失败:市场上所有的卖方,无论商品好坏,都选择不卖(混同均衡)
- 市场完全成功:质量好的商品的卖方将商品投放市场,质量差的商品的卖方不敢将商品投放市场(分离均衡)
- 市场部分成功:所有的卖方,无论商品好坏,都将商品投放市场,而买方也不管好坏商品都买进(混同均衡)(混同是针对先行动者,在本问题中是卖方)
- 市场接近失败:所有好商品的卖方都将商品投放市场,而只有部分“差”商品的卖方将商品投放市场,同时买方以一定的概率随机决定是否买进(非分离均衡)
纯战略完美贝叶斯均衡
-
市场部分成功的混同均衡
~卖方选择卖,不管车子好差
~买方选择买,只要卖方卖
~买方的判断是
p ( g ∣ s ) = p g , p ( b ∣ s ) = p b p(g|s)= p_g,p(b|s)= p_b p(g∣s)=pg,p(b∣s)=pb
~条件:
差车概率很小
买到差车损失不大
伪装费用较小 P > > c P >>c P>>c -
市场完成成功的分离均衡
~卖方在车好时卖,车差时不卖
~买方选买,只要卖方卖
~买方的判断为: p ( g ∣ s ) = 1 , p ( b ∣ s ) = 0 p(g|s)=1, p(b|s)=0 p(g∣s)=1,p(b∣s)=0
~条件: P < C PP<C -
市场完全失败的合并均衡
~卖方选择不卖
~买方选择不买
~买方的判断为: p ( g ∣ s ) = 0 , p ( b ∣ s ) = 1 p(g|s)=0, p(b|s)=1 p(g∣s)=0,p(b∣s)=1
~条件: W < P WW<P
混合战略精练贝叶斯均衡 P>C,W<P
条件: P > C , W < P P>C,W
市场接近失败的数字例子:
假设: V = 3000 , W = 0 , P = 2000 , C = 1000 V=3000,W =0,P =2000,C=1000 V=3000,W=0,P=2000,C=1000
P g = P b = 0.5 P_g= P_b=0.5 Pg=Pb=0.5
均衡:
■卖方在车好时选卖,车差时以0.5概率随机选择卖或不卖
■买方以0.5概率随机选择买或不买
■买方的判断为
p ( g ∣ s ) = 2 / 3 , p ( b ∣ s ) = 1 / 3 p(g|s)=2/3,p(b|s) = 1/3 p(g∣s)=2/3,p(b∣s)=1/3
三、信号传递博弈
这种博弈也是在海萨尼转换的基础上进行的。
- “自然”首先选择参与人1的类型 θ ∈ Θ , Θ = { θ 1 . θ 2 … , θ k } \theta∈Θ,Θ= \left\{\theta_1.\theta_2… ,\theta_k\right\} θ∈Θ,Θ={θ1.θ2…,θk}是参与人1的类型空间,参与人自己知道 θ \theta θ,但参与人2不知道,只知道参与人1属于 θ \theta θ的先验概率 p = p ( θ ) , ∑ k ( θ k ) = 1 p = p(\theta),\sum_k(\theta^k)=1 p=p(θ),∑k(θk)=1。
- 参与人1在观测到类型 θ \theta θ后选择发出信号 m ∈ M , M = { m 1 , m 2 , . . , m j } m∈M,M = \left\{m^1 ,m^2,..,m^j\right\} m∈M,M={m1,m2,..,mj}是信号空间。
- 参与人2观测到参与人1发出的信号 m m m(但不是类型 θ \theta θ),使用贝叶斯法则从先验概率 p = p ( θ ) p = p(\theta) p=p(θ)得到后验概率 p ~ = p ~ ( θ [ m ) \widetilde{p}=\widetilde{p}(\theta[m) p =p (θ[m),然后选择行动 a ∈ A , A = { a 1 , a 2 , … , a H } a ∈ A,A =\left\{a_1, a_2,…,a_H\right\} a∈A,A={a1,a2,…,aH}是参与人2的行动空间。
- 支付函数分别为: μ 1 ( m , a , θ ) μ_1(m,a,\theta) μ1(m,a,θ)和 μ 2 ( m , a , θ ) μ_2(m,a,\theta) μ2(m,a,θ)
用图来表示就是:
-
首先自然为参与人1选择他的类型(此处我们假设为两种: θ 1 \theta_1 θ1和 θ 2 \theta_2 θ2),概率分别为 P P P和 1 − P 1-P 1−P:
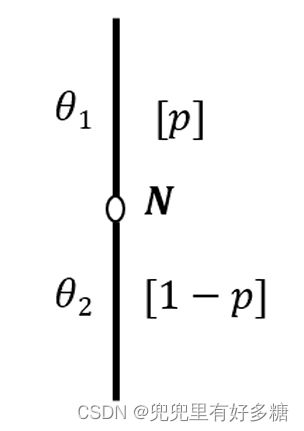
-
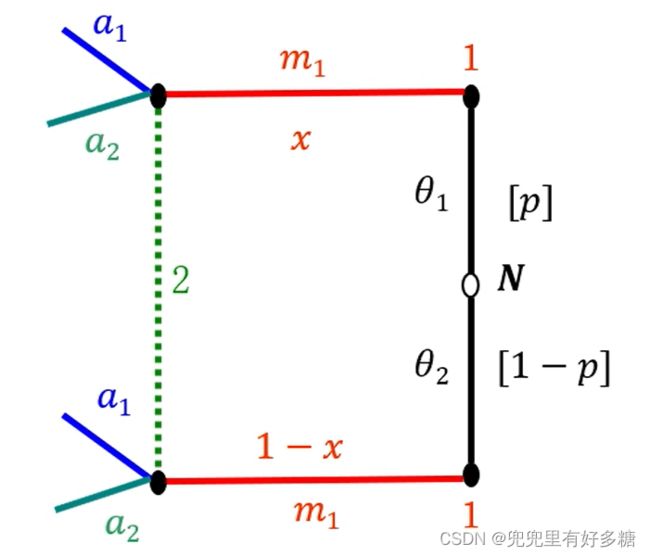
之后参与人1就会发送信号,类型为 θ 1 \theta_1 θ1的可以发出 m 1 m_1 m1这样的信号,类型为 θ 2 \theta_2 θ2的也可以发出 m 1 m_1 m1这样的信号。

-
参与人2在接收到信号之后可以从自己的行为空间中选择 a 1 a_1 a1或者 a 2 a_2 a2来进行行动。
-
但是要注意的是,参与人2在接收到 m 1 m_1 m1信号之后是不能完全确定这是属于 θ 1 \theta_1 θ1还是 θ 2 \theta_2 θ2发出的。参与人2只能通过一定的信息去推断这个信息是属于 θ 1 \theta_1 θ1发出的概率是 x x x,属于 θ 2 \theta_2 θ2发出的概率是 1 − x 1-x 1−x。
-
参与人1的两个类型 θ 1 \theta_1 θ1和 θ 2 \theta_2 θ2也可以发出 m 2 m_2 m2这样类型的信号。然后参与人2从自己的行为空间再进行选择。并且推断这个消息属于 θ 1 \theta_1 θ1和 θ 2 \theta_2 θ2发出的概率分别为 x x x和 1 − x 1-x 1−x。
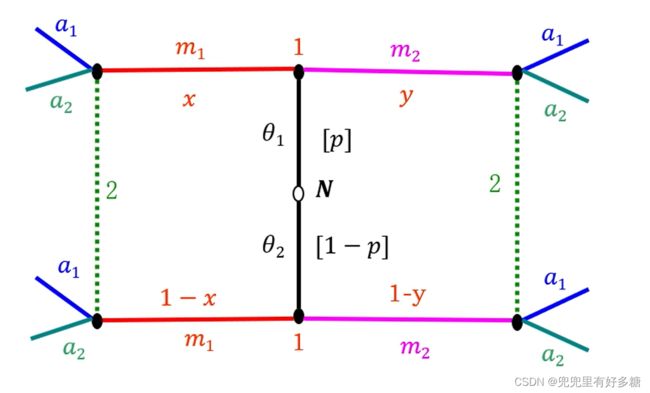
信号传递博弈的精炼贝叶斯均衡定义
- 信号传递博弈的精炼贝叶斯均衡是战略组合 ( m ∗ ( θ ) , a ∗ ( m ) ) (m^* (\theta), a^*(m)) (m∗(θ),a∗(m))和后验概率 p ~ ( θ ∣ m ) \widetilde{p}(\theta|m) p (θ∣m)的结合,它满足:
( P 1 ) a ∗ ( m ) ∈ arg max a Σ θ p ~ ( θ ∣ m ) μ 2 ( m , a , θ ) \left(P_1\right){a}^*(m) \in \arg \max _a \Sigma_\theta \widetilde{{p}}(\theta \mid m) \mu_2({m}, {a}, \theta) (P1)a∗(m)∈argmaxaΣθp (θ∣m)μ2(m,a,θ) 接收方
( P 2 ) m ∗ ( θ ) ∈ arg max m μ i ( m , a ∗ ( m ) , θ ) \left({P}_2\right) {m}^*({\theta}) \in \arg \max _m \mu_i\left({m}, {a}^*({m}), {\theta}\right) \quad (P2)m∗(θ)∈argmaxmμi(m,a∗(m),θ) 发送方
意思就是接收方会选择使得自己能够达到期望收益最大化的行为,而信号发送方会选择使得自己的收益最大化的那个信号进行发送。 - ( B ) p ~ ( θ ∣ m ) (B)\widetilde{p}(\theta|m) (B)p (θ∣m)是参与人2使用贝叶斯法则从先验概率 p ( θ ) p(\theta) p(θ)、观测到的信号 m m m、参与人1的最优战略 m ∗ ( θ ) m^*(\theta) m∗(θ)得到的(在可能的情况下)。
由于不完美信息动态博弈同样不存在子博弈,也就是最后一个阶段无法完全割裂开进行分析,所以在这样的情况下我们只能采用前向的方法,也就是分析最先行动的参与人她该怎么行动。
所以我们就是按照上一节课的思想,看最线行动的参与人有哪些可能的选择,把这些分别来进行讨论,看能不能构成均衡。所以我们就是先提出一些均衡的可能性,然后看他能否成立。那么我们可以提出的均衡类型一共有三种:分离均衡(不同类型的先行动者会采取不同的行动,也就是发出不同的信号),混同均衡(不同类型的先行动者发出相同的信号),准分离均衡(一些人发出相同的信号,一些人随机选择)
①分离均衡(separating equilibrium)
- 不同类型的发送者以1的概率选择不同的信号。
μ 1 ( m 1 , a ∗ ( m ) , θ 1 ) > μ 1 ( m 2 , a ∗ ( m ) , θ 1 ) μ 1 ( m 2 , a ∗ ( m ) , θ 2 ) > μ 1 ( m 1 , a ∗ ( m ) , θ 2 ) \begin{gathered} \mu_1\left(m^1, \quad a^*(m), \theta^1\right)>\mu_1\left(m^2, a^*(m), \theta^1\right) \\ \mu_1\left(m^2, \quad a^*(m), \theta^2\right)>\mu_1\left(m^1, a^*(m), \theta^2\right) \\ \end{gathered} μ1(m1,a∗(m),θ1)>μ1(m2,a∗(m),θ1)μ1(m2,a∗(m),θ2)>μ1(m1,a∗(m),θ2)
首先明确当我们假设这个均衡的时候达到均衡的条件是什么?
分离均衡的条件指的是:参与人1的类型如果是 θ 1 \theta_1 θ1,就一定会发送 m 1 m_1 m1类型的信号,如果类型是 θ 2 \theta_2 θ2,就一定会发送 m 2 m_2 m2类型的信号。
上面这样的分离策略如果想达到均衡应该达到的条件是:参与人1是 θ 1 \theta_1 θ1类型时,发送 m 1 m_1 m1类型的信号,此时接收方根据 m 1 m_1 m1而选择做出的行动使得参与人1得到的收益要大于参与人1选择 m 2 m_2 m2,接收方选择行动过后他得到的收益。
同样, θ 2 \theta_2 θ2类型的发送方,发送 m 2 m_2 m2类型的信号,所获得的收益要大于他发送 m 1 m_1 m1类型的信号所获得的收益。
还有就是接收方的推断:接收方接收到 m 1 m_1 m1类型的信号之后推断这个消息是 θ 1 \theta_1 θ1发出的概率是1(等等):
p ~ ( θ 1 ∣ m 1 ) = 1 , p ~ ( θ 1 ∣ m 2 ) = 0 p ~ ( θ 2 ∣ m 1 ) = 0 , p ~ ( θ 2 ∣ m 2 ) = 1 \begin{gathered} \widetilde{p}\left(\theta^1 \mid m^1\right)=1, \widetilde{p}\left(\theta^1 \mid m^2\right)=0 \\ \widetilde{p}\left(\theta^2 \mid m^1\right)=0, \widetilde{p}\left(\theta^2 \mid m^2\right)=1 \end{gathered} p (θ1∣m1)=1,p (θ1∣m2)=0p (θ2∣m1)=0,p (θ2∣m2)=1
②混同均衡(pooling equilibrium)
- 不同类型的发送者(参与人1)选择相同的信号。
不同类型的发送者都发送 m j m^j mj类型的信号,因为发送 m j m^j mj信号所获得的收益要比其他的信号所获得的收益高。
μ 1 ( m j , a ∗ ( m ) , θ 1 ) > μ 1 ( m , a ∗ ( m ) , θ 1 ) μ 1 ( m j , a ∗ ( m ) , θ 2 ) > μ 1 ( m , a ∗ ( m ) , θ 2 ) \begin{gathered} \mu_1\left(m^j, \quad a^*(m), \theta^1\right)>\mu_1\left(m, \quad a^*(m), \theta^1\right) \\ \mu_1\left(m^j, \quad a^*(m), \theta^2\right)>\mu_1\left(m, \quad a^*(m), \theta^2\right) \\ \end{gathered} μ1(mj,a∗(m),θ1)>μ1(m,a∗(m),θ1)μ1(mj,a∗(m),θ2)>μ1(m,a∗(m),θ2)
并且由于市场上所有参与人发出的信息都是 m j m^j mj,所以接收方即使获得了 m j m^j mj这个信号,也不会对其原有的概率预估有所更新和改变,所以后验概率和先验概率是一样的,没有更新:
p ~ ( θ k ∣ m j ) ≡ p ( θ k ) \widetilde{p}\left(\theta^k \mid m^j\right) \equiv p\left(\theta^k\right) p (θk∣mj)≡p(θk)
③准分离均衡(semi-separating equilibrium)
- 一些类型的发送者随机地选择信号,另一些类型的发送者选择特定的信号。
比如 θ 1 \theta_1 θ1类型的发送 m 1 m^1 m1和发送 m 2 m^2 m2类型的信息得到的收益是一样的,那么他最后就会从 m 1 m^1 m1和 m 2 m^2 m2中随机选择一个发送。
但是对于 θ 2 \theta_2 θ2来说,发送 m 1 m^1 m1得到的收益比发送 m 2 m^2 m2要少,那么他最终就会选择发送 m 2 m^2 m2,所以他的发送信息就是固定不变的,是特定的。
μ 1 ( m 1 , a ∗ ( m ) , θ 1 ) = μ 1 ( m 2 , a ∗ ( m ) , θ 1 ) μ 1 ( m 1 , a ∗ ( m ) , θ 2 ) < μ 1 ( m 2 , a ∗ ( m ) , θ 2 ) \begin{gathered} \mu_1\left(m^1, a^*(m), \theta^1\right)=\mu_1\left(m^2, a^*(m), \theta^1\right) \\ \mu_1\left(m^1, a^*(m), \theta^2\right)<\mu_1\left(m^2, a^*(m), \theta^2\right) \\ \end{gathered} μ1(m1,a∗(m),θ1)=μ1(m2,a∗(m),θ1)μ1(m1,a∗(m),θ2)<μ1(m2,a∗(m),θ2)
那么作为接受方我们的推断应该是什么样的呢?
那就是接收到 m 1 m^1 m1的话会判断出一定是 θ 1 \theta_1 θ1发出的,因为 θ 2 \theta_2 θ2一定不会发送 m 1 m^1 m1的。而接收到 m 2 m^2 m2的话可能是 θ 1 \theta_1 θ1发出的也可能是 θ 2 \theta_2 θ2发出的(都是由全概率公式算出来的):
p ~ ( θ 1 ∣ m 1 ) = a × p ( θ 1 ) a × p ( θ 1 ) + 0 × p ( θ 2 ) = 1 p ~ ( θ 1 ∣ m 2 ) = ( 1 − a ) × p ( θ 1 ) ( 1 − a ) × p ( θ 1 ) + 1 × p ( θ 2 ) < p ( θ 1 ) p ~ ( θ 2 ∣ m 2 ) = 1 × p ( θ 1 ) ( 1 − a ) × p ( θ 1 ) + 1 × p ( θ 2 ) > p ( θ 2 ) \widetilde{p}\left(\theta^1 \mid m^1\right)=\frac{a \times p\left(\theta^1\right)}{a \times p\left(\theta^1\right)+0 \times p\left(\theta^2\right)}=1 \\ \widetilde{p}\left(\theta^1 \mid m^2\right)=\frac{(1-a) \times p\left(\theta^1\right)}{(1-a) \times p\left(\theta^1\right)+1 \times p\left(\theta^2\right)}
【例题】求下列信号博弈的纳什均衡(解法一)

末端显示的收益值是(发送方收益值,接收方收益值),先验概率是0.5。
有4个可能的纯战略精炼贝叶斯均衡:
①混同于 m 1 m^1 m1;
②混同于 m 2 m^2 m2;
③分离均衡, θ 1 \theta^1 θ1选择 m 1 m^1 m1, θ 2 \theta^2 θ2选择 m 2 m^2 m2;
④分离均衡, θ 1 \theta^1 θ1选择用 m 2 m^2 m2, θ 2 \theta^2 θ2选择 m 1 m^1 m1;
下面分别讨论这四种情况:
①混同于 m 1 m^1 m1:发送者在类型 θ 1 \theta^1 θ1和 θ 2 \theta^2 θ2下均选择信号 m 1 m^1 m1。
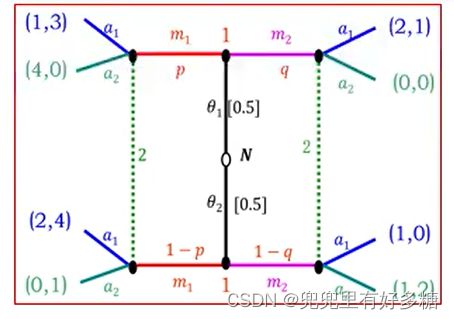
θ 1 θ 2 } → m 1 ⟶ 推断 ( p , 1 − p ) = ( 0.5 , 0.5 ) (这个结果不是直接写出的,而是通过之前的推导,也就是贝叶斯全概率公式的推导得到的,这里省略中间步骤,直接给出结果了) ⟶ a ≻ a 2 a 1 → { θ 1 : ( 1 , 3 ) θ 2 : ( 2 , 4 ) \begin{aligned} & \left.\begin{array}{l} \theta_1 \\ \theta_2 \end{array}\right\} \rightarrow m_1 \stackrel{\text {推断}}{\longrightarrow}(p, 1-p)=(0.5,0.5)(这个结果不是直接写出的,而是通过之前的推导,也就是贝叶斯全概率公式的推导得到的,这里省略中间步骤,直接给出结果了) \\ & \stackrel{a \succ a_2}{\longrightarrow} a_1 \rightarrow\left\{\begin{array}{l} \theta_1:(1,3) \\ \theta_2:(2,4) \end{array}\right. \\ & \end{aligned} θ1θ2}→m1⟶推断(p,1−p)=(0.5,0.5)(这个结果不是直接写出的,而是通过之前的推导,也就是贝叶斯全概率公式的推导得到的,这里省略中间步骤,直接给出结果了)⟶a≻a2a1→{θ1:(1,3)θ2:(2,4)
则如果选择 a 1 a_1 a1的话,他得到的期望收益值是 3 ∗ 0.5 + 4 ∗ 0.5 = 3.5 3*0.5+4*0.5=3.5 3∗0.5+4∗0.5=3.5。如果选择 a 2 a_2 a2的话,收益值就是 ( 4 , 0 ) , ( 0 , 1 ) (4,0),(0,1) (4,0),(0,1)这两个组合,那么接收者的期望收益就是 0 ∗ 0.5 + 1 ∗ 0.5 = 0.5 0*0.5+1*0.5=0.5 0∗0.5+1∗0.5=0.5。根据期望收益最大化的原则,我们选择 a 1 a_1 a1作为行动。所以我们通过计算就可以得出,如果发送方固定选择发送 m 1 m_1 m1作为发送信号的话,接收方会用 a 1 a_1 a1这个行动作为应对,因为 a 1 a_1 a1这个行动会使得接收方获得最大的期望收益。那么接收方在用 a 1 a_1 a1这个行动时,收益组合就是要么是 ( 1 , 3 ) (1,3) (1,3),要么是 ( 2 , 4 ) (2,4) (2,4)。可以看到发送方的收益值要么是1要么是3。
那么如果想让这个策略可以达成一个均衡,我们要推导出的是使得“发送方选择 m 2 m_2 m2作为信号发送的时候发送方的收益不会有这么多”成立的条件。
那么下面看如果发送方选择发送 m 2 m_2 m2的话:
m 2 → { a 1 { θ 1 : ( 2 , 1 ) θ 2 : ( 1 , 0 ) a 2 { θ 1 : ( 0 , 0 ) θ 2 : ( 1 , 2 ) m_2 \rightarrow\left\{\begin{array}{l} a_1\left\{\begin{array}{l} \theta_1:(2,1) \\ \theta_2:(1,0) \end{array}\right. \\ a_2\left\{\begin{array}{l} \theta_1:(0,0) \\ \theta_2:(1,2) \end{array}\right. \end{array}\right. m2→⎩ ⎨ ⎧a1{θ1:(2,1)θ2:(1,0)a2{θ1:(0,0)θ2:(1,2)
两种类型的发送者是否都愿意选择 m 1 m_1 m1,要分析接收者对 m 2 m_2 m2将如何反应。
若 2 ( 1 − q ) + q ∗ 0 ≥ q ∗ 1 + ( 1 − q ) ∗ 0 → q ≤ 2 / 3 2(1-q)+q*0≥q*1+(1-q)*0\rightarrow q≤2/3 2(1−q)+q∗0≥q∗1+(1−q)∗0→q≤2/3,接收者对 m 2 m_2 m2的反应必为 a 2 a_2 a2。
所以如果满足 q ≤ 2 / 3 q≤2/3 q≤2/3,那么就会发生:发送人发送 m 2 m_2 m2的话,接收人一定要选择 a 2 a_2 a2来确保自己获得最大期望收益。而发送人选择 a 2 a_2 a2的时候接收人获得的收益我们看看是多少:如果接收人是 θ 1 \theta_1 θ1的话,发送 m 2 m_2 m2,接收人选择 a 2 a_2 a2应对,那么收益组合是(0,0),发送人的收益是0,如果发送人发送的是 m 1 m_1 m1,接收人会用 a 1 a_1 a1来应对,此时收益组合是(1,3),此时发送人的收益是1。同理可以分析发送人为 θ 2 \theta_2 θ2的时候的收益值,也可以得到相同的结论,就是发送 m 1 m_1 m1的收益值会大于发送 m 2 m_2 m2的收益值。所以我们就确定了, q ≤ 2 / 3 q≤2/3 q≤2/3就是这个混同均衡成立的条件。
所以混同均衡为:
[ ( m 1 , m 1 ) , ( a 1 , a 2 ) , p = 0.5 , q ≤ 2 / 3 ] \left[\left(m_1, m_1\right),\left(a_1, a_2\right), p=0.5, q \leq 2 / 3\right] [(m1,m1),(a1,a2),p=0.5,q≤2/3]
上面 ( m 1 , m 1 ) (m_1,m_1) (m1,m1),指的是两个类型的发送人都选择发送 m 1 m_1 m1。
( a 1 , a 2 ) (a_1,a_2) (a1,a2)中的 a 1 a_1 a1指的是在发送方选择发送 m 1 m_1 m1的时候接收方会选择 a 1 a_1 a1作为应对。后面的 a 2 a_2 a2指的是保证了当前面的 ( m 1 , m 1 ) (m_1,m_1) (m1,m1)条件不成立的时候他会选择 a 2 a_2 a2,所以这个条件也是使得发送方不愿意发送 m 2 m_2 m2的制约条件。
也就是 ( m 2 , a 2 ) (m_2,a_2) (m2,a2)不在均衡路径上,但是他是促使 ( m 1 , a 1 ) (m_1,a_1) (m1,a1)这个均衡路径成立的条件。如果没有这个限制, ( m 1 , a 1 ) (m_1,a_1) (m1,a1)这个均衡就难以保证。所以即使他不在均衡路径上,但是他保证了均衡的实现,同时如果 ( m 1 , a 1 ) (m_1,a_1) (m1,a1)不成立,后面就会发生 ( m 2 , a 2 ) (m_2,a_2) (m2,a2)这样的情况。
所以我们的思路总结一下就是:根据构造均衡的几个出发点(四种均衡类型)构造出一个,然后来进行推断,推断过后得出一个均衡能够成为一个均衡所需要具备的条件,以及不在均衡路径上的要促使均衡实现的制约条件是什么
②混同于 m 2 m^2 m2:发送者在类型 θ 1 \theta^1 θ1和 θ 2 \theta^2 θ2下均选择信号 m 2 m^2 m2。
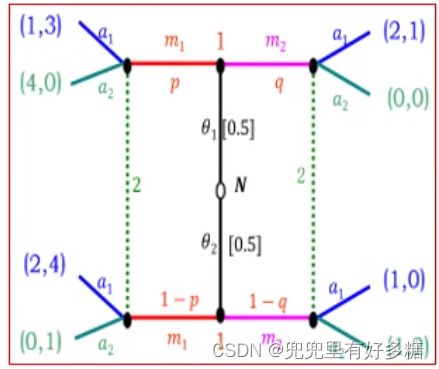
θ 1 θ 2 } → m 2 ⟶ 推断 ( q , 1 − q ) = ( 0.5 , 0.5 ) ⟶ 1 ∗ 0.5 < 2 ∗ 0.5 a 2 → { θ 1 : ( 0 , 0 ) θ 2 : ( 1 , 2 ) \begin{aligned} & \left.\begin{array}{l} \theta_1 \\ \theta_2 \end{array}\right\} \rightarrow m_2 \stackrel{\text {推断}}{\longrightarrow}(q, 1-q)=(0.5,0.5) \\ & \stackrel{1*0.5<2*0.5}{\longrightarrow} a_2 \rightarrow\left\{\begin{array}{l} \theta_1:(0,0) \\ \theta_2:(1,2) \end{array}\right. \\ & \end{aligned} θ1θ2}→m2⟶推断(q,1−q)=(0.5,0.5)⟶1∗0.5<2∗0.5a2→{θ1:(0,0)θ2:(1,2)
但 θ 1 → m 1 ⟶ a 1 > a 2 ,接收方会选择 a 2 的战略 a 1 → ( 1 , 3 ) \theta_1\rightarrow m_1 \stackrel{a_1>a_2,接收方会选择a_2的战略}{\longrightarrow}a_1\rightarrow(1,3) θ1→m1⟶a1>a2,接收方会选择a2的战略a1→(1,3)
因此,类型 θ 1 \theta^1 θ1不愿意发送 m 2 m^2 m2
于是不存在发送者战略为 ( m 2 , m 2 ) (m^2,m^2) (m2,m2)的均衡。
③分离均衡: θ 1 \theta^1 θ1选择 m 1 m^1 m1, θ 2 \theta^2 θ2选择 m 2 m^2 m2

第一步还是根据我们规定的发送者的战略分析出接收者会采取的战略
θ 1 → m 1 ⟶ 推断 ( p , 1 − p ) ⟶ p = μ ( θ 1 ∣ m 1 ) = μ ( θ 1 ) / μ ( θ 1 ) = 1 ( 1 , 0 ) ⟶ 选择 a 1 得到的收益是 3 ,选择 a 2 得到 0 ,所以 a 1 ≻ a 2 ,当然选择 a 1 a 1 → θ 1 : ( 1 , 3 ) \begin{aligned} & \theta_1 \rightarrow m_1 \stackrel{\text { 推断 }}{\longrightarrow}(p, 1-p) \stackrel{p=\mu\left(\theta_1 \mid m_1\right)=\mu\left(\theta_1\right) / \mu\left(\theta_1\right)=1}{\longrightarrow}(1,0) \\ & \stackrel{选择a_1得到的收益是3,选择a_2得到0,所以a_1 \succ a_2,当然选择a_1}{\longrightarrow} a_1 \rightarrow \theta_1: \quad(1,3) \end{aligned} θ1→m1⟶ 推断 (p,1−p)⟶p=μ(θ1∣m1)=μ(θ1)/μ(θ1)=1(1,0)⟶选择a1得到的收益是3,选择a2得到0,所以a1≻a2,当然选择a1a1→θ1:(1,3)
第二步是看看接收者采取上面我们推断出来的战略的时候,发送者的有没有比我们规定的战略更好的战略,也就是检验既定战略是否是最优的
θ 2 → m 2 ⟶ 推断 ( q , 1 − q ) ⟶ 1 − q = μ ( θ 2 ∣ m 2 ) = μ ( θ 2 ) / μ ( θ 2 ) = 1 ( 0 , 1 ) ⟶ a 2 → θ 2 : ( 1 , 2 ) \begin{aligned} & \theta_2 \rightarrow m_2 \stackrel{\text { 推断 }}{\longrightarrow}(q, 1-q) \stackrel{1-q=\mu\left(\theta_2 \mid m_2\right)=\mu\left(\theta_2\right) / \mu\left(\theta_2\right)=1}{\longrightarrow}(0,1) \\ &{\longrightarrow} a_2 \rightarrow \theta_2: \quad(1,2) \end{aligned} θ2→m2⟶ 推断 (q,1−q)⟶1−q=μ(θ2∣m2)=μ(θ2)/μ(θ2)=1(0,1)⟶a2→θ2:(1,2)
检验对给定的接收者战略 a 1 , a 2 a^1,a^2 a1,a2,发送者的战略是否最优:
θ 2 → m 1 ⟶ a 1 > a 2 a 1 → ( 2 , 1 ) \theta_2\rightarrow m_1 \stackrel{a_1>a_2}{\longrightarrow}a_1\rightarrow(2,1) θ2→m1⟶a1>a2a1→(2,1)
因此,类型 θ 2 \theta_2 θ2不愿意发送 m 2 m^2 m2
于是不存在发送者战略为 ( m 1 , m 2 ) (m^1,m^2) (m1,m2)的均衡。
④分离均衡: θ 1 \theta^1 θ1选择 m 2 m^2 m2, θ 2 \theta^2 θ2选择 m 1 m^1 m1

θ 1 → m 2 ⟶ 推断 ( q , 1 − q ) ⟶ q = μ ( θ 1 ∣ m 2 ) = μ ( θ 1 ) / μ ( θ 1 ) = 1 ( 1 , 0 ) ⟶ a 1 ≻ a 2 a 1 → θ 1 : ( 2 , 1 ) \begin{aligned} & \theta_1 \rightarrow m_2 \stackrel{\text { 推断 }}{\longrightarrow}(q, 1-q) \stackrel{q=\mu\left(\theta_1 \mid m_2\right)=\mu\left(\theta_1\right) / \mu\left(\theta_1\right)=1}{\longrightarrow}(1,0) \\ &\stackrel{a_1 \succ a_2}{\longrightarrow} a_1 \rightarrow \theta_1: \quad(2,1) \end{aligned} θ1→m2⟶ 推断 (q,1−q)⟶q=μ(θ1∣m2)=μ(θ1)/μ(θ1)=1(1,0)⟶a1≻a2a1→θ1:(2,1)
θ 2 → m 1 ⟶ 推断 ( p , 1 − p ) ⟶ 1 − p = μ ( θ 2 ∣ m 1 ) = μ ( θ 2 ) / μ ( θ 2 ) = 1 ( 0 , 1 ) ⟶ a 1 ≻ a 2 a 1 → θ 2 : ( 2 , 4 ) \begin{aligned} & \theta_2 \rightarrow m_1 \stackrel{\text { 推断 }}{\longrightarrow}(p, 1-p) \stackrel{1-p=\mu\left(\theta_2 \mid m_1\right)=\mu\left(\theta_2\right) / \mu\left(\theta_2\right)=1}{\longrightarrow}(0,1) \\ & \stackrel{a_1 \succ a_2}{\longrightarrow} a_1 \rightarrow \theta_2: \quad(2,4) \end{aligned} θ2→m1⟶ 推断 (p,1−p)⟶1−p=μ(θ2∣m1)=μ(θ2)/μ(θ2)=1(0,1)⟶a1≻a2a1→θ2:(2,4)
θ 1 → m 1 ⟶ a 1 > a 2 a 1 → ( 1 , 3 ) \theta_1\rightarrow m_1 \stackrel{a_1>a_2}{\longrightarrow}a_1\rightarrow(1,3) θ1→m1⟶a1>a2a1→(1,3)
θ 2 → m 2 ⟶ a 1 → ( 1 , 0 ) \theta_2\rightarrow m_2 {\longrightarrow}a_1\rightarrow(1,0) θ2→m2⟶a1→(1,0)
所以,分离精炼贝叶斯均衡为:
[ ( m 2 , m 1 ) , ( a 1 , a 1 ) , p = 0 , q = 1 ] [(m_2,m_1),(a_1,a_1),p=0,q=1] [(m2,m1),(a1,a1),p=0,q=1]
【例题】求下列信号博弈的纳什均衡(解法二)
首先看接收方根据接收到的信息做出的行为选择:
①当接受到 m 1 m^1 m1后其行动须使期望收益最大化,即
a ∗ ( m 1 ) ∈ arg max E U [ θ i , m 1 , a k ( m 1 ) ] max E U [ θ i , m 1 , a k ( m 1 ) ] = max { 3 p + 4 ( 1 − p ) , ( 1 − p ) } = max { 4 − p , 1 − p } = 4 − p ∴ a ∗ ( m 1 ) = a 1 \begin{aligned} & a^*\left(m^1\right) \in \arg \max E U\left[\theta^i, m^1, a_k\left(m^1\right)\right] \\ & \max E U\left[\theta^i, m^1, a_k\left(m^1\right)\right] \\ & =\max \{3 p+4(1-p),(1-p)\} \\ & =\max \{4-p, 1-p\}=4-p \\ & \therefore \quad a^*\left(m^1\right)=a^1 \end{aligned} a∗(m1)∈argmaxEU[θi,m1,ak(m1)]maxEU[θi,m1,ak(m1)]=max{3p+4(1−p),(1−p)}=max{4−p,1−p}=4−p∴a∗(m1)=a1
②当接受到 m 2 m^2 m2后其行动须使期望收益最大化,即
a ∗ ( m 2 ) ∈ arg max E U [ θ i , m 2 , a k ( m 2 ) ] max E U [ θ i , m 2 , a k ( m 2 ) ] = max { q , 2 ( 1 − q ) } = max { q , 2 − 2 q } = { q , q > 2 / 3 2 − 2 q , q ≤ 2 / 3 ∴ a ∗ ( m 2 ) = { a 1 , q > 2 / 3 a 2 , q ≤ 2 / 3 \begin{aligned} & a^*\left(m^2\right) \in \arg \max E U\left[\theta^i, m^2, a_k\left(m^2\right)\right] \\ & \max E U\left[\theta^i, m^2, a_k\left(m^2\right)\right] \\ & =\max \{q, 2(1-q)\}=\max \{q, 2-2 q\} \\ & =\left\{\begin{array}{l} q, q>2 / 3 \\ 2-2 q, q \leq 2 / 3 \end{array}\right. \\ & \therefore \quad a^*\left(m^2\right)=\left\{\begin{array}{l} a^1, q>2 / 3 \\ a^2, q \leq 2 / 3 \end{array}\right. \end{aligned} a∗(m2)∈argmaxEU[θi,m2,ak(m2)]maxEU[θi,m2,ak(m2)]=max{q,2(1−q)}=max{q,2−2q}={q,q>2/32−2q,q≤2/3∴a∗(m2)={a1,q>2/3a2,q≤2/3
然后看发送方如何选择:
③当发送者类型为 θ 1 \theta^1 θ1,在给定接受者的最优行动条件下,发送者选择信号 m m m使其效用最大化,即:
m ∗ ( θ 1 ) ∈ argmax U [ θ 1 , m j , a ∗ ( m j ) ] ( a ∗ 就表示给定的接收者的最优行动条件 ) max U [ θ 1 , m j , a ∗ ( m j ) ] 根据前面的推导可以知道:接收到 m 1 的时候,接收者一定会选择 a 1 但是接收到 m 2 的时候接收方不一定选择哪一个行动,具体要看 q 的取值 , 所以就有了下面两个式子: = { m a x { U ( θ 1 , m 1 , a 1 ) , U ( θ 1 , m 2 , a 1 ) } , q > 2 / 3 m a x { U ( θ 1 , m 1 , a 1 ) , U ( θ 1 , m 2 , a 2 ) } , q ≤ 2 / 3 { m a x { 1 , 2 } = 2 , q > 2 / 3 m a x { 1 , 0 } = 1 , q ≤ 2 / 3 m ∗ ( θ 1 ) = { m 2 , q > 2 / 3 m 1 , q ≤ 2 / 3 \begin{aligned} & m^*\left(\theta^1\right) \in \operatorname{argmax} U\left[\theta^1, m^j, a^*\left(m^j\right)\right] \\ &(a^*就表示给定的接收者的最优行动条件)\\ & \max U\left[\theta^1, m^j, a^*\left(m^j\right)\right] \\ &根据前面的推导可以知道:接收到m_1的时候,接收者一定会选择a_1\\ &但是接收到m_2的时候接收方不一定选择哪一个行动,具体要看q的取值,所以就有了下面两个式子:\\ & =\left\{\begin{array}{l} \mathrm{max}\left\{U\left(\theta^1, m^1, a^1\right), U\left(\theta^1, m^2, a^1\right)\right\}, q>2 / 3 \\ \mathrm{max}\left\{U\left(\theta^1, m^1, a^1\right), U\left(\theta^1, m^2, a^2\right)\right\}, q \leq 2 / 3 \end{array}\right. \\ & \left\{\begin{array}{l} \mathrm{max}\{1,2\}=2, q>2 / 3 \\ \mathrm{max}\{1,0\}=1, q \leq 2 / 3 \end{array}\right. \\ & m^*\left(\theta^1\right)=\left\{\begin{array}{l} m^2, q>2 / 3 \\ m^1, q \leq 2 / 3 \end{array}\right. \end{aligned} m∗(θ1)∈argmaxU[θ1,mj,a∗(mj)](a∗就表示给定的接收者的最优行动条件)maxU[θ1,mj,a∗(mj)]根据前面的推导可以知道:接收到m1的时候,接收者一定会选择a1但是接收到m2的时候接收方不一定选择哪一个行动,具体要看q的取值,所以就有了下面两个式子:={max{U(θ1,m1,a1),U(θ1,m2,a1)},q>2/3max{U(θ1,m1,a1),U(θ1,m2,a2)},q≤2/3{max{1,2}=2,q>2/3max{1,0}=1,q≤2/3m∗(θ1)={m2,q>2/3m1,q≤2/3
④当发送者类型为 θ 2 \theta^2 θ2,在给定接受者的最优行动条件下,发送者选择信号 m m m使其效用最大化,即:
m ∗ ( θ 2 ) ∈ arg max U [ θ 2 , m j , a ∗ ( m j ) ] max U [ θ 2 , m j , a ∗ ( m j ) ] = { max { U ( θ 2 , m 1 , a 1 ) , U ( θ 2 , m 2 , a 1 ) } , q > 2 / 3 max { U ( θ 2 , m 1 , a 1 ) , U ( θ 2 , m 2 , a 2 ) } , q ≤ 2 / 3 { max { 2 , 1 } = 2 , q > 2 / 3 max { 2 , 1 } = 2 , q ≤ 2 / 3 ∴ m ∗ ( θ 2 ) = m 1 \begin{aligned} & m^*\left(\theta^2\right) \in \arg \max U\left[\theta^2, m^j, a *\left(m^j\right)\right] \\ & \max U\left[\theta^2, m^j, a *\left(m^j\right)\right] \\ & =\left\{\begin{array}{l} \max \left\{U\left(\theta^2, m^1, a^1\right), U\left(\theta^2, m^2, a^1\right)\right\}, q>2 / 3 \\ \max \left\{U\left(\theta^2, m^1, a^1\right), U\left(\theta^2, m^2, a^2\right)\right\}, q \leq 2 / 3 \end{array}\right. \\ & \left\{\begin{array}{l} \max \{2,1\}=2, q>2 / 3 \\ \max \{2,1\}=2, q \leq 2 / 3 \end{array}\right. \\ & \therefore \quad m^*\left(\theta^2\right)=m^1 \end{aligned} m∗(θ2)∈argmaxU[θ2,mj,a∗(mj)]maxU[θ2,mj,a∗(mj)]={max{U(θ2,m1,a1),U(θ2,m2,a1)},q>2/3max{U(θ2,m1,a1),U(θ2,m2,a2)},q≤2/3{max{2,1}=2,q>2/3max{2,1}=2,q≤2/3∴m∗(θ2)=m1
综合得到初步的均衡结果如下:
{ a ∗ ( m 1 ) = a 1 a ∗ ( m 2 ) = { a 1 , q > 2 / 3 a 2 , q ≤ 2 / 3 \left\{\begin{array}{l} a *\left(m^1\right)=a^1 \\ a^*\left(m^2\right)=\left\{\begin{array}{l} a^1, q>2 / 3 \\ a^2, q \leq 2 / 3 \end{array}\right. \end{array}\right. ⎩ ⎨ ⎧a∗(m1)=a1a∗(m2)={a1,q>2/3a2,q≤2/3
{ m ∗ ( θ 1 ) = { m 1 , q > 2 / 3 m 2 , q ≤ 2 / 3 m ∗ ( θ 2 ) = m 1 \left\{\begin{array}{l} m^*\left(\theta^1\right)=\left\{\begin{array}{l} m^1, q>2 / 3 \\ m^2, q \leq 2 / 3 \end{array}\right. \\ m^*\left(\theta^2\right)=m^1 \end{array}\right. ⎩ ⎨ ⎧m∗(θ1)={m1,q>2/3m2,q≤2/3m∗(θ2)=m1
{ ( m 1 , m 1 ) , ( a 1 , a 2 ) } , q ≤ 2 / 3 { ( m 2 , m 1 ) , ( a 1 , a 1 ) } , q > 2 / 3 \begin{aligned} &\left\{\left(m^1, m^1\right),\left(a^1, a^2\right)\right\}, q \leq 2 / 3\\ &\left\{\left(m^2, m^1\right),\left(a^1, a^1\right)\right\}, q>2 / 3 \end{aligned} {(m1,m1),(a1,a2)},q≤2/3{(m2,m1),(a1,a1)},q>2/3
然后还要检验我们推断出的均衡是否满足不完美信息动态博弈的要求3和要求4(即无论在不在均衡路径上都要符合贝叶斯法则)。
对于第一个均衡,按照要求3,4分析:
p ( m 1 ∣ θ 1 ) = 1 , p ( m 2 ∣ θ 1 ) = 0 p ( m 1 ∣ θ 2 ) = 1 , p ( m 2 ∣ θ 1 ) = 0 μ ( θ 1 ∣ m 1 ) = 1 × 0.5 1 × 0.5 + 1 × 0.5 = 1 2 μ ( θ 2 ∣ m 1 ) = 1 × 0.5 1 × 0.5 + 1 × 0.5 = 1 2 μ ( θ 1 ∣ m 2 ) < 2 3 μ ( θ 2 ∣ m 2 ) ≥ 2 3 { ( m 1 , m 1 ) , ( a 1 , a 2 ) } , p = 1 / 2 , q ≤ 2 / 3 \begin{array}{ll} p\left(m^1 \mid \theta^1\right)=1, p\left(m^2 \mid \theta^1\right)=0 & p\left(m^1 \mid \theta^2\right)=1, p\left(m^2 \mid \theta^1\right)=0 \\ \mu\left(\theta^1 \mid m^1\right)=\frac{1 \times 0.5}{1 \times 0.5+1 \times 0.5}=\frac{1}{2} & \mu\left(\theta^2 \mid m^1\right)=\frac{1 \times 0.5}{1 \times 0.5+1 \times 0.5}=\frac{1}{2} \\ \mu\left(\theta^1 \mid m^2\right)<\frac{2}{3} & \mu\left(\theta^2 \mid m^2\right) \geq \frac{2}{3} \\ \left\{\left(m^1, m^1\right),\left(a^1, a^2\right)\right\}, p=1 / 2, q \leq 2 / 3 \end{array} p(m1∣θ1)=1,p(m2∣θ1)=0μ(θ1∣m1)=1×0.5+1×0.51×0.5=21μ(θ1∣m2)<32{(m1,m1),(a1,a2)},p=1/2,q≤2/3p(m1∣θ2)=1,p(m2∣θ1)=0μ(θ2∣m1)=1×0.5+1×0.51×0.5=21μ(θ2∣m2)≥32
对于第二个均衡,按照要求3,4分析:
p ( m 1 ∣ θ 1 ) = 0 p ( m 2 ∣ θ 1 ) = 1 p ( m 1 ∣ θ 2 ) = 1 p ( m 2 ∣ θ 1 ) = 0 μ ( θ 1 ∣ m 1 ) = 0 μ ( θ 1 ∣ m 2 ) = 1 μ ( θ 2 ∣ m 1 ) = 1 μ ( θ 2 ∣ m 2 ) = 0 { ( m 2 , m 1 ) , ( a 1 , a 2 ) } , p = 0 , q = 1 \begin{array}{|ll|} \hline p\left(m^1 \mid \theta^1\right)=0 & p\left(m^2 \mid \theta^1\right)=1 \\ p\left(m^1 \mid \theta^2\right)=1 & p\left(m^2 \mid \theta^1\right)=0 \\ \mu\left(\theta^1 \mid m^1\right)=0 & \mu\left(\theta^1 \mid m^2\right)=1 \\ \mu\left(\theta^2 \mid m^1\right)=1 & \mu\left(\theta^2 \mid m^2\right)=0 \\ \left\{\left(m^2, m^1\right),\left(a^1, a^2\right)\right\}, & p=0, q=1 \end{array} p(m1∣θ1)=0p(m1∣θ2)=1μ(θ1∣m1)=0μ(θ2∣m1)=1{(m2,m1),(a1,a2)},p(m2∣θ1)=1p(m2∣θ1)=0μ(θ1∣m2)=1μ(θ2∣m2)=0p=0,q=1
【例题】二手车交易博弈模型
二手车交易博弈的参与者 i = 1 , 2 i=1,2 i=1,2,参与者1为卖主,参与者2为买主。参与者1的类型空间为 T = { t 1 , t 2 } T=\left\{t1,t2\right\} T={t1,t2},其中 t 1 t_1 t1表示卖主所出售的二手车是低质量的, t 2 t_2 t2表示卖主出售的二手车是高质量的。参与者1知道自己的类型,参与者2不知道,但参与者2对两种类型具有信念 P ( t ) = α P(t)= α P(t)=α, P ( t 2 ) = 1 − α P(t2)= 1-α P(t2)=1−α。参与者1的信号空间为KaTeX parse error: Expected '}', got 'EOF' at end of input: M={P1,Pz3,其中 p r , p 2 pr,p2 pr,p2分别表示卖主对二手车的两种不同的要价, p 1 < P z p1
设卖主将低质量的二手车伪装成高质量二车手所需付出的成本为 c c c,买主购得高质量二手车的价值为 V V V,买主购买低质量二手车的价值为 W W W,且 W < V W
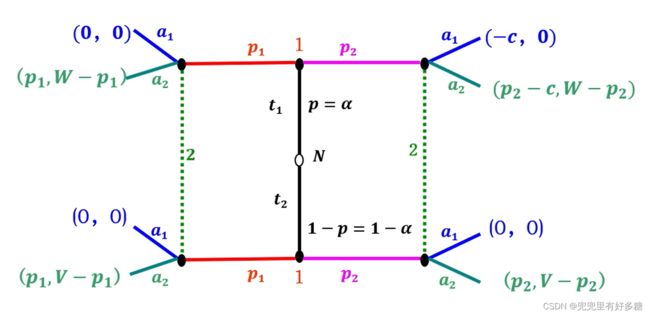
- p = P ( t 1 ∣ p 1 ) , 1 − p = P ( t 2 ∣ p 1 ) ; q = P ( t 1 ∣ p 2 ) , 1 − q = P ( t 2 ∣ p 2 ) \text { - } p=P\left(t_1 \mid p_1\right), 1-p=P\left(t_2 \mid p_1\right) ; q=P\left(t_1 \mid p_2\right), 1-q=P\left(t_2 \mid p_2\right) - p=P(t1∣p1),1−p=P(t2∣p1);q=P(t1∣p2),1−q=P(t2∣p2)
①买主(参与者2)的行为选择
max a i ∈ { a 1 , a 2 } ∑ t k ∈ T P ( t k ∣ p j ) ⋅ u 2 ( t k , p j , a i ) = max a i ∈ { a 1 , a 2 } [ P ( t 1 ∣ p j ) ⋅ u 2 ( t 1 , p j , a i ) + P ( t 2 ∣ p j ) ⋅ u 2 ( t 2 , p j , a i ) ] \begin{aligned} & \max _{a_i \in\left\{a_1, a_2\right\}} \sum_{t_k \in T} P(t k \mid p j) \cdot u_2(t k, p j, a i) \\ & =\max _{a_i \in\left\{a_1, a_2\right\}}\left[P\left(t_1 \mid p_j\right) \cdot u_2\left(t_1, p j, a_i\right)+P\left(t_2 \mid p_j\right) \cdot u_2\left(t_2, p j, a_i\right)\right] \\ & \end{aligned} ai∈{a1,a2}maxtk∈T∑P(tk∣pj)⋅u2(tk,pj,ai)=ai∈{a1,a2}max[P(t1∣pj)⋅u2(t1,pj,ai)+P(t2∣pj)⋅u2(t2,pj,ai)]
卖主要低价时,
max a i ∈ { a 1 , a 2 } [ p ⋅ u 2 ( t 1 , p 1 , a i ) + ( 1 − p ) ⋅ u 2 ( t 2 , p 1 , a i ) ] \max _{a_i \in\left\{a_1, a_2\right\}}\left[p \cdot u_2\left(t_1, p_1, a_i\right)+(1-p) \cdot u_2\left(t_2, p_1, a_i\right)\right] ai∈{a1,a2}max[p⋅u2(t1,p1,ai)+(1−p)⋅u2(t2,p1,ai)]
卖主要高价时,
max a i ∈ { a 1 , a 2 } [ q ⋅ u 2 ( t 1 , p 2 , a i ) + ( 1 − q ) ⋅ u 2 ( t 2 , p 2 , a i ) ] \max _{a_i \in\left\{a_1, a_2\right\}}\left[q \cdot u_2\left(t_1, p_2, a_i\right)+(1-q) \cdot u_2\left(t_2, p_2, a_i\right)\right] ai∈{a1,a2}max[q⋅u2(t1,p2,ai)+(1−q)⋅u2(t2,p2,ai)]
p × 0 + ( 1 − p ) × 0 = 0 p \times 0+(1-p) \times 0=0 p×0+(1−p)×0=0
p × ( W − p 1 ) + ( 1 − p ) × ( V − p 1 ) = V − p 1 − p ( V − W ) p \times\left(W-p_1\right)+(1-p) \times\left(V-p_1\right) \\ =V-p_1-p(V-W) p×(W−p1)+(1−