人间真实——用interpret可解释分析一下影响年薪收入的因素
导读
近年来,可解释AI(eXplainable AI,XAI)是人工智能的一个热门方向,相关研究内容呈现快速增长趋势。在众多可解释AI相关开源工具中,微软的interpret是一个功能比较全面、展示效果较好的代表,个人在学习了interpret文档后,发现其一个demo中用到的数据集为Adult数据集——一个用于预测个人年收入是否大于50K(单位:$)的人口普查数据集。所以,刚好用interpret来分析一下,影响年薪收入的因素都有哪些,以及影响程度如何!
interpret是微软开源的一款可解释AI工具,支持训练一个白盒模型或者解释一个黑盒/灰盒模型。关于白盒、黑盒、灰盒模型的区别在于:
黑盒模型是完全不具备可解释性的模型,典型的代表是深度学习模型,所以需要去解释,属于事后解释;
白盒模型是完全具有可解释性的模型,典型代表是线性模型和树模型,可以在模型训练时即获取对模型内在逻辑的理解;
灰盒模型是介于二者之间,但个人觉得没什么典型的代表
其中可解释性按照面向的对象,又可细分为全局可解释性和局部可解释性,一般来说,白盒模型既支持全局也支持局部可解释性,而灰黑和黑盒模型则一般是支持局部可解释性。全局和局部可解释的区别在于:
全局可解释性是基于全量数据集对模型的运行机理进行解释,典型的解释结果是特征重要性
局部可解释是对单个样本为何会得出如此的预测结果进行解释,具体包括哪些特征对预测结果贡献有多大
关于interpret的更多资料,可进一步查阅interpret官方文档:

interpret官方文档: https://interpret.ml/docs/intro.html
本文选用Adult数据集展开分析(在OpenML和UCI数据集网站上均可以获取),这是一份关于欧美多个国家的个人年收入的数据记录,任务类型是二分类,即基于个人基本信息作为特征,预测其年收入是否大于50K。这里首先看下数据集的基本信息:

如果对python自动化测试、web自动化、接口自动化、移动端自动化、面试经验交流等等感兴趣的测试人,可以 点这自行获取…
其中,Income列即是要预测的标签列,其余字段则是个人基本信息,从列名中可以基本猜到该字段的含义,而后对该数据集进行train_test_split,得到训练集和验证集。
train_cols = df.columns[0:-1]
label = df.columns[-1]
X = df[train_cols]
y = df[label]
seed = 1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=seed)
为了利用interpret开展全局和局部可解释性分析,我们选用一个白盒模型,这里以梯度提升树为例:
from interpret.glassbox import ExplainableBoostingClassifier
ebm = ExplainableBoostingClassifier(random_state=seed)
ebm.fit(X_train, y_train)
实际上,interpret中的模型沿用了sklearn中的API设计风格,即可以简单的通过调用fit和predict的形式完成模型的训练和预测,比如这里训练完成的模型即为ebm(ExplainableBoostingClassifier模型直接支持类别型特征的处理)。
一、全局可解释性分析
调用ebm的全局可解释性接口进行分析,并将结果以可视化图表的形式加以展示:
# 可视化设置
from interpret import set_visualize_provider
from interpret.provider import InlineProvider
set_visualize_provider(InlineProvider())
from interpret import show
# explain_global: 全局可解释性方法
ebm_global = ebm.explain_global()
show(ebm_global)
下图展示了各特征对模型预测结果的重要性,大体等价于常规的特征重要性分析:
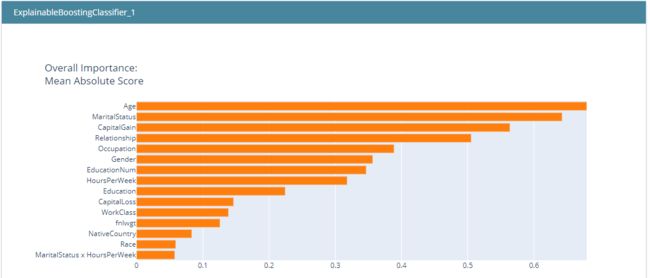
当然,特征重要性分析是可解释AI中最为基础的结果,甚至说直接用树模型也是可以得到的结论,当然interpret还提供了更为丰富和有价值的信息。我们进一步查看interpret对各特征的分析结果:
1.Age-年龄:
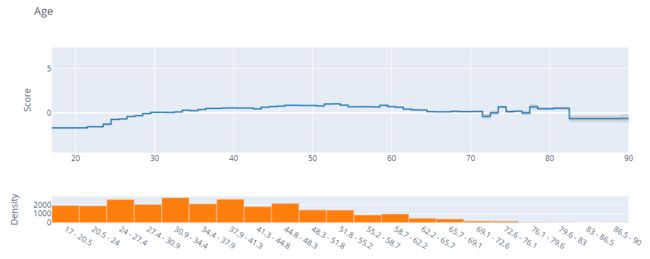
如图所示,上方score曲线展示的各年龄取值对于二分类预测结果评分的影响,评分越高越容易取得较高的概率结果(可理解为对模型的predict_prob的输出值影响);下面的Density则展示了在该数据集中该字段的取值密度分布。从中可以看出,大体上,年龄在20-50之间整体上Score随年龄的增加而现增长趋势,意味着年龄越大越有可能带来高收入(Income>50K),而后则略微呈现下降趋势。此外,在Score的变化曲线附近,还以阴影区域展示了该部分曲线数值的抖动范围,例如在上图中年龄大于70的部分可以较为明显看到灰色阴影区域,这是由于样本中该部分数据较少,意味着模型对其分析的结果置信度相对较低。
类似地,我们也可以分析一些类别型变量,例如:
2.Education-学历:
在该数据集中,学历特征分为受教育程度和受教育年限两个字段,分别来看:

受教育程度特征是一个离散特征,我们看到该特征的多数取值对于预测结果的贡献都是负的,这些取值大多是低教育程度,而在有正向贡献的特征取值中,粗略看了一下具有最大共享的是Education=Doctorate,即博士学位,看来博士学位还是吃香啊!
进一步地,我们看下受教育年限的影响,这是一个数值型特征,所以分析起来应该更直观一些:

结果非常明显:即随着受教育年限的增加,对于预测结果的贡献稳步上升(预测结果为1表示个人年收入>50K),看来多读书还是有好处。
当然,类似的还可以进一步分析其他特征对预测结果的影响,且这些图表都是可交互的(底层大概是基于plotly实现的可视化,不过文档中并未注明),非常方便查阅。
如果对python自动化测试、web自动化、接口自动化、移动端自动化、面试经验交流等等感兴趣的测试人,可以 点这自行获取…
这里推荐下我自己建的软件测试交流学习Q群:746506216,群里都是学测试的,如果你想学或者正在学习测试相关内容 ,欢迎你加入,大家都是测试党,不定期分享干货(只有软件测试相关的),包括我自己整理的一份2022最新的Python自动化测试进阶资料和零基础教学,欢迎想进阶学习、感兴趣的小伙伴加入!
二、局部可解释性分析
调用模型的局部可解释性分析接口,即可对特定的样本进行分析。这里我们选取测试集中的前5个样本进行分析:
# explain_local: 局部可解释性方法
ebm_local = ebm.explain_local(X_test[:5], y_test[:5])
show(ebm_local)
从结果中分别选择一个Income<50K和一个Income>50K的样本进行分析,得到如下结果:
1.一个Income<=50K的样本
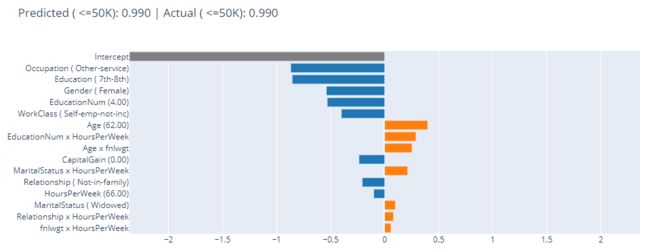
该样本的真实标签和预测结果都是<=50K,至于模型为何将其预测为<=50K呢,可以通过查看左侧的特征及其取值分析原因,例如:对预测结果倾向于0的前三个特征及取值包括:
Occupation=Other-service
Education=7th-9th
Gender=Female
即,模型认为该样本年薪低于50K的原因TOP3是:任职类型、教育程度低、女性。当然,该样本的部分特征取值也呈现一定的正向贡献,例如年龄及两个交叉衍生字段等,但终究其贡献度要低于预测为0的贡献,所以最终模型将其预测结果输出为0。
2.一个Income>50K的样本

该样本的真实标签和预测结果都是>50K,至于模型为何将其预测为>50K呢,发现影响该样本预测结果最显著的特征有且只有一个:Capital-Gain(该特征的含义大概是:投资收益),且其取值较高,约27K。这里,我们再进一步回到前面的全局可解释性分析结果,查看该特征不同取值对模型预测输出的影响:

果不其然,该特征的主要取值区间在0-3.85K,而该样本的该特征取值约27.8K(已经超过了带预测的目标年收入50K的一半),所以,纵然有其1.身份、2.任职类型、3.年龄和4.情感状态等不利因素,但该特征取值的出现还是直接决定了预测结果——将其预测结果输出为1。
太真实了,这大概是说:当一个人的投资收益很高时,不管其他状态如何,他的年收入大概率是高于50K的!好吧,这个道理是非常让人信服的,该模型的确是可解释的!
如果对python自动化测试、web自动化、接口自动化、移动端自动化、面试经验交流等等感兴趣的测试人,可以 点这自行获取…
这里推荐下我自己建的软件测试交流学习Q群:746506216,群里都是学测试的,如果你想学或者正在学习测试相关内容 ,欢迎你加入,大家都是测试党,不定期分享干货(只有软件测试相关的),包括我自己整理的一份2022最新的Python自动化测试进阶资料和零基础教学,欢迎想进阶学习、感兴趣的小伙伴加入!