etcd 架构原理学习(来自etcd实战)
文章目录
- 参考
- 防挂图 pdf 版
- 整体架构
-
- 基础模块介绍
- 写流程 简单了解
- 读流程 详细了解
-
- 串行读(数据敏感度低,适用计数等)
- 线性读(数据敏感度高,要求一致性)
- 写流程 详细了解
-
- 与读流程不一样的模块
-
- Quota 模块
- KVServer 模块(读流程有此模块)
-
- Preflight Check 检查
- WAL 模块
-
- WAL 记录类型(5种)
- WAL 日志的结构
- WAL 日志构成举例
- Apply 模块
-
- crash-safe 如何实现
- 幂等性如何实现?
- MVCC 模块
-
- treeIndex
- boltdb
- Raft 实现高可用,数据一致性
-
- 多种多副本复制方法利弊分析
- 共识算法——解决上述方法困境
- Raft 算法
-
- Leader 选举
-
- 三种角色
- 选举过程 简述
- 日志复制
-
- Raft 日志
- 解答疑问 1
- 解答疑问 2
- 日志流图梳理
- 安全性
-
- 选举规则
- 日志复制规则
-
- Leader 完全特性
- 只附加原则
- 日志匹配特性
- 鉴权
-
- 整体架构
-
- 控制面
- 数据面
-
- 如何安全存储密码
- 租约 Lease(检测客户端是否存活)
-
- 整体架构
- MVCC
-
- 整体架构
- treeIndex 原理
- MVCC 更新 key 原理
- MVCC 查询 key 原理
- MVCC 删除 key 原理
- Watch
-
- 带着问题去思考(4大核心问题)
- 轮询 vs 流式传输
- 滑动窗口 vs MVCC
- 可靠的时间推送机制
-
- 整体架构
- 核心解决方案(复杂度管理、问题拆分)
-
- synced watcher
- unsynced watcher
- 最新事件推送机制
- 异常场景重试机制
- 历史事件推送机制
- 高效的事件匹配
-
- 事务(安全实现多 key 操作)
- 整体流程
- 事务 ACID 特性
- boltdb 持久化存储你的 key-value 数据
-
- boltdb 磁盘布局
- boltdb API
- 核心数据结构介绍
-
- page 磁盘页结构
- meta page 数据结构
-
- meta page 十六进制分析
- bucket 数据结构
- leaf page
- branch page
- freelist
- Open 原理
- Put 原理
- 事务提交原理
- 压缩 回收旧版本数据
-
- 整体架构
- 压缩原理
- 为什么压缩后 db 大小不减少呢?
参考
- etcd 实战 极客时间
防挂图 pdf 版
链接: https://pan.baidu.com/s/1AthrvnoSPKyYrEA9pHthYA 提取码: 9ec0
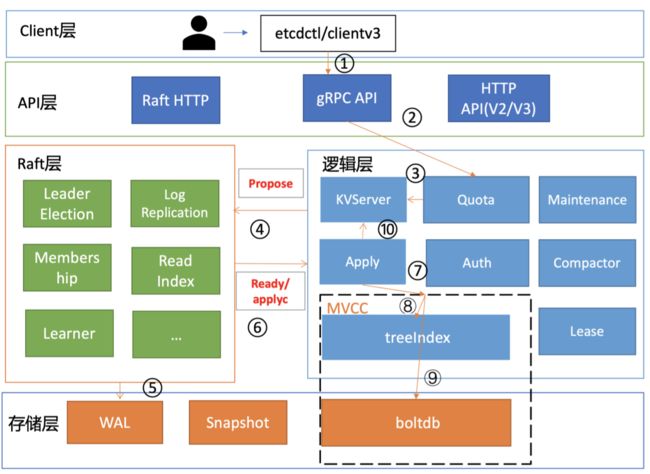
整体架构

基础模块介绍
- client 层: 包含 client v2 和 v3 两个大版本 API 客户端
- API 网络层:
- 主要包含 clent 访问 server 和 server 节点之间的通信协议
- clent 访问 server 分为两个版本:v2 API 采用 HTTP/1.x 协议,v3 API 采用 gRPC 协议
- server 之间的通信:是指节点间通过 Raft 算法实现数据复制和 Leader 选举等功能时使用的 HTTP 协议
- Raft 算法层:
- 实现了 Leader 选举、日志复制、ReadIndex 等核心算法特性
- 用于保障 etcd 多节点间的数据一致性、提升服务可用性等,是 etcd 的基石和亮点
- 功能逻辑层:
- etcd 核心特性实现层
- 如典型的 KVServer 模块、MVCC 模块、Auth 鉴权模块、Lease 租约模块、Compactor 压缩模块等
- 其中 MVCC 模块主要有 treeIndex 模块和 boltdb 模块组成
- 存储层:
- 包含预写日志 WAL 模块、快照 Snapshot 模块、 boltdb 模块
- 其中 WAL 可保障 etcd crash 后数据不丢失,boltdb 则保存了集群元数据和用户写入的数据
写流程 简单了解
-
简单了解一下写流程==
-
client 发起一个更新 hello 为 world 请求后
-
若 Leader 收到写请求,它会将此请求持久化到 WAL 日志,并广播给各个节点
a. 若一半以上节点持久化成功,则该请求对应的日志条目被标识为已提交
b. 之后,etcdserver 模块异步从 Raft 模块获取已提交的日志条目,应用到状态机(boltdb等)
-
读流程 详细了解

串行读(数据敏感度低,适用计数等)

- W——WAL 新数据;S——状态机 旧数据
- 串行读
- 直接读状态机数据返回、无需通过 Raft 协议与集群进行交互
- 具有低延迟、高吞吐量的特点
- 为什么串行读,会读到旧数据?
- 因为 Follower 节点收到 Leader 节点的同步些请求后,应用日志条目到状态机是个异步过程
- 因此产生一种需求,能否确保最新的数据已经应用到状态机中?—— 产生了线性读 ReadIndex 机制
线性读(数据敏感度高,要求一致性)
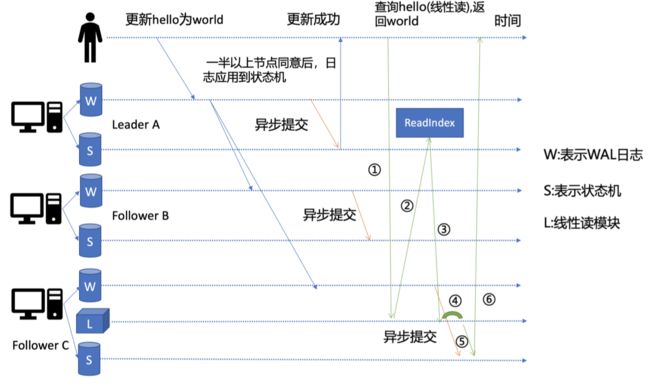
- 线性读 ReadIndex,原理图如上所示,以下简要文字描述
- Follower C 收到一个线性读请求时,首先会从 Leader 获取集群最新的已提交的日志索引(committed index),如上图流程2(发起请求)
- Leader 收到 ReadIndex 请求时,为了防止脑裂等异常场景,会向 Follower 节点发送心跳确认
- 一半以上节点确认 Leader 身份后,才能将已提交的索引(committed index)返回给节点 C (上图流程3)
- C 节点会等待,直到状态机已应用索引(applied index)大于等于 Leader 的已提交索引时(committed index)(见上图流程4)
- 然后去通知读请求,数据已赶上 Leader,可以去状态机中访问数据了(上图流程5)
简而言之,就是当前节点向 Leader 问”你进行到哪了“,Leader 回复一个当前号码”committed index“,当前节点用自己的状态机号码"applied index"对比一下,若当前节点落后,则等一等,等到号码赶上
(这中间还会涉及到,Leader 是否是真正的 Leader,因此会采用心跳机制向周围节点确认,防止该 Leader 是个假的,也就是防止脑裂)
- 架构图中的流程梳理
- KVServer 模块收到线性读请求后,通过架构图中的流程 3 向 Raft 模块发起 ReadIndex 请求
- Raft 模块将 Leader 最新的已提交日志索引封装在架构图流程 4 的 ReadState 结构体中
- 通过 channel 层层返回给线性读模块
- 线性读模块等待本节点状态机追赶上 Leader 进度
- 追赶完成后,就通知 KVServer 模块,进行架构图中流程 5,与状态机中的 MVCC 模块进行交互了
写流程 详细了解

-
简单了解一下写流程
-
client 发起一个更新 hello 为 world 请求后
-
若 Leader 收到写请求,它会将此请求持久化到 WAL 日志,并广播给各个节点
a. 若一半以上节点持久化成功,则该请求对应的日志条目被标识为已提交
b. 之后,etcdserver 模块异步从 Raft 模块获取已提交的日志条目,应用到状态机(boltdb等)
-
回顾一下写入过程(详细版)
client 发送 put请求时,首先到达 KVServer 模块(此部分还有认证、鉴权、限速模块),之后到达 Raft 模块,将日志条目写入到 Wal 模块(持久化),之后将日志条目写入到 Raft 稳定日志(内存中),此时标记为已提交状态,之后到达 Apply 模块,此模块利用 consistent index 字段记录已执行的日志(这个也是保证了 crash-safe 和幂等性),之后达到 MVCC 模块,实现真正的存储,MVCC 模块包含两部分 treeIndex 和 boltdb,treeIndex 是在内存中,维护 版本号 和用户key的映射关系,真正的数据是存储在 boltdb 中,boltdb 中,key 为版本号,value 是个结构体(包含用户的 key-value信息、关联的 LeaseID 等),boltdb 也是存在内存中,因此需要将数据磁盘化进行持久化,但不可能一条数据一次提交,开销太昂贵,所以采用批量提交方式,因此提交一条数据的话,虽然标记已提交了,但是并未在存储状态机中,因此直接访问状态机,不会获得最新数据,为了解决此问题,etcd 引入 buffer 机制,一个作用是为了缓存,另一个也是为了存储还未存到状态机的新数据(从而可以对外服务),那么这一部分数据在哪呢?其实在 boltdb 的 buffer bucket 桶中。
etcd 重启时
Raft 日志 从 WAL 模块恢复
treeIndex 从 boltdb 模块恢复
与读流程不一样的模块
- 相比于读流程,写流程还涉及到 Quota、WAL、Apply 三个模块
- crash-safe 及幂等性也正是基于 WAL 和 Apply 流程的 consistant index 实现的
- crash-safe 就是保证发生故障时,仍可以正常回复
- 幂等性就是 一个操作多次提交,但结果和 一次提交执行的结果相同,不会产生多次重复操作
Quota 模块
- 检查是否还有存储空间,去存新增数据
- 默认 db 配额是 2G
- 工作原理
- 当 etcd server 收到 put/txn 等写请求时,会首先检查当前 etcd db 大小加上你请求的 key-value 大小之和是否超过了配额(quota-backend-bytes)
- 若超过了配额,会产生告警 Alarm 请求,告警类型是 NO SPACE
- 并通过 Raft 日志同步给其他节点,告知 db 无空间了,并将告警持久化存储到 db 中
- 当把配额调大后,为什么集群依然拒绝写入?
- 因为 Apply 模块在执行每个命令的时候,都会检查当前是否存在 NO SPACE 告警
- 如果有,则拒绝写入
- 所以,需要你额外发送一个取消告警(etcdctl alarm disarm)的命令,以消除所有告警
- 因为 Apply 模块在执行每个命令的时候,都会检查当前是否存在 NO SPACE 告警
- etcd 社区建议配额不要超过 8 G
- 另外如何预防这种超配额问题呢?
- 在压缩模块设置合理的压缩策略,用来回收旧版本
KVServer 模块(读流程有此模块)
- 经过上面的配额检查后,到达此
- 此模块,需要将 put 写请求内容打包成一个提案消息,提交给 Raft 模块
- 不过载 KVServer 模块在提交提案前,还要做一些检查和限速
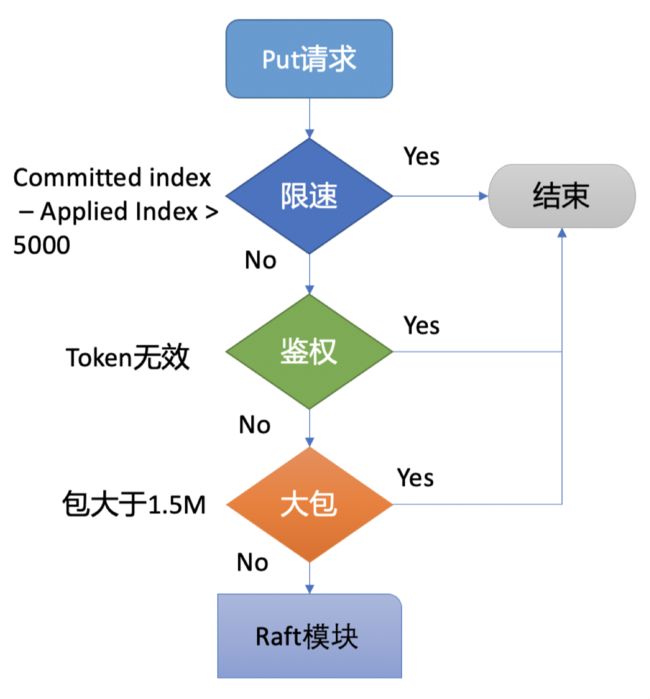
Preflight Check 检查
-
作用:为了保证集群稳定,避免雪崩,任何提交到 Raft 模块的请求,都会做一些简单的限速判断
-
什么时候限速呢?
- 例如,Raft模块已提交的日志索引(committed index)比已应用到状态机的日志索引(applied index)多了5000
- 就是 Raft 模块记录的日志多,状态机处理不过来了
-
同时还会检查 token的有效性,及包的大小
-
WAL 模块
- Raft 模块收到提案后
- 如果当前节点是 Follower 节点,则会转发给 Leader 节点
- 因为只有 Leader 节点才能处理写请求
- 之后 Leader 节点上的 etcdserver 从 Raft 模块获取以上的消息和日志条目后
- 会将 put 提案消息广播给集群各个节点
- 同时需要把集群 Leader 任期号、投票信息、已提交索引、提案内容持久化到一个 WAL(Write Ahead Log)日志文件中(用于保证集群的一致性、可恢复性),这个也就是上面的流程 5
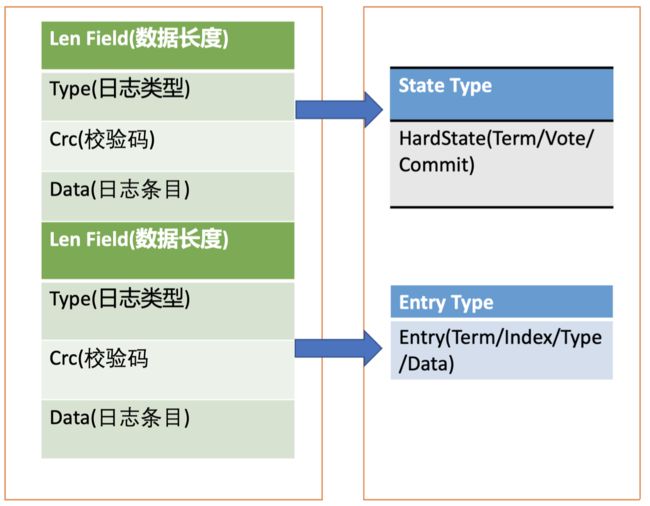
WAL 记录类型(5种)
- 文件元数据记录
- 包含节点 ID、集群 ID 信息,它在 WAL 文件创建的时候写入
- 日志条目记录
- 包含 Raft 日志信息,如 put 提案内容
- 状态信息记录
- 包含集群的任期号、节点投票信息等,一个日志文件中会有多条,以最后的记录为准
- CRC 记录
- 包含上一个 WAL 文件的最后的 CRC(循环冗余校验码)信息
- 在创建、切割 WAL 文件时,作为第一条记录写入到新的 WAL 文件,用于校验数据文件的完整性、准确性等
- 快照记录
- 包含快照的任期号、日志索引信息,用于检查快照文件的准确性
WAL 日志的结构
WAL 日志构成举例
以 日志条目记录 类型 为例,其数据结构,包含了如下字段
- Term 是 Leader 任期号,随着 Leader 选举增加
- Index 是日志条目的索引,单调递增增加
- Type 是日志类型,比如是普通的命令日志(EntryNormal)还是集群配置变更日志(EntryConfChange)
- Data 保存我们上面描述的 put 提案内容
再看 WAL 模块如何持久化 Raft 日志条目
- 首先将 Raft 日志条目内容(含任期号、索引、提案内容)序列化后保存到 WAL 记录的 Data 字段
- 然后计算 Data 的 CRC 值,设置 Type 为 Entry Type
- 以上信息就组成了一个完整的 WAL 记录
- 最后计算 WAL 记录的长度,顺序写入 WAL 长度(Len Field)
- 然后写入记录内容,调用 fsync 持久化到磁盘,完成日志条目保存到持久化存储中
当一半以上节点持久化此日志条目后,Raft 模块就会通过 channel 告知 etcdserver 模块,put 提案已经被集群多数节点确认,提案状态为已提交
于是进入了流程 6
etcdserver 模块从 channel 取出提案内容,添加到先进先出(FIFO)调度队列
随后通过 Apply 模块按入队顺序,异步、依次执行提案内容
Apply 模块
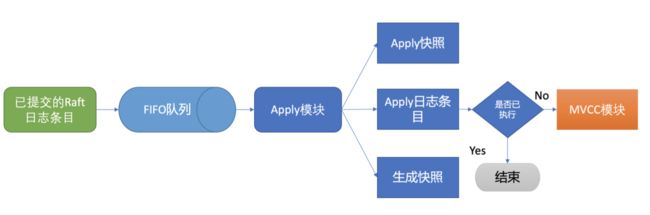
crash-safe 如何实现
核心就是 WAL 日志
- 若 put 请求提案在执行流程七的时候 etcd 突然 crash 了, 重启恢复的 时候,etcd 是如何找回异常提案,再次执行的呢?
- 因为 Raft 模块再将提案交给 Apply 模块前,已在 WAL 模块中进行持久化(就是 WAL 中的内容是获得多数节点确认的)
- 因此 etcd 重启时,会从 WAL 中解析出 Raft 日志条目内容,追加到 Raft 日志存储中,并重放已提交的日志提案给 Apply 模块执行
幂等性如何实现?
该考虑的问题 —— 如何确保幂等性,防止提案重复执行导致数据混乱?
引入 consistent index 字段,存储已执行过的日志条目索引
- 提案的唯一标识 —— 日志条目索引
- 日志条目索引是 全局单调递增的,每个日志条目索引对应一个提案
- 考虑利用日志条目索引,解决幂等性问题
- 考虑在db中,利用日志条目索引,记录其对应的执行状态
- 这样可以,但是不够安全
- 比如 命令的请求执行成功了,但在更新状态时发生失败了
- 因此需要将这两个操作(执行,状态更新)作为原子事务提交
- 所以 etcd 引入了一个 consistant index 字段,存储系统当前已经执行过的日志条目索引,实现幂等性
- 考虑在db中,利用日志条目索引,记录其对应的执行状态
MVCC 模块
Apply 模块 判断此提案未执行后,就会调用 MVCC 模块来执行提案内容
MVCC 模块主要由两部分组成
- 内存索引模块 treeIndex,保存 key 的历史版本号信息
- boltdb 模块,用来持久化存储 key-value 数据
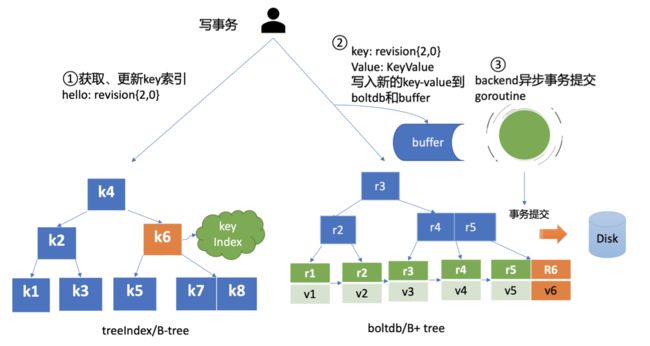
treeIndex
-
维护 key 与 版本号revision 的映射关系
-
版本号(revision)在 etcd 里发挥着重大作用,是 etcd 的逻辑时钟
- etcd 启动时的默认版本号是 1,随着对 key 的增删改操作,而全局单调递增
-
etcd 不需要持久化一个全局版本号
- 因为启动时,从最小值 1 开始枚举到最大值,未读到数据的时候结束,最后读出来的版本号,即为当前 etcd 的最大版本号 currentRevision
-
采用数据结构 B-tree
- 简单描述 B-tree 与 B+tree 的区别
- B-tree 中间节点存储数据
- B+tree 中间节点不存储数据,只存储索引,叶子节点存储所有节点的数据,利用链表连接起来,适合区间搜索
boltdb
- 基于 B+tree 实现的 key-value 嵌入式 db
- key 为 版本号revision,value包含的内容很丰富(要存储的key,value信息等)
- 重启时,treeIndex 也是根据 boltdb 重建的
- value 值就是以下信息的结构体序列化成的二进制数据
- 下面的 key 指的是用户的 key ,不是 版本号,value 指的是用户设置的 值
- key 名称
- key 创建时的版本号(create_revision)
- 最后一次修改时的版本号(mod_revison)
- key 自身修改的次数(version)
- value 值
- 租约信息(Lease)
- 通过提供桶(bucket)机制实现类似 MySQL 表的逻辑隔离
- 上面提到为了保证日志的幂等性,保存了一个名为 consistent index 的变量在 db 里面,实际上就存储在 元数据 meta 桶里面
通过 boltdb 提供的 put 接口,etcd 快速完成了将你的数据写入 boltdb,对应上面流程 2
但需要注意的是,以上流程中,etcd 并未提交事务(commit)
因此数据只更新在 boltdb 所管理的内存数据结构中,并未持久化到 db 文件中
一次一提交,开销昂贵,大大损失性能,因此 etcd 采用批量提交
未提交时,通过 buffer 读取,etcd 引入 bucket buffer 来保存暂未提交的事务数据
在更新 boltdb 时,etcd 也会同步数据到 bucket buffer
- 事务提交带来的性能损失
- 事务的提交过程,包含 B+tree 的平衡、分裂,将 boltdb 的脏数据(dirty page)、元数据信息刷新到磁盘上,因此事务提交的开销是昂贵的
- 若每次更新都提交事务,etcd 写性能就会较差
- 解决方法 —— 合并再合并(大白话,批量提交)
- 因为 boltdb key 是版本号,put/delete 操作是,版本号都是递增的,属于顺序写入
- 因此考虑调整 boltdb 的 bucket.FillPercent 参数,使每个 page 填充更多数据,减少 page 填充更多数据,减少 page 的分裂次数并降低 db 空间
- 此外,etcd 通过合并多个写事务请求,异步机制定时(默认每100ms)将批量事务一次性提交,大大提高吞吐量
- 不过也带来个问题,因为事务未提交,因此读请求可能无法从 boltdb 获取到最新数据
- 为解决此问题,etcd 引入一个 bucket buffer 来保存暂未提交的事务数据
- 在更新 boltdb 时,etcd 也会同步数据到 bucket buffer
Raft 实现高可用,数据一致性
多种多副本复制方法利弊分析
- 多副本常用的技术方案主要有主从复制和去中心化复制。主从复制,又分为全同步复制、 异步复制、半同步复制,比如 MySQL/Redis 单机主备版就基于主从复制实现的。
- 全同步复制是指主收到一个写请求后,必须等待全部从节点确认返回后,才能返回给客户 端成功。因此如果一个从节点故障,整个系统就会不可用。这种方案为了保证多副本的一 致性,而牺牲了可用性,一般使用不多。
- 异步复制是指主收到一个写请求后,可及时返回给 client,异步将请求转发给各个副本, 若还未将请求转发到副本前就故障了,则可能导致数据丢失,但是可用性是最高的。
- 半同步复制介于全同步复制、异步复制之间,它是指主收到一个写请求后,至少有一个副 本接收数据后,就可以返回给客户端成功,在数据一致性、可用性上实现了平衡和取舍。
- 跟主从复制相反的就是去中心化复制,它是指在一个 n 副本节点集群中,任意节点都可接 受写请求,但一个成功的写入需要 w 个节点确认,读取也必须查询至少 r 个节点。
共识算法——解决上述方法困境

- 共识算法,基于复制状态机背景提出的
- 上图是复制状态机的结构,由共识模块、日志模块、状态机组成
- 共识模块保证各个节点日志的一致性
- 然后各个节点基于同样的日志、顺序执行指令,最终各个复制状态机的结果实现一致
Raft 算法
- 共识算法的祖师爷是 Paxos,但是过于复杂,难于理解
- 因此为了可理解性、易于实现,Raft 算法诞生了,将复杂的共识问题拆分成三个子问题
- Leader 选举,Leader 故障后集群能快速选出新 Leader
- 日志复制,集群只有 Leader 能写入日志,Leader 负责复制日志到 Follower 节点,并强制 Follower 节点与自己保持相同
- 安全性,一个任期内集群只能产生一个 Leader、已提交的日志条目在发生 Leader 选举时,一定会存在更高任期的新 Leader 日志中、各个节点的状态机应用的任意位置的日志条目内容应一样等
- Raft 原理动画 (推荐看看):http://thesecretlivesofdata.com/raft/
Leader 选举
三种角色
- Follower
- 跟随者,同步从 Leader 收到的日志,etcd 启动的时候默认为此状态
- Candidate
- 竞选者,可以发起 Leader 选举
- Leader
- 集群领导者,唯一性,拥有同步日志的特权,续订是广播心跳给 Follower 节点,以维持领导者身份
选举过程 简述
- 当 Follower 节点接收 Leader 节点心跳消息超时后,会转变为 Candidate 节点,并可发起竞选投票,若获得集群多数节点的支持后,它就可转变为 Leader 节点
- Leader 都会有个任期号,通过任期号,可以比较各个节点的数据新旧、识别过期的 Leader 等,任期号在 Raft 算法中充当逻辑时钟,发挥着重要作用
- 进入 Candidate 状态的节点,会发起选举流程,自增任期号,投票给自己,冰箱其他节点发送竞选 Leader 投票消息
- 正常来说,任期号弱于对方,且没投票,当然投给对方
- 但是为了防止任期号相同,因此引入随机数,使每个节点等待发起选举的时间点不一致
日志复制

- 首先 Leader 收到 client 的请求后,etcdserver 的 KVServer 模块会向 Raft 模块提交一个(如 put hello 为 world的)提案消息,消息类型是 MsgProp
- Leader 的 Raft 模块获取到 MsgProp 提案消息后,为此提案生成一个日志条目,追加到为持久化、不稳定的 Raft 日志中
- 随后会遍历集群 Follower 列表和进度信息,为每个 Follower 生成追加(MsgApp)类型的 RPC 消息,此消息中包含待复制给 Follower 的日志条目
这里就出现两个疑问了❓
- Leader 如何知道哪个索引位置发送日志条目给 Follower,以及 Follower 已复制的日志最大索引是多少呢?
- 日志条目什么时候才会追加到稳定的 Raft 日志中呢?Raft 模块负责持久化吗?
Raft 日志

以上是 Raft 日志复制过程中的日志细节图
- 最上方是日志条目序号/索引
- 每个日志条目内容保存了 Leader 任期号和提案内容
解答疑问 1
Leader 如何知道哪个索引位置发送日志条目给 Follower,以及 Follower 已复制的日志最大索引是多少呢?
- Leader 会维护两个核心字段来追踪各个 Follower 的进度信息
- NetIndex 字段,表示 Leader 发送给 Follower 节点的下一个日志条目索引
- MatchIndex 字段,表示 Follower 节点复制的最大日志条目的索引(上图 C 节点最大日志条目索引是 5,A节点是4)
解答疑问 2
日志条目什么时候才会追加到稳定的 Raft 日志中呢?Raft 模块负责持久化吗?
- etcd Raft 模块设置及实现上抽象了网络、存储、日志等模块,本身不会进行网络、存储相关操作
- 上册应用需结合自己业务场景选择内置的模块或自定义实现网络、存储、日志等模块
- (见上图2,3流程)上层应用通过 Raft 模块的输出接口(如 Ready 结构),获取到待持久化的日志条目和待发送给 Peer 节点的消息后(如上面的 MsgApp 日志消息)
- 之后需要 持久化 日志条目到自定义的 WAL 模块(图中流程4)
- 并通过自定的网络模块将消息发送给 Peer 节点(图中流程4)
- 日志条目持久化到稳定存储中后,此时就可以将日志条目追加到稳定的 Raft 日志中(图中流程5)
- 即便 Raft 这个日志是内存存储,节点重启后也不会丢失任何日志条目
- 因为 WAL 模块已持久此日志条目,可通过它重建 Raft 日志
- etcd Raft 模块提供了一个内置的内存存储(MemoryStorge)模块实现,etcd 使用就是这个,Raft 日志条目保存在内存中
- 网络模块并未提供内置的实现,etcd 基于 HTTP 协议实现了 peer 节点间的网络通信
- 并根据消息类型,支持选择 pipeline 、stream 等模式发送,显著提高了网络吞吐量、降低了延时
日志流图梳理
-
Raft 模块输入的是 Msg 消息,输出是一个 Ready 结构
- Ready 结构包含待持久化的日志条目、发送给 peer 节点的消息、已提交的日志条目内容、线性查询结果等 Raft 输出核心信息
-
etcdserver 模块通过 channel 从 Raft 模块获取到 Ready 结构后(图中流程3)
- 因为其是 Leader 节点,所以它首先会通过基于 HTTP 协议的网络模块将追加日志条目消息(MsgApp)广播给 Follower(图中流程4)
- 同时将待持久化的日志条目持久化到 WAL 文件中(图中流程4)
- 最后将日志追加到稳定的 Raft 日志存储中(图中流程5)
-
各个 Follower 收到追加日志条目(MsgApp)消息
- 通过安全检查后,会持久化消息到 WAL 日志中,并将消息追加到 Raft 日志存储
- 随后想 Leader 回复一个应答追加日志条目(MsgAppResp)的消息,告知 Leader 当前已复制的日志最大索引(图中流程6)
-
Leader 收到应答追加日志条目(MsgAppResp)消息后,会将 Follower 回复的已复制日志最大索引更新到跟踪 Follower 进展的 Match Index 字段
-
最后 Leader 根据 Follower 的 MatchIndex 信息,计算出一个位置
- 若该位置已经被一半以上节点持久化,那么这个位置之前的日志条目都可以被标记为已提交
-
Leader 在发送心跳消息给 Follower 节点时,会告知目前已经提交的日志索引位置
-
最后各个节点的 etcdserver 模块,可通过 channel 从 Raft 模块获取到已提交的日志条目(图中流程7)
- 之后应用日志条目内容到存储状态机(图中流程8),返回结果给 client
- 存储状态机是什么? 我理解是 boltdb 部分,将用户提交的操作,进行真正的处理及存储,此部分只是写到了 WAL 日志和本地内存的 Raft 稳定日志中
安全性
选举规则
- 当节点收到选举投票的时候
- 需检查候选者的最后一条日志中的任期号
- 若小于自己则拒绝投票
- 若任期号相同,日志却比自己段,也拒绝为其投票
日志复制规则
Leader 节点若频繁发生 crash 后,可能会导致 Follower 节点与 Leader 节点日志条目冲突,如何保证各个节点的同 Raft 日志位置含有同样的日志条目?
此异常的安全性保障依靠 Raft 算法的安全机制:
- Leader 完全特性
- 只附加原则
- 日志匹配等
Leader 完全特性
- 是指若某个日志条目在某个任期号中已经被提交,那么这个条目必然出现在更大任期号的所有 Leader 中
只附加原则
- Leader 只能追加日志条目,不能删除已持久化的日志条目
日志匹配特性
- 为了保证各个节点日志一直性,Raft 算法在追加日志的时候,引入了一致性检查
- Leader 在发送追加日志 RPC 消息是,会把新的日志条目紧接着之前的条目的索引位置和任期号包含在里面
- Follower 节点会检查相同索引位置的任期号是否与 Leader 一致,一致才能追加
鉴权
整体架构
控制面

- 可以通过客户端工具 etcdctl 和鉴权 API 动态调整认证、鉴权规则,AuthServer 收到请求后,为了确保各节点加农机安全元数据一致性,会通过 Raft 模块进行数据同步
- 执行流程为
- 首先客户端设置规则,形成 Raft 日志
- 当对应的 Raft 日志条目被集群半数以上节点确认后,Apply 模块通过鉴权存储(AuthStore)模块,执行日志条目的内容
- 最后设置的规则将会存储到 boltdb 的一系列”鉴权表“里
数据面

-
数据面鉴权流程,由认证和授权流程组成
-
认证的目的是检查 client 的身份是否合法、防止匿名用户访问等
-
目前 etcd 实现了两种认证机制
- 密码认证和证书认证
-
认证通过后,为了提高密码认证性能,会分配一个 Token 给 client
- client 后续其他请求携带此 Token,server 就可快速完成 client 的身份校验工作
-
实现分配 Token 的服务也有很多中,这是 TokenProvider 所负责的,目前支持 SimpleToken 和 JWT 两种
- JWT 是无状态的。JWT Token 自带用户名、版本号、过期时间 等描述信息,etcd server 不需要保存它
-
通过认证后,在访问 MVCC 模块之前,还需要通过授权流程
- 授权的目的是检查 client 是否有权限操作你请求的数据路径
- etcd 实现了 RBAC 机制,支持为每个用户分配一个角色,为每个角色授予最小化的权限
如何安全存储密码
-
etcd 的用户密码存储正是融合了高安全性 hash 函数(Blowfish encryption algorithm)、随机的加盐 salt、可自定义的 hash 值计算迭代次数 cost。
-
etcd 创建用户流程
- 鉴权模块收到此命令后,它会使用 bcrpt 库的 blowfish 算法,基于明文密码、随机分配的 salt、自定义的 cost、迭代多次计算得到一个 hash 值,并将加密算法版本、salt 值、 cost、hash 值组成一个字符串,作为加密后的密码。
- 最后,鉴权模块将用户名作为 key,用户名、加密后的密码作为 value,存储到 boltdb 的 authUsers bucket 里面,完成一个账号创建。
- 当你使用用户账号访问 etcd 的时候,你需要先调用鉴权模块的 Authenticate 接口,它 会验证你的身份合法性。
-
etcd 验证密码流程
- 鉴权模块首先会根据你请求的用户名,从 boltdb 获取加密后的密码,因此 hash 值 包含了算法版本、salt、cost 等信息,因此可以根据你请求中的明文密码,计算出最终的 hash 值,若计算结果与存储一致,那么身份校验通过。
租约 Lease(检测客户端是否存活)
- 首先了解 Leader 选举机制的本质是什么呢?
- 是为了保证 Leader 的唯一性
- 之后若主节点故障了,备节点如何快速感应到呢?(也就是活性探测)这里有两种活性探测方案
- 被动型检测,通过探测节点定时拨测 Leader 节点,看其是否健康,比如 Redis Sentinel
- 主动上报,Leader 节点定期向协调服务发送”特殊心跳“汇报状态
- 若为正常发送心跳,且超过和协调服务约定的最大存活时间后,就会被协调服务移除 Leader 身份标识
- 同时其他节点通过协调服务,快速告知到 Leader 故障了,进而发起新的选举
今天的主题,Lease,正是基于主动型上报模式,提供的一种活性探测机制
Lease,就是 client 和 etcd server 之间存在一个约定,内容是 etcd server 保证在约定的有效期内(TTL),不会删除你关联到此 Lease 的 key-value
整体架构
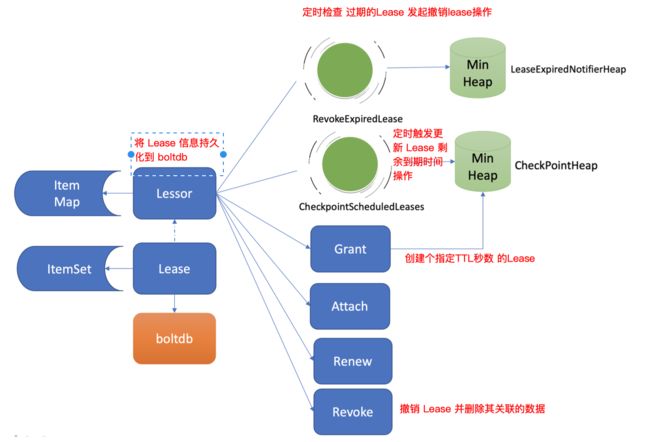
-
etcd 在启动的时候,创建 Lessor 模块时,会启动两个常驻 goroutine
- RevokeExpiredLease 任务,定期检查是否有过期 Lease,发起撤销过期的 Lease 操作
- 定期从最小堆取出已过期的 Lease,执行删除 Lease 和其关联的 key列表
- etcd Lessor 主循环每隔 500ms 执行一次撤销 Lease 检查(RevokeExpiredLease),每次轮询堆顶
- 若过期,则加入待淘汰列表,直到堆顶的 Lease 过期时间大于当前,结束本轮轮询
- Lessor 模块获取到过期的 LeaseID,保存在一个名为 expiredC 的 channel 中
- etcd server 的主循环会定期从 channel 中获取 LeaseID,发起 revoke 请求,通过 Raft Log 传递给 Follower 节点
- 各节点收到 revoke Lease 请求后,获取关联到此 Lease 上的 key 列表
- 从 boltdb 中删除 key,从 Lessor 的 Lease map 内存中删除此 Lease 对象
- 最后还需要从 boltdb 的 Lease bucket 中删除这个 Lease
- 简而言之,Lessor 定期扫描过期的,记录到 channel中,Leader 定期查看 channel,发现有过期的了,发起 revoke(删除)操作,就是通知整个集群删除该 Lease 和其关联的数据
检查 Lease 是否过期、维护最小堆、针对过期的 Lease 发起 revoke 操作,都是 Leader 节点负责的,类似于 Lease 的仲裁者
通过以上清晰的权责划分,降低了 Lease 特性的实现复杂度
因此也会面临个问题
当 Leader 因重启、crash、磁盘 IO 等异常不可用时,选出了新 Leader,那么新 Leader 要完成以上职责,必须重建 Lease 过期最小堆等管理数据结构
重建会触发什么问题呢?
etcd 早期版本为了优化,并未持久化存储 Lease 剩余 TTL 信息,因此重建时就会自动给所有 Lease 自动续期了
然而若频繁出现 Leader 切换,切换时间小于 Lease 的 TTL,这会导致 Lease 永远无法删除,大量 key 堆积,db 大小超过配额等异常
为了解决此问题,etcd 引入了检查点机制,就是下面的 CheckpointScheduledLease 任务
- CheckpointScheduledLease,定时触发更新 Lease 的剩余到期时间的操作
- etcd 启动时,Leader 节点后台会运行此异步任务
- 定期批量将 Lease 剩余的 TTL 基于 Raft Log 同步给 Follower 节点
- Follower 节点收到 Checkpoint 请求后,更新内存数据结构 LeaseMap 的剩余 TTL 信息
- 当 Leader 节点收到 KeepAlive 请求时
- 也会通过 checkpoint 机制把此 Lease 的剩余 TTL 重置,并同步给 Follower 节点,尽量确保续期后集群各个节点的 Lease 剩余 TTL 一致性
- 最后注意,此特性属于试验特性,可通过 experimental -enable-lease-checkpoint 参数开启
- etcd 启动时,Leader 节点后台会运行此异步任务
- RevokeExpiredLease 任务,定期检查是否有过期 Lease,发起撤销过期的 Lease 操作
-
Lessor 模块提供的其他接口
- Grant 表示创建一个 TTL 为指定秒数的 Lease,Lessor 会将 Lease 信息持久化存储在 boltdb 中
- Revoke 表示撤销 Lease 并删除其关联的数据
- LeaseTimeToLive 表示获取一个 Lease 的有效期、剩余时间
- LeaseKeepAlive 表示为 Lease 续期
# 创建一个TTL为600秒的lease,etcd server返回LeaseID
$ etcdctl lease grant 600
lease 326975935f48f814 granted with TTL(600s)
# 查看lease的TTL、剩余时间
$ etcdctl lease timetolive 326975935f48f814
lease 326975935f48f814 granted with TTL(600s), remaining(590s)

- 上图为将用户 key 与指定 Lease 关联(命令见上图 流程见下图)
- 通过 put 命令,指定参数 --lease
- 内部原理,MVCC 模块会通过 Lessor 的 Attach 方法,将 key 关联到 Lease 在 key 内存集合 ItemSet 中
- 问题:Lease 的 key 集合是在内存中,那么 etcd 重启时,如何知道每个 Lease 上关联了哪些 key 呢?
- 答:etcd 的 MVCC 模块在持久化存储 key-value 的时候,保存到 boltdb 的 value 是个结构体(mvccpb.KeyValue)
- 该结构体不仅 包含了用户的 key-value 数据,还包含了 关联的 LeaseID 等信息
回顾一下写入过程,client 发送 put请求时,首先到达 KVServer 模块,之后到达 Raft 模块,将日志条目写入到 Wal 模块(持久化),之后将日志条目写入到 Raft 稳定日志(内存中),此时标记为已提交状态,之后到达 Apply 模块,此模块利用 consistent index 字段记录已执行的日志,之后达到 MVCC 模块,实现真正的存储,MVCC 模块包含两部分 treeIndex 和 boltdb,treeIndex 是在内存中,维护 版本号 和用户key的映射关系,真正的数据是存储在 boltdb 中,boltdb 中,key 为版本号,value 是个结构体(包含用户的 key-value信息、关联的 LeaseID 等),boltdb 也是存在内存中,因此需要将数据磁盘化进行持久化,但不可能一条数据一次提交,开销太昂贵,所以采用批量提交方式,因此提交一条数据的话,虽然标记已提交了,但是并未在存储状态机中,因此直接访问状态机,不会获得最新数据,为了解决此问题,etcd 引入 buffer 机制,一个作用是为了缓存,另一个也是为了存储还未存到状态机的新数据(从而可以对外服务),那么这一部分数据在哪呢?其实在 boltdb 的 buffer bucket 桶中。

MVCC
- 核心思想:保存一个 key-value 数据的多个历史版本
- etcd 基于它实现了可靠的 Watch 机制,避免 client 频繁发起 List Pod 等昂贵操作,保障etcd 集群稳定性
- 同时 MVCC 还能以较低的并发控制开销,实现各类隔离级别的事务,保障事务的安全性,是事务特性的基础
- MVCC 机制是基于多版本技术实现的一种乐观锁机制
- 乐观地认为数据不会发生冲突,但当事务提交时,具备检测数据是否冲突的能力
- 在 MVCC 数据库中,更新一个 key-value 数据时,并不会直接覆盖原数据,而是新增一个版本来存储新数据,每个数据都有一个版本号
- 当指定版本读取数据时,实际上访问的是版本号生成那个时间点的快照数据
- 当删除数据时,实际上也是新增一条代删除标识的数据记录
整体架构
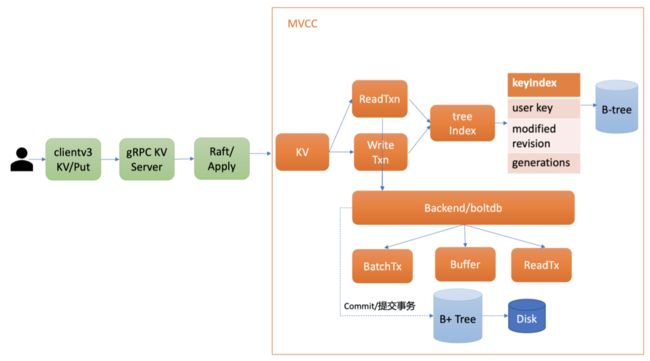
- Apply 模块通过 MVCC 模块来执行 put 请求,持久化 key-value 数据
- MVCC 模块将请求划分为两类别
- 读事务(ReadTxn),负责处理 range 请求
- 写事务(WriteTxn),负责 put/delete 操作
- 读写事务基于 treeIndex、Backend/boltdb 提供的能力,实现对 key-value 的增删改查功能
- treeIndex 基于内存版的 B-tree 实现了 key 索引管理,保存了用户 key 和版本号(revision)的映射关系等信息
- Backend 模块负责 etcd 的 key-value 持久化存储,主要由 ReadTx、BatchTx、Buffer 组成
- ReadTx 定义了抽象的读事务接口
- BatchTx 在 ReadTx 之上定义了抽象的写事务接口
- Buffer 是数据缓存区
- etcd 支持多种 Backend 实现,目前采用 boltdb,其是基于 B+tree 实现的、支持事务的 key-value 嵌入式数据库
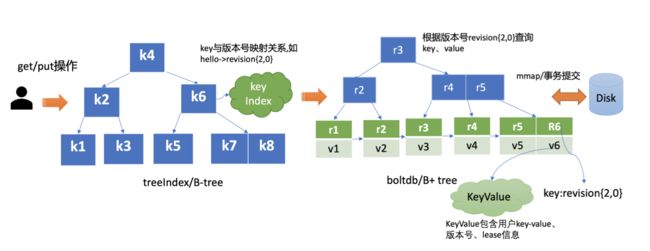
treeIndex 原理
- 实现 key 的历史版本保存
- 为什么选用 B-tree,而不是哈希表、平衡二叉树等?
- 因为 B-tree 支持范围查询,同时每个节点可容纳多个数据,树的高度更低,更扁平,查找次数更少,性能优越

- 在 treeIndex 中,每个节点的 key 是一个 keyIndex 结构,etcd 就是通过此保存 用户key 与 版本号 的映射关系
-
 - 用户的 key - 最后一次修改 key 时的版本号 - key 的若干代(generation)版本号信息
- 用户的 key - 最后一次修改 key 时的版本号 - key 的若干代(generation)版本号信息 -
 - ver key 的修改次数 - created 是 generation 创建时的版本号 - revs 是对此 key 的修改版本号记录列表**(注意 revison 是个结构体)**
- ver key 的修改次数 - created 是 generation 创建时的版本号 - revs 是对此 key 的修改版本号记录列表**(注意 revison 是个结构体)** 

- main 是全局递增的版本号,是 etcd 逻辑时钟,随着 put/txn/delete 等事务递增
- sub 是一个事务内的子版本号,从 0 开始随事务内的 put/delete 操作递增
- 比如启动一个空集群,全局版本号默认为 1,执行下面的 txn 事务,它包含两次 put、一 次 get 操作,那么按照我们上面介绍的原理,全局版本号随读写事务自增,因此是 main 为 2,sub 随事务内的 put/delete 操作递增,因此 key hello 的 revison 为{2,0},key world 的 revision 为{2,1}。
-
MVCC 更新 key 原理
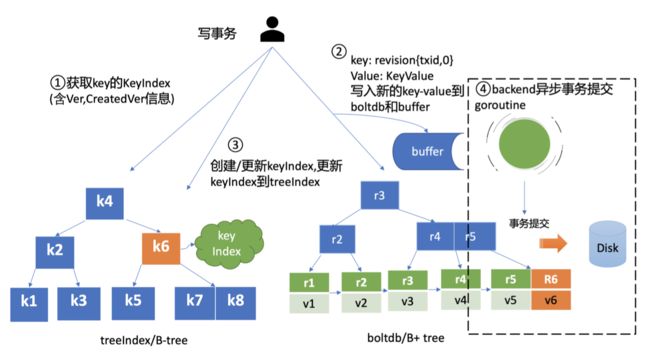
先获取,然后填充结构体,写入到 boltdb 缓存,写入到 buffer,再写入到 treeIndex,最后通过异步 goroutine 进行批量提交
- 因为是第一次创建 hello key,此时 keyIndex 索引为空
- 其次 etcd 会根据当前的全局版本号(空集群启动时默认为 1)自增,生成 put hello 操作 对应的版本号 revision{2,0},这就是 boltdb 的 key
- boltdb 的 value 是 mvccpb.KeyValue 结构体,它是由用户 key、value、 create_revision、mod_revision、version、lease 组成。它们的含义分别如下:
- create_revision 表示此 key 创建时的版本号。在我们的案例中,key hello 是第一次创 建,那么值就是 2。当你再次修改 key hello 的时候,写事务会从 treeIndex 模块查询 hello 第一次创建的版本号,也就是 keyIndex.generations[i].created 字段,赋值给 create_revision 字段
- mod_revision 表示 key 最后一次修改时的版本号,即 put 操作发生时的全局版本号加 1
- version 表示此 key 的修改次数。每次修改的时候,写事务会从 treeIndex 模块查询 hello 已经历过的修改次数,也就是 keyIndex.generations[i].ver 字段,将 ver 字段值 加 1 后,赋值给 version 字段。
- boltdb 的 value 是 mvccpb.KeyValue 结构体,它是由用户 key、value、 create_revision、mod_revision、version、lease 组成。它们的含义分别如下:
- 填充好 boltdb 的 KeyValue 结构体后,这时就可以通过 Backend 的写事务 batchTx 接口 将 key{2,0},value 为 mvccpb.KeyValue 保存到 boltdb 的缓存中,并同步更新 buffer, 如上图中的流程 2 所示。(缓存到 boltdb,保存到 buffer)
- 此时存储到 boltdb 中的 key、value 数据如下:
-
- 然后 put 事务需将本次修改的版本号与用户 key 的映射关系保存到 treeIndex 模块中,也 就是上图中的流程 3(保存到 treeIndex)
- 因为 key hello 是首次创建,treeIndex 模块它会生成 key hello 对应的 keyIndex 对象, 并填充相关数据结构
- 但是此时数据还并未持久化,为了提升 etcd 的写吞吐量、性能,一般情况下(默认堆积的 写事务数大于 1 万才在写事务结束时同步持久化),数据持久化由 Backend 的异步 goroutine 完成,它通过事务批量提交
- 定时将 boltdb 页缓存中的脏数据提交到持久化存 储磁盘中,也就是下图中的黑色虚线框住的流程 4

MVCC 查询 key 原理

- 并发读特性的核心原理是创建读事务对象时,它会全量拷贝当前写事务未提交的 buffer 数 据,并发的读写事务不再阻塞在一个 buffer 资源锁上,实现了全并发读
- 未带版本号读,默认是读取最新的数据
MVCC 删除 key 原理
-
etcd 实现的是延期删除模式,原理与 key 更新类似
-
与更新 key 不一样之处在于
- 生成的 boltdb key 版本号{4,0,t}追加了删除标识 (tombstone, 简写 t)
- boltdb value 变成只含用户 key 的 KeyValue 结构体
- treeIndex 模块也会给此 key hello 对应的 keyIndex 对象,追加一个空的 generation 对象,表示此索引对应的 key 被删除了
-
boltdb 此时会插入一个新的 key revision{4,0,t},此时存储到 boltdb 中的 key-value 数 据如下
-
-
key 打上删除标记后有哪些用途呢
- 一方面删除 key 时会生成 events,Watch 模块根据 key 的删除标识,会生成对应的 Delete 事件
- 另一方面,当你重启 etcd,遍历 boltdb 中的 key 构建 treeIndex 内存树时,你需要知道 哪些 key 是已经被删除的,并为对应的 key 索引生成 tombstone 标识
- 真正删除 treeIndex 中的索引对象、boltdb 中的 key 是通过压缩 (compactor) 组件异步完成
- 正因为 etcd 的删除 key 操作是基于以上延期删除原理实现的,因此只要压缩组件未回收 历史版本,我们就能从 etcd 中找回误删的数据

Watch
带着问题去思考(4大核心问题)
- client 获取事件的机制,etcd 是使用轮询模式还是推送模式呢?两者各有什么优缺 点?
- 事件是如何存储的? 会保留多久?watch 命令中的版本号具有什么作用?
- 当 client 和 server 端出现短暂网络波动等异常因素后,导致事件堆积时,server 端会丢弃事件吗?若你监听的历史版本号 server 端不存在了,你的代码该如何处理?
- 如果你创建了上万个 watcher 监听 key 变化,当 server 端收到一个写请求后, etcd 是如何根据变化的 key 快速找到监听它的 watcher 呢?
轮询 vs 流式传输
问题1: client 获取事件的机制,etcd 是使用轮询模式还是推送模式呢?两者各有什么优缺点?
两种机制 etcd 都使用过
etcd v2 Watch 机制实现中,client 通过 HTTP/1.1 协议长连接定时轮询 server,获取最新的数据变化事件,然而当你的 watcher 成千上万的时,即使集群空负载,大量轮询也会产生一定的 QPS, server 端会消耗大量的 socket、内存等资源,导致 etcd 的扩展性、稳定性无法满足 Kubernetes 等业务场景诉求
etcd v3 中,为了解决 etcd v2 的以上缺陷,使用的是基于 HTTP/2 的 gRPC 协议,双向流的 Watch API 设计,实现了连接多路复用
在 HTTP/2 协议中,HTTP 消息被分解独立的帧(Frame),交错发送,帧是最小的数据 单位。每个帧会标识属于哪个流(Stream),流由多个数据帧组成,每个流拥有一个唯一 的 ID,一个数据流对应一个请求或响应包

- 如图所示,client 正在向 server 发送数据流 5 的帧,同时 server 也正在向 client 发送 数据流 1 和数据流 3 的一系列帧。一个连接上有并行的三个数据流,HTTP/2 可基于帧的 流 ID 将并行、交错发送的帧重新组装成完整的消息。
- etcd 基于以上介绍的 HTTP/2 协议的多路复用等机制,实现了一个 client/TCP 连接支持多 gRPC Stream, 一个 gRPC Stream 又支持多个 watcher,如下如所示
- 同时事件通知模式也从 client 轮询优化成 server 流式推送,极大降低了 server 端 socket、内存等资源
- 在 clientv3 库中,Watch 特性被抽象成 Watch、Close、RequestProgress 三个简单 API 提供给开发者使用,屏蔽了 client 与 gRPC WatchServer 交互的复杂细节,实现了一 个 client 支持多个 gRPC Stream,一个 gRPC Stream 支持多个 watcher,显著降低了开发复杂度。
- 同时当 watch 连接的节点故障,clientv3 库支持自动重连到健康节点,并使用之前已接收的最大版本号创建新的 watcher,避免旧事件回放

滑动窗口 vs MVCC
问题 2:事件是如何存储的? 会保留多久?watch 命令中的版本号具有什么作用?
该问题本质是:历史版本存储
etcd 经历了从滑动窗口到 MVCC 机制的演变,滑动窗口是仅保存有限的最近历史版本到内存中,而 MVCC 机制则将历史版本保存在磁盘中, 避免了历史版本的丢失,极大的提升了 Watch 机制的可靠性
- etcd v2 采用简单的环形数组来存储历史事件版本,当 key 被修改后,相关事件就 会被添加到数组中来。若超过 eventQueue 的容量,则淘汰最旧的事件
- 缺陷显而易见的,固定的事件窗口只能保存有限的历史事件版本,是不可靠的
- 当写请求较多的时候、client 与 server 网络出现波动等异常时,很容易导致事件丢失, client 不得不触发大量的 expensive 查询操作,以获取最新的数据及版本号,才能持续监听数据
- 特别是对于重度依赖 Watch 机制的 Kubernetes 来说,显然是无法接受的。因为这会导致控制器等组件频繁的发起 expensive List Pod 等资源操作,导致 APIServer/etcd 出现高负载、OOM 等,对稳定性造成极大的伤害
- etcd v3 的 MVCC 机制,就是为解决 etcd v2 Watch 机制不可靠而诞生,etcd v3 则是将一个 key 的历史修改版本保存在 boltdb 里面
- boltdb 是一个基于磁盘文件的持久化存储,因此它重启后历史事件不像 etcd v2 一样会丢失
- 同时你可通过配置压缩策略,来控制保存的历史版本数
最后 watch 命令中的版本号具有什么作用呢?
- 版本号是 etcd 逻辑时钟,当 client 因网络等异常出现连接闪断后,通过版本号,它就可从 server 端的 boltdb 中获取错过的历史事件, 而无需全量同步,它是 etcd Watch 机制数据增量同步的核心。
可靠的时间推送机制
问题 3:当 client 和 server 端出现短暂网络波动等异常因素后,导致事件堆积时,server 端会丢弃事件吗?若你监听的历史版本号 server 端不存在了,你的代码该如何处理?
此问题的本质是可靠事件推送机制,要搞懂它,我们就得弄懂 etcd Watch 特性的整体架构、核心流程
整体架构

简要介绍一下 watch 的整体流程
- 当你通过 etcdctl 或 API 发起一个 watch key 请求的时候,etcd 的 gRPCWatchServer 收到 watch 请求后,会创建一个 serverWatchStream
- serverWatchStream 负责接收 client 的 gRPC Stream 的 create/cancel watcher 请求 (recvLoop goroutine),并将从 MVCC 模块接收 的 Watch 事件转发给 client(sendLoop goroutine)
- 当 serverWatchStream 收到 create watcher 请求后,serverWatchStream 会调用 MVCC 模块的 WatchStream 子模块分配一个 watcher id,并将 watcher 注册到 MVCC 的 WatchableKV 模块
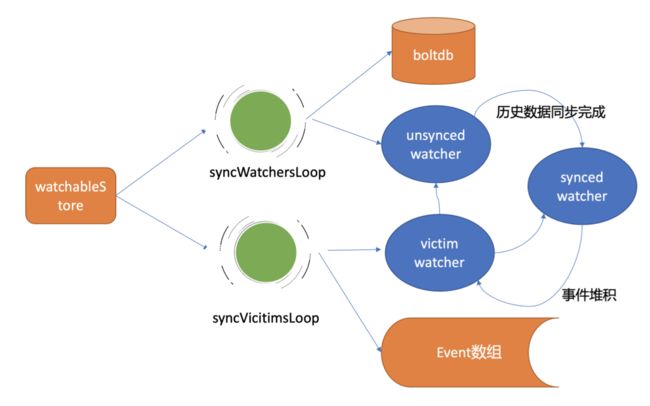
- 在 etcd 启动的时候,WatchableKV 模块会运行 syncWatchersLoop 和 syncVictimsLoop goroutine
- 分别负责不同场景下的事件推送,它们也是 Watch 特性可靠性的核心之一
- 从架构图中你可以看到 Watch 特性的核心实现是 WatchableKV 模块
核心解决方案(复杂度管理、问题拆分)
- etcd 根据不同场景,对问题进行了分解,将 watcher 按场景分类,实现了轻重分离、低耦合
synced watcher
- 表示此类 watcher 监听的数据都已经同步完毕,在等待新的变更
- 如果你创建的 watcher 未指定版本号 (默认 0)、或指定的版本号大于 etcd sever 当前最新的版本号 (currentRev),那么它就会保存到 synced watcherGroup 中
- watcherGroup 负责管理多个 watcher,能够根据 key 快速找到监听该 key 的一个或多个 watcher
unsynced watcher
- 表示此类 watcher 监听的数据还未同步完成,落后于当前最新数据变更,正在努力追赶
- 如果你创建的 watcher 指定版本号小于 etcd server 当前最新版本号,那么它就会保存到 unsynced watcherGroup 中
- 比如我们的这个案例中 watch 带指定版本号 1 监听时,版本号 1 和 etcd server 当前版本之间的数据并未同步给你,因此它就属于此类
最新事件推送机制

当 etcd 收到一个写请求,key-value 发生变化的时候,处于 syncedGroup 中的 watcher,是如何获取到最新变化事件并推送给 client 的呢?
当你创建完成 watcher 后,此时你执行 put hello 修改操作时,如上图所示,请求经过 KVServer、Raft 模块后 Apply 到状态机时,在 MVCC 的 put 事务中,它会将本次修改的后的 mvccpb.KeyValue 保存到一个 changes 数组中。
在 put 事务结束时,它会将 KeyValue 转换成 Event 事件,然后 回调 watchableStore.notify 函数(流程 5)。
- notify 会匹配出监听过此 key 并处于 synced watcherGroup 中的 watcher,同时事件中的版本号要大于等于 watcher 监听的 最小版本号,才能将事件发送到此 watcher 的事件 channel 中。
serverWatchStream 的 sendLoop goroutine 监听到 channel 消息后,读出消息立即推 送给 client(流程 6 和 7),至此,完成一个最新修改事件推送。
异常场景重试机制
新增了一个watcherBatch 结构名为 victim ,保障 Watch 时间的高可用性
当堆积的事件推送到 watcher 接收 channel 失败后,会加入到 victim watcherBatch 数据结构中,等待下次重试
-
若出现 channel buffer 满了,etcd 为了保证 Watch 事件的高可靠性,并不会丢弃它
- 而 是将此 watcher 从 synced watcherGroup 中删除
- 然后将此 watcher 和事件列表保存到 一个名为受害者 victim 的 watcherBatch 结构中,通过异步机制重试保证事件的可靠性
-
还有一个点你需要注意的是,notify 操作它是在修改事务结束时同步调用的,必须是轻量级、高性能、无阻塞的,否则会严重影响集群写性能
-
我们知道 WatchableKV 模块会启动两个异步 goroutine
- 其中一个是 syncVictimsLoop,正是它负责 slower watcher 的堆积的事件推送
- 基本工作原理是,遍历 victim watcherBatch 数据结构,尝试将堆积的事件再次推送到 watcher 的接收 channel 中。
- 若推送失败,则再次加入到 victim watcherBatch 数据 结构中等待下次重试。
- 若推送成功,watcher 监听的最小版本号 (minRev) 小于等于 server 当前版本号 (currentRev),说明可能还有历史事件未推送,需加入到 unsynced watcherGroup 中
- 若 watcher 的最小版本号大于 server 当前版本号,则加入到 synced watcher 集合中
- 其中一个是 syncVictimsLoop,正是它负责 slower watcher 的堆积的事件推送
-
下面一幅图总结各类 watcher 状态转换关系
历史事件推送机制
-
WatchableKV 模块的另一个 goroutine,syncWatchersLoop,正是负责 unsynced watcherGroup 中的 watcher 历史事件推送
-
在历史事件推送机制中,如果你监听老的版本号已经被 etcd 压缩了,client 该如何处理?
- 要了解这个问题,我们就得搞清楚 syncWatchersLoop 如何工作
- 核心支撑是 boltdb 中存储了 key-value 的历史版本。
- syncWatchersLoop,它会遍历处于 unsynced watcherGroup 中的每个 watcher
- 为了 优化性能,它会选择一批 unsynced watcher 批量同步,找出这一批 unsynced watcher 中监听的最小版本号。
- 通过指定查询的 key 范围的最小版本号作为 开始区间,当前 server 最大版本号作为结束区间,遍历 boltdb 获得所有历史数据
- 然后将 KeyValue 结构转换成事件,匹配出监听过事件中 key 的 watcher 后,将事件发送 给对应的 watcher 事件接收 channel 即可
- 发送完成后,watcher 从 unsynced watcherGroup 中移除、添加到 synced watcherGroup 中,如下面的 watcher 状态转换 图黑色虚线框所示。
- 要了解这个问题,我们就得搞清楚 syncWatchersLoop 如何工作
-
若 watcher 监听的版本号已经小于当前 etcd server 压缩的版本号,历史变更数据就可能已丢失,因此 etcd server 会返回 ErrCompacted 错误给 client
- client 收到此错误后,需重新获取数据最新版本号后,再次 Watch。
- 你在业务开发过程中,使用 Watch API 最 常见的一个错误之一就是未处理此错误。

高效的事件匹配
问题 4:如果你创建了上万个 watcher 监听 key 变化,当 server 端收到一个写请求后, etcd 是如何根据变化的 key 快速找到监听它的 watcher 呢?
答:
etcd 的确使用 map 记录了监听单个 key 的 watcher,
但是你要注意的是 Watch 特性不仅仅可以监听单 key,它还可以指定监听 key 范围、key 前缀,因此 etcd 还使用了如下的区间树。
- 当收到创建 watcher 请求的时候,它会把 watcher 监听的 key 范围插入到上面的区间树 中,区间的值保存了监听同样 key 范围的 watcher 集合 /watcherSet。
- 当产生一个事件时,etcd 首先需要从 map 查找是否有 watcher 监听了单 key,其次它还 需要从区间树找出与此 key 相交的所有区间,然后从区间的值获取监听的 watcher 集合。
- 区间树支持快速查找一个 key 是否在某个区间内,时间复杂度 O(LogN),因此 etcd 基于 map 和区间树实现了 watcher 与事件快速匹配,具备良好的扩展性。

事务(安全实现多 key 操作)
-
事务,它就是为了简化应用层的编程模型而诞生的
-
etcd v3 为了解决多 key 的原子操作问题,提供了全新迷你事务 API,同时基于 MVCC 版 本号,它可以实现各种隔离级别的事务。它的基本结构如下
-

-
可以看到,事务 API 由 If 语句、Then 语句、Else 语句组成,这与我们平 时常见的 MySQL 事务完全不一样
-
If 语句支持哪些检查项呢?
- key 的最近一次修改版本号 mod_revision,简称 mod。你可以通过它检查 key 最近一次被修改时的版本号是否符合你的预期
- key 的创建版本号 create_revision,简称 create。你可以通过它检查 key 是否已存在
- key 的修改次数 version。你可以通过它检查 key 的修改次数是否符合预期
- key 的 value 值。你可以通过检查 key 的 value 值是否符合预期
-
整体流程

- 上图是 etcd 事务的执行流程,当你通过 client 发起一个 txn 转账事务操作时
- 通过 gRPC KV Server、Raft 模块处理后,
- 在 Apply 模块执行此事务的时候,
- 它首先对你的事务的 If 语句进行检查,也就是 ApplyCompares 操作,
- 如果通过此操作,则执行 ApplyTxn/Then 语句,
- 否则执行 ApplyTxn/Else 语句。
- 在执行以上操作过程中,它会根据事务是否只读、可写,通过 MVCC 层的读写事务对象, 执行事务中的 get/put/delete 各操作,也就是我们上一节课介绍的 MVCC 对 key 的读写 原理。
事务 ACID 特性
- ACID 是衡量事务的四个特性,由原子性(Atomicity)、一致性(Consistency)、隔离 性(Isolation)、持久性(Durability)组成
- 原子性(Atomicity)是指在一个事务中,所有请求要么同时成功,要么同时失败
- 持久性(Durability)是指事务一旦提交,其所做的修改会永久保存在数据库
- 一致性(Consistency)的表述,其实在不同场景下,它的含义是 不一样的
- CAP 原理中的一致性是指可线性化。核心原理是虽然整个系统是由多副本组成,但 是通过线性化能力支持,对 client 而言就如一个副本,应用程序无需关心系统有多少个副本
- 一致性哈希,它是一种分布式系统中的数据分片算法,具备良好的分散性、平衡性
- 事务中的一致性,它是指事务变更前后,数据库必须满足若干恒等条件的状态约束,一致性往往是由数据库和业务程序两方面来保障的。
- 隔离性,它是指事务在执行过程中的可见性。 常见的事务隔离级别有以下四种
- 未提交读(Read UnCommitted),也就是一个 client 能读取到未提交的事务。比 如转账事务过程中,Alice 账号资金扣除后,Bob 账号上资金还未增加,这时如果其他 client 读取到这种中间状态,它会发现系统总金额钱减少了,破坏了事务一致性的约束
- 已提交读(Read Committed),指的是只能读取到已经提交的事务数据,但是存 在不可重复读的问题。比如事务开始时,你读取了 Alice 和 Bob 资金,这时其他事务修改 Alice 和 Bob 账号上的资金,你在事务中再次读取时会读取到最新资金,导致两次读取结 果不一样
- 可重复读(Repeated Read),它是指在一个事务中,同一个读操作 get Alice/Bob 在事务的任意时刻都能得到同样的结果,其他修改事务提交后也不会影响你本 事务所看到的结果
- 串行化(Serializable),它是最高的事务隔离级别,读写相互阻塞,通过牺牲并发 能力、串行化来解决事务并发更新过程中的隔离问题。对于串行化我要和你特别补充一 点,很多人认为它都是通过读写锁,来实现事务一个个串行提交的,其实这只是在基于锁 的并发控制数据库系统实现而已。
- 为了优化性能,在基于 MVCC 机制实现的各个数据库系 统中,提供了一个名为“可串行化的快照隔离”级别,相比悲观锁而言,它是一种乐观并 发控制,通过快照技术实现的类似串行化的效果,事务提交时能检查是否冲突。
boltdb 持久化存储你的 key-value 数据
boltdb 磁盘布局

- boltdb 文件指的是你 etcd 数据目录下的 member/snap/db 的文件, etcd 的 keyvalue、lease、meta、member、cluster、auth 等所有数据存储在其中。
- etcd 启动的时候,会通过 mmap 机制将 db 文件映射到内存,后续可从内存中快速读取文件中的数据
- 写请求通过 fwrite 和 fdatasync 来写入、持久化数据到磁盘
- 文件的内容由若干个 page 组成,一般情况下 page size 为 4KB
- page 按照功能可分为元数据页 (meta page)、B+ tree 索引节点页 (branch page)、B+ tree 叶子节点页 (leaf page)、空闲页管理页 (freelist page)、空闲页 (free page)
- 文件最开头的两个 page 是固定的 db 元数据 meta page
- 空闲页管理页记录了 db 中哪 些页是空闲、可使用的
- 索引节点页保存了 B+ tree 的内部节点,如图中的右边部分所示,它们记录了 key 值
- 叶子节点页记录了 B+ tree 中的 key-value 和 bucket 数据
- boltdb 逻辑上通过 B+ tree 来管理 branch/leaf page, 实现快速查找、写入 key-value 数据
boltdb API
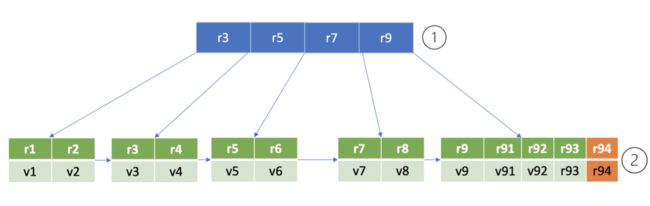
- boltdb 提供了非常简单的 API 给上层业务使用,当我们执行一个 put hello 为 world 命令时
- boltdb 实际写入的 key 是版本号,value 为 mvccpb.KeyValue 结构体
- 这里我们简化下,假设往 key bucket 写入一个 key 为 r94,value 为 world 的字符串, 其核心代码如下:
- 通过 boltdb 的 Open API,我们获取到 boltdb 的核心对象 db 实例后
- 然后通过 db 的 Begin API 开启写事务,获得写事务对象 tx
- 通过写事务对象 tx, 你可以创建 bucket
- 这里我们创建了一个名为 key 的 bucket(如果不存在),并使用 bucket API 往其中更新了一个 key 为 r94,value 为 world 的数据
- 最后我们使用写事务的 Commit 接口提交整个事务,完成 bucket 创建和 key-value 数据 写入

核心数据结构介绍
- boltdb 整个文件由一个个 page 组成。最开头 的两个 page 描述 db 元数据信息,而它正是在 client 调用 boltdb Open API 时被填充 的
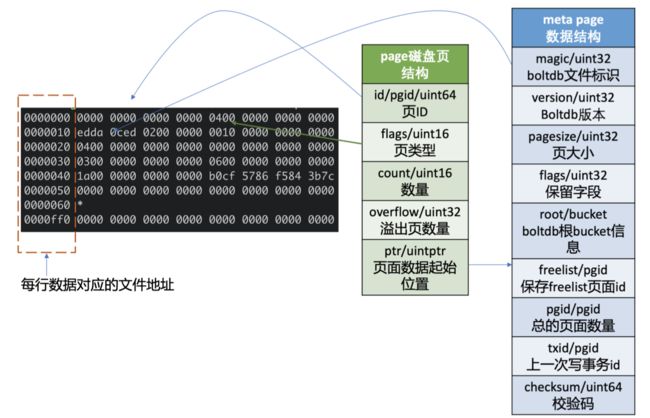
page 磁盘页结构
- 由页 ID(id)、页类型 (flags)、数量 (count)、溢出页数量 (overflow)、页面数据起始位置 (ptr) 字段组成
- 页类型目前有如下四种:0x01 表示 branch page,0x02 表示 leaf page,0x04 表示 meta page,0x10 表示 freelist page
- 数量字段仅在页类型为 leaf 和 branch 时生效
- 溢出页数量是指当前页面数据存放不下, 需要向后再申请 overflow 个连续页面使用
- 页面数据起始位置指向 page 的载体数据,比如 meta page、branch/leaf 等 page 的内容
meta page 数据结构
- 第 0、1 页我们知道它是固定存储 db 元数据的页 (meta page)
- 它由 boltdb 的文件标识 (magic)、版 本号 (version)、页大小 (pagesize)、boltdb 的根 bucket 信息 (root bucket)、freelist 页面 ID(freelist)、总的页面数量 (pgid)、上一次写事务 ID(txid)、校验码 (checksum) 组 成。
meta page 十六进制分析

-
了解完 db 元数据页面原理后,那么 boltdb 是如何根据元数据页面信息快速找到你的 bucket 和 key-value 数据呢?
-
这就涉及到了元数据页面中的 root bucket,它是个至关重要的数据结构。下面我们看看 它是如何管理一系列 bucket、帮助我们查找、写入 key-value 数据到 boltdb 中。
-
bucket 数据结构

- 之前介绍过的 auth/lease/meta 等熟悉的 bucket,它们都 是 etcd 默认创建的。那么 boltdb 是如何存储、管理 bucket 的呢?
- meta page 中的,有一个名为 root、类型 bucket 的重要数据结构
- bucket 由 root 和 sequence 两个字段组成,root 表示该 bucket 根节点的 page id
-

- meta page 中的 bucket.root 字段,存储的是 db 的 root bucket 页面信息
- 你所看到的 key/lease/auth 等 bucket 都是 root bucket 的子 bucket
-

- 当 bucket 比较少时,我们子 bucket 数据可直接从 meta page 里 指向的 leaf page 中找到
leaf page
- meta page 的 root bucket 直接指向的是 page id 为 4 的 leaf page, page flag 为 0x02
- leaf page 它的磁盘布局如下图所示,前半部分是 leafPageElement 数组,后半 部分是 key-value 数组
- leafPageElement 包含 leaf page 的类型 flags, 通过它可以区分存储的是 bucket 名称 还是 key-value 数据
- 当 flag 为 bucketLeafFlag(0x01) 时,表示存储的是 bucket 数据
- 否则存储的是 keyvalue 数据
- 当存储的是 bucket 数据的时候,key 是 bucket 名称,value 则是 bucket 结构信息
- bucket 结构信息含有 root page 信息,通过 root page(基于 B+ tree 查找算法),可以快速找到你存储在这个 bucket 下面的 key-value 数据所在页面
-

- leaf page 它的磁盘布局如下图所示,前半部分是 leafPageElement 数组,后半 部分是 key-value 数组
branch page
-
branch page 保存 B+ tree 的非叶子节点 key 数据
-
boltdb 使用了 B+ tree 来高效管理所有子 bucket 和 key-value 数据,因此它可以支持大 量的 bucket 和 key-value
-
只不过 B+ tree 的根节点不再直接指向 leaf page,而是 branch page 索引节点页。branch page flags 为 0x01
-
磁盘布局如下图所示,前半 部分是 branchPageElement 数组,后半部分是 key 数组。
- branchPageElement 包含 key 的读取偏移量、key 大小、子节点的 page id
- 根据偏移量和 key 大小,我们就可以方便地从 branch page 中解析出所有 key,然后二分搜索匹配 key,获取其子节点 page id,递归搜索,直至从 bucketLeafFlag 类型的 leaf page 中找 到目的 bucket name
- 注意,boltdb 在内存中使用了一个名为 node 的数据结构,来保存 page 反序列化的结 果
-

从上面分析过程中你会发现,boltdb 存储 bucket 和 key-value 原理是类似的,将 page 划分成 branch page、leaf page,通过 B+ tree 来管理实现
boltdb 为了区分 leaf page 存储的数据类型是 bucket 还是 key-value,增加了标识字段 (leafPageElement.flags)
因此 key-value 的数据存储过程我就不再重复分析了
freelist
- 再看 meta page 中的另外一个核心字段 freelist
- 我们知道 boltdb 将 db 划分成若干个 page,那么它是如何知道哪些 page 在使用中,哪 些 page 未使用呢
- 答案是 boltdb 通过 meta page 中的 freelist 来管理页面的分配,freelist page 中记录了 哪些页是空闲的
- 当你在 boltdb 中删除大量数据的时候,其对应的 page 就会被释放,页 ID 存储到 freelist 所指向的空闲页中
- 当你写入数据的时候,就可直接从空闲页中申请页面使用
- 下图是 freelist page 存储结构,pageflags 为 0x10,表示 freelist 类型的页,ptr 指向空闲页 id 数组
- 注意在 boltdb 中支持通过多种数据结构(数组和 hashmap)来管理 free page,这里我介绍的是数组

Open 原理
- 首先它会打开 db 文件并对其增加文件锁,目的是防止其他进程也以读写模式打开它后, 操作 meta 和 free page,导致 db 文件损坏
- 其次 boltdb 通过 mmap 机制将 db 文件映射到内存中,并读取两个 meta page 到 db 对象实例中
- 然后校验 meta page 的 magic、version、checksum 是否有效,若两个 meta page 都无效,那么 db 文件就出现了严重损坏,导致异常退出
Put 原理
- 通过 bucket API 创建一个 bucket、发起一个 Put 请求更 新数据时,boltdb 是如何工作的呢
- 首先是根据 meta page 中记录 root bucket 的 root page,按照 B+ tree 的查找算法,从 root page 递归搜索到对应的叶子节点 page 面,返回 key 名称、leaf 类型
- 如果 leaf 类型为 bucketLeafFlag,且 key 相等,那么说明已经创建过,不允许 bucket 重复创建,结束请求。
- 否则往 B+ tree 中添加一个 flag 为 bucketLeafFlag 的 key,key 名称为 bucket name,value 为 bucket 的结构
- 创建完 bucket 后,你就可以通过 bucket 的 Put API 发起一个 Put 请求更新数据
- 它的 核心原理跟 bucket 类似,根据子 bucket 的 root page,从 root page 递归搜索此 key 到 leaf page
- 如果没有找到,则在返回的位置处插入新 key 和 value
事务提交原理

-
首先从上面 put 案例中我们可以看到,插入了一个新的元素在 B+ tree 的叶子节点,它可 能已不满足 B+ tree 的特性,因此事务提交时,第一步首先要调整 B+ tree,进行重平 衡、分裂操作,使其满足 B+ tree 树的特性
-
在重平衡、分裂过程中可能会申请、释放 free page,freelist 所管理的 free page 也发生 了变化。因此事务提交的第二步,就是持久化 freelist
-
事务提交的第三步就是将 client 更新操作产生的 dirty page 通过 fdatasync 系统调用,持 久化存储到磁盘中
-
最后,在执行写事务过程中,meta page 的 txid、freelist 等字段会发生变化,因此事务的最后一步就是持久化 meta page
-
通过以上四大步骤,我们就完成了事务提交的工作,成功将数据持久化到了磁盘文件中, 安全地完成了一个 put 操作
-
真正持久化数据到磁盘是通过事务提交执行的
压缩 回收旧版本数据
- etcd 是通过什么机制来回收历史版本数据,控制索引内存占用和 db 大小的呢?
- 目前 etcd 支持两种压 缩模式,分别是时间周期性压缩和版本号压缩
- 周期性压缩,希望 etcd 只保留最近一段时间写入的历史版本时,你就可以选择配置 etcd 的压缩模 式为 periodic,保留时间为你自定义的 1h 等
- 版本号压缩,当你写请求比较多,可能产生比较多的历史版本导致 db 增长时,或者不确定配置 periodic 周期为多少才是最佳的时候,
- 可以通过设置压缩模式为 revision,指定保留的 历史版本号数。比如你希望 etcd 尽量只保存 1 万个历史版本,那么你可以指定 compaction-mode 为 revision,auto-compaction-retention 为 10000
- 压缩的本质是回收历史版本,目标对象仅是历史版本,不包括一个 key-value 数据的最新版本,因此你可以放心执行压缩命令,不会删除你的最新版本数据
- 目前 etcd 支持两种压 缩模式,分别是时间周期性压缩和版本号压缩
整体架构

压缩原理
-
Compact 请求经过 Raft 日志同步给多数节点后,etcd 会从 Raft 日志取出 Compact 请求,应用此请求到状态机执行
-
执行流程如下图所示
- MVCC 模块的 Compact 接口首先会检查 Compact 请求的版本号 rev 是否已被压缩过,若是则返回 ErrCompacted 错误给 client
- 其次会检查 rev 是否大 于当前 etcd server 的最大版本号,若是则返回 ErrFutureRev 给 client
- 通过检查后,Compact 接口会通过 boltdb 的 API 在 meta bucket 中更新当前已调度的压缩版本号 (scheduledCompactedRev) 号,然后将压缩任务追加到 FIFO Scheduled 中,异步调度执行
-

-
为什么 Compact 接口需要持久化存储当前已调度的压缩版本号到 boltdb 中呢?
- 试想下如果不保存这个版本号,etcd 在异步执行的 Compact 任务过程中 crash 了,那么 异常节点重启后,各个节点数据就会不一致。
- 因此 etcd 通过持久化存储 scheduledCompactedRev,节点 crash 重启后,会重新向 FIFO Scheduled 中添加压缩任务,已保证各个节点间的数据一致性。
-
异步的执行压缩任务会做哪些工作呢?
- 首先回顾 treeIndex 索引模块,它是 etcd 支持保存历史版本的核心 模块,每个 key 在 treeIndex 模块中都有一个 keyIndex 数据结构,记录其历史版本号信息
- 异步压缩任务的第一项工作,就是压缩 treeIndex 模块中的各 key 的历 史版本、已删除的版本
-

- 为了避免压缩工作影响读写性能,首先会克隆一个 B-tree,然后通过克隆后的 B-tree 遍历每一个 keyIndex 对象,压缩历史版本号、清理已删除的版本。
- 假设当前压缩的版本号是 CompactedRev, 它会保留 keyIndex 中最大的版本号,移除小于等于 CompactedRev 的版本号,并通过一个 map 记录 treeIndex 中有效的版本号返回 给 boltdb 模块使用
- 为什么要保留最大版本号呢?
- 因为最大版本号是这个 key 的最新版本,移除了会导致 key 丢失。而 Compact 的目的是 回收旧版本
- Compact 任务执行完索引压缩后,它通过遍历 B-tree、keyIndex 中的所有 generation 获得当前内存索引模块中有效的版本号,这些信息将帮助 etcd 清理 boltdb 中的废弃历史 版本
-
- 压缩任务的第二项工作就是删除 boltdb 中废弃的历史版本数据。如上图所示,它通过 etcd 一个名为 scheduleCompaction 任务来完成
-

- scheduleCompaction 任务会根据 key 区间,从 0 到 CompactedRev 遍历 boltdb 中的 所有 key,通过 treeIndex 模块返回的有效索引信息,判断这个 key 是否有效,无效则调 用 boltdb 的 delete 接口将 key-value 数据删除
- 在这过程中,scheduleCompaction 任务还会更新当前 etcd 已经完成的压缩版本号 (finishedCompactRev),将其保存到 boltdb 的 meta bucket 中
- scheduleCompaction 任务遍历、删除 key 的过程可能会对 boltdb 造成压力,为了不影响正常读写请求,它在执行过程中会通过参数控制每次遍历、删除的 key 数(默认为 100,每批间隔 10ms),分批完成 boltdb key 的删除操作
-
为什么压缩后 db 大小不减少呢?
- 上节课我们介绍 boltdb 实现时,提到过 boltdb 将 db 文件划分成若干个 page 页,page 页又有四种类型,分别是 meta page、branch page、leaf page 以及 freelist page
- branch page 保存 B+ tree 的非叶子节点 key 数据,leaf page 保存 bucket 和 key value 数据,freelist 会记录哪些页是空闲的
- 当我们通过 boltdb 删除大量的 key,在事务提交后 B+ tree 经过分裂、平衡,会释放出 若干 branch/leaf page 页面,然而 boltdb 并不会将其释放给磁盘,调整 db 大小操作是 昂贵的,会对性能有较大的损害
- boltdb 是通过 freelist page 记录这些空闲页的分布位置,当收到新的写请求时,优先从 空闲页数组中申请若干连续页使用,实现高性能的读写(而不是直接扩大 db 大小)。当 连续空闲页申请无法得到满足的时候, boltdb 才会通过增大 db 大小来补充空闲页。
- 一般情况下,压缩操作释放的空闲页就能满足后续新增写请求的空闲页需求,db 大小会趋 于整体稳定。