分布式数据库的优势是将IO分散在不同的Physical Disk上,每次查询都由多台Server的CPU,I/O共同负载,通过各节点并行处理数据来提高性能,劣势是消耗大量的网络带宽资源,管理难度大。在SQL Server 2012 版本中,创建水平切分的分布式数据库,必须分两步来实现:划分子集和对子集进行并集操作。
划分子集是将原始表水平切分成若干个较小的成员表,每一个成员表都是全集的一个划分(各子集的并集是全集,其交集是空集)。每个成员表包含与原始表相同数量的列,并且每一列具有与原始表中的相应列同样的特性(如数据类型、大小、排序规则),成员表的schema和原始表相同,只是存储的数据不同。水平切分原始表,也叫做数据库水平分片,sharding。在查询时,利用分区视图来实现水平分片对用户透明,分区视图对分布在不同服务器中的分区数据进行并集操作,使数据看起来来自一个表。
分布在不同场地的SQL Server通过Linked Server相互通信,通过MSDTC来保证查询的事务特性。Linked Server定义从某一数据库服务器到另一数据库服务器的单向通信路径,而MSDTC能够保证一个事务在不同的Server上实现ACID属性。例如,在一个事务中存在 Server1上的 Insert 操作和 Server2上 Update 操作 ,如果事务回滚,那么MSDTC保证Server1 和 Server2的操作都要回滚;如果事务提交,MSDTC保证Server1 和 Server2的操作都要Commit。
设计目的:将table dbo.Person 的数据水平分片,分布到两天SQL Server上,Column [PersonType] 共有6个值,分别是:('IN','EM','SP'),('SC','VC','GC');

CREATE TABLE [dbo].[Person] ( [PersonID] [int] NOT NULL, [PersonType] [nchar](2) NOT NULL, [FirstName] [sysname] NOT NULL, [MiddleName] [sysname] NOT NULL, [LastName] [sysname] NOT NULL )
step1,打开Win10 MSDTC(Microsoft Distributed Transaction Coordinator)
参考《Win10 打开MSDTC》,不再赘述。
step2,分别在两台Server上创建数据库和表,数据库分别是DBtest1 和 DBTest2,将DBTest1作为Master DB,将DBTest2作为Slave DB。
--default instance CREATE TABLE [dbo].[Person]( [PersonID] [int] NOT NULL, [PersonType] [nchar](2) NOT NULL, [FirstName] sysname, [MiddleName] sysname , [LastName] sysname, constraint chk__Person_PersonType check([PersonType] in ('IN','EM','SP')) ); --named instance CREATE TABLE [dbo].[Person]( [PersonID] [int] NOT NULL, [PersonType] [nchar](2) NOT NULL, [FirstName] sysname, [MiddleName] sysname , [LastName] sysname, constraint chk__Person_PersonType check([PersonType] in ('SC','VC','GC')) );
Step3,在Master DB中,添加Linked Server
--add linked server exec sys.sp_addlinkedserver @server= N'db1'
,@srvproduct= N'' ,@provider= N'SQLNCLI' ,@datasrc= N'LJHPC\NamedInstance1' ,@location= null ,@provstr= null ,@catalog= N'dbtest2' --check select * from sys.servers where is_linked=1 --drop linked server --EXEC sys.sp_dropserver @server=N'db1', @droplogins='droplogins' --add login exec sp_addlinkedsrvlogin @rmtsrvname = 'db1' ,@useself=false ,@locallogin=null ,@rmtuser ='sa' ,@rmtpassword='sa'
step4,创建分布式水平分区视图
create view dbo.view_Person as select [PersonID] ,[PersonType] ,[FirstName] ,[MiddleName] ,[LastName] from [dbo].[Person] with(nolock) where [PersonType] in('IN','EM','SP') union all select [PersonID] ,[PersonType] ,[FirstName] ,[MiddleName] ,[LastName] from db1.[DBTest2].[dbo].[Person] with(nolock) where [PersonType] in('SC','VC','GC') with check OPTION;
Step5,查询分布式数据,查看执行计划
SELECT * from dbo.view_Person p where p.PersonType in ('em','sc')
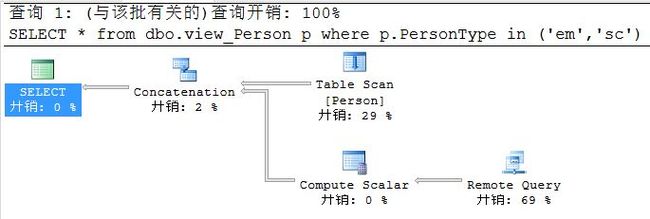
Step6,优化
分布式事务使用的资源远大于内部事务,通常使用OPENQUERY等相关行集函数,避免过度依赖分布式事务。
1,使用OpenQuery,避免DTC的干预
create view dbo.view_Person as select [PersonID] ,[PersonType] ,[FirstName] ,[MiddleName] ,[LastName] from [dbo].[Person] with(nolock) where [PersonType] in('IN','EM','SP') union all select [PersonID] ,[PersonType] ,[FirstName] ,[MiddleName] ,[LastName] from OPENQUERY ( db1 , N'select [PersonID] ,[PersonType] ,[FirstName] ,[MiddleName] ,[LastName] from db1.[DBTest2].[dbo].[Person] with(nolock) where [PersonType] in(''SC'',''VC'',''GC'')' ) as p with check OPTION;
2,在Local Server上更新分片数据
update db1.DBTEST2.dbo.person set FirstName=N'Harm' where PersonId=102; --修改成 exec db1.DBTEST2.sys.sp_executesql N'update dbo.person set FirstName=N''Harm'' where PersonId=102;'
Appendix
--SQL Server 阻止了对组件 'Ad Hoc Distributed Queries' exec sp_configure 'show advanced options',1 reconfigure exec sp_configure 'Ad Hoc Distributed Queries',1 reconfigure --使用完成后,关闭Ad Hoc Distributed Queries: exec sp_configure 'Ad Hoc Distributed Queries',0 reconfigure exec sp_configure 'show advanced options',0 reconfigure
参考doc:
Top 3 Performance Killers For Linked Server Queries