redis集群
1.定义
由于数据量过大,单个master复制集难以承担,因需要对多个复制集进行集群,形成水平扩展,每个复制集只负责存储整个数据集的一部分,这就是redis的集群,其作用是提供在多个redis节点间共享数据的程序集。
(1)redis集群支持多个master,每个master又可以挂载多个slave
(2)由于cluster自带sebtinel的故障转移机制,内置了高可用的支持,无需再去使用哨兵功能。
(3)客户端与redis的节点连接,不再需要连接集群中所有的节点,只需要任意连接集群中的一个可用节点即可
(4)槽位slot负责分配到各个物理服务节点,由对应的集群来负责维护节点、插槽和数据之间的关系
2.分片
分片是什么?
使用redis集群时,我们会将存储的数据分散到多台redis机器上,这称为分片,简言之,集群中的每个redis实例都被认为是整个数据的一个分片
如何找到给定key的分片?
为了找到给定key的分片,我们对key进行CRC16(key)算法处理并通过对总分片数量取模,然后,使用确定性哈希函数,这意味着给定的key将多次始终映射到同一个分片,我们可以推断将来读取特定key的位置
优势
方便扩容、缩容和数据分派查找

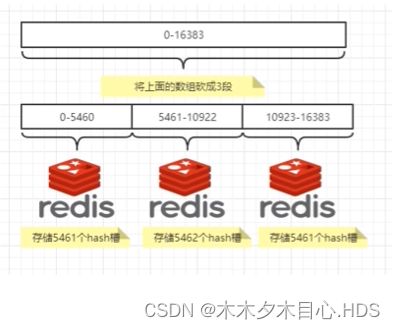
3.哈希槽算法
redis集群中内置了16384个哈希槽,redis会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要再redis集群中放置一个key-value时,redis先对key使用CRC16算法算出一个结果然后用结果对16384求余[CRC16(key)%16384],这样每个key都会对应一个编号在0-16384之间的哈希槽,也就是映射到某个节点上。
另外两种算法:
哈希取余算法、一致性hash算法
4.为什么redis集群的最大槽数是16384?
redis集群并没有使用一致性hash而是引入了哈希槽的概念。redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模决定位于的槽位,集群的每个节点负责一部分hash槽。但为什么哈希槽的数量是16384(2^14)个呢?
CRC16算法产生的hash值有16bit,该算法可以产生2^16=65536个值。换句话说值是分布在0~65535之间,有更大的65535不用为什么只用16384就可以了?
原因:正常的心跳数据包带有节点的完整配置,可以用幂等方式用旧的节点替换旧节点,以便更新旧的配置。这意味着它们包含原始节点的插槽配置,该节点使用2k的空间和16k的插槽,但是会使用8k的空间(使用65k的插槽)。同时,由于其他设计折衷,redis集群不太可能扩展到1000个以上的主节点。因此16k处于正确的范围内,以确保每个机器具有足够的插槽,做多可容纳1000个矩阵,但数量足够少,可以轻松地将插槽配置作为原始位图传播。在小型集群中,位图将难以压缩,因为当N较小时,位图将设置的slot/N位占设置位的很大百分比。
(1)如果槽位位65535,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
在消息头中最占空间的时myslots[CLUSTER_SLOTS/8]。当槽位是65535时,这块大小是:65535/8/1024=8kb。当槽位是16384时,这块大小是:16384/8/1024=2kb。因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为65535,这个ping消息的消息头太大了,浪费带宽。
(2)redis的集群主节点数量基本不可能超过1000个
集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者不建议集群节点超过1000个。那么,对于节点数量在1000以内的集群,16384个槽位够用了。没用必要扩展到65535个。
(3)槽位越小,节点少的情况下,压缩比高,容易传输
redis主节点的配置信息中它所负责的哈希槽是通过一张bitmap的形式保存的,在传输过程中会对bitmap进行压缩,但是如果bitmap的填充率slots/N很高的话(N表示节点),bitmap的压缩率就很低。如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很高。
5.构建redis集群
(1)主机192.168.1.5,两个配置文件redis6379.conf、redis6380.conf
redis6379.conf
# bind * -::*
daemonize yes
protected-mode no
port 6379
logfile "/tmp/redis6379.log"
pidfile "/var/run/redis_6379.pid"
dir "/root/redis/my_cluster_conf/dumpdir"
dbfilename "dump6379.rdb"
appendonly yes
appendfilename "appendonly6379.aof"
requirepass "root"
masterauth "root"
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
redis6380.conf
# bind * -::*
daemonize yes
protected-mode no
port 6380
logfile "/tmp/redis6380.log"
pidfile "/var/run/redis_6380.pid"
dir "/root/redis/my_cluster_conf/dumpdir"
dbfilename "dump6380.rdb"
appendonly yes
appendfilename "appendonly6380.aof"
requirepass "root"
masterauth "root"
cluster-enabled yes
cluster-config-file nodes-6380.conf
cluster-node-timeout 15000
(2)主机192.168.1.6,两个配置文件redis6379.conf、redis6380.conf,与上面一样
(3)主机192.168.1.7,两个配置文件redis6379.conf、redis6380.conf,与上面一样
(4)在每个机器上启动redis
redis-server ./redis6379.conf
redis-server ./redis6380.conf
(5)创建集群
redis-cli -a root --cluster create --cluster-replicas 1 192.168.1.5:6379 192.168.1.5:6380 192.168.1.6:6379 192.168.1.6:6380 192.168.1.7:6379 192.168.1.7:6380
注意,集群至少3个master

连接集群
redis-cli -a root -c -p 6379
输入命令查看集群节点


(6)redis集群常用命令
cluster info
cluster nodes
redis-cli -a root --cluster check 192.168.1.6:6380
# 查看槽数是否被占用
CLUSTER COUNTKEYSINSLOT {槽位数字}
# 计算某key的槽位
CLUSTER KEYSLOT {key}
当集群中某个master宕机了,集群中会有另外一个slave节点接替宕机master的位置和数据