时间序列预测实战(十三)定制化数据集FNet模型实现滚动长期预测并可视化结果

论文地址->官方论文代码地址
官方代码地址->官方下载地址Github
个人修改代码地址-> 个人修改版本呢的下载地址CSDN
一、本文介绍
本博客将介绍一种新的时间序列预测模型——FNet,它通过使用傅里叶变换代替自注意力机制,旨在解决传统Transformer模型中的效率问题。FNet模型通过简单的线性变换,包括非参数化的傅里叶变换,来“混合”输入令牌,从而实现了快速且高效的处理方式。这种创新的方法在保持了相对较高的准确性的同时,显著提高了训练速度,特别是在处理长序列数据时更显优势。本文的内容包括:FNet的工作原理,并通过一个实战案例展示如何实现基于FNet的可视化结果和滚动长期预测。
预测类型->多元预测、单元预测、长期预测。
适用对象->资源受限的环境,例如生产服务器或边缘设备
二、FNet的工作原理
1.FNet的框架原理
FNet是一种基于Transformer编码器架构的模型,通过替换自注意力子层为简单的线性变换,特别是傅里叶变换,来加速处理过程。FNet架构中的每一层由一个傅里叶混合子层和一个前馈子层组成(下图中的白色框)。傅里叶子层应用2D离散傅里叶变换(DFT)到其输入,一维DFT沿序列维度和隐藏维度。

总结:FNet相对于传统的Transformer的改进其实就一点就是将注意力机制替换为傅里叶变换,所以其精度并没有提升(我觉得反而有下降,但是论文内相等,但是从我的实验角度结果分析精度是有下降的),其这么改进的主要效果就是训练速度的加快,因为注意力机制一般都需要复杂计算,傅里叶变化的计算很简单。
2.FNet的主要优势
FNet的改进主要优势可能就是其训练速度了,这适合一些资源受限的环境,例如生产服务器或边缘设备,当我们在实际工作时候生产环境一般都不带有GPU的所以速度就很重要了,下面我来分析其训练速度的提升。

上面的这张图表展示了不同模型在掩码语言模型(MLM)任务中的准确性与训练步骤时间的关系。时间以毫秒(ms)为单位,采用对数尺度表示,可以看出随着训练时间的增加,准确性有所提升
图中展示了四种不同的模型:
- BERT(用蓝色圆点表示)
- Linear(用红色三角形表示)
- FNet(用黄色方块表示)
- FNet-Hybrid(用绿色星形表示)
从图中可以观察到以下几点:
- BERT模型在相对较短的训练时间内提供了高准确性,但随着时间的增加,准确性提升的速度放缓。
- Linear模型在初始阶段准确性较低,但随着训练时间的增加,其准确性的提升速度似乎比BERT模型要快。
- FNet模型的表现介于BERT和Linear模型之间,表明其在训练速度和准确性之间取得了一定的平衡。
- FNet-Hybrid模型与FNet相比,似乎在较长的训练时间内达到了更高的准确性,这表明在FNet中加入了一些自注意力机制可能会有所帮助。
此图的一个关键信息是,尽管BERT在开始时领先,但随着时间的推移,其他模型在准确性上逐渐接近BERT,这表明对于有限的训练时间,其他模型可能是更有效的选择。此外,考虑到时间和准确性的平衡我们本文的模型FNet和FNet-Hybrid可能更适合在资源有限的情况下使用。
三、数据集介绍
本文所用到的数据集为某公司的业务水平评估和其它参数具体的内容我就介绍了估计大家都是想用自己的数据进行训练模型,这里展示部分图片给大家提供参考->

四、参数讲解
模型涉及到的参数全部如下->
parser = argparse.ArgumentParser(description='FNet Multivariate Time Series Forecasting')
# basic config
parser.add_argument('--train', type=bool, default=True, help='Whether to conduct training')
parser.add_argument('--rollingforecast', type=bool, default=True, help='rolling forecast True or False')
parser.add_argument('--rolling_data_path', type=str, default='ETTh1-Test.csv', help='rolling data file')
parser.add_argument('--show_results', type=bool, default=True, help='Whether show forecast and real results graph')
parser.add_argument('--model', type=str, default='FNet',help='Model name')
# data loader
parser.add_argument('--root_path', type=str, default='./data/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file')
parser.add_argument('--features', type=str, default='MS',
help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
parser.add_argument('--target', type=str, default='OT', help='target feature in S or MS task')
parser.add_argument('--freq', type=str, default='h',
help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
parser.add_argument('--checkpoints', type=str, default='./models/', help='location of model models')
# forecasting task
parser.add_argument('--seq_len', type=int, default=126, help='input sequence length')
parser.add_argument('--label_len', type=int, default=64, help='start token length')
parser.add_argument('--pred_len', type=int, default=4, help='prediction sequence length')
# model
parser.add_argument('--norm', action='store_false', default=True, help='whether to apply LayerNorm')
parser.add_argument('--rev', action='store_true', default=True, help='whether to apply RevIN')
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
parser.add_argument('--n_heads', type=int, default=1, help='num of heads')
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size')
parser.add_argument('--dec_in', type=int, default=7, help='decoder input size')
parser.add_argument('--c_out', type=int, default=7, help='output size')
parser.add_argument('--dropout', type=float, default=0.05, help='dropout')
parser.add_argument('--embed', type=str, default='timeF',
help='time features encoding, options:[timeF, fixed, learned]')
parser.add_argument('--activation', type=str, default='gelu', help='activation')
# optimization
parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
parser.add_argument('--train_epochs', type=int, default=10, help='train epochs')
parser.add_argument('--batch_size', type=int, default=16, help='batch size of train input data')
parser.add_argument('--learning_rate', type=float, default=0.001, help='optimizer learning rate')
parser.add_argument('--loss', type=str, default='mse', help='loss function')
parser.add_argument('--lradj', type=str, default='type1', help='adjust learning rate')
# GPU
parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--device', type=int, default=0, help='gpu')参数的详细讲解如下->
| 参数名称 | 参数类型 | 参数讲解 | |
|---|---|---|---|
| 0 | train | bool | 是否进行训练,如果你单纯只想进行预测设置为False即可, |
| 1 | rollingforecast | bool | 是否进行滚动预测,如果是则设置为True,如果不进行滚动预测则进行正常的预测 |
| 2 | rolling-data-path | str | 如果进行滚动预测则需要添加新的和训练文件相同格式的数据 |
| 3 | show_results | bool | 是否保存预测值和真实值的滚动预测对比图 |
| 4 | model | str | 定义的模型名称 |
| 5 | root_path | str | 这个才是你文件的路径,不要到具体的文件,到目录级别即可。 |
| 6 | data_path | str | 这个填写你文件的具体名称。 |
| 7 | features | str | 这个是特征有三个选项M,MS,S。分别是多元预测多元,多元预测单元,单元预测单元。 |
| 8 | target | str | 这个是你数据集中你想要预测那一列数据,假设我预测的是油温OT列就输入OT即可。 |
| 9 | freq | str | 时间的间隔,你数据集每一条数据之间的时间间隔。 |
| 10 | checkpoints | str | 训练出来的模型保存路径 |
| 11 | seq_len | int | 用过去的多少条数据来预测未来的数据 |
| 12 | label_len | int | 可以理解为更高的权重占比的部分要小于seq_len |
| 13 | pred_len | int | 预测未来多少个时间点的数据 |
| 14 | norm | int | 这个参数控制是否应用层归一化 |
| 15 | rev | int | 表明这个参数控制是否应用RevIN操作(推荐大家使用) |
| 16 | enc_in | int | 你数据有多少列,要减去时间那一列,这里我是输入8列数据但是有一列是时间所以就填写7 |
| 17 | dec_in | int | 同上 |
| 18 | c_out | int | 这里有一些不同如果你的features填写的是M那么和上面就一样,如果填写的MS那么这里要输入1因为你的输出只有一列数据。 |
| 19 | d_model | int | 用于设置模型的维度,默认值为512。可以根据需要调整该参数的数值来改变模型的维度 |
| 20 | n_heads | int | 用于设置模型中的注意力头数。默认值为8,表示模型会使用8个注意力头,我建议和的输入数据的总体保持一致,列如我输入的是8列数据不用刨去时间的那一列就输入8即可。 |
| 21 | e_layers | int | 用于设置编码器的层数 |
| 22 | d_layers | int | 用于设置解码器的层数 |
| 23 | s_layers | str | 用于设置堆叠编码器的层数 |
| 24 | dropout | float | 这个应该都理解不说了,丢弃的概率,防止过拟合的。 |
| 25 | embed | str | 时间特征的编码方式,默认为"timeF" |
| 26 | activation | str | 激活函数 |
| 27 | num_workers | int | 线程windows大家最好设置成0否则会报线程错误,linux系统随便设置。 |
| 28 | train_epochs | int | 训练的次数 |
| 29 | batch_size | int | 一次往模型力输入多少条数据 |
| 30 | learning_rate | float | 学习率。 |
| 31 | loss | str | 损失函数,默认为"mse" |
| 32 | lradj | str | 学习率的调整方式,默认为"type1" |
| 33 | use_gpu | bool | 是否使用GPU训练,根据自身来选择 |
| 34 | gpu | int | GPU的编号 |
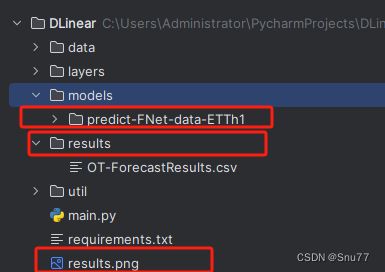
五、项目结构
项目的目录结构如下图->

其中的main.py文件为我们程序的主入口其中的配置如下->
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='FNet Multivariate Time Series Forecasting')
# basic config
parser.add_argument('--train', type=bool, default=True, help='Whether to conduct training')
parser.add_argument('--rollingforecast', type=bool, default=True, help='rolling forecast True or False')
parser.add_argument('--rolling_data_path', type=str, default='ETTh1-Test.csv', help='rolling data file')
parser.add_argument('--show_results', type=bool, default=True, help='Whether show forecast and real results graph')
parser.add_argument('--model', type=str, default='FNet',help='Model name')
# data loader
parser.add_argument('--root_path', type=str, default='./data/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file')
parser.add_argument('--features', type=str, default='MS',
help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
parser.add_argument('--target', type=str, default='OT', help='target feature in S or MS task')
parser.add_argument('--freq', type=str, default='h',
help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
parser.add_argument('--checkpoints', type=str, default='./models/', help='location of model models')
# forecasting task
parser.add_argument('--seq_len', type=int, default=126, help='input sequence length')
parser.add_argument('--label_len', type=int, default=64, help='start token length')
parser.add_argument('--pred_len', type=int, default=4, help='prediction sequence length')
# model
parser.add_argument('--norm', action='store_false', default=True, help='whether to apply LayerNorm')
parser.add_argument('--rev', action='store_true', default=True, help='whether to apply RevIN')
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
parser.add_argument('--n_heads', type=int, default=1, help='num of heads')
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size')
parser.add_argument('--dec_in', type=int, default=7, help='decoder input size')
parser.add_argument('--c_out', type=int, default=7, help='output size')
parser.add_argument('--dropout', type=float, default=0.05, help='dropout')
parser.add_argument('--embed', type=str, default='timeF',
help='time features encoding, options:[timeF, fixed, learned]')
parser.add_argument('--activation', type=str, default='gelu', help='activation')
# optimization
parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
parser.add_argument('--train_epochs', type=int, default=10, help='train epochs')
parser.add_argument('--batch_size', type=int, default=16, help='batch size of train input data')
parser.add_argument('--learning_rate', type=float, default=0.001, help='optimizer learning rate')
parser.add_argument('--loss', type=str, default='mse', help='loss function')
parser.add_argument('--lradj', type=str, default='type1', help='adjust learning rate')
# GPU
parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--device', type=int, default=0, help='gpu')
args = parser.parse_args()
Exp = SCINetinitialization
# setting record of experiments
setting = 'predict-{}-data-{}'.format(args.model, args.data_path[:-4])
SCI = SCINetinitialization(args) # 实例化模型
if args.train:
print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(args.model))
SCI.train(setting)
print('>>>>>>>predicting : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(args.model))
SCI.predict(setting, True)
plt.show()
六、模型训练和预测
1.模型训练
当我们配置好所有的参数以后就可以开始训练了,控制台的输出如下->
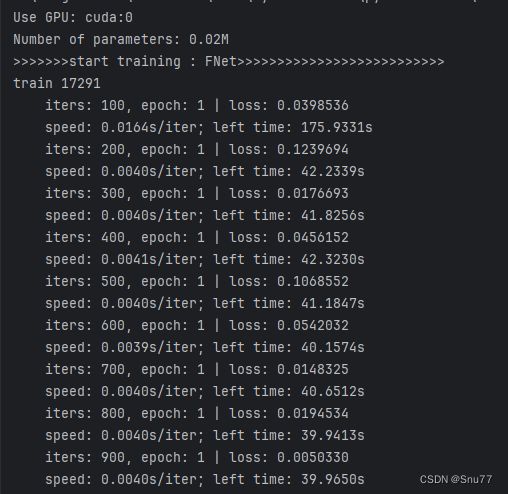
2.滚动预测
我们进行滚动长期预测,共预测未来的五百条数据,每次预测四条数据,控制台输入如下->

2.1结果展示
下面的图片就是预测值和真实值的对比,这个模型FNet和我前面用到的一些模型相比结果真的不是很好,我也不知道模型本身就是这样还是该模型的效果有什么问题,但是训练的速度和推理速度还是挺快的。

3.结果保存
我们的滚动预测的输出结果和训练的模型和预测值和真实值的对比分别保存在下图的标注的路径上。
七、如何定制化训练个人数据集
这个模型我在写的过程中为了节省大家训练自己数据集,我基本上把大部分的参数都写好了,需要大家注意的就是如果要进行滚动预测下面的参数要设置为True。
parser.add_argument('--rollingforecast', type=bool, default=True, help='rolling forecast True or False')如果上面的参数设置为True那么下面就要提供一个进行滚动预测的数据集,该数据集的格式要和你训练模型的数据集格式完全一致(重要!!!),如果没有可以考虑在自己数据的尾部剪切一部分,不要粘贴否则数据模型已经训练过了的话预测就没有效果了。
parser.add_argument('--rolling_data_path', type=str, default='ETTh1-Test.csv', help='rolling data file')其它的没什么可以讲的了大部分的修改操作在参数讲解的部分我都详细讲过了,这里的滚动预测可能是大家想看的所以摘出来详细讲讲。
全文总结
到此本文已经全部讲解完成了,希望能够帮助到大家,在这里也给大家推荐一些我其它的博客的时间序列实战案例讲解,其中有数据分析的讲解就是我前面提到的如何设置参数的分析博客,最后希望大家订阅我的专栏,本专栏均分文章均分98,并且免费阅读。
概念理解
15种时间序列预测方法总结(包含多种方法代码实现)
数据分析
时间序列预测中的数据分析->周期性、相关性、滞后性、趋势性、离群值等特性的分析方法
机器学习——难度等级(⭐⭐)
时间序列预测实战(四)(Xgboost)(Python)(机器学习)图解机制原理实现时间序列预测和分类(附一键运行代码资源下载和代码讲解)
深度学习——难度等级(⭐⭐⭐⭐)
时间序列预测实战(五)基于Bi-LSTM横向搭配LSTM进行回归问题解决
时间序列预测实战(七)(TPA-LSTM)结合TPA注意力机制的LSTM实现多元预测
时间序列预测实战(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
时间序列预测实战(十一)用SCINet实现滚动预测功能(附代码+数据集+原理介绍)
时间序列预测实战(十二)DLinear模型实现滚动长期预测并可视化预测结果
Transformer——难度等级(⭐⭐⭐⭐)
时间序列预测模型实战案例(八)(Informer)个人数据集、详细参数、代码实战讲解
时间序列预测模型实战案例(一)深度学习华为MTS-Mixers模型
个人创新模型——难度等级(⭐⭐⭐⭐⭐)
时间序列预测实战(十)(CNN-GRU-LSTM)通过堆叠CNN、GRU、LSTM实现多元预测和单元预测
传统的时间序列预测模型(⭐⭐)
时间序列预测实战(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)
时间序列预测实战(六)深入理解ARIMA包括差分和相关性分析
融合模型——难度等级(⭐⭐⭐)
时间序列预测实战(九)PyTorch实现融合移动平均和LSTM-ARIMA进行长期预测
