多线程的再学习
多线程学习
- 启动线程的方式
- 线程基本的方法
- 数据操作不加锁会怎样?
- synchronized是可重入的吗?
- 锁遇到异常会释放吗?
- CAS(自旋)
- 对象在内存中的布局
- 锁的升级过程
- 什么是重量级锁?
- 锁消除和锁粗化
- 锁与对象
- 公平锁与非公平锁
本文主要是跟着B站马士兵老师的课学习做的笔记,老师的课真的值得一看!!!
课程链接:https://www.bilibili.com/video/BV1xK4y1C7aT?from=search&seid=5058132445119285717
启动线程的方式
先创建一个线程,随后创建线程对象,并调用对象的run() 或者 start(),这两种方式有何不同呢?我们看一段代码
public class StartThread {
//创建一个线程,以静态内部类的方式
private static class Thread1 extends Thread {
@Override
public void run() {
for(int i = 0; i < 5; i++) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t1");
}
}
}
public static void main(String[] args) {
new Thread1().run(); //方式1
//new Thread1().start(); //方式2
for(int i = 0; i < 5; i++) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("main");
}
}
}
执行main方法,并分别测试方式1和方式2,发现结果大不相同:
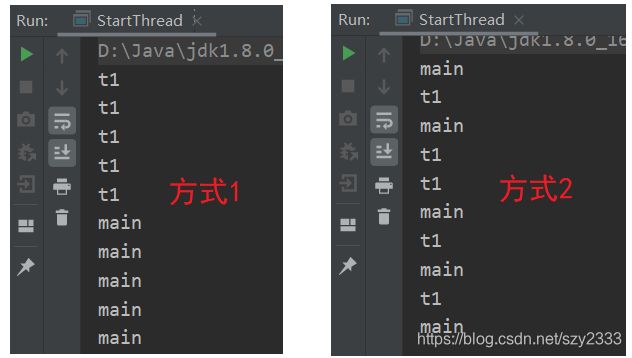
可以看出,以方式1执行,程序是先输出t1,再输出main;方式2则是两者交替乱序执行。其实start() 才是真正启动线程的方式,调用start,程序会开辟一个新的线程,与主线程抢夺时间片交替执行,而如果是run(),虽然Thread1的内容也被执行了,但是这相当于是一个普通的方法调用,因此是顺序执行的。同时,start方法内部中是调用了run方法的。
线程基本的方法
sleep():当前线程睡眠一段时间,让给别的线程去执行。
yield():让出一下CPU,返回至就绪状态,即先从CPU上离开,进入等待队列。
join():在线程调用时,先执行其他的线程,等到另外线程调用完毕再回来继续执行自己的代码。经常用于等待另外一个线程的结束。
数据操作不加锁会怎样?
先看一段代码:我们对于count进行运算,启动100个线程每次对count减一,随后输出count值
public class ThreadCount implements Runnable {
private static int count = 100;
public /*synchronized*/ void run() {
count--;
System.out.println(Thread.currentThread().getName() + " count = " + count);
}
public static void main(String[] args) {
ThreadCount threadCount = new ThreadCount();
for(int i = 0; i < 100; i++) {
new Thread(threadCount, "Thread" + i).start();
}
}
}
输出结果:
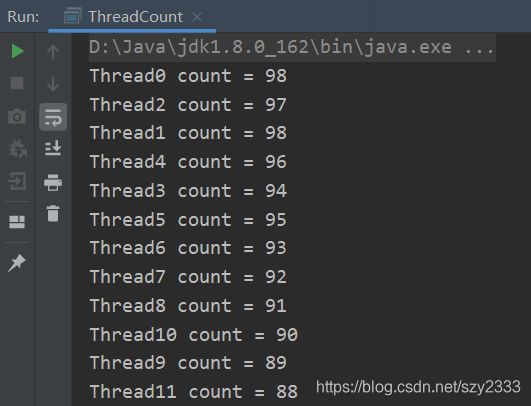
可以看到数据是不规律的,这是因为操作数据时,run方法里的两条数据不是原子性的,有可能上一个线程进行进行了count–,还没等到输出,结果其他线程又进行了count–,最后导致数据并不能按照规律的每次减一执行。想要编程原子操作,只需要将run加锁即可。
synchronized是可重入的吗?
先说答案,必须是可重入的!
例如父类和子类的 fun() 都被synchronized修饰,子类执行super.fun(),如果不是可重入锁,那么这种继承会成为死锁。在比如同一个类中,f1() 和 f2() 都被synchronized修饰,且f1() 调用了 f2(),如果不是可重入,这又会造成死锁,这显然是不可行的。
注:synchronized修饰方法锁的是this对象
锁遇到异常会释放吗?
实践出真知,我们写一段代码执行count的操作,并自己制造出一个异常,当线程1先拿到锁执行,遇到异常后,会出现怎么样的结果
public class LockAndException {
int count = 0;
synchronized void fun() {
while (true) {
count++;
System.out.println(Thread.currentThread().getName() + " count : " + count);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
if(count == 5) {
//制造异常
int i = 1 / 0;
}
}
}
public static void main(String[] args) {
LockAndException lae = new LockAndException();
Runnable r = new Runnable() {
@Override
public void run() {
lae.fun();
}
};
new Thread(r, "t1").start();
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(r, "t2").start();
}
}
代码结果:
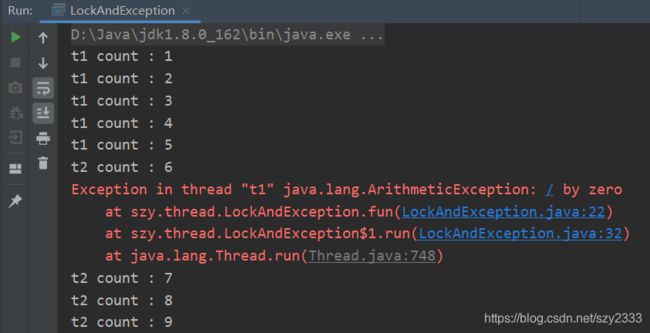
从结果中,我们可以看出线程1遇到异常后,线程2可以拿到锁然后执行,这说明锁遇到异常默认是释放的,因此在业务逻辑中加锁时一定要注意异常的处理。
CAS(自旋)
CAS,即 compare and swap,意思就是先比较后交换:先拿到当前的值A并计算结果值V,然后拿到当前的新值N,在改变新值之前,先比较A和N值是否一致,如果一致,则更新值为V,如果不一致,那就重新执行这个步骤。流程图如下:
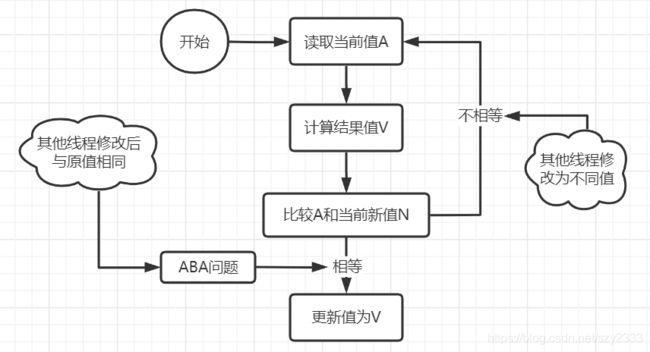
流程中的ABA问题是什么呢?
就是原值为0,多个线程对数据进行修改,但修改的最后值依然为0,此时虽然N为0,但已经不是原来的那个值了
如何解决呢?
加上版本号,这样之后不仅比较值,也比较版本号。
在执行时间短,线程较少的情况下适合使用自旋锁。
对象在内存中的布局
偷的马老师的图嘿嘿

锁的升级过程
1.首先new一个对象,此时是无锁状态的。
2.从无锁升级到偏向锁。在第一个线程对这个对象上锁,其实是将自己的线程id贴上,代表这个对象属于我了。这样的好处是:只有一个线程时,可以不需要向CPU申请那么重量级的锁来耗费时间,执行完任务随后等到下一次拿到锁发现上面锁的标签还是自己时,直接拿过来用就可以
3.等到有另一个线程竞争时,就会自动升级为轻量级锁。首先撤销偏向锁状态,由于每个线程都有自己的线程栈,在自己的线程栈中可以生成对象,即生成锁记录(LockRecord),随后,两个LockRecord对对象进行抢夺(使用自旋的方式,即CAS),看谁可以先把对象的markword设置为指向自己的指针,设置成功者得到锁。
4.在自旋锁达到一定状态的时候(JVM自己控制),自旋太占用CPU,此时就会升级为重量级锁。为什么一定要升级为重量级锁?因为重量级锁会有一个自己的队列,升级成功其他线程会自动进入队列,只要锁没有释放,线程在队列为wait状态,不消耗任何CPU
Q:既然锁可以升级,那么该如何降级呢?
A:锁降级是发生在GC的一个状态,在这个锁不被其他任何线程锁定了就降级了,但实际上没有什么意义,因为都在GC了,因此可以简单的认为锁降级不存在
推荐马老师关于锁升级的文章:我就是厕所所长,这个文章太秀了
什么是重量级锁?
Q:首先,我们需要知道一些概念,用户态和内核态,这是什么呢?
A:现在的操作系统,把执行状态分成了这两种状态,内核态是指非常核心的和硬件打交道的操作,只有它能执行,例如想要往网卡或者显卡上写数据,就必须交给内核帮助执行,而不能直接去访问硬件。而我们的一般的应用程序操作则是在用户态上。也就是说如果用户态想要执行一些特殊的操作时需要交给内核态执行,例如拿锁(重量级锁)。
重量级锁也称为互斥锁或者悲观锁。锁在内核中实际上是互斥的数据结构,这些结构是有数量限制的,而我们申请重量级锁是需要向内核申请,申请成功后Markword会指向重量级锁的指针。
Q:那么轻量级锁为什么一定要经过内核态升级为重量级锁呢?
A:轻量级锁虽然是执行在用户态上,效率高,但是它实际上就是在执行一个循环,如果竞争特别激烈, 几千几万个线程在循环,然鹅拿到锁的线程却一直不释放,那么CPU消耗会特别高!此时,就需要升级为重量级锁。升级成功后,其他线程会自动进入这把锁的等待队列,此时wait状态的线程不需要消耗任何CPU
锁消除和锁粗化
锁消除
锁消除是也是一种优化,它会在编译时,去除不可能存在竞争资源的锁
public void add(String s1, String s2) {
StringBuffer buffer = new StringBuffer();
buffer.append(s1).append(s2);
}
如上代码,StringBuffer中的append方法是被synchronized修饰的,但因为buffer这个引用只会在add方法中使用,由于方法是栈私有的,因此不可能与其他的线程栈共享资源,所以JVM会自动消除StringBuffer对象内部的锁。
锁粗化
public String add2(String str) {
int i = 0;
StringBuffer buffer = new StringBuffer();
while (i < 100) {
buffer.append(str);
i++;
}
return buffer.toString();
}
在add2方法中,对于buffer对象在循环中不断append,在没有锁粗化的情况下,就会进行100次循环的加锁解锁,但优化后,JVM会将加锁的范围粗化到这一连串的外部,如直接加到while循环中,相当于只需要进行一次加锁解锁,这就是锁粗化。
锁与对象
锁住的对象如果变了怎么办呢?
public class LockAndObject {
/*final*/ Object object = new Object();
public void m() {
synchronized (object) {
while (true) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
}
}
}
public static void main(String[] args) {
LockAndObject lao = new LockAndObject();
new Thread(lao::m, "t1").start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(lao::m, "t2").start();
lao.object = new Object(); //如果不注释,那么t2永远不会输出
}
}
在这个程序中,m方法锁住Object对象,第一个线程,随后将Object改变,又使用另一个线程执行m方法,那么执行结果输出会既有t1,又有t2,如果Object对象不改变,那么t2将永远不会被输出。
而这种情况又很容易发生,想要避免对象中途被修改,就需要在最开始为对象使用final关键字修饰,使其不会被修改。
还有另一种问题:如果两个线程表面上锁住了两个对象,但这两个对象实质上是一个对象,这该怎么办?如以下例子:
public class LockAndString {
String str1 = "hello";
String str2 = "hello";
void m1() {
synchronized (str1) {
while (true) {
System.out.println(Thread.currentThread().getName() + str1);
}
}
}
void m2() {
synchronized (str2) {
while (true) {
System.out.println(Thread.currentThread().getName() + str2);
}
}
}
public static void main(String[] args) {
LockAndString las1 = new LockAndString();
LockAndString las2 = new LockAndString();
new Thread(las1::m1, "t1").start();
new Thread(las2::m2, "t222222222222").start();
}
}
虽然两个线程调用的是不同对象的不同方法,但这两个方法实质上锁定的是一个对象,因此会造成死锁。为了避免这种问题,一般会禁止使用String,Integer等类型作为加锁对象。
公平锁与非公平锁
公平锁就是:几个线程在争取锁,谁先来,那么谁可以优先拿到锁
非公平锁是:无论你什么时候来,只要上一个锁释放,剩下的线程都重新竞争
两者相比,非公平锁效率会更高,因为不需要对在等待队列中的线程的优先级进行排序,而非公平锁则有可能导致某一个苦逼的线程永远拿不到锁。。。synchronized是非公平锁。