13-数据采集项目02
一、安装各类软件
创建文件夹
mkdir -p /opt/installs
mkdir -p /opt/modules
mkdir -p /opt/scripts上传文件:

1、jdk的安装
步骤:解压,修改jdk名字,配置环境变量,source 一下即可
今天学习一个jdk的自动化安装脚本。(Shell脚本)
将所有的脚本都放入到这个/opt/scripts下面
创建install_jdk.sh
#!/bin/bash
APP_PREFIX=/opt/installs
APP_PATH=${APP_PREFIX}/jdk
TAR_PATH=/opt/modules/jdk-8u171-linux-x64.tar.gz
ETC_PROFILE=/etc/profile
usage() {
echo "请确保${TAR_PATH}包含了指定的文件!!!"
}
# 校验安装包是否存在
if [ ! -e ${TAR_PATH} ]; then
usage
exit 0
fi
# 判断如果已经安装,则无需再次安装
if [ -e ${APP_PATH} ]; then
echo "${APP_PATH}已存在,APP已经安装,无需重复安装!!!"
exit 0
fi
# 判断安装路径是否存在
if [ ! -e ${APP_PREFIX} ]; then
mkdir -p ${APP_PREFIX}
echo "创建目录:${APP_PREFIX}"
fi
# 解压安装
tar -zxvf ${TAR_PATH} -C ${APP_PREFIX}
cd ${APP_PREFIX}
mv jdk1.8.0_171 jdk
# 配置环境变量
cat << EOF >> ${ETC_PROFILE}
export JAVA_HOME=${APP_PATH}
export PATH='$PATH':${APP_PATH}/bin
EOF
source ${ETC_PROFILE}
java -version
# 提示安装成功
echo "install jdk has successed"一定要注意字符集的问题,在linux中创建,在linux中编辑,就不会出现问题了。
if [ ! -e ${TAR_PATH} ];
-e 后面跟上文件路径,如果 filename存在,则为真
cat << EOF
其中EOF表示文件结束符号,可以是其他的表示,比如ABC都可以,EOF的意思是End Of File的意思
>> 表示追加
比如:
这里写一个A.sh脚本如下:
#!/bin/bash
cat > kube.txt <2、mysql安装
mysql的安装有哪些方式:
1、yum源安装 其实本质上还是rpm ,原因是先帮你下载rpm然后再帮你安装
2、rpm安装包安装
3、可以使用今天的方式安装(也属于yum源安装的一种)
这个软件mysql80-community-release-el7-4.noarch.rpm,它不是一个安装包,而已是一个引导包
cd /opt/modules
yum install -y wget
wget https://dev.mysql.com/get/mysql80-community-release-el7-4.noarch.rpm
# yum install -y mysql80-community-release-el7-4.noarch.rpm
yum localinstall -y mysql80-community-release-el7-4.noarch.rpm
##1.2 安装mysql
yum install -y mysql-community-server
如果报错:
源 "MySQL 8.0 Community Server" 的 GPG 密钥已安装,但是不适用于此软件包。请检查源的公钥 URL 是否配置正确。
失败的软件包是:mysql-community-client-8.0.28-1.el7.x86_64
GPG 密钥配置为:file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
执行如下:
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
并且再次安装:yum install -y mysql-community-server
##1.3 启动mysql服务
[root@hadoop yum.repos.d]# systemctl start mysqld
##1.4 查看初始root密码
[root@hadoop yum.repos.d]# grep 'temporary password' /var/log/mysqld.log
##1.5 登陆mysql
[root@hadoop yum.repos.d]# mysql -uroot -p
修改密码:
alter user root@localhost identified by 'Y1h2e3d4u5!';
set global validate_password.policy=LOW;
set global validate_password.length=4;
set global validate_password.mixed_case_count=0;
set global validate_password.number_count=0;
set global validate_password.special_char_count=0;
# 2. 修改密码
alter user root@localhost identified by '123456';
##1.6 远程授权
create user 'root'@'%' identified by '123456';
grant all privileges on *.* to 'root'@'%' with grant option;
flush privileges;
以下这个如果不使用navicat 可以不执行。
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
##1.8 重启mysql的服务
service mysqld restart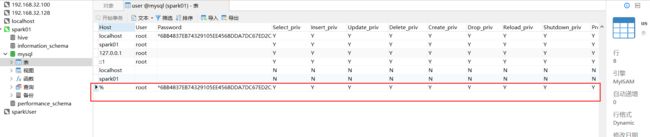
3、hadoop的安装
编写一个脚本,自动化安装hadoop
install_hadoop.sh
先解压,配置环境变量,修改配置文件
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
hadoop-env.sh
worker#!/bin/bash
APP_PREFIX=/opt/installs
APP_PATH=${APP_PREFIX}/hadoop
TAR_PATH=/opt/modules/hadoop-3.3.1.tar.gz
ETC_PROFILE=/etc/profile
usage() {
echo "请确保${TAR_PATH}包含了指定的文件!!!"
}
# 校验安装包是否存在
if [ ! -e ${TAR_PATH} ]; then
usage
exit 0
fi
# 判断如果已经安装,则无需再次安装
if [ -e ${APP_PATH} ]; then
echo "${APP_PATH}已存在,APP已经安装,无需重复安装!!!"
exit 0
fi
# 判断安装路径是否存在
if [ ! -e ${APP_PREFIX} ]; then
mkdir -p ${APP_PREFIX}
echo "创建目录:${APP_PREFIX}"
fi
# 解压安装
tar -zxvf ${TAR_PATH} -C ${APP_PREFIX}
cd ${APP_PREFIX}
mv hadoop-3.3.1 hadoop
# 配置环境变量
cat << EOF >> ${ETC_PROFILE}
export HADOOP_HOME=${APP_PATH}
export PATH='$PATH':${APP_PATH}/bin:${APP_PATH}/sbin
EOF
source ${ETC_PROFILE}
## hadoop-env.sh
cat << EOF >> ${APP_PATH}/etc/hadoop/hadoop-env.sh
export JAVA_HOME=${APP_PREFIX}/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
EOF
## core-site.xml
cat << EOF > ${APP_PATH}/etc/hadoop/core-site.xml
fs.defaultFS
hdfs://caiji:9820
hadoop.tmp.dir
/opt/installs/hadoop/tmp
EOF
## hdfs-site.xml
cat << EOF > ${APP_PATH}/etc/hadoop/hdfs-site.xml
dfs.replication
1
dfs.namenode.secondary.http-address
caiji:9868
dfs.namenode.http-address
caiji:9870
EOF
## yarn-site.xml
cat << EOF > ${APP_PATH}/etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostname
caiji
yarn.nodemanager.aux-services
mapreduce_shuffle
EOF
## mapred-site.xml
cat << EOF > ${APP_PATH}/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
EOF
## workers
cat << EOF > ${APP_PATH}/etc/hadoop/workers
caiji
EOF
## 格式化
${APP_PATH}/bin/hdfs namenode -format
# 提示安装成功
echo "install hadoop has successed"免密登录:两台电脑之间的免密
ssh-keygen -t rsa
ssh-copy-id caijisource /etc/profile
hadoop version
启动集群: start-all.sh
单个开启命令如下:
start-dfs.sh
start-yarn.shjps
在 jdk下面的bin路径下,环境变量正确,是没有问题的,真不行就做个软连接
ln -s /opt/installs/jdk/bin/java /usr/bin/java
4、hive的安装
hive的元数据放在mysql中,所以需要先安装mysql
正常的步骤:
1、解压 2、环境变量 3、hive-site.xml (连接mysql的元数据,开启远程服务) 4、启动测试
1、解压并安装
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/installs/
cd /opt/installs/
mv apache-hive-3.1.2-bin hive
2、修改环境变量:
export HIVE_HOME=/opt/installs/hive
export PATH=$PATH:$HIVE_HOME/bin:
source /etc/profile
3、配置hive-site.xml
先在conf 文件夹下创建一个新的文件 hive-site.xml
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
javax.jdo.option.ConnectionURL
jdbc:mysql://192.168.52.129:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.cj.jdbc.Driver
hive.exec.scratchdir
hdfs://caiji:9820/user/hive/tmp
hive.metastore.warehouse.dir
hdfs://caiji:9820/user/hive/warehouse
hive.querylog.location
hdfs://caiji:9820/user/hive/log
hive.server2.thrift.port
10000
hive.server2.thrift.bind.host
caiji
hive.metastore.uris
thrift://caiji:9083
在启动之前先将mysql的驱动包,拷贝到hive 的lib 目录下
cp /opt/modules/mysql-connector-java-8.0.26.jar /opt/installs/hive/lib/
第一次的时候,需要初始化一下数据库:
schematool -dbType mysql -initSchema
启动: hive
show databases;
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
5、先启动metastore
hive --service metastore &
nohup hive --service metastore 2>&1 >/dev/null &
6、hive
进入hive后,测试一下:
show databases;
metastore 是一个什么样的服务? Hive这个服务是既当客户端也当服务器端。
答:是一个管理hive元数据的服务。
以前: hive --> mysql (hive 连接mysql不是不用metastore 而是默认底层启动了一个)
现在 hive --> metatore --> mysql
metastore 启动一个,其他的客户端都不需要启动metastore了,大大节约了资源。
hiveserver2 是一个远程连接工具
beeline --> hiveserver2 --> mysql
现在的方式是:
beeline --> hiveserver2 --> metatore --> mysql
hiveserver2 需要远程连接的时候才启动。
启动hiveserver2的命令:
hive --service metastore &5、flume的安装
解压
tar -zxvf /opt/modules/apache-flume-1.9.0-bin.tar.gz -C /opt/installs/
mv apache-flume-1.9.0-bin/ flume
配置环境变量:
export FLUME_HOME=/opt/installs/flume
export PATH=$PATH:$FLUME_HOME/bin
source /etc/profile
在conf 文件夹下,有一个 flume-env.sh.template
改名: mv flume-env.sh.template flume-env.sh
修改这个文件中的JAVA_HOME
export JAVA_HOME = /opt/installs/jdk
测试一下: flume-ng version6、sqoop的安装
解压:
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt/installs/
修改名称:
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop
修改配置文件:conf
mv sqoop-env-template.sh sqoop-env.sh
修改里面的内容:
export HADOOP_COMMON_HOME=/opt/installs/hadoop
export HADOOP_MAPRED_HOME=/opt/installs/hadoop
export HIVE_HOME=/opt/installs/hive
export HCAT_HOME=/opt/installs/hive/hcatalog
环境变量
export SQOOP_HOME=/opt/installs/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
source /etc/profile
测试:
sqoop version二、通过脚本实现采集日志的滚动
1、编写一个脚本(可以将一个文件拷贝,并且重命名,产生新的文件)
采集的日志在collect-app-access.log 这个文件如果不管它,它会一直变大,并且它在使用过程中,是无法进行分析的。
可以采用一个定时器,每隔一段时间,将日志停止,产生一个新的日志继续存储。
这个时候就可以源源不断的产生新的log,从而可以进行分析。
假如现在需要编写一个脚本:
需要干什么事儿?
需要知道日志的地址 /opt/apps/collect-app/logs/collect-app-access.log
还需要知道:切完之后,日志存储在哪里 /opt/apps/collect-app/datas
还需要知道nginx.pid 文件存储在哪里? 因为我想把Nginx停止下来(不需要真的停下来),并且重新生成新的collect-app-access.log
cat nginx.pid 这个的位置在:/opt/apps/collect-app/logs/nginx.pid
存储的就是master的进程号,干掉master就是干掉Nginx
date +"%s" 中间是有空格的
得到的是时间戳
mkdir -p /opt/apps/collect-app/datassplit_logs.sh
#!/bin/bash
log_file=/opt/apps/collect-app/logs/collect-app-access.log
data_file=/opt/apps/collect-app/datas
pid_file=/opt/apps/collect-app/logs/nginx.pid
# 如何判断一个文件中是否有数据:可以查看行数,可以查看第一行的内容或者最后一行的内容
line=`tail -n 1 ${log_file}`
# 假如日志文件是空的,就不切了。
if [ ! "${line}" ]; then
echo "warning:${log_file} file no data, don's split !!!"
exit -1
fi
mv ${log_file} ${data_file}/collect-app-access.$(date +"%s").log
kill -USR1 `cat ${pid_file}`
1.kill命令中.9也是信号量,表示为强制终止进程.发送其他信号量可以与进程进行沟通(沟通怎么死.....)
2.USR1信号量被nginx定义,为重新打开日志;当kill命令发送USR1时,nginx会重新打开日志文件,并重新创建进程;
面试:写剧本的。常见的linux命令有哪些?
nohup 查看磁盘空间 内存使用情况等
查看某个文件的行数:
wc -l /opt/apps/collect-app/logs/collect-app-access.log | awk '{print $1}'查看结果,发现以前的日志,确实被移动到了datas文件夹下,而且重新生成了新的日志文件,但是不会自动移动到datas,每次想切割文件都需要手动执行split_logs.sh
2、编写定时任务,执行这个脚本
想要定时执行可以采用如下解决方案:
1、linux的定时任务
2、shell脚本中添加sleep
3、使用azkaban 做定时
4、使用ds 做定时
5、使用java代码做定时任务
......一个脚本如何定时执行。Linux本身就自带了一个定时任务Crontab
复习一下crontab
采用的是Linux字段的定时任务:
crontab -e
编写定时任务的命令
补充:
crontab -r 删除定时任务
crontab -l 展示所有的定时任务
crontab collect-app.cron 添加定时任务 这种方式跟 crontab -e 添加的是一个效果如果没有定时任务功能,可以安装:
yum install crontabs
systemctl start crond # 启动服务
systemctl stop crond # 停止服务
systemctl restart crond # 重启服务
systemctl reload crond # 重载配置文件
systemctl status crond # 查看状态通过这个文件可以查看格式提醒:
cat /etc/crontab

定时任务:
crontab -l # 显示crontab文件(显示已设置的定时任务)
crontab -e # 编辑crontab文件(编辑定时任务)
crontab -r # 删除crontab文件(删除定时任务)crontab -e
*/1 * * * * echo "Good Moring" >> /home/test.txt
每隔一分钟,在/home/test.txt 中,追加一条记录 "Good Moring"定时任务的语法格式:
格式如下:
* * * * * user-name command to be executed
共有六部分组成,分别表示: 分 时 ⽇ ⽉ 星期 要运⾏的命令 解析:
minute: ⼀⼩时中的哪⼀分钟 [0~59]
hour: ⼀天中的哪个⼩时 [0~23]
day: ⼀⽉中的哪⼀天 [1~31]
month: ⼀年中的哪⼀⽉ [1~12]
week: ⼀周中的哪⼀天 [0~6] 星期日是1 ,星期6 是 7
commands: 执⾏的命令
1、执行的命令是否可以执行 ntpdate
2、可执行的脚本你是否赋予了权限 比如自定义的脚本需要赋予权限才能运行
3、*/num 表示频率
4、如果是相连的时间使用 - 比如,周一到周五 1-5
如果时间不是相邻的,使用逗号(,)即可。 比如 8,10,12开始创建我的日志采集:
crontab -e
*/1 * * * * sh /opt/scripts/split_logs.sh
保存退出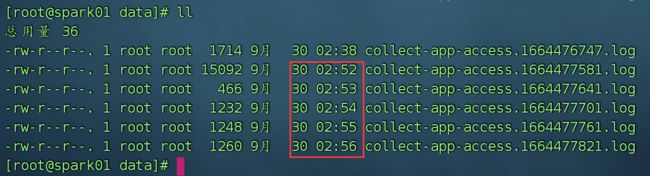
因为以上这种方案所有的定时任务都在一个文件中,不是特别的方便。
##1. 创建定时调度脚本
collect_app.cron
里面编辑如下命令:
*/5 * * * * sh /opt/scripts/split_logs.sh
##2. 启动定时器
[root@hadoop scripts]# crontab collect_app.cron
[root@hadoop scripts]# crontab -l3、查看另一个更加灵活的脚本
需要学习一个新的内容 :getopts
举例说明:testgetopts.sh
./testgetopts.sh -b 100
假如你想给一个shell传递参数的话, hello.sh a b c
此时的a b c 都是 hello.sh 的参数,可以通过$1 $2 $3 获取到
现在假如你想编写这个命令 hello.sh -id 1 -age 20 -name zhangsan
通过第二种方式传递参数,貌似比第一种更加的便于阅读
#!/bin/bash
while getopts ':b:d:' OPT &>/dev/null
do
case $OPT in
b)
echo "option is b"
echo "${OPTARG}"
;;
d)
echo "option is d"
echo "${OPTARG}"
;;
*)
echo "option is not exists"
;;
esac
done#!/bin/sh
while getopts :ab:c: OPTION;do
case $OPTION in
a)echo "get option a"
;;
b)echo "get option b and parameter is $OPTARG"
;;
c)echo "get option c and parameter is $OPTARG"
;;
?)echo "get a non option $OPTARG and OPTION is $OPTION"
;;
esac
done
测试:
sh a.sh -a 100关于 /dev/null 的解释,可以参考下面这个文章:
百度安全验证
echo "hello" >>/dev/null
cat /dev/null
yan 2>/dev/null 将错误输出到黑洞中测试:
sh testgetopts.sh -d 123
-d 就传递给 OPT
123 就传递给了 ${OPTARG} 固定的#!/bin/bash
# filename:split-access-log.sh
# author:laoyan
# date:2022-06-14
# desc:切割文件,存放到另一个目录中。多用于切割日志
## usage函数:此脚本的使用说明
usage() {
echo "usage:"
echo "split-access-log.sh [-f -d -p -h]"
echo "descripation:"
echo " log_file: nginx's collect-app-access.log file absolute path"
echo " data_file: split file absolute path"
echo " pid_file nginx pid file absolute path"
echo "warning : if no params, use default value!!!"
}
## default函数,作用是给log_file、data_file、pid_file赋予默认的初始值
default() {
echo "use defaut value:"
echo " log_file=/opt/apps/collect-app/logs/collect-app-access.log"
echo " data_file=/opt/apps/collect-app/data"
echo " pid_file=/opt/apps/collect-app/logs"
log_file=/opt/apps/collect-app/logs/collect-app-access.log
data_file=/opt/apps/collect-app/data
pid_file=/opt/apps/collect-app/logs/nginx.pid
}
## 控制选项(option)参数
while getopts 'f:d:p:h' OPT &>/dev/null
do
case $OPT in
f) log_file="${OPTARG}" ;;
d) data_file="${OPTARG}" ;;
p) pid_file="${OPTARG}" ;;
h) usage
exit -1 ;;
*) usage
exit -1 ;;
esac
done
## 控制使用脚本的时候别人不输入参数
if [ $# -eq 0 ]; then
default
fi
## 控制参数要么全部都输入,要么全部都不输入
if [ ! "${log_file}" ] || [ ! "${data_file}" ] || [ ! "${pid_file}" ]; then
echo "some params is empty, please try again!!!"
usage
exit -1
fi
## 切割之前,判断目标的日志文件是否有数据,如果他没有数据就没有必要切割
line=`tail -n 1 ${log_file}`
if [ ! "${line}" ]; then
echo "warning:${log_file} file no data, don's split !!!"
exit -1
fi
## 切割
mv ${log_file} ${data_file}/collect-app-access.$(date +"%s").log
## 重新生成日志文件:采取重置nginx进程的方式,自动生成collect-app-access.log
kill -USR1 `cat ${pid_file}`
## 提示结果
echo "info:finished" 使用方法是这样的:
sh split-access-log.sh -f /opt/apps/collect-app/logs/collect-app-access.log -d /opt/apps/collect-app/datas -p /opt/apps/collect-app/logs/nginx.pid
也可以使用 sh split-access-log.sh -h 查看帮助文档
sh split-access-log.sh 直接运行,使用的是默认值
也可以这样用,但是脚本中要使用 $1 $2 $3来获取值
sh split-access-log.sh /opt/apps/collect-app/logs/collect-app-access.log /opt/apps/collect-app/datas /opt/apps/collect-app/logs/nginx.pid三、如果使用beeline连接hive失败
启动hiveserver2失败,按照如下方式修改。
查看日志:/tmp/root/hive.log
Caused by: MetaException(message:User root is not allowed to perform this API call)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.authorizeProxyPrivilege(HiveMetaStore.java:7517)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.get_current_notificationEventId(HiveMetaStore.java:7477)
... 20 more在hadoop的core-site.xml 中,添加如下配置:
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
hadoop.proxyuser.root.users
*
然后重启hadoop集群。
重启metastore
hive --service metastore &
重启hiveserver2服务
hive --service hiveserver2 &
使用beeline连接:
!connect jdbc:hive2://caiji:10000
用户名 root 密码 123456
也可以使用如下方式连接:
beeline -u jdbc:hive2://caiji:10000 -n root
补充一点小知识
1、grep -v
查找文件中包含某个字符串的内容。
grep hello a.txt
grep -v hello a.txt 取反grep name# 表示只查看包含name这个关键字的行内容
grep -v name # 表示查看除了含有name之外的行内容
比如:
ps axu|grep nginx|grep -v grep
ps -ef|grep nginx | grep -v grep
这个命令结果没有红色
下面这个命令结果保留红色:
ps -ef | grep -v grep|grep nginx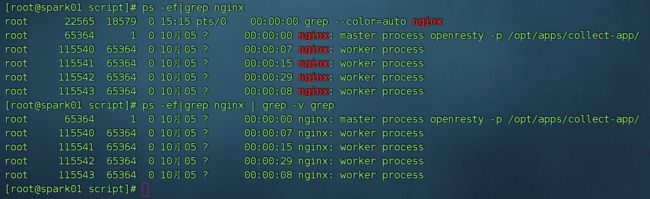
grep 是shell脚本三剑客之一: awk sed grep
2、ps aux
-ef
ps -e 此参数的效果和指定"A"参数相同
ps -A 显示所有程序
ps -f 下面是 man 的结果
does full-format listing. This option can be combined with many other UNIX-style options to add additional columns. It also causes the command arguments to be printed. When used with -L, the NLWP (number of threads) and LWP (thread ID) columns will be added. See the c option, the format keyword args, and the format keyword comm.
所以,ps -ef 也是打印所有进程。aux:
ps a 显示现行终端机下的所有程序,包括其他用户的程序
ps u 以用户为主的格式来显示程序状况
ps x 显示所有程序,不以终端机来区分。
所以,ps aux就是打印所有进程。ps -ef
ps aux 都可以查看进行
一般不会单独使用,而是跟grep 一起使用,查找某个带有某个关键字的进行
ps -ef | grep nginx
不能查看端口号,跟这个命令特别像的jps (只能查看java进程的应用)netstat
-a 显示所有网络连接和监听的所有端口。
-b 显示创建每个连接或者监听商品的相关可执行程序。有时候有些已知的可执行程序拥有多个独立组件,在这种情况下会按一定顺序显示创建连接或者端口的组件。netstat会将可执行程序的名称显示在底下的方括号[]中,而顶部显示的是其调用的组件,只有在TCP/IP连接上后才会继续继续下一步。注意这种操作可能很耗时且在你没有足够权限的情况下可能会失败(笔者注:所以最好以管理员权限执行该命令)。
-e 显示以太网统计数据。这个参数往往与-s组合使用。
-f 显示外部地址的FQDN名称(完全限定域名)。
-n 以数字形式显示地址和端口。
-o 显示每个连接相关的所属进程的ID。
-p proto 显示通过proto值指定的协议的连接;proto可以是下列中的任一个:TCP、UDP、TCPv6、UDP或者UDPv6。如果使用-s选项来显示每个协议的统计数据,proto可以是以下的任意一个:IP、IPv6、ICMP、ICMPv6、TCP、TCPv6、UDP或UDPv6。
-q 显示所有的连接、监听端口及绑定非监听TCP端口。绑定非监听端口可能有或者没有与一个活动连接相关联。
-r 显示路由表。(笔者注:跟route print命令一样的效果。)
s 显示每个协议的统计数据。默认情况下,统计数据显示如下协议:IP、IPv6、ICMP、ICMPv6、TCP、TCPv6、UDP和UDPv6;-p选项可以用来指定一个上述协议的子集。(笔者注:就是用户可以通过-p选项来指定只显示哪个的意思。)
-t 显示当前连接的卸载状态。(笔者注:卸载状态是指的TCP Chimney Offload,这是一种网络技术,它可以帮助在网络数据传输期间将工作负载从CPU传输到网络适配器。)
-x 显示NetworkDirect连接、监听器和共享终端。
-y 显示所有连接的TCP连接模板。此选项不能与其它选项组合使用。
可以通过这个命令查看端口形式的应用。
netstat -nltpo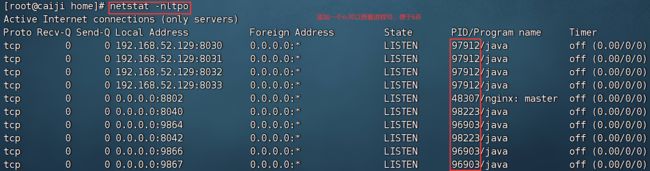
二、将切割的文件上传至hdfs
使用flume进行采集
准备工作:
1、nginx是否启动
ps -ef| grep nginx | grep -v grep
如果没有启动:
openresty -p /opt/apps/collect-app/
查看nginx文件是否有错误:
openresty -p /opt/apps/collect-app/ -t
2、frpc 这个内网穿透工具是否启动:
frpc http --sd xiongda -l 8802 -s frp.qfbigdata.com:7001 -u xiongda
定时任务是否启动,是否成功切割文件
3、crontab -e 中添加如下定时任务
*/1 * * * * sh /opt/scripts/split_logs.sh
4、同步时间
查看 /opt/apps/collect-app/logs 文件夹中的文件是否发生变化使用flume进行文件的采集:
flume 又分为 source sink channel
source --> spooling directory
channel --> memory
sink --> hdfs 文件的特点:1、不断的产生新的文件 2、要将其采集到hdfs
Flume 1.9用户手册中文版 — 可能是目前翻译最完整的版本了
在 flume中的conf文件夹下,创建一个文件
确定:
sources 使用 Spooling Directory Source 可以采集一个文件夹,文件夹中的文件只要有新的文件产生就采集
collect-app-agent.conf
a1.channels = ch-1
a1.sources = src-1
a1.sources.src-1.type = spooldir
a1.sources.src-1.channels = ch-1
a1.sources.src-1.spoolDir = /opt/apps/collect-app/datas
a1.sources.src-1.fileHeader = true
a1.sources.src-1.includePattern = ^collect-app-access.*.log
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = ch-1
a1.sinks.k1.hdfs.path = hdfs://caiji:9820/sources/news/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = news-%Y%m%d_%H
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.fileSuffix = .gz
a1.sinks.k1.hdfs.codeC = gzip
a1.sinks.k1.hdfs.useLocalTimeStamp = true
## 目录滚动
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 24
a1.sinks.k1.hdfs.roundUnit = hour
## 文件滚动
a1.sinks.k1.hdfs.rollInterval = 600
a1.sinks.k1.hdfs.rollSize = 1048576
a1.sinks.k1.hdfs.rollCount = 0采集日志:在flume的job文件夹下
flume-ng agent -n a1 -c ../conf/ -f collect-app-agent.conf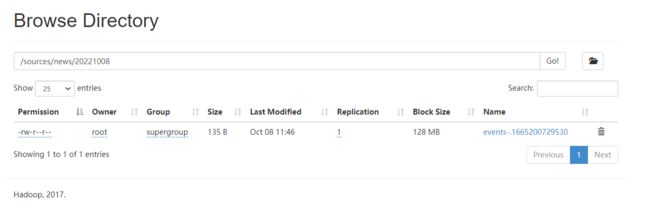
如果在线查看文件数据报如下错误:

修改hadoop下的hdfs-site.xml,重新启动 hdfs
dfs.webhdfs.enabled
true
dfs.permissions
false
第二步,配置windows本地的hosts文件:
C:\Windows\System32\drivers\etc
192.168.233.131 caiji查看上传的脚本内容:
hdfs dfs -cat /sources/news/20230913/news-20230913_00.1694589918847.gz.tmp | gzip -d在采集的过程中,不要随意停止集群,否则压缩包中的数据会异常。
以上可以写为一个脚本:
flume-agent.sh start | stop
#!/bin/bash
FLUME_HOME=/opt/installs/flume
usage() {
echo "usage:"
echo "flume-agent.sh start | stop"
echo "descripation:"
echo " start: start flume agent"
echo " stop: stop flume agent"
}
CMD=$1
if [ ${CMD} == "start" ]; then
nohup ${FLUME_HOME}/bin/flume-ng agent -n a1 -c ${FLUME_HOME}/conf -f ${FLUME_HOME}/job/collect-app-agent.conf >> /opt/apps/collect-app/logs/a1-flume-agent.log 2>&1 &
elif [ ${CMD} == "stop" ]; then
ps -aux | grep flume | grep collect-app-agent.conf | gawk '{print $2}' | xargs -n1 kill -9
else
usage
filinux脚本三剑客 grep sed awk
以上的脚本中也可以使用如下命令杀死flume进程
kill -9 `ps -ef|grep collect-app-agent.conf | grep -v grep | gawk '{print $2}'`xargs 是一个强有力的命令,它能够捕获一个命令的输出,然后传递给另外一个命令。
之所以能用到这个命令,关键是由于很多命令不支持|管道来传递参数,而日常工作中有有这个必要,所以就有了 xargs 命令
xargs 用作替换工具,读取输入数据重新格式化后输出。
-n num 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。nohup 的用法:
linux后台执行命令:&与nohup的用法 - 知乎
&
后台运行程序的意思。但是日志输出还是在前端控制台
./test >> out.txt 2>&1 &
运行test这个脚本,日志输出到 out.txt 文件中
2>&1是指将标准错误重定向到标准输出,于是标准错误和标准输出都重定向到指定的out.txt文件中
在命令的末尾加个&符号后,程序可以在后台运行,但是一旦当前终端关闭(即退出当前帐户),该程序就会停止运行。
可以使用nohup命令。nohup就是不挂起的意思( no hang up)
nohup ./test >> out.txt 2>&1 &如果遇到:
SEQ!org.apache.hadoop.io.LongWritable"org.apache.hadoop.io.BytesWritabl
解决方案是:
添加
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.fileSuffix = .gz
a1.sinks.k1.hdfs.codeC = gzip三、将加密数据解密并自定义格式
问题答疑:
![]()

采集到hdfs上的数据,长这个样子
eyJjdGltZSI6MTY1NTExMDc2Mjk1MCwicHJvamVjdCI6Im5ld3MiLCJpcCI6IjM5LjEwNy45Ny4xNTQifQ==-eyJjb250ZW50Ijp7InV1aWQiOiJhZWZjZDFlNy1mOGZlLTQzMDktOTY2ZC02ZTI0MTk1ZWEwMDIiLCJkaXN0aW5jdF9pZCI6IjAiLCJwcm9wZXJ0aWVzIjp7Im1vYmlsZSI6Ijg2IDEzNjQ4NTI4MTMwIiwiZW1haWwiOiJUcmlzaGEuWmVtbGFrMjgxNUBxcS5jb20iLCJuaWNrX25hbWUiOiJSb3dsYW5kIE11cnJheVlvc3QtMDIyOSIsIm5hbWUiOiLpg73lro/nlYUiLCJnZW5kZXIiOiLlpbMiLCJhZ2UiOiI5NCIsInNpZ251cF90aW1lIjoxNjU1MTEwNzQyMDAwfSwidHlwZSI6InByb2ZpbGVfc2V0In19因为我们需要将这个数据进行分析的,需要映射到hive表中,密文显然不行。需要明文
# 原始日志格式
eyJwcm9qZWN0IjoibmV3cyIsImN0aW1lIjoxNjk0NTg5ODg0ODY3LCJpcCI6IjM5LjEwNy45Ny4xNTQifQ==-eyJjb250ZW50Ijp7InV1aWQiOiJhNzNmOWFjMi1jNmVlLTRmN2ItYWQ4NS05OGNjMDgxMjE2YjQiLCJkaXN0aW5jdF9pZCI6IjI2ODAiLCJwcm9wZXJ0aWVzIjp7Im1vYmlsZSI6Ijg2IDE4NzUxMDEwNTg3IiwiZW1haWwiOiJJbW9nZW5lLldpc29reTI5MjdAMTIzLmNvbSIsIm5pY2tfbmFtZSI6IkNvbnN0YW5jZSBTYXdheW5PbmRyaWNrYS0yMzg1IiwibmFtZSI6Iuavlea5m+iLsSIsImdlbmRlciI6IuWlsyIsImFnZSI6Ijg1Iiwic2lnbnVwX3RpbWUiOjE2OTQ1ODk4NDQwMDB9LCJ0eXBlIjoicHJvZmlsZV9zZXQifX0=
# 解析
echo "eyJwcm9qZWN0IjoibmV3cyIsImN0aW1lIjoxNjk0NTg5ODg0ODY3LCJpcCI6IjM5LjEwNy45Ny4xNTQifQ=="|base64 -d
echo "eyJjb250ZW50Ijp7InV1aWQiOiJhNzNmOWFjMi1jNmVlLTRmN2ItYWQ4NS05OGNjMDgxMjE2YjQiLCJkaXN0aW5jdF9pZCI6IjI2ODAiLCJwcm9wZXJ0aWVzIjp7Im1vYmlsZSI6Ijg2IDE4NzUxMDEwNTg3IiwiZW1haWwiOiJJbW9nZW5lLldpc29reTI5MjdAMTIzLmNvbSIsIm5pY2tfbmFtZSI6IkNvbnN0YW5jZSBTYXdheW5PbmRyaWNrYS0yMzg1IiwibmFtZSI6Iuavlea5m+iLsSIsImdlbmRlciI6IuWlsyIsImFnZSI6Ijg1Iiwic2lnbnVwX3RpbWUiOjE2OTQ1ODk4NDQwMDB9LCJ0eXBlIjoicHJvZmlsZV9zZXQifX0=" |base64 -d
# 解析结果
{
content: {
uuid: "a73f9ac2-c6ee-4f7b-ad85-98cc081216b4",
distinct_id: "2680",
properties: {
mobile: "86 18751010587",
email: "[email protected]",
nick_name: "Constance SawaynOndricka-2385",
name: "毕湛英",
gender: "女",
age: "85",
signup_time: 1694589844000
},
type: "profile_set"
}
}
{"project":"news","ip":"127.0.0.1","ctime":1589781236541}
# 通过flume拦截器解析结果 目标
{
"ctime": 1589781236541,
"project": "news",
"content": {
"distinct_id": "51818968",
"event": "AppClick",
"properties": {
"element_page": "新闻列表页",
"screen_width": "640",
"app_version": "1.0",
"os": "GNU/Linux",
"battery_level": "11",
"device_id": "886113235750",
"client_time": "2020-05-18 13:53:56",
"ip": "61.233.88.41",
"is_charging": "1",
"manufacturer": "Apple",
"carrier": "中国电信",
"screen_height": "320",
"imei": "886113235750",
"model": "",
"network_type": "WIFI",
"element_name": "tag"
}
}
}需要使用拦截器(Flume的)
将切割好的文件,上传至hdfs,并且解密。
导入包(pom.xml):
4.0.0
com.bigdata
MyInterceptor
1.0-SNAPSHOT
jar
8
8
org.apache.flume
flume-ng-core
1.9.0
com.alibaba
fastjson
1.2.48
org.apache.maven.plugins
maven-shade-plugin
3.1.1
false
package
shade
com.google.protobuf
shaded.com.google.protobuf
log4j:*
*:*
META-INF/*.SF
reference.conf
mainclass
编写代码:
package com.bigdata;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.codec.binary.Base64;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import org.jboss.netty.handler.codec.base64.Base64Encoder;
import java.text.SimpleDateFormat;
import java.util.List;
public class NewsInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 解析 文本数据变为另一种格式
byte[] body = event.getBody();
String content = new String(body);
String[] split = content.split("-");
if(split.length == 2){
// 将密文切割
String header = split[0];
String neirong = split[1];
// 将两段密文解析
String mingHeader = new String(Base64.decodeBase64(header));
String mingNeirong = new String(Base64.decodeBase64(neirong));
// 将明文json进行解析
// {"project":"news","ip":"127.0.0.1","ctime":1589781236541}
JSONObject jsonObject = JSON.parseObject(mingHeader);
String project = jsonObject.getString("project");
String ip = jsonObject.getString("ip");
String ctime = jsonObject.getString("ctime");
/**
* {
* content: {
* uuid: "a73f9ac2-c6ee-4f7b-ad85-98cc081216b4",
* distinct_id: "2680",
* properties: {
* mobile: "86 18751010587",
* email: "[email protected]",
* nick_name: "Constance SawaynOndricka-2385",
* name: "毕湛英",
* gender: "女",
* age: "85",
* signup_time: 1694589844000
* },
* type: "profile_set"
* }
* }
*/
JSONObject jsonObject2 = JSON.parseObject(mingNeirong);
// json字符串,不是json对象
String contentJson = jsonObject2.getString("content");
/**
* 目标:
* {
* "ctime": 1589781236541,
* "project": "news",
* "content": {
* "distinct_id": "51818968",
* "event": "AppClick",
* "properties": {
* "element_page": "新闻列表页",
* "screen_width": "640",
* "app_version": "1.0",
* "os": "GNU/Linux",
* "battery_level": "11",
* "device_id": "886113235750",
* "client_time": "2020-05-18 13:53:56",
* "ip": "61.233.88.41",
* "is_charging": "1",
* "manufacturer": "Apple",
* "carrier": "中国电信",
* "screen_height": "320",
* "imei": "886113235750",
* "model": "",
* "network_type": "WIFI",
* "element_name": "tag"
* }
* }
* }
*/
JSONObject newJson = new JSONObject();
newJson.put("ctime",ctime);
newJson.put("project",project);
// 修改此处的代码
JSONObject contentJsonObj = JSON.parseObject(contentJson);
// newJson.put("content",contentJson);
newJson.put("content",contentJsonObj);
String newBody = newJson.toJSONString();
SimpleDateFormat format = new SimpleDateFormat("yyyyMMdd");
String ctime2 = format.format(Long.parseLong(ctime));
event.getHeaders().put("ctime",ctime2);
event.setBody(newBody.getBytes());
}
return event;
}
@Override
public List intercept(List list) {
for (int i = 0; i < list.size(); i++) {
Event oldEvent = list.get(i);
Event newEvent = intercept(oldEvent);
list.set(i,newEvent);
}
return list;
}
@Override
public void close() {
}
// 作用只有一个,就是new 一个自定义拦截器的类
public static class BuilderEvent implements Builder{
@Override
public Interceptor build() {
return new NewsInterceptor();
}
@Override
public void configure(Context context) {
}
}
} 接着在flume下面创建文件夹:
可以放在这个地方
mkdir -p plugins.d/interceptor/lib
也可以放在 flume的/lib 下
我们是放在了flume安装路径下的lib下:
编写完代码,配置文件需要注意几个点:
a1.channels = ch-1
a1.sources = src-1
a1.sources.src-1.type = spooldir
a1.sources.src-1.channels = ch-1
a1.sources.src-1.spoolDir = /opt/apps/collect-app/datas
a1.sources.src-1.fileHeader = true
a1.sources.src-1.includePattern = ^collect-app-access.*.log
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
a1.sources.src-1.interceptors = i1
a1.sources.src-1.interceptors.i1.type = com.bigdata.NewsInterceptor$BuilderEvent
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = ch-1
a1.sinks.k1.hdfs.path = hdfs://caiji:9820/sources/news/%{ctime}
a1.sinks.k1.hdfs.filePrefix = news-%Y%m%d_%H
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.fileSuffix = .gz
a1.sinks.k1.hdfs.codeC = gzip
a1.sinks.k1.hdfs.useLocalTimeStamp = true
## 目录滚动
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 24
a1.sinks.k1.hdfs.roundUnit = hour
## 文件滚动
a1.sinks.k1.hdfs.rollInterval = 600
a1.sinks.k1.hdfs.rollSize = 1048576
a1.sinks.k1.hdfs.rollCount = 0重启你的flume:
查看hdfs上的压缩文件:
一定要查看最新的压缩包,老的压缩包的数据还是老的。
hdfs dfs -cat /sources/news/20221008/news-20221008_00.1665215726761.gz.tmp | gzip -d结果就是:
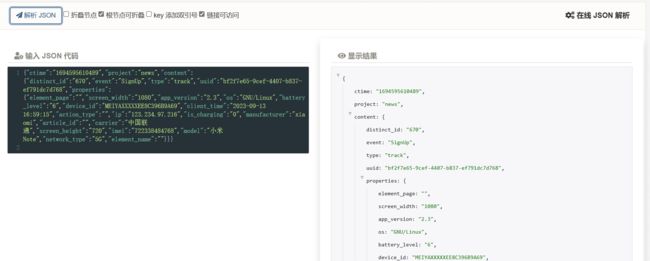
{"ctime":"1694595610489","project":"news","content":{"distinct_id":"670","event":"SignUp","type":"track","uuid":"bf2f7e65-9cef-4407-b837-ef791dc7d768","properties":{"element_page":"","screen_width":"1080","app_version":"2.3","os":"GNU/Linux","battery_level":"6","device_id":"MEIYAXXXXXEE8C396B9A69","client_time":"2023-09-13 16:59:15","action_type":"","ip":"123.234.97.216","is_charging":"0","manufacturer":"xiaomi","article_id":"","carrier":"中国联通","screen_height":"720","imei":"722338484768","model":"小米Note","network_type":"5G","element_name":""}}}
以上格式是对的,以下格式是错误的,需要重新修改代码:
{"ctime":"1694594399765","project":"news","content":"{\"distinct_id\":\"1941\",\"event\":\"AppClick\",\"type\":\"track\",\"uuid\":\"4a51fe58-8f79-4834-b9eb-7c15cddfa99b\",\"properties\":{\"element_page\":\"注册登录页\",\"screen_width\":\"1920\",\"app_version\":\"1.3\",\"os\":\"\",\"battery_level\":\"23\",\"device_id\":\"TAIJIXXXX3CF512F8BDE0\",\"client_time\":\"2023-09-13 16:39:24\",\"action_type\":\"\",\"ip\":\"182.92.174.1\",\"is_charging\":\"\",\"manufacturer\":\"Sumsung\",\"article_id\":\"\",\"carrier\":\"中国移动\",\"screen_height\":\"1152\",\"imei\":\"425843834523\",\"model\":\"Galaxy S6\",\"network_type\":\"\",\"element_name\":\"\"}}"}采集到hdfs上的文件,里面的内容都是解析以后的数据。
解决问题的时候:先停止flume,删除掉hdfs上已经传好的数据,再启动flume,查看是否有数据。
查看数据格式是否正确:在线 JSON 解析 | 菜鸟工具