*HDFS完全分布式集群搭建与配置及常见问题总结*
小组介绍:
哈喽大家好!
我们是---哈了个Doop小组,接下来为大家做一下小组介绍。一共有六个成员。主要特点是由一名男生和五名女生组成,又称为“一汉娘子组”,由无所不能且帅气的文组长带领。成员有:优秀的诺同学和芝同学、有创意的灵同学、两位颜值担当的杰同学和张同学。组员介绍已完毕。
使用电脑时很多朋友会发现一台计算机虽然可以安装多个操作系统,但是对电脑的硬件有着极大的要求,而虚拟机的出现则完美的解决了这个问题,当我们在虚拟机中植入病毒进行测试或者利用漏洞进行攻击时,只会让我们的虚拟机操作系统崩溃,而不会影响物理机。
centOS7是一个开源类服务操作系统,2014年7月7日正式发布,是企业级的Linux发行版本。接下来主要给大家介绍如何搭建可正常使用的centOS7系统虚拟机节点。
一.*HDFS完全分布式集群搭建
1. *检查xshell中的node1 node2 node3是否联网*
代码如下:
ping www.baidu.com


2. *创建安装目录*
在node01里的opt创建softwarew目录
代码如下:
cd /opt
mkdir software
在software目录里创建hadoop目录
代码如下:
cd /software
mkdir hadoop
在hadoop目录里创建hdfs目录
cd /hadoop
mkdir hdfs
![]()
在hdfs目录里创建data name tmp 等三个文件
代码如下:
mkdir data
mkdir name
mkdir tmp

3.进入hadoop目录上安装插件和上传hadoop-2.9.2.tar.gz
进入hdoop目录:cd /opt/software/hadoop
安装插件yum -y install lrzsz上传并解压hadoop-2.9.2.tair.gz:
上传:将hadoop-2.9.2.tar.gz压缩包拖到node01
解压:tar- xvzf hadoop-2.9.2.tair.gz
查询是否解压成功 ll

4.配置环境变量
代码如下
vi /etc/profile
export HADOOP_HOME=/opt/software/hadoop/hadoop - 2.9..2
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin

然后刷新source /etc/profile
检查Hadoop是否安装成功
hadoop version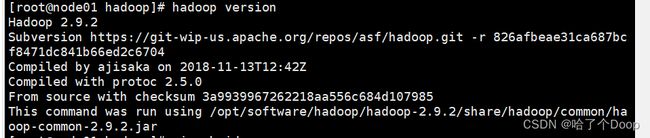
二.配置
1.配置工作
进入cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/ 路径
①修改hadoop-env.sh
vi hadoop-env.sh
修改值如图所示
export JAVA_HOME=/usr/local/java/jdk1.8 export HADOOP_CONF_DIR=/opt/software/hadoop/hadoop-2.9.2/etc/hadoop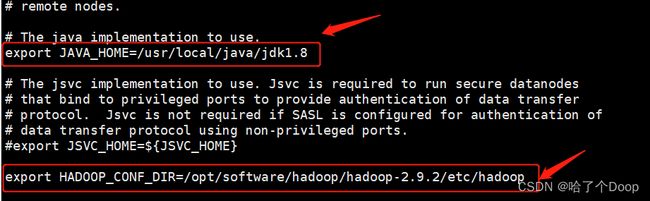
②修改yarn-env.sh
vi yarn-env.sh
如图所示添加配置:export JAVA_HOME=/usr/local/java/jdk1.8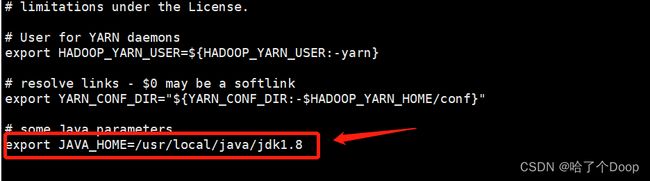
③修改core-site.xml
vi core-site.xml
代码如下:
如图所示: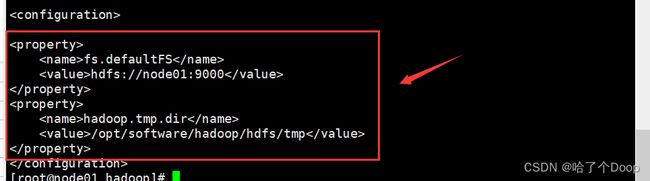
④修改hdfs-site.xml
vi hdfs-site.xml
代码如下:
如图所示:
⑤修改mapred-site.xml
到此路径:cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/
拷贝:cp mapred-site.xml.template mapred-site.xml vi mapred-site.xml
代码如下:
如图所示: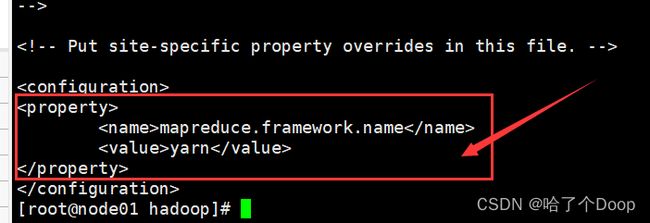
⑥修改 yarn-site.xml
vi yarn-site.xml
代码如下:
如图所示: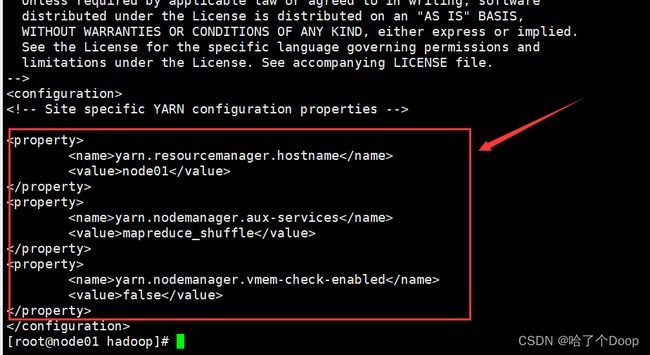
⑦修改slaves
vi slaves
修改主机名localhost为node01 node02 node03 都作为DataNode
如图所示:

2.拷贝到其他两个节点
①在两个节点上创建 /opt/software路径
把node01配置的相关文件拷贝到node02 node03 (均在node01下执行)
拷贝命令如下:
scp -r hadoop/ node02:$PWD scp -r hadoop/ node03:$PWD
②在node02 node03上配置Hadoop的环境变量
vi /etc/profile
代码如下:
export HADOOP_HOME=/opt/software/hadoop/hadoop-2.9.2 export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
3.刷新
source /etc/profile(注意:三台虚拟机必须一起刷新,则后续会出错)
三.启动集群
1.在node01上格式化
代码如下:hdfs namenode -format
2.在node01上启动集群
node02 node03上不用启动
代码如下:start-dfs.sh
启动成功后呈如图所示:

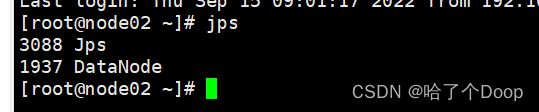

四.常见问题
1.格式化失败——配置代码填写错误
*配置文件时需仔细编写配置代码
2.关机虚拟机重启时务必启动集群,则jps部分不显示
3.nameNode到自身免密登录失败
*文件权限不足
4.NameNode到DataNode免密登陆失败
*文件权限不足
5.Hadoop-env.sh文件出错
6.集群启动失败
五.总结
Hadoop 被称为Google技术的山寨版,因为它是由Google的三大论文作为基础开发出来的,分别是:MapReduce,GFS和BigTable。不过它因是世界上唯一一个做得相对完善而又开源的框架而成为当下大数据处理技术的国际标准。 Hadoop是一个能够对大量数据进行分布式处理的软件框架,Hadoop的序列化数据特点:紧凑 :高效使用存储空间;快速:读写数据的额外开销小;互操作:支持多语言的交互。 Hadoop框架中最核心的设计就是:MapReduce和HDFS。 MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据分析应用”的核心框架。MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop 集群上。 HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。HDFS 的使用场景:适合一次写入(上传),多次读出(下载)的场景。一个文件经过创建、写入和关闭之后就不需要改变文件的内容(只支持文件的内容追加)。 以上是我对Hadoop技术的初步认识,希望这些可以对你有所帮助。