C++泛型编程——模板(初识)
C++泛型编程——模板(初识)
文章目录
- C++泛型编程——模板(初识)
- 1. 泛型编程的概念
- 2. 模板
-
- 2.1 模板格式
- 2.2 函数模板
-
- 2.3 函数模板的实例化
-
- 2.3.1 隐式(推演)实例化
- 2.3.2 显式实例化
- 2.3 类模板
- 3. 模板的本质
本章思维导图:
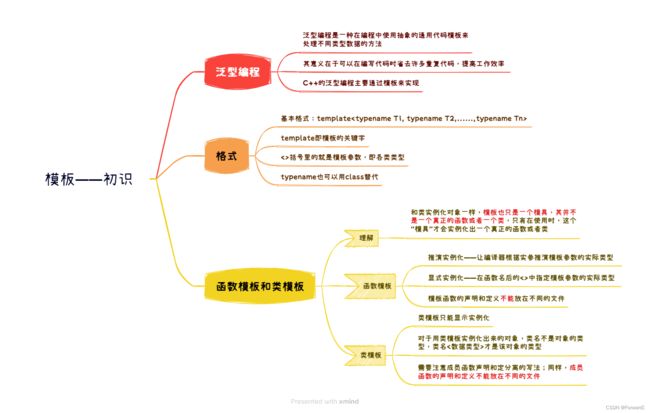 注:本章思维导图对应的
注:本章思维导图对应的 xmind和 .png文件都已同步导入至 资源
1. 泛型编程的概念
在C++中,如果我们不借助库函数,要实现两个数据的交换函数swap,由于要考虑到数据类型的多样性,我们难免要将swap函数重载很多次,例如:
void swap(int& num1, int& num2)
{
int temp = num1;
num1 = num2;
num2 = temp;
}
void swap(char& num1, char& num2)
{
int temp = num1;
num1 = num2;
num2 = temp;
}
k'j
void swap(double& num1, double& num2)
{
int temp = num1;
num1 = num2;
num2 = temp;
}
//…………………………
swap函数的函数体基本相同,只有交换数据的类型不同,但就是由于这个小小的不同迫使我们产生很多冗余代码,使生产效率变得低下
为了解决这一问题,C++就支持了泛型编程这一概念:
允许我们用一个通用的代码模板来处理不同类型数据
在C++中,泛型编程就是靠模板来实现的
2. 模板
2.1 模板格式
基本格式为:
template
template为模板的关键字<>里面的即模板参数,代表一个数据类型typename可以用class替代
2.2 函数模板

基本格式为:
template
返回值类型 函数名(参数列表){}
例如:
//定义一个函数模板swap
//T泛指所有类型
template <typename T>
void swap(T& num1, T& num2)
{
T temp = num1;
num1 = num2;
num2 = temp;
}
注意:
当模板函数的声明和定义不能分布在不同的文件
2.3 函数模板的实例化
用不同的类型使用函数模版生成一个具体的函数这一过程叫做函数模板的实例化,函数模板的实例化有以下两种方法:
2.3.1 隐式(推演)实例化
推演实例化——让编译器根据实参推演模板参数的实际类型
例如:
template <typename T>
void swap(T& num1, T& num2)
{
T temp = num1;
num1 = num2;
num2 = temp;
}
int main()
{
int a = 1, b = 2;
double a1 = 1.0, b1 = 2.0;
swap(a, b); //实例化函数模板为swap(int& num1, int& num2),并进行调用
swap(a1, b1); //实例化函数模板为swap(double& num1, double& num2),并进行调用
return 0;
}
需要注意:
如果该函数模板的模板参数只有一个,那么进行推演实例化时,传入的实参的类型就只能有一个(即模板不允许自动类型转换例如:
template <typename T> void swap(T& num1, T& num2) { T temp = num1; num1 = num2; num2 = temp; } int main() { int a = 1; double b = 2.0; swap(a, b); return 0; } //会报错: // “swap”: 未找到匹配的重载函数 // “void swap(T &,T &)”: 模板 参数“T”不明确为了避免这个问题,一种解决方式就是增多模板参数:
template <typename T1, typename T2> void swap(T1& num1, T2& num2) { T1 temp = num1; num1 = num2; num2 = temp; } int main() { int a = 1; double b = 2.0; swap(a, b); return 0; }一种方法是使用强制类型转换,使传入的类型相同。但这个方法也有一个需要注意的点:如果函数模板的形参为引用类型,但是没有被
const修饰,那么就不能用强制类型转换来实现推演实例化:template <typename T> void swap(T& num1, T& num2) { T temp = num1; num1 = num2; num2 = temp; } int main() { int a = 1; double b = 2.0; swap(a, (int)b); //(int)b涉及数据类型的转换,因此产生了一个临时变量,而临时变量具有常性(const), //被const修饰的引用权限不能被放大,因此无法转换为没有被const修饰的形参T& num return 0; }还有一种常用的方法就是使用显式实例化
2.3.2 显式实例化
显式实例化——在函数名后的<>中指定模板参数的实际类型
注意:使用显式实例化同样需要注意引用权限不能提升的问题
例如:
template <typename T>
T Add(const T& num1, const T& num2)
{
return num1 + num2;
}
int main()
{
int a1 = 1, b1 = 2;
double a2 = 2.0, b2 = 4.99;
int ret1 = Add<int>(a1, a2);
double ret2 = Add<double>(b1, b2);
return 0;
}
2.3 类模板

基本格式:
template
class 类模板名 {};
例如:
//定义一个类模板stack
//该stack可以存储所有类型
template <class T>
class stack
{
public:
stack(int capacity = 3)
{
_a = new T[capacity];
_capacity = capacity;
_top = 0;
}
void push(T val) {}
//…………
private:
T* _a;
int _capacity;
int _top;
};
类模板只能显示实例化,其基本格式为:
类模板名 <数据类型> 对象名
例如对于上面的类模板stack:
stack<int> st1;
stack<double> st2;
类成员函数声明和定义分离:
template <class T>
class stack
{
public:
stack(int capacity = 3)
{
_a = new T[capacity];
_capacity = capacity;
_top = 0;
}
void push(T val);
//…………
private:
T* _a;
int _capacity;
int _top;
};
//当声明和定义分离时,需要制定成员函数所在类的类型
//类模板的类模板名不是类名,类模板名<数据类型>才是类类型
//同样,成员函数的声明和定义不能分在两个不同的文件
template <class T>
void stack<T>::push(T val) {}
3. 模板的本质
-
和类实例化对象类似,我们不能将类看成是一个具体的对象,它只是一个不占据空间的
蓝图 -
同样,我们也不能将函数模板和类模板看成是一个具体的函数和类,他们也只是实例化一个具体函数和类的
模具 -
只有我们使用一个或多个具体的数据类型用模板实例化时,才会形成一个具体的函数和类。
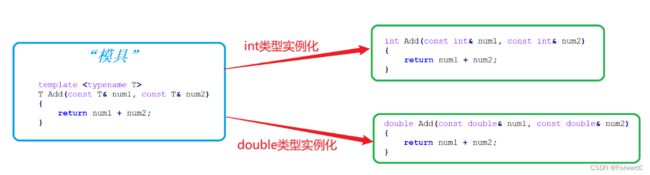
如上图所示, 在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。因此实际上,我们没写的冗余代码,编译器都替我们完成了,是编译器在替我们负重前行。