Java InfluxDB 入门
文章目录
-
- 1. InfluxDB 配置
-
- 1.1. 配置方式
- 1.2. 常用配置
- 2. token 获取
- 3. 依赖包
- 4. 接口设计
- 5. 插入数据
- 6. 查询数据
- 7. 常见问题
-
- 7.1. 时区问题
- 7.2 注册为 Windows 服务启动数据丢失问题
最近在做的业务设计到物联网数据的采集,之前没做过这个领域的东西,但是直接用关系类的数据库做不是很理想吧,多方学习查询知道了数据库还有一类叫时序数据库,特点就是数据都有一个时间,且是有顺序的,感觉有两个还不错,一个涛思数据库(TDEngine),一个 InfluxDB,两个基础功能都是开源免费的,github 的 start 数据也差不多,后面 TDEngine 上手感觉要容易点,实测用了下也还不错(我们业务就很简单,就是存储采集的数据,查询就一个根据时间查历史数据,要求不高的),其实心里也偏向一点国产… 后面一切完成,去客户那边部署的时候尴尬了(也确实是选型测试不到位,java js 的简单业务写惯了以为是个系统就能跑)… … 客户那边是 Windows Server 2012 系统,安装涛思数据库直接少个文件,问下社群原因是不支持… 
然而我当时装的是 3.0.6… 既然官方已经表明不支持了还是换一个吧,趁业务要求还不高,连夜学习 InfluxDB,目前也算差不多了,简单记录一下。 记录为主,教程为辅, 推荐一下尚硅谷的免费 InfluxDB 课程: 尚硅谷大数据技术之InfluxDB时序数据库(虽然我只跳着看了几集,感觉还是不错的)
注:本文采用 InfluxDB 版本为 2.7.1
可以先贴一下采集的数据大概样子:
{
"data": [
{
"name": "WSBB006_AM",
"value": false
},
{
"name": "KT3506_state",
"value": true
},
{
"name": "WSDIP_TEMP",
"value": 25
},
{
"name": "WSDIP_HUMI",
"value": 58.2
},
],
"message": "查询测点数据成功",
"result": true
}
现场对接口的一点小插曲,开始线上聊的时候,采集那边说是返回 0 1(也可能是搞嵌入式的习惯把 false true 说成 0 1?)结果到现场一测是个布尔值(fasle,true这种),,后面想了一下,还是中间套一个小服务比较好,处理一下三方转过来的数据格式,让其变成兼容系统设计的,这样三方那边一些数据格式的变化改动就容易很多了。
1. InfluxDB 配置
可以对启动端口、数据存储目录等进行配置
官方配置文档: https://docs.influxdata.com/influxdb/v2/reference/config-options/
1.1. 配置方式
按优先级排序:
-
命令参数
启动时附加标记来指定位置 -
环境变量
配置环境变量 -
配置文件
会读取 influxd 目录下的config.*格式文件,支持格式: yaml toml json
1.2. 常用配置
#### 更改数据存储目录默认在当前用户目录下面,下面改成 influxd 同级示例:
# 数据目录
engine-path: .influxdbv2/engine
# 账户数据等
bolt-path: .influxdbv2/influxd.bolt
# sqlite 文件,存的 notebooks 等数据
sqlite-path: .influxdbv2/influxd.sqlite
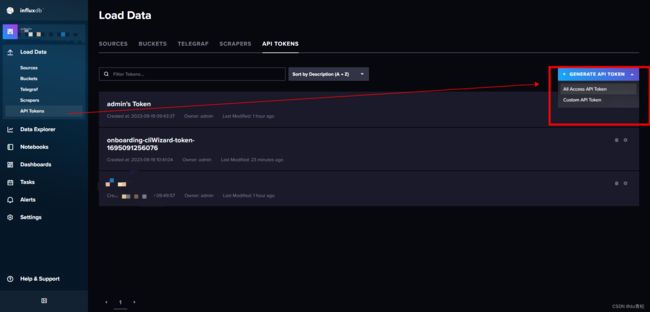
2. token 获取
在此处添加即可
3. 依赖包
此处可直接获取对应语言的入门示例:
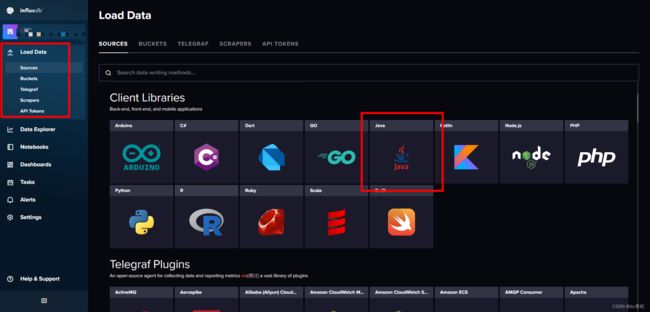
influxdb 客户端依赖,该用哪个版本上面示例点进去可以看到
<dependency>
<groupId>com.influxdbgroupId>
<artifactId>influxdb-client-javaartifactId>
<version>6.6.0version>
dependency>
yml 环境配置
influxdb:
url: http://192.168.1.1:8086 # influx 地址
token: WCp4FCd9yZjAl4uweTZGXSnMSEqJH_M5XjAnUPy3cDvMhakKXXprkKe9Q0wwh2WYtBlJlcZSk3dm4WEnaA2B6A==
bucket: 存储桶
org: 组织名称
InfluxDBClient 配置,注册 InfluxDBClient Spring 单例 Bean
@Configuration
public class InfluxDBConfig {
@Value("${influxdb.url}")
private String url;
@Value("${influxdb.token}")
private String token;
@Value("${influxdb.bucket}")
private String bucket;
@Value("${influxdb.org}")
private String org;
@Bean
public InfluxDBClient init() {
// 构造函数有很多方式,具体根据业务形式调整即可,我们这个桶和组织都是不变的,所以这里创建的时候直接带上即可,后面写数据就不用再传了
return InfluxDBClientFactory.create(url, token.toCharArray(), org, bucket);
}
}
至此可以先运行一下,如果报错 ,如图所示:
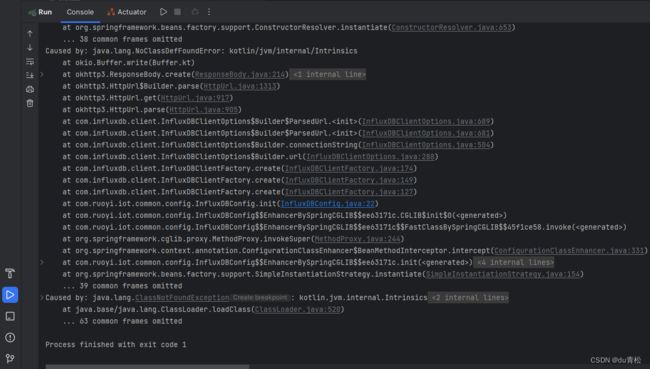
则需要再添加一个依赖,参考链接: https://github.com/influxdata/influxdb-client-java/issues/530
<dependency>
<groupId>com.squareup.okhttp3groupId>
<artifactId>okhttpartifactId>
<version>4.10.0version>
dependency>
4. 接口设计
public interface DataCollectionService {
// tableName 对应其实就是测量名称,data 就是采集字段和值
void write(String tableName, Map<String, String> data);
/**
* 查历史数据
* @param tableName
* @param fields 字段集合
* @param start 开始时间
* @param end 结束时间
* @return 字段 -> [值,时间]
*/
Map<String, List<List>> getHistories(String tableName,
List<String> fields,
Date start,
Date end,
Integer pageSize,
Integer pageNum
);
}
5. 插入数据
可以用 com.influxdb.client.WriteApiBlocking 的 writeRecord 或 writePoint,record 就是纯字符串的 Influx 行协议,个人感觉 writePoint 要易用一些。
@Override
public void write(String measureName, Map<String, String> data) {
Point point = Point
.measurement(measureName)
.time(Instant.now(), WritePrecision.MS); // 这里也可以不指定时间,不指定, 业务时间精度要求不高,毫秒足矣了,虽然我对这不是很懂,但是低精度性能总比高精度性能好一点点吧?这里还有个时区问题,写到后文了。
data.forEach((key, value) -> {
if (value == null) {
return;
}
try {
point.addField(key, Double.valueOf(value)); // 数字一定要直接存数字,不然存成字符串了,然后后台的图表等功能就用不了了(主要还是采集)
} catch (NumberFormatException e) {
if (value.equals("false") || value.equals("true")) {
point.addField(key, Boolean.valueOf(value));
return;
}
point.addField(key, value);
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
});
// client 就是注入的 InfluxDBClient
WriteApiBlocking writeApi = client.getWriteApiBlocking();
writeApi.writePoint(point);
}
6. 查询数据
查询数据的 flux 语句可以在此处生成:
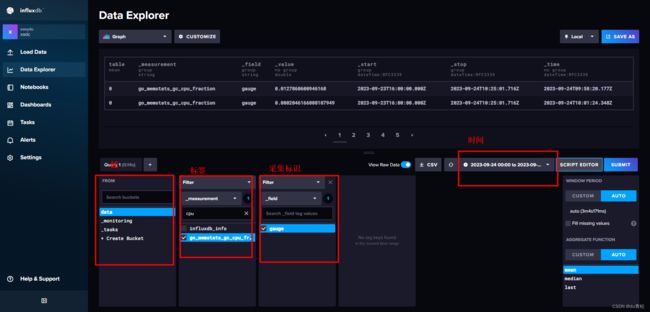
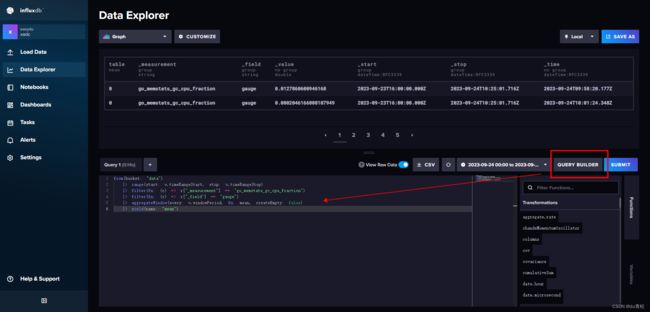
然后它这有的参数是 v. xxx,类似与 QueryAPI 的这个:
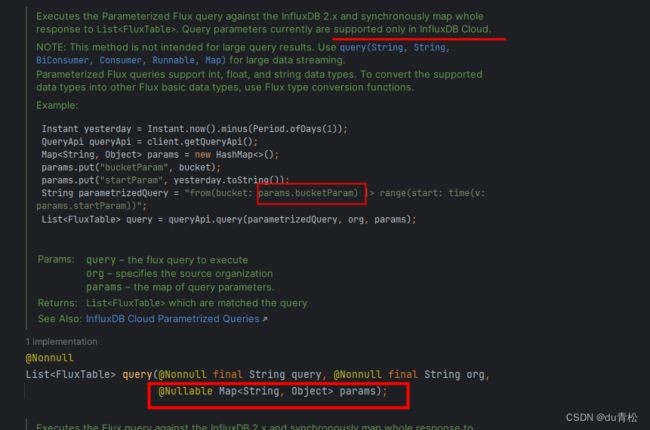
但是这种传参方式在 JavaAPI 里面只支持 Influx Cloud,但是也问题不大。
toInfluxDate 就是把前端传来的日期转成 yyyy-MM-ddTHH:mm:ss.000Z 这种 UTC 格式
public Map<String, List<List>> getHistories(String measureName,
List<String> fields,
Date start,
Date end,
Integer pageSize,
Integer pageNum) {
// client 就是注入的 InfluxDBClient
QueryApi queryApi = client.getQueryApi();
List<String> parametrizedQuery = new ArrayList<>();
parametrizedQuery.add(String.format("from(bucket: \"%s\")", bucket));
/**
* 时间范围
*/
parametrizedQuery.add(String.format("range(start: %s, stop: %s)", toInfluxDate(start), toInfluxDate(end))); // toInfluxDate 就是给小时减了8小时,其实在前端处理更合理,只是我们系统没有国际化的需求,算是给前端偷懒了
/**
* 过滤采集名称
*/
parametrizedQuery.add(String.format("filter(fn: (r) => r[\"_measurement\"] == \"%s\")", measureName));
/**
* 过滤字段
*/
String filedFilter = fields.stream().map(field -> String.format("r[\"_field\"] == \"%s\"", field)).collect(Collectors.joining(" or "));
parametrizedQuery.add(String.format("filter(fn: (r) => %s)", filedFilter));
/**
* 排序 按时间倒序
*/
parametrizedQuery.add("sort(columns: [\"_time\"], desc: true)");
/**
* 分页
*/
parametrizedQuery.add(String.format("limit(n: %s, offset: %s)", pageSize, pageSize * (pageNum - 1)));
Map<String, List<List>> result = new HashMap<>();
List<FluxTable> tables = queryApi.query(String.join(" |> ", parametrizedQuery));
for (FluxTable table : tables) {
List<List> list = table.getRecords().stream().map(record ->
Arrays.asList(record.getValue(), record.getTime().atZone(ZoneId.systemDefault()).toLocalDateTime()) // 日期直接转成本地的,前端拿去直接用
).collect(Collectors.toList());
result.put(table.getRecords().get(0).getField(), list);
}
return result;
}
7. 常见问题
7.1. 时区问题
InfluxDB 采用的 UTC 时间比国内多八个小时,所以进行查询操作的时候,需要给时间减去八小时。
开始想着在插入的时候加上八小时就OK了,后面我研究了下 WebUI 的传值方式:
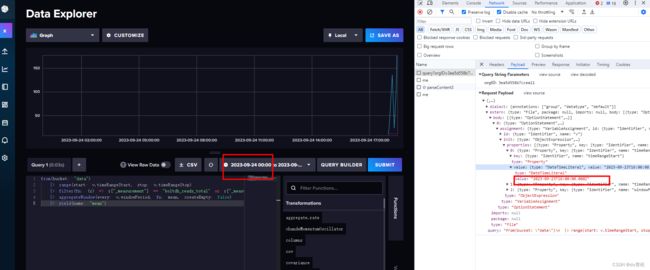
前端的日期是本地时间,给接口传的是已经处理过的了,如果后台存的时间是 +8小时的时间,那网页可能就用不了吧…
如果设计国际化的话,前端处理时区问题才是更合理的,毕竟前端相比后端,更容易知道用户的时区吧
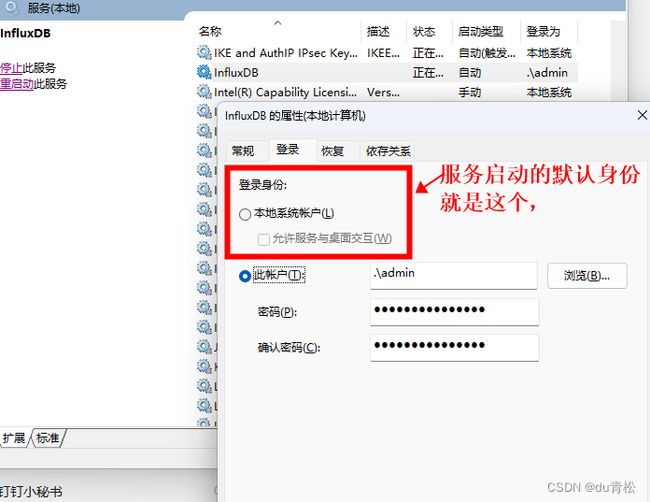
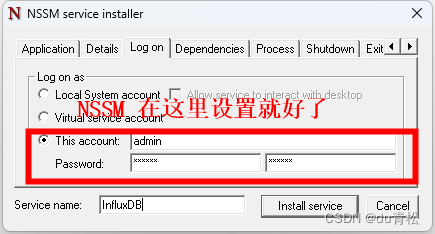
7.2 注册为 Windows 服务启动数据丢失问题
使用 NSSM 工具或者其它注册服务的工具注册为服务运行可能导致之前的数据丢失,其原因就是 InfluxDB 的数据目录默认在当前登录用户下的主目录下面(即 %USERPROFILE%),而服务默认情况下使用的用户身份是 本地系统账户 (主目录在:C:\Windows\System32\config\systemprofile),在该用户身份下读取数据自然就读不到了,有两种解决方案
一是手动设置服务的登录身份:
二是配置 InfluxDB 的数据目录,然而这个我暂时也还没找见在哪改,有知道的可以指导一下!!!
感谢 @绘入此间风指导, 参考上面 Influx 配置
神奇的是,有个人代码结构居然跟我差不多。。
https://blog.csdn.net/weixin_45914119/article/details/126760975