deep_learning_month4_week1_Convolution_model_Application
标签: 机器学习深度学习
代码已上传github:
https://github.com/PerfectDemoT/my_deeplearning_homework
[TOC]
说明:
这是month4_week1的第一个作业,这里用tensorflow构建了一个拥有两个卷基层,两个池化层,一个全连接层的卷积神经网络。
用来检测手指比划数字。
有一个坑,大家要小心:
在执行foward propagation那部分的代码时,有可能你的代码都是正确的,但是你的运行结果却与juypter notebook上的expected output的结果不一样。我在同学的电脑上试图运行相同的代码,结果发现可以正常运行,且结果正确;但是在自己电脑上运行的结果却不一样。虽然不知道原因,但是有一个解决办法:那就是换成老版本的tensorflow。我最初使用的就是tensorflow1.6.0版本,后来换成了1.2.0的版本就可以正确输出结果了。
下面一步步看代码
1. 准备
1. 先导入包:
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
import scipy
from PIL import Image
from scipy import ndimage
import tensorflow as tf
from tensorflow.python.framework import ops
from cnn_utils import *
%matplotlib inline
np.random.seed(1)
2. 导入数据
# Loading the data (signs)
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
3. 数据可视化看看一幅图
# Example of a picture
index = 6
plt.imshow(X_train_orig[index])
print ("y = " + str(np.squeeze(Y_train_orig[:, index])))

4. 查看数据的规模进行
X_train = X_train_orig/255.
X_test = X_test_orig/255.
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
conv_layers = {}
2. 函数编写
1. 编写占位符函数,方便之后赋值运行
# GRADED FUNCTION: create_placeholders
def create_placeholders(n_H0, n_W0, n_C0, n_y):
"""
Creates the placeholders for the tensorflow session.
Arguments:
n_H0 -- scalar, height of an input image
n_W0 -- scalar, width of an input image
n_C0 -- scalar, number of channels of the input
n_y -- scalar, number of classes
Returns:
X -- placeholder for the data input, of shape [None, n_H0, n_W0, n_C0] and dtype "float"
Y -- placeholder for the input labels, of shape [None, n_y] and dtype "float"
"""
### START CODE HERE ### (≈2 lines)
X = tf.placeholder(name='X', shape=(None, n_H0, n_W0, n_C0), dtype=tf.float32)
Y = tf.placeholder(name='Y', shape=(None, n_y), dtype=tf.float32)
### END CODE HERE ###
return X, Y
测试代码:
X, Y = create_placeholders(64, 64, 3, 6)
print ("X = " + str(X))
print ("Y = " + str(Y))
结果:
X = Tensor("Placeholder:0", shape=(?, 64, 64, 3), dtype=float32)
Y = Tensor("Placeholder_1:0", shape=(?, 6), dtype=float32)
2. 随机初始化参数
用到了tf.contrib.layers.xavier_initializer(seed = 0)函数,并且注意,tf.get_variable()内部参数的设定
def initialize_parameters():
"""
Initializes weight parameters to build a neural network with tensorflow. The shapes are:
W1 : [4, 4, 3, 8]
W2 : [2, 2, 8, 16]
Returns:
parameters -- a dictionary of tensors containing W1, W2
"""
tf.set_random_seed(1) # so that your "random" numbers match ours
### START CODE HERE ### (approx. 2 lines of code)
W1 = tf.get_variable(name='W1', dtype=tf.float32, shape=(4, 4, 3, 8), initializer=tf.contrib.layers.xavier_initializer(seed = 0))
W2 = tf.get_variable(name='W2', dtype=tf.float32, shape=(2, 2, 8, 16), initializer=tf.contrib.layers.xavier_initializer(seed = 0))
### END CODE HERE ###
parameters = {"W1": W1,
"W2": W2}
return parameters
当然,其中的seed的设定是为了让值和expected的结果一样
输出一下:
tf.reset_default_graph()
with tf.Session() as sess_test:
parameters = initialize_parameters()
init = tf.global_variables_initializer()
sess_test.run(init)
print("W1 = " + str(parameters["W1"].eval()[1,1,1]))
print("W2 = " + str(parameters["W2"].eval()[1,1,1]))
结果为:
W1 = [ 0.00131723 0.14176141 -0.04434952 0.09197326 0.14984085 -0.03514394
-0.06847463 0.05245192]
W2 = [-0.08566415 0.17750949 0.11974221 0.16773748 -0.0830943 -0.08058
-0.00577033 -0.14643836 0.24162132 -0.05857408 -0.19055021 0.1345228
-0.22779644 -0.1601823 -0.16117483 -0.10286498]
3. 前向传播(这里有坑)
有可能你的代码都是正确的,但是你的运行结果却与juypter notebook上的expected output的结果不一样。我在同学的电脑上试图运行相同的代码,结果发现可以正常运行,且结果正确;但是在自己电脑上运行的结果却不一样。虽然不知道原因,但是有一个解决办法:那就是换成老版本的tensorflow。我最初使用的就是tensorflow1.6.0版本,后来换成了1.2.0的版本就可以正确输出结果了。
解释:
对于函数 tf.nn.conv2d(input , filter , strides , padding , use_cudnn_on_gpu=None , name=None) :
input:指卷积需要输入的参数,具有这样的shape[batch, in_height, in_width, in_channels],分别是[batch张图片, 每张图片高度为in_height, 每张图片宽度为in_width, 图像通道为in_channels]。
filter:指用来做卷积的滤波器,当然滤波器也需要有相应参数,滤波器的shape为[filter_height, filter_width, in_channels, out_channels],分别对应[滤波器高度, 滤波器宽度, 接受图像的通道数, 卷积后通道数],其中第三个参数 in_channels需要与input中的第四个参数 in_channels一致,out_channels第一看的话有些不好理解,如rgb输入三通道图,我们的滤波器的out_channels设为1的话,就是三通道对应值相加,最后输出一个卷积核。
strides:代表步长,其值可以直接默认一个数,也可以是一个四维数如[1,2,1,1],则其意思是水平方向卷积步长为第二个参数2,垂直方向步长为1.其中第一和第四个参数我还不是很明白,请大佬指点,貌似和通道有关系。
padding:代表填充方式,参数只有两种,SAME和VALID,SAME比VALID的填充方式多了一列,比如一个33图像用22的滤波器进行卷积,当步长设为2的时候,会缺少一列,则进行第二次卷积的时候,VALID发现余下的窗口不足2*2会直接把第三列去掉,SAME则会填充一列,填充值为0。
use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true。大概意思是是否使用gpu加速,还没搞太懂。
name:给返回的tensor命名。给输出feature map起名字。
tf.nn.max_pool(value, ksize, strides, padding, name=None)
value:池化的输入,一般池化层接在卷积层的后面,所以输出通常为feature map。feature map依旧是[batch, in_height, in_width, in_channels]这样的参数。
ksize:池化窗口的大小,参数为四维向量,通常取[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1。ps:估计面tf.nn.conv2d中stries的四个取值也有 相同的意思。
stries:步长,同样是一个四维向量。
padding:填充方式同样只有两种不重复了。
tf.contrib.layers.flatten(P) 的参数意义。
tf.contrib.layers.flatten(P): given an input P, this function flattens each example into a 1D vector it while maintaining the batch-size. It returns a flattened tensor with shape [batch_size, k].
tf.contrib.layers.fully_connected(F, num_outputs)
tf.contrib.layers.fully_connected(F, num_outputs): given a the flattened input F, it returns the output computed using a fully connected layer. You can read the full documentation
下面看看代码:
def forward_propagation(X, parameters):
"""
Implements the forward propagation for the model:
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
Arguments:
X -- input dataset placeholder, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "W2"
the shapes are given in initialize_parameters
Returns:
Z3 -- the output of the last LINEAR unit
"""
# Retrieve the parameters from the dictionary "parameters"
W1 = parameters['W1']
W2 = parameters['W2']
### START CODE HERE ###
# CONV2D: stride of 1, padding 'SAME'
Z1 = tf.nn.conv2d(input=X, filter=W1, strides=(1, 1, 1, 1), padding='SAME')
# RELU
A1 = tf.nn.relu(Z1)
# MAXPOOL: window 8x8, sride 8, padding 'SAME'
P1 = tf.nn.max_pool(value=A1, ksize=(1, 8, 8, 1), strides=(1, 8, 8, 1), padding='SAME')
# CONV2D: filters W2, stride 1, padding 'SAME'
Z2 = tf.nn.conv2d(input=P1, filter=W2, strides=(1, 1, 1, 1), padding='SAME')
# RELU
A2 = tf.nn.relu(Z2)
# MAXPOOL: window 4x4, stride 4, padding 'SAME'
P2 = tf.nn.max_pool(value=A2, ksize=(1, 4, 4, 1), strides=(1, 4, 4, 1), padding='SAME')
# FLATTEN
P2 = tf.contrib.layers.flatten(inputs=P2)
# FULLY-CONNECTED without non-linear activation function (not not call softmax).
# 6 neurons in output layer. Hint: one of the arguments should be "activation_fn=None"
Z3 = tf.contrib.layers.fully_connected(P2, 6, activation_fn=None)
### END CODE HERE ###
return Z3
输出一下:
tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
X, Y = create_placeholders(64, 64, 3, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
init = tf.global_variables_initializer()
sess.run(init)
a = sess.run(Z3, {X: np.random.randn(2,64,64,3), Y: np.random.randn(2,6)})
print("Z3 = " + str(a))
结果:
Z3 = [[-0.44670227 -1.57208765 -1.53049231 -2.31013036 -1.29104376 0.46852064]
[-0.17601591 -1.57972014 -1.4737016 -2.61672091 -1.00810647 0.5747785 ]]
4.介绍cost函数
这里用的是softmax回归,借助tensorflow框架,只需要一行代码即可完成cost
# GRADED FUNCTION: compute_cost
def compute_cost(Z3, Y):
"""
Computes the cost
Arguments:
Z3 -- output of forward propagation (output of the last LINEAR unit), of shape (6, number of examples)
Y -- "true" labels vector placeholder, same shape as Z3
Returns:
cost - Tensor of the cost function
"""
### START CODE HERE ### (1 line of code)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3, labels=Y))
### END CODE HERE ###
return cost
输出结果:
tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
X, Y = create_placeholders(64, 64, 3, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
init = tf.global_variables_initializer()
sess.run(init)
a = sess.run(cost, {X: np.random.randn(4,64,64,3), Y: np.random.randn(4,6)})
print("cost = " + str(a))
结果:
cost = 2.91034
3. 整合(model)函数
这个函数运用了前面的的所有的函数,创建占位符函数,随机初始化函数,前向传播函数,反向传播函数,cost函数。
然后用了mini-batch每一个Batch大小为64,对于反向传播,只需要一行。是下面这个:
$$optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)$$
下面我们来看看代码:
def model(X_train, Y_train, X_test, Y_test, learning_rate=0.009,
num_epochs=100, minibatch_size=64, print_cost=True):
"""
Implements a three-layer ConvNet in Tensorflow:
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
Arguments:
X_train -- training set, of shape (None, 64, 64, 3)
Y_train -- test set, of shape (None, n_y = 6)
X_test -- training set, of shape (None, 64, 64, 3)
Y_test -- test set, of shape (None, n_y = 6)
learning_rate -- learning rate of the optimization
num_epochs -- number of epochs of the optimization loop
minibatch_size -- size of a minibatch
print_cost -- True to print the cost every 100 epochs
Returns:
train_accuracy -- real number, accuracy on the train set (X_train)
test_accuracy -- real number, testing accuracy on the test set (X_test)
parameters -- parameters learnt by the model. They can then be used to predict.
"""
ops.reset_default_graph() # to be able to rerun the model without overwriting tf variables
tf.set_random_seed(1) # to keep results consistent (tensorflow seed)
seed = 3 # to keep results consistent (numpy seed)
(m, n_H0, n_W0, n_C0) = X_train.shape
n_y = Y_train.shape[1]
costs = [] # To keep track of the cost
# Create Placeholders of the correct shape
### START CODE HERE ### (1 line)
X, Y = create_placeholders(n_H0, n_W0, n_C0, n_y)
### END CODE HERE ###
# Initialize parameters
### START CODE HERE ### (1 line)
parameters = initialize_parameters()
### END CODE HERE ###
# Forward propagation: Build the forward propagation in the tensorflow graph
### START CODE HERE ### (1 line)
Z3 = forward_propagation(X, parameters)
### END CODE HERE ###
# Cost function: Add cost function to tensorflow graph
### START CODE HERE ### (1 line)
cost = compute_cost(Z3, Y)
### END CODE HERE ###
# Backpropagation: Define the tensorflow optimizer. Use an AdamOptimizer that minimizes the cost.
### START CODE HERE ### (1 line)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
### END CODE HERE ###
# Initialize all the variables globally
init = tf.global_variables_initializer()
# Start the session to compute the tensorflow graph
with tf.Session() as sess:
# Run the initialization
sess.run(init)
# Do the training loop
for epoch in range(num_epochs):
minibatch_cost = 0.
num_minibatches = int(m / minibatch_size) # number of minibatches of size minibatch_size in the train set
seed = seed + 1
minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)
for minibatch in minibatches:
# Select a minibatch
(minibatch_X, minibatch_Y) = minibatch
# IMPORTANT: The line that runs the graph on a minibatch.
# Run the session to execute the optimizer and the cost, the feedict should contain a minibatch for (X,Y).
### START CODE HERE ### (1 line)
_, temp_cost = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y})
### END CODE HERE ###
minibatch_cost += temp_cost / num_minibatches
# Print the cost every epoch
if print_cost == True and epoch % 5 == 0:
print("Cost after epoch %i: %f" % (epoch, minibatch_cost))
if print_cost == True and epoch % 1 == 0:
costs.append(minibatch_cost)
# plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
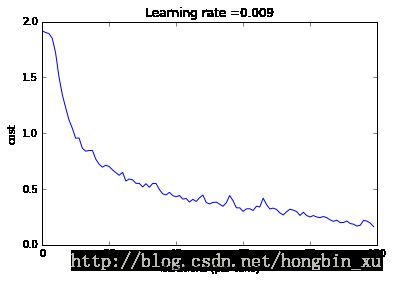
plt.title("Learning rate =" + str(learning_rate))
plt.show()
# Calculate the correct predictions
predict_op = tf.argmax(Z3, 1)
correct_prediction = tf.equal(predict_op, tf.argmax(Y, 1))
# Calculate accuracy on the test set
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print(accuracy)
train_accuracy = accuracy.eval({X: X_train, Y: Y_train})
test_accuracy = accuracy.eval({X: X_test, Y: Y_test})
print("Train Accuracy:", train_accuracy)
print("Test Accuracy:", test_accuracy)
return train_accuracy, test_accuracy, parameters
输出一下:
_, _, parameters = model(X_train, Y_train, X_test, Y_test)
结果(迭代了100次,所以有20个输出(每隔五个输出一次))
Cost after epoch 0: 1.917929
Cost after epoch 5: 1.506757
Cost after epoch 10: 0.955359
Cost after epoch 15: 0.845802
Cost after epoch 20: 0.701174
Cost after epoch 25: 0.571977
Cost after epoch 30: 0.518435
Cost after epoch 35: 0.495806
Cost after epoch 40: 0.429827
Cost after epoch 45: 0.407291
Cost after epoch 50: 0.366394
Cost after epoch 55: 0.376922
Cost after epoch 60: 0.299491
Cost after epoch 65: 0.338870
Cost after epoch 70: 0.316400
Cost after epoch 75: 0.310413
Cost after epoch 80: 0.249549
Cost after epoch 85: 0.243457
Cost after epoch 90: 0.200031
Cost after epoch 95: 0.175452
cost曲线图片如下
准确度计算:
Tensor("Mean_1:0", shape=(), dtype=float32)
Train Accuracy: 0.940741
Test Accuracy: 0.783333
4. 大家可以用自己的图片试试
fname = "images/thumbs_up.jpg"
image = np.array(ndimage.imread(fname, flatten=False))
my_image = scipy.misc.imresize(image, size=(64,64))
plt.imshow(my_image)
好了,已经完成了用tensorflow搭建一个卷积神经网络