sql语句和mysql函数
sql语句的分类
| 名字 | 类型 | 作用的对象 | 作用 |
|---|---|---|---|
| DDL 英文全称 (Data Definition Language) | 数据定义语言 | 库、表、列 | 创建、删除、修改、库或表结构,对数据库或表的结构操作 |
| DML 英文全称(Data Manipulation Language) | 数据操作语言 | 数据库记录(数据) | 增、删、改,对表记录进行更新(增、删、改) |
| DQL 英文全称(Data Query Language) | 数据查询语言 | 数据库记录(数据) | 查、用来查询数据,对表记录的查询 |
| DCL 英文全称(Data Control Language) | 数据控制语言 | 数据库用户 | 用来定义访问的权限和安全级别,对用户的创建,及授权 |
DDL (Data Definition Language) 数据定义语言
# 对数据库的常用操作
# 查看所有的数据库
show datebases;
# 查看某个数据库的定义的信息
show create database 数据库名;
# 查看正在使用的数据库
select database();
# 切换 (选择要操作的) 数据库
use 数据库名;
# 创建数据库
create database [if not exists] 数据库名 [charset=utf8];
# 删除数据库
drop database [if exists] 数据库名;
# 修改数据库编码
alter database 数据库名 character set utf8;
# 对表结构的常用操作
# 创建表
create table 表名(列名 列类型[长度,约束],......);
# 查看当前数据库的所有表名称
show tables;
# 查看指定某个表的创建语句
show create table 表名;
# 查看表结构
desc 表名;
# 删除表
drop table [if exists] 表名;
# 修改表结构
# 添加列
alter table 表名 add(列名 列类型,列名 列类型,列名 列类型,......,列名 列类型);
# 修改表之修改列类型
alter table 表名 modify 列名 修改的列类型;
# 修改表之改列名
alter table 表名 change 原列名 新列名 列类型;
# 修改表之删除列
alter table 表名 drop 列名;
# 修改表之修改表名称
alter table 原表名 rename to 新表名;
# 修改表的字符集
ALTER TABLE 表名 CHARACTER SET gbk;
# 表的复制
# 1. 复制表结构
create table table1 like table2;
# 2. 复制表结构和数据
create table table1 select * from table2;
DML(Data Manipulation Language)数据操作语言
# delete
delete from 表名 where 条件;
# insert
# 表结构一样
insert into 表1 select * from 表2
# 表结构不一样
insert into 表1 (列名1,列名2,列名3) select 列1,列2,列3 from 表2
# 只从另一个表取部分字段
insert into 表1 (列名1,列名2,列名3) values(列1,列2,(select 列3 from 表2));
# update
# 更新所有记录的指定字段
update 表名 set 字段名=值,字段名=值,…;
# 更新符合条件记录的指定字段
update 表名 set 字段名=值,字段名=值,… where 条件;
# 修改多表
update table t1,table2 t2 on t1.id=t2.id set t1.name='zs' where t2.name='ls'
sql约束
# not null
# default 写在字段类型后
# PRIMARY KEY 约束唯一标识数据库表中的每条记录。
# 主键必须包含唯一的值。
# 主键列不能包含 NULL 值。
# 每个表都应该有一个主键,并且每个表只能有一个主键。
# 创建表时添加约束
CREATE TABLE persons
( id_p int PRIMARY KEY,
lastname varchar(255),
firstname varchar(255),
address varchar(255),
city varchar(255) )
# 创建表时,在constraint约束区域,声明指定字段为主键:
# 格式: [constraint 名称] primary key (字段列表)
# 关键字constraint可以省略,如果需要为主键命名,constraint不能省略,主键名称一般没用。
#字段列表需要使用小括号括住,如果有多字段需要使用逗号分隔。声明两个以上字段为主键,我们称为联合主键。
CREATE TABLE persons (
firstname varchar(255),
lastname varchar(255),
address varchar(255),
city varchar(255),
CONSTRAINT pk_personID PRIMARY KEY (firstname,lastname) )
# 方式三:创建表之后,通过修改表结构,声明指定字段为主键:
# 格式: ALTER TABLE persons ADD [CONSTRAINT 名称] PRIMARY KEY (字段列表)
CREATE TABLE persons (
firstname varchar(255),
lastname varchar(255),
address varchar(255),
city varchar(255) )
ALTER TABLE persons ADD PRIMARY KEY (firstname,lastname)
# 删除主键约束
ALTER TABLE persons DROP PRIMARY KEY
# 自动增长列
# 我们可以在表中使用 auto_increment(自动增长列)关键字,
# 自动增长列类型必须是整形,自动增长列必须为键(一般是主键)。
# sql发生回滚,自增主键不会回滚,下一次分配继续自增
CREATE TABLE persons (
p_id int PRIMARY KEY AUTO_INCREMENT,
lastname varchar(255),
firstname varchar(255),
address varchar(255),
city varchar(255) )
# 在为字段赋值时,自动增长的列可以为null 或者 什么都不写
# :默认AUTO_INCREMENT 的开始值是 1,如果希望修改起始值
ALTER TABLE persons AUTO_INCREMENT=100
# 针对auto_increment,
# delete 一条一条删除,不清空auto_increment记录数。
# truncate 直接将表删除,重新建表,auto_increment将置为零,从新开始。
# UNIQUE 约束唯一标识数据库表中的每条记录。 UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。
# 每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。
# unique可以为null,PRIMARY KEY不可以为null
CREATE TABLE persons (id_p int UNIQUE, lastname varchar(255) NOT NULL, firstname varchar(255), address varchar(255), city varchar(255) )
CREATE TABLE persons (id_p int, lastname varchar(255) NOT NULL, firstname varchar(255), address varchar(255), city varchar(255), CONSTRAINT 名称UNIQUE (Id_P) )
ALTER TABLE persons ADD [CONSTRAINT 名称] UNIQUE (Id_P)
ALTER TABLE persons DROP INDEX 名称
# 外键约束
# 从表外键的值是对主表主键的引用。
# 从表外键类型,必须与主表主键类型一致
# 在从表添加外键约束,用于限制主表中某列的值
alter table 从表 add [constraint][外键名称] foreign key (从表外键字段名) references 主表 (主 表的主键); [外键名称]用于删除外键约束的,一般建议“_fk”结尾
alter table 从表 drop foreign key 外键名称
使用int自增主键后最大id是3,删除id 3和2,再添加一条记录,最后添加的id是几?
如果重启mysql就会从最大的id自增,
如果没重启,就会延续删除之前最大的id
CREATE TABLE if NOT EXISTS article(
id INT(10) UNSIGNED NOT NULL PRIMARY KEY auto_increment,
author_id int(10) UNSIGNED NOT NULL,
category_id int(10) UNSIGNED NOT NULL,
views int(10) UNSIGNED NOT NULL,
comments int(10) UNSIGNED NOT NULL,
title VARBINARY(255) NOT NULL,
content text NOT NULL
);
INSERT INTO article(`author_id`,`category_id`,`views`,`comments`,`title`,`content`) VALUES (1,1,1,1,'1','1'),
(2,2,2,2,'2','2'),
(3,3,3,3,'3','3');
SELECT * FROM article;
DELETE FROM article WHERE id=2 OR id=3;
# id是4
INSERT INTO article (`author_id`,`category_id`,`views`,`comments`,`title`,`content`) VALUES(4,4,4,4,'4','4');
# 删除最新的这条,然后重启mysql,再添加,
# id就不是5,而是2
DELETE FROM article WHERE id=4;
# AUTO_INCREMENT=2,当前最大id是被记录了的,
SHOW CREATE TABLE article;
有没有使用过外键?
下面是阿里巴巴开发手册的

sql关键字
# 去重
distinct
# limit后面不能跟子查询,只能跟数字
limit
# 任何值与null 使用 + 连接,都为null
null
## UNION
# UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
# 请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。
# 列也必须拥有相似的数据类型。同时,每条 SELECT语句中的列的顺序必须相同。
# 注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
select id from t where num=10
union all
select id from t where num=20
exists和in
# exists
# 返回1,相当于true
SELECT EXISTS(SELECT * FROM student);
# 返回0,相当于false
SELECT EXISTS(SELECT * FROM student WHERE sid=6);
# exists和in的区别
# 外表很小,子表大,用exists,否则用in
# 如果两表相差不大,则查询效率相差不大
# exists是把外表每条数据都拿出来做比较,所以外表越小,它比较的次数越小,
# 性能也就越高
# in是把子查询的结果集分解成每一个条件来和外表进行比较,所以子表越小,它比较的次数越少
select a.name,a.projectId from a a where EXISTS
(select b.id from b b where a.projectId = b.id)
SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,...)
多表连接
# inner 可以省略
select * from table t1 left(right,inner) join table2 t2
on t1.id=t2.id
where
group by
having
order by
limit 起始索引,显示的个数

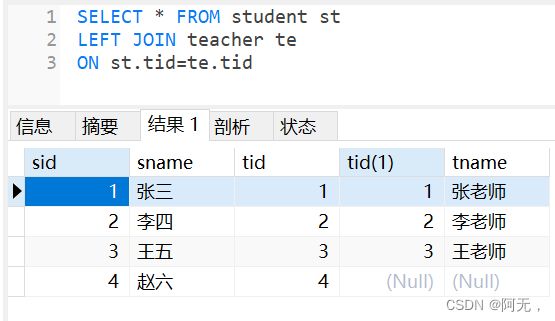
七种join sql
# 部门表
CREATE TABLE tbl_dept(
id int(11) NOT NULL AUTO_INCREMENT,
deptName VARCHAR(30) DEFAULT NULL,
locAdd VARCHAR(40) DEFAULT NULL,
PRIMARY key(id)
)ENGINE=innodb auto_increment=1 DEFAULT CHARSET=utf8;
# 员工表
CREATE TABLE tbl_emp(
id int(11) NOT NULL AUTO_INCREMENT,
name VARCHAR(20) DEFAULT NULL,
deptId int(11) DEFAULT NULL,
PRIMARY key(id),
key fk_dept_id (deptId)
)ENGINE=innodb auto_increment=1 DEFAULT CHARSET=utf8;
INSERT INTO tbl_dept(deptName,locAdd) VALUES('rd',11);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('hr',12);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('mk',13);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('mis',14);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('fd',15);
INSERT INTO tbl_emp(name,deptId) VALUES('z3',1);
INSERT INTO tbl_emp(name,deptId) VALUES('z4',1);
INSERT INTO tbl_emp(name,deptId) VALUES('z5',1);
INSERT INTO tbl_emp(name,deptId) VALUES('w5',2);
INSERT INTO tbl_emp(name,deptId) VALUES('w6',2);
INSERT INTO tbl_emp(name,deptId) VALUES('s7',3);
INSERT INTO tbl_emp(name,deptId) VALUES('s8',4);
INSERT INTO tbl_emp(name,deptId) VALUES('s9',5);
# 1. 笛卡尔积,数量 = a表数量 * b表数量
SELECT * FROM tbl_emp te,tbl_dept td;
# 2. 内连接,两表的公共部分,inner join可以省略
SELECT * FROM tbl_emp te,tbl_dept td WHERE te.deptId=td.id;
# 3. 左外连接,两张表关联之后,左表以及两表的公共部分
# 如果左表有而右表没有的部分,右表补null
# 右外连接与左外连接类似,不做概述
SELECT * FROM tbl_emp te LEFT JOIN tbl_dept td on te.deptId=td.id;
# 4. a表独有
# 两表关联之后,只要a表的部分,舍弃b表及公共部分
# b表独有与a表独有类似,不做概述
SELECT * FROM tbl_emp te LEFT JOIN tbl_dept td on te.deptId=td.id WHERE td.id is null;
# 5. 全连接,a表及b表的全部,包括共有部分
# mysql5.7不支持 FULL JOIN
# SELECT * FROM tbl_emp te FULL JOIN tbl_dept td on te.deptId=td.id;
# 可以使用union代替
SELECT * FROM tbl_emp te LEFT JOIN tbl_dept td on te.deptId=td.id
UNION
SELECT * FROM tbl_dept td right JOIN tbl_emp te on te.deptId=td.id
# 6.a独有 + b独有
SELECT * FROM tbl_emp te LEFT JOIN tbl_dept td on te.deptId=td.id WHERE td.id is null
UNION
SELECT * FROM tbl_emp te RIGHT JOIN tbl_dept td on td.id=te.deptId WHERE te.deptId is null
# 员工表
SELECT * FROM tbl_emp;
# 部门表
SELECT * FROM tbl_dept;
sql书写的注意事项和执行顺序
- where后面不能跟聚合函数
- where后面不能使用select中定义的别名
- sql语句的书写顺序和执行顺序不一样
- select … from … where … group by … having … order by
- from … where … group by … having … select … order by

having与where的区别
-
having是在分组后对数据进行过滤.
where是在分组前对数据进行过滤 -
having后面可以使用分组函数(统计函数)
where后面不可以使用分组函数
where后面为什么不能跟聚合函数
聚合函数又叫列函数,聚合函数要对全列数据计算,因而使用它的前提是:结果集已经确定!
根据mysql的执行步骤,当程序执行到where的时候,mysql是没有确定结果集的,所以聚合函数不能用在where后面。
使用having前面一定要有分组,而分组的时候就已经有结果了,所以就有结果集,满足聚合函数前面一定要有结果集的要求。
mysql函数
聚合函数
max(列名) 求这一列的最大值
min(列名) 求这一列的最小值
avg(列名) 求这一列的平均值
sum(列名) 对这一列求总和
abs() 绝对值
count(列名) 统计这一列有多少条记录
count(*) 统计有多少行,只要有一列不为null,就全部统计
count(1) 统计有多少行,相当于增加了一列,值都是1
# count(*)与count(列名)的区别
# count(*)会统计值为null的行,count(列名)不会
MYISAM存储引擎下,*效率高
innodb存储引擎下,*和1的效率差不多,比字段高一点
数学函数
# cast 数据类型转换
# cast没有截断和四舍五入的功能,所以,当要转换为int,
# 而输入的字符串不是整数时,将报错
# 字符串转换为浮点
# 10 代表 小数位数 + 整数位数,2表示小数位数
# 那么 该数最大为8个9,最小为 0.01
SELECT CAST('9.5' AS decimal(10,2))
// 2022-02-15
SELECT CAST(NOW() AS DATE)
# TRUNCATE()直接截取小数值,不会四舍五入
SELECT TRUNCATE(1.23456,3) -- 1.234
# ROUND()函数,四舍五入截取
SELECT round(1.23456,3) -- 1.235
# ceil() 向上取整
# floor() 向下取整
# mod() 取余
日期函数
// 6
SELECT DAY("2020-07-06")
year()
month()
// 获取7月的最后一天
SELECT LAST_DAY('2020-07-01')
// 2020-05-22 16:25:32
SELECT NOW()
// 2020-05-22
select curdate()
SELECT CURRENT_TIME()
// 日期对应星期几
dayname(日期)
// 获取上个月的第一天
select date_add(curdate() - day(curdate()) +1,interval -1 month )
SELECT STR_TO_DATE('1999-09-09','%Y-%m-%d')
# date_format(date,format):日期格式化
// 2020-02-22 22:22:22
SELECT DATE_FORMAT('2020:02:22 22:22:22','%Y-%m-%d %H:%i:%s')
// 2018-07-12
SELECT DATE_FORMAT(NOW(),'%Y-%m-%d')
# date_add():为日期增加一个时间间隔
select date_add(now(), interval 1 day); -- add 1 day
select date_add(now(), interval 1 hour); -- add 1 hour
select date_add(now(), interval 1 minute); -- add 1 minute
select date_add(now(), interval 1 second); -- 秒
select date_add(now(), interval 1 microsecond); -- 微秒
select date_add(now(), interval 1 week);
select date_add(now(), interval 1 month);
select date_add(now(), interval 1 quarter); -- 季度
select date_add(now(), interval 1 year);
select date_add(now(), interval -1 day); -- sub 1 day
select date_add(now(), interval '01:15:30' hour_second); -- 增加时间间隔为时分秒
# date_sub(): 为日期减去一个时间间隔
# 和date_add()用法一致
字符串函数
# 1
SELECT LENGTH('1');
# 4 该函数求的是字节,utf8编码一个汉字占3个字节,gbk占两个字节
SELECT LENGTH('啊1');
/*
substring与substr异同
第一个参数是当前下标
第二个参数是截取字符串的长度
一模一样,有的文章在瞎扯
*/
# 都是 2023-09-30 05:44:35
SELECT substr(now(),1);
SELECT substring(now(),1);
# param2 在 param1中的起始索引
SELECT INSTR('科学家的类别可以不一样','不一样')
# 去除前后空格
trim(str)
SELECT REPLACE('类别不一样','一样','相同')
# concat 连接查询出来的值
# attr_name attr_value
# 颜色 黑色
# 内存 12
SELECT CONCAT(attr_name,":",attr_value) FROM pms_sku_sale_attr_value WHERE sku_id=6
# 颜色:黑色
# 内存:12
# 将group by产生的同一个分组中的值连接起来
# 颜色 黑色
# 内存 8
# 颜色 黑色
# 内存 12
# 颜色 白色
# 内存 8
# 颜色 白色
# 内存 12
# 颜色 蓝色
# 内存 8
# 颜色 蓝色
# 内存 12
SELECT attr_name,GROUP_CONCAT(attr_value) FROM ceshi GROUP BY attr_name;
# 内存 8,12,8,12,8,12
# 颜色 黑色,黑色,白色,白色,蓝色,蓝色
流程控制函数
# IFNULL(expression, alt_value)
# 如果第一个参数的表达式 expression 为 NULL,则返回第二个参数的备用值
SELECT IFNULL(NULL, "RUNOOB"); --RUNOOB
# IF(条件表达式,值1,值2)
select
Sname as '学生姓名',
Sage as '学生年龄',
IF(YEAR(Sage)<=1995,'1班','2班') as '所在班级'
from students ORDER BY Sage;
# 也有if else结构,可以应用于begin end中
# case when:相当于if else
--简单Case函数
case 字段 when 值 then 返回值 when 值2 then 返回值2 end
--举例
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
--Case搜索函数
case when 条件1 then 返回值1 when 条件2 then 返回值2 end
--举例
CASE WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END
# 循环结构
# while loop repeat
# iterate 相当于 CONTINUE
# leave 相当于 break
/*
给循环起名字是为了循环控制,也就是 iterate leave
【循环名字:】WHILE 循环条件 DO
循环体
END WHILE【循环名字】;
*/
CREATE PROCEDURE test_while(IN insertCount INT)
BEGIN
DECLARE i INT DEFAULT 10;
a:WHILE i<=insertCount DO
INSERT INTO student VALUES(i,'1',i);
if i>=15 THEN LEAVE a;
END IF;
SET i=i+1;
END WHILE a;
END;
CALL test_while(12);
存储过程/函数
现在的公司用的可能不多
变量
- 系统变量:全局变量、会话变量
变量由系统(mysql)提供,不是用户定义
会话变量仅仅对于当前会话(连接)有效
# 查看全局系统变量
SHOW GLOBAL VARIABLES;
# 查看会话系统变量 [SESSION]
SHOW SESSION VARIABLES;
# 按条件查询,查的是name
SHOW GLOBAL VARIABLES LIKE '%char%';
# 为系统变量赋值
SET 系统变量名=值;
- 自定义变量:用户变量、局部变量
# 用户变量
# 作用域:针对当前会话(连接)有效
# 声明并初始化/更新,使用就是select @用户变量名
SET @用户变量名=值;
SET @用户变量名:=值;
SELECT @用户变量名:=值;
# 局部变量
# 作用域:仅在定义它的begin、end中有效(只能在其中使用,且必须是第一行)
# 声明
DECLARE 变量名 类型;
DECLARE 变量名 类型 DEFAULT 值;
# 赋值,查询 SELECT 局部变量名
SET 局部变量名=值;
SET 局部变量名:=值;
SELECT @局部变量名:=值;
存储过程
# 如果存储过程只有一句话,BEGIN AND可以省略
CREATE PROCEDURE 存储过程名(param)
BEGIN
END
# 参数列表包含参数模式、参数名、参数类型
IN stuname VARCHAR(20)
# 参数模式 in out inout
# in 需要调用方传入值
# out 返回值
# 调用
CALL 存储过程名(实参列表);
# 无参
SELECT * FROM student;
DELIMITER $
CREATE PROCEDURE inset_data()
BEGIN
INSERT INTO student(sid,sname,tid) VALUES(7,'房思琪',7),(8,'周星星',8);
END $
CALL inset_data()
# 输入参数
CREATE PROCEDURE select_stu(in t_id int)
BEGIN
SELECT * FROM student WHERE tid=t_id;
END;
CALL select_stu(1);
# 存储过程中定义变量
CREATE PROCEDURE select_stu_sname(in t_id int)
BEGIN
DECLARE result VARCHAR(10) DEFAULT '';
SET result = (SELECT sname FROM student WHERE tid=t_id);
SELECT result;
END;
CALL select_stu_sname(1);
# out
CREATE PROCEDURE select_stu_sname3(in t_id int,out sname2 varchar(10))
BEGIN
SELECT sname into sname2 FROM student WHERE tid=t_id;
END;
CALL select_stu_sname3(1,@sname);
SELECT @sname;
# inout
CREATE PROCEDURE double2(INOUT a INT,INOUT b INT)
BEGIN
SET a=a*2;
SET b=b*2;
END
SET @a =1;
SET @b =2;
CALL double2(@a,@b);
SELECT @a,@b;
# 删除
DROP PROCEDURE 存储过程名;
函数
存储过程和函数的区别
- 存储过程可以有0/多个返回值,函数有且仅有一个返回值
- 函数可以返回一个表对象,因此它可以在查询语句中位于FROM关键字的后面。 SQL语句中不可用存储过程,而可以使用函数。
# 1. 参数列表包含 参数名 参数类型
# 2. 函数体必须包含 return ,否则会报错
# 3. 函数体中仅有一句话,则可以省略begin end
# 4.
CREATE FUNCTION 函数名(参数列表) RETURNS 返回类型
BEGIN
函数体
END
# 调用语法
SELECT 函数名(参数列表)
# 实例
CREATE FUNCTION func_select_stu2(s_id int) RETURNS INT
BEGIN
DECLARE c INT DEFAULT 0;
SELECT count(*) INTO c FROM student;
RETURN c;
END
select func_select_stu2(1);
# 查看函数
show create function 函数名;
# 删除函数
drop function 函数名;
视图
当数据库的表结构比较复杂,在关联查询或者子查询的语句比较多的时候,经常会用到一些查询的结果集。
如果多个不同的业务,不同的sql,中间有一些结果集是重复的,我们就可以使用视图,给它虚拟成一张表。
下次执行的时候相当于我们从这个视图里查询就可以了。
视图并不会带来更好的性能,但是会增强代码的可读性。

部分知识引用自:
https://blog.csdn.net/fanbaodan/article/details/84304782
https://blog.csdn.net/dz77dz/article/details/115111559
https://blog.csdn.net/jinjiniao1/article/details/92666614
https://www.bilibili.com/video/BV1N24y1y7a1?p=15&vd_source=64c73c596c59837e620fed47fa27ada7
别说在哪儿!一知道在哪儿,世界就变的像一张地图那么小了
《三体 黑暗森林》