Linux centos7 for循环与文件倒序
当需要对文件进行倒序显示时,应用查看文件命令tac可以达到目的,简约而有效!
本文讨论for循环与文件倒序显示或输出,出发点是项目引领学习,训练逆向思维,归纳整合知识点。
一、学习思维
作为以项目为引领的学习方法,实现目标并不重要,而在于追求目标的过程中采用的方法与技巧,命令的理解与拓展,剖析的角度与层次。
本文简单介绍了如何对文件进行倒序输出,其实也就是介绍命令使用的一种思路,对于实际工作中不一定会使用,重要的是遇到问题知道怎么多角度分析解决。
倒序输出文件,用到如下知识点:空格与换行符,排序与分割,文件查看,文件重定向和数据存取等。
二、项目剖析
1.文件结构
文件由行构成,行与行之间用分隔符相区分。每行都有一个序号相对应,隐形而存在,与需要相关,是行的附加属性。
我们用cat命令可以查看文件全部内容,加选项可以显示行号。
而用head -2命令可以查看前面两行内容,用tail -2命令可以查看最后两行内容。
我们以数组的观点分析文件,文件名就是数组名,各行就是数组的值:有序、不同、字符化!
2.循环语句
以循环的观点理解查看文件,就是每次从文件中取出第一行,在标准输出中显示。第二次循环,再取出、显示。多次重复此过程,直至最后一行结束。
在循环过程中获取的数据需要存放,或有效处理。
sed流编辑器,有保持空间。sed流编辑器主要是在模式空间中处理数据与读取行和输出处理结果。而需要时,可以在保持空间暂时保存未处理的数据、已处理的数据等。
vi或vim编辑器,有无名寄存器及许多临时寄存器,系统剪切板,可以存放变量、数据等字符。
在编程中,可以用变量存储少量数据,存放大量数据就要借助数组或数据库了。一般编程中,把读取的行内容存入一个变量中,如果再存放数据就会覆盖原数据。而一个数组,可以有顺序存放、可以追加数据,仅要求数据类型一致。
在命令行中,可以采取新的思路,就是获取一行数据就追加到一个文件中去,读取行内容就是用一个或多个命令在文件中操作,而采用另外命令及时追加到新文件,一行一次,循环读、存。
四种方式,就有四类方法。本文重点梳理第四种命令行方式。
这个读存过程包括三部分:
a.循环读取行数据
b.行数自动加1(或减1)
c.循环添加行数据到新文件
3.方法与思路
a.追加到文件
对于利用for循环边读取数据边追加到另一文件中,思路清晰,方法是否可行?
理论上是可行的,有两种读取方式,对应两种存放方法。
(1)我们从原文件的第一行开始读取,放在另一新文件的首行。第二次读取原文件的第二行,仍然存放在另一新文件的首行(这时,新文件有了两行,原来的行变为第二行,新加入的行仍然为第一行)。循环进行多次,直至循环次数等于行的数量时全部完成。
(2)我们获取文件从尾部开始,倒序取行,追加到另一文件后,就会行号反转:最后一行变为新文件的第一行。读取的原文件的倒数第二行成为新文件的正数第二行。边取边追加,直至全部完成。
后面,我们将分别讨论两种情况。
b.正向读取行数据添加到新文件的前面
我们获取行数据从前向后,方便易懂,是for循环默认方式,追加到文件也好处理,用(追加)重定向 >> 新文件即可。
主要问题是如何把行数据添加到新文件的前面?
(1)可以用sed命令:
sed -i '1i $line' newfile
(2)可以用while命令
先设置 计数i=0
while read line 读第1行
i++ 行数加1
(3)可以用cat命令
我们读取一行数据,重定向为一个文件file1;我们再读取第二行数据,重定向为一个文件file2。原文件有多少行,就重定向为多少个文件file*。
我们可以用cat命令同时查看多个文件,重定向为一个文件file0,可以理解为组合多行数据为一个新文件(倒序排放)。
如何保证重定向后的文件按需求组合呢?可以把文件file*排序,按数字反向排序,如下,具体选项的含义可自选方式查看sort命令帮助。
ls file* |sort –k1.5nr
c.反向读取行数据追加到新文件的后面
在此方法中,重点是如何反向读取文件各行!
我们的思路就是:从原文件的最后一行读取,把行内容追加到一个新文件中,循环执行。
追加没问题,有对应的命令与操作符;重点是如何倒序一行一行读。
我们可以利用head和tail命令实现。在此之前,必须先计算出文件有多少行,这就用到wc命令,这是统计文件有多少字符,多少单词,多少行的重要命令。加选项–l是统计文件行数。
三、命令实现
1.正序读取文件行,倒序合并文件行
从一个文件的第一行开始,每次取一行;获取的行总是添加到一个新文件的首行;循环完成后,从原文件全部取出每行,新文件是原文件的倒序内容。
a.方法
把获取的行重定向为一个文件file1;
再获取再重定向为另一个文件file2;
后面进入循环:取出;重定向,再cat文件
命令可以这样实现:
i=0
for line in `cat 文件名`
do
echo $line >file$i
let i++
cat $line(这个是新的一行) file$i(这个是上一行产生的) > file$((i+1))
done
前面echo和cat两行代码不能处于同一次循环中!
echo行代码的目的是把读取的文件重定向为一个文件,可以理解为暂时保存读取的数据。
cat行代码合并才是我们的目的。能否把echo行直接插入到本行代码中呢?
认真分析后可知,echo行没有标准输出,只有重定向,就不能用管道送入下一条命令。应用管道的原理只能是对标准输出的内容再处理一次!
多次合并比较麻烦,我们能否仅循环读取、循环重定向,一次合并呢?答案是完成可以。
b.案例
现有文件test
cat test
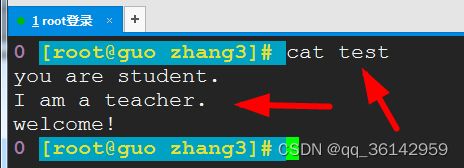
为了论证方法,我们只录入三行内容。
主要代码
oldifs=$IFS;IFS=$'\n';len=`cat test|wc -l`;j=1;for line in $(cat test);do echo $line >file$j;let j++;done;IFS=$oldifs
生成三个重定向文件

合并重定向的所有文件

基本达到目的。
可以再重定向为一个新文件file0,查看文件,是原文件的倒序排列。

完整代码
oldifs=$IFS;IFS=$'\n';len=`cat test|wc -l`;j=1;for line in $(cat test);do echo $line >file$j;let j++;done; cat `ls file* -r` >file0; IFS=$oldifs
注意:一般是不修改IFS(文件换行符变量),以免系统显示有误,先把IFS值定义给oldifs,运行完程序后,再把默认的IFS值还原。
理解此方法的处理,可以看出数组的重要性,以及保持空间或寄存器的必要性!
2.反序读取文件行,追加文件行到新文件
反序读取文件的各行,首先计算出文件有多少行len=?,再查看前len行,用查看尾部文件命令tail再查看后面的行内容。如果加行数选项–n 1就是查看最后面的一行。循环查看,就可以实现反序查看文件,读取文件。追加文件行简单,用>>。
主要代码
先计算文件有多少行
len=`cat 文件名 |wc –l`
再读取文件的前len行
head -n $len 文件名
最后查看倒数第1行
tail -1
把此代码写入循环,就实现了全文件反向读取。
案例
现有文件test
cat test

完整代码
len=`cat test |wc -l`;for((i=len;i>0;i--));do echo `head -n $i test |tail -1`;tee >>test1;done
注意:查看文件内容后,可以输出到屏幕,也可以重定向一个文件,同时达到两项需求,要用到命令tee。
总结
如何取数据,如何存数据,是考验个人逻辑思维的能力;而用代码语言表达个人思路,是命令学习是否扎实,会否组织代码进而编程的试金石。多锻炼,才会有收获,而终至成功。
用vim命令,编辑两个文件,也可以达到合并文件的目的。但vim是交互式处理文件,需要打开vim,编辑、保存,此过程不能用命令自动完成。
而sed是流编辑器,就是把文件、行、字符串等看作数据流,送到sed中,加工处理,空毕后,自动送出结果。sed加工处理的方法用‘模式表达式‘告诉sed,如:是否静默打印,用添加参数-n与否确定;是否修改原文件,用添加参数-i与否确定。
ex是比较古考的行编辑器,在vim中仍然使用,也属于交互式编辑方式。
最简单最易懂的是多条命令实现一个功能。
执行循环的过程,是理解命令与实现功能的最好方法。