Prometheus入门与实战
1.Prometheus介绍

1.什么是监控?
从技术角度来看,监控是度量和管理技术系统的工具和过程,但监控也提供从系统和应用程序生成的指标到业务价值的转换。这些指标转换为用户体验的度量,为业务提供反馈,同样还向技术提供反馈,指示业务的工作状态以及持续改进
监控不应该:
- 事后监控
- 监控的不完整
- 不正确的监控
- 静态监控
- 监测不够频繁
- 没有自动化
良好的监控应该提供:
- 整个架构的状态,从上到下
- 协助故障诊断
- 基础架构、应用程序开发和业务人员的信息源
应用程序监控有两种方法:
- 探测
- 自省
执行监控有两种方法:
- 推
- 拉
监测数据的类型主要由两种:
-
Metrics(度量)
-
度量是对软件或硬件组件属性的度量。为了使度量有用,我们跟踪它的状态,通常随时间记录数据点。这些数据点成为观测值。观测由值、时间戳以及有时描述观测的一系列数据(如源或标记)组成。观测的集合称为时间序列
-
类型:
- 仪表
- 计数器
- 直方图
- 摘要

-
-
度量总结:
- 通常,单个指标的值对我们来说并不有用。相反,度量的可视化需要对其应用数学变换。例如,我们可以将统计函数应用到我们的度量或度量组中。我们可以应用的一些常见功能包括:
-
Logs
良好的通知系统,要考虑
- 通知什么问题
- 谁来通知:alertermanager
- 如何通知
- 通知间隔
- 什么时候停止
2.Prometheus特点
普罗米修斯的主要特点是:
- 支持多维数据模型有指标名称和键值对标识的时间序列数据
- 内置时间序列库TSDB(Time Serices Database)
- 支持PromQL(Prometheus Query Language),对数据的查询和分析、图形展示和监控告警
- 不支持分布式存储;单个服务器节点是自治的
- 只是HTTP的拉取方式收集时间序列数据
- 通过中间网关Pushgateway推送时间序列
- 通过服务发现或静态配置两种方式发现目标
- 支持多种可视化和仪表盘,如:grafana


3.核心组件
- Prometheus Server:主要用于抓取数据和存储时序数据,另外还提供查询和Alert Rule配置管理
- Client Libraries:用于检测应用程序代码的客户端库
- pushgateway:用于批量,短期的监控数据的汇总节点,主要用于业务数据汇报等
- exporters:收集监控样本数据,并以标准格式向Prometheus提供。例如:收集服务器系统数据的node_exporter,收集MySQL监控样本数据的是MySQL exporter等
- 用于告警通知管理的alertmanager
4.基础架构
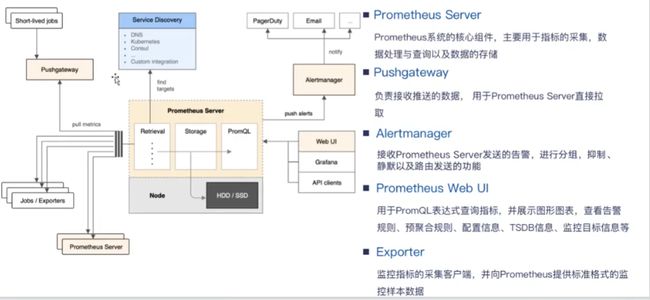
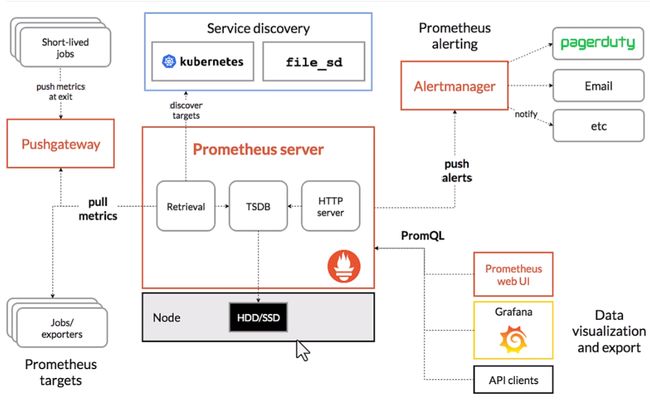
- Prometheus server定期从静态配置的targets或者服务发现的target拉取数据(Targets是Prometheus采集Agent需要抓取的采集目标)
- 当新拉取的数据大于配置内存缓冲区的时候,Prometheus会将数据持久化到磁盘(如果使用remote storage将持久化到云端)
- Prometheus可以配置rules,然后定时查询数据,当条件触发的时候,会将alerts推送到配置的Alertmanager
- Alertmanager收到警告的时候,可以根据配置,聚合,去重,降噪,最后发送警告
- 可以使用API,Prometheus Console或Grafana查询和聚合数据
- METRIC集合:为了获取端点,普罗米修斯定义了一个称为目标的配置,称为Scrape(刮刮)
- 服务发现:
- 用户提供的静态资源列表
- 基于文件的发现-例如:使用配置管理工具生成在Prometheus中自动更新的资源列表
- 自动发现
- 聚合和提醒
- 服务器还可以查询和聚合时间序列数据,并可以创建规则来记录常用的查询和聚合。这允许从现有的时间序列中创建新的时间序列
- 普罗米修斯也可以定义警报规则,但没有内置警报根据,而是通过外在的Alertmanager
- 查询数据:Prometheus服务器也提供了内置的查询语言PromQL;一个表达式浏览器;以及一个图像界面,可以使用它来查询服务器上的数据
- Prometheus采集数据需要依赖采集客户端
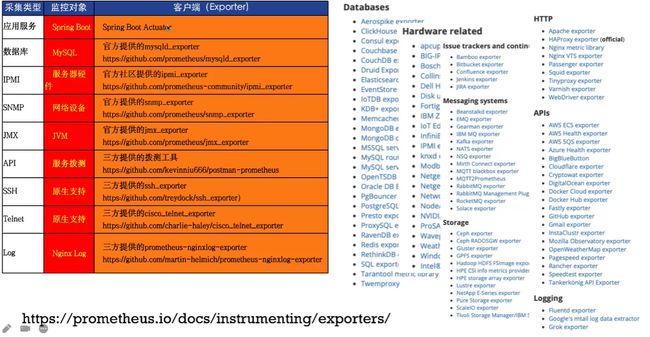
5.Prometheus数据及安全模型
-
Metric名字
- 时间序列的名称通常描述收集的时间序列数据的一般性质–例如:website_visits_total作为网站访问数。名称可以包含ASCII字母、数字、下划线和冒号


-
标签
- 以__为前缀的标签名称保留给Prometheus内部使用

-
Metric保留时长
- Prometheus是为短期监视和警报需求而设计的。默认情况下,它在本地数据库中保存15天的时间序列。如果想保留更长时间的数据,建议的方法是将所需要的数据发送到远程的第三方平台。Prometheus具有向外部数据存储写入的能力
-
安全模型

6.Prometheus与Zabbix的对比

2.Prometheus安装
Prometheus下载地址
# 下载二进制包
wget https://github.com/prometheus/prometheus/releases/download/v2.45.1/prometheus-2.45.1.linux-amd64.tar.gz
# 将命令复制到bin目录下
cp prometheus promtool /usr/local/bin
# 启动服务
mkdir /etc/prometheus
cp prometheus.yml /etc/prometheus/
promtool check config /etc/prometheus/prometheus.yml
prometheus --config.file /etc/prometheus/prometheus.yml --web.enable-lifecycle
# 热配置,默认是关闭的,需要--web.enable-lifecycle参数开启
curl -X POST http://localdns:9090/-/reload
kill -HUP pid
3.使用Node-exporter监控节点
# 安装Node-exporter
wget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz
# 复制命令
cp node_exporter /usr/local/bin
# 配置文本文件收集器
mkdir -p /var/lib/node_exporter/textfile_colletor
echo 'metadata{role="docker_server",datacenter="N"}1'|sudo tee /var/lib/node_exporter/textfile_colletor/metadata.prom
# 运行节点导出器
node_exporter --collector.textfile.directory /var/lib/node_exporter/textfile_colletor/ --collector.systemd --collector.systemd.unit-whitelist="(docker|ssh|rsyslog).service" --web.listen-address=":9600" --web.telemetry-path="/node_metrics"
#--collector.textfile.directory /var/lib/node_exporter/textfile_colletor/:这个选项告诉 node_exporter 从 /var/lib/node_exporter/textfile_colletor/ 目录中读取 textfile collector 的数据。
#--collector.systemd:这个选项启用了 systemd collector,它可以收集有关 systemd 的信息。
#--collector.systemd.unit-whitelist="(docker|ssh|rsyslog).service":这个选项配置了 systemd collector,使其只收集特定的 systemd 单元的信息,即 docker、ssh 和 rsyslog。
#--web.listen-address=":9600":这个选项设置了 node_exporter 的监听地址,使其在 9600 端口上接收请求。默认监听9100
#--web.telemetry-path="/node_metrics":这个选项设置了暴露指标的 HTTP 路径为 /node_metrics
1.监控docker

2.metrics过滤
- 可以在配置文件中使用
params参数对获取指标进行过滤
- job_name: 'node'
metrics_path: '/node_metrics'
static_configs:
- targets: ["192.168.19.133:9600"]
params:
collect[]:
- cpu
- meminfo
4.标签的使用
在一个几种、复杂的监视环境中,有时无法控制正在监视的所有资源以及他们公开的监视数据。重新标记允许在环境中控制、管理和潜在的标准化度量。一些最常见的用例是:
- 删除不必要的指标
- 从指标中删除敏感或不需要的标签
- 添加、编辑或修改指标的标签值或标签格式
有两个阶段可以重新命名。第一阶段是重新标记来自服务发现的目标。这对于将来自服务发现的元数据标签的信息应用到度量上的标签非常有用。这是由作业内部的relabel_configs块中完成
第二个阶段是在scape之后,但在保存到存储系统之前。这使我们能够确定我们保存了那些指标,删除了那些指标,以及这些指标将是什么样子。这在metric_relabel_configs中完成
1.删除metrics
- job_name: 'node'
metrics_path: '/node_metrics'
static_configs:
- targets: ["192.168.19.133:9600"]
metric_relabel_configs:
- source_labels: [__name__] # 匹配的标签
separator: ";" # 分隔符
regex: "(memory|node_memory_MemTotal_bytes)" # 匹配的正则,如果指定了多个源标签,那么需要用分隔符分开正则
action: drop # 执行的动作,默认为覆盖
2.更换标签
- job_name: 'node'
metrics_path: '/node_metrics'
static_configs:
- targets: ["192.168.19.133:9600"]
metric_relabel_configs:
- source_labels: [id]
regex: '/kubepods/([a-z0-9]);'
replacement: '$1' # 将正则匹配的第一个括号中的内容保存到这,并将结果存储到新标签中
target_label: container_id
3.删除标签
- job_name: 'node'
metrics_path: '/node_metrics'
static_configs:
- targets: ["192.168.19.133:9600"]
metric_relabel_configs:
- source_labels: [id]
regex: '/kubepods/([a-z0-9]);'
action: labeldrop
5.监控
1.监控CPU

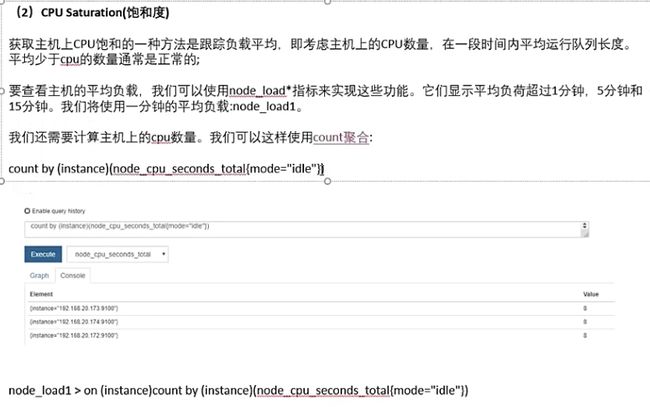
2.监控内存


3.向量匹配
6.规则记录
# 在/etc/prometheus下创建rules目录
mkdir rules
# 在配置文件中修改
rule_files:
- rules/node_rules.yml
# 添加记录预聚合规则
# 命名规则:level:metric:operations
instance:node_cpu:avg_rate5m

7.服务发现
手动配置监控目标显然不适合我们大批量监控节点,特别是kubernetes
Prometheus通过服务发现解决这个问题,自动机制来检测、分类和识别新的和变更的目标。可以通过以下三种方式:
- 通过配置管理工具填充的文件接收目标列表
- 查询API(如Amazon AWS API)以获取目标列表
- 使用DNS记录返回目标列表
1.基本文件发现
基于文件的发现只是比静态配置更高级的一小步,但是它对于配置管理工具的配置非常有用。通过基于文件的发型,普罗米修斯使用文件中指定的目标。这些文件通常由另一个系统生成,例如配置管理系统,如Puppet、Ansible,或者从另一个源(如CMDB)查询。定期运行脚本或查询,或触发他们(重新)填充这些文件。然后,普罗米修斯按照指定的时间表从这些文件中重新加载目标
这些文件可以是YAML格式或JSON格式,并包含定义的目标列表
- job_name: 'node'
metrics_path: '/node_metrics'
file_sd_configs:
- files:
- targets/nodes/*.json
refresh_interval: 1m
metric_relabel_configs:
- regex: node
# 文件
[
{
"targets": [":9100" ],
"labels": {
"datacenter": "dc1",
"role": "database"
}
},
{
"targets": [":9100" ],
"labels": {
"datacenter": "dc2",
"role": "webserver"
}
}
]
2.DNS服务发现
DNS服务发现依赖于A、AAAA或SRV DNS记录
dns_sd_configs:
- names: ['_prometheus_tcp.xiaodi.cn'] # 基于SRV
# _prometheus为服务名称
# _tcp为协议名
# xiaodi.cn为域名
dns_sd_configs:
- names: ['cc.xiaodi.cn']
type: A
port: 9100
8.告警
普罗米修斯是一个划分的平台,度量的收集和存储与报警时分开的。警报由Alertmanager工具提供,这是监视环境的独立部分。警报规则是在Prometheus服务器上定义的。这些规则可以触发事件,然后将其传播到Alertmanager。Alertmanager随后决定如何处理各自的警报,处理复制之类的问题,并决定在发送警报时使用什么机制:实时消息、电子邮件或其他工具

# 下载Alertmanager
wget https://github.com/prometheus/alertmanager/releases/download/v0.26.0/alertmanager-0.26.0.linux-amd64.tar.gz
mkdir -pv /etc/alertmanager
# 配置
global:
smtp_smarthost: 'smtp.qq.com:25'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'bhqhzqawgqcueafj'
smtp_require_tls: false
route: # 设定路由,接受者是mail
receiver: mail
receivers: # 定义接收者详细信息,发送给谁
- name: 'mail'
email_configs:
- to: '[email protected],[email protected]' # 可以写多个邮箱,用逗号隔开
# 启动服务
alertmanager --config.file /etc/alertmanager/alertmanager.yml
# 在Prometheus上添加Alertmanager
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.19.133:9093
# 对Alertmanager进行监控
- job_name: alertmanager
static_configs:
- targets: ['192.168.19.133:9093']
# 设置报警触发规则
groups:
- name: node_alerts
rules:
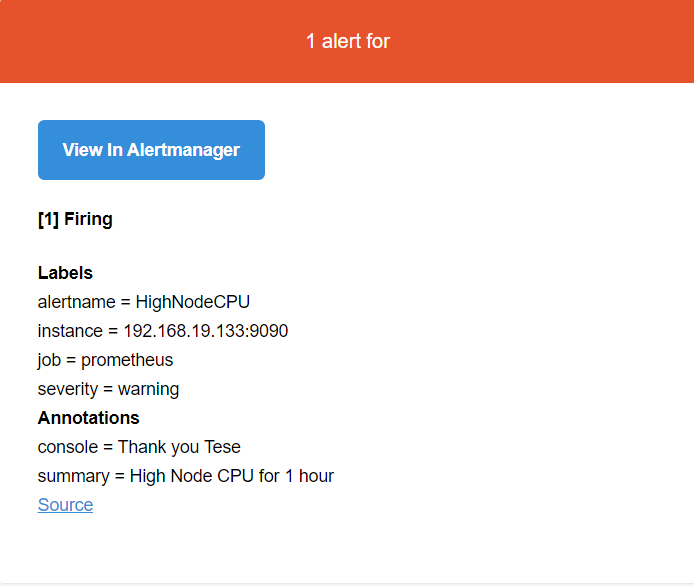
- alert: HighNodeCPU # 警报名称
expr: instance:node_cpu:avg_rate5m > 4 # 触发表达式
for: 1m # 持续这么长时间才报警
labels: # 标签
severity: warning
annotations: # 注解
summary: High Node CPU for 1 hour
console: Thank you Tese
# 浏览器进入192.168.19.133:9093能对Alertmanager进行查看


Prometheus也能使用模板语言

1.路由
route:
group_by: ['instance'] # 以什么分组
group_wait: 30s # 等待该组的报警,有报警后等待30s再发出
group_interval: 5m # 下一次报警时间
repeat_interval: 3h # 重复报警时间,下一次实际报警实践为 group_interval+repeat_interval
receiver: email
routes:
- match:
severity: critical
receiver: pager
- match_re:
severity: ^(warning|critical)$
receiver: support_team
receivers:
- name: 'email'
email_configs:
- to: ''
- name: 'support_team'
rmail_configs:
- to: ''
- name: 'pager'
rmail_configs:
- to: ''
2.静默配置
静默设置在Alertmanager中进行设置,如果要使用正则需要再前面加上~,如alertname=~“High.*”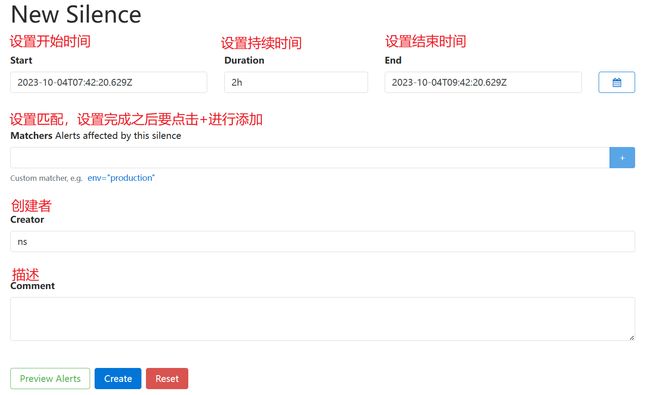

9.高可用
Prometheus作为一个单一的服务器,只有一个Alertmanager。这适用于很多监控场景,但通常不会扩展到多个团队上,当Prometheus或Alertmanager超载或出现故障,监控就会失效
这些问题分为:
- 可靠性和容错能力
- 扩展
Prometheus侧重于实时监控,通常只有有限的数据保留,而配置则被认为是由配置管理工具管理的。从可用性的角度来看,一个单独的Prometheus服务器通常被认为是一次性的。普罗米修斯体系结构认为,实现这个集群所需的投资,以及该集群节点之间数据的一致性,都高于数据本身的价值
不过,普罗米修斯并没有忽视解决容错问题的必要性。实际上,Prometheus推荐的容错解决方案是并行运行两个相同配置的Prometheus服务器,他们都处于活动状态。此配置生成的重复警报在Alertmanager中使用其分组(及其抑制功能)在上游处理。建议的方法不是关注Prometheus服务器的容错能力,而是让下游的Alertmanager容错

这是通过创建Alertmanager集群实现的。所有的Prometheus服务器会向所有的Alertmanager发送警报。Alertmanager负责重复数据删除,并通过集群共享警报状态
这种方法的缺点是,首先,两个Prometheus服务器将收集指标,它们产生的潜在负载将增加一倍。其次,如果一个单独的Prometheus服务器出现故障,那么一个服务器上的数据就会出现缺口。这意味着在查询服务器上的数据时要注意这个差距。PromQL中有一些方法可以弥补这一点。例如。当从两个源请求单个度量值时,可以使用两个度量值的最大值。或者,当从一个具有可能得间隙的单个工作碎片发出警报时,可能会增加for子句,确保有多个度量
1.Alertmanager集群
在Prometheus的Alertmanager中,使用集群模式有以下几个好处:
-
高可用性:如果一个Alertmanager实例发生故障,其他实例可以继续处理警报。这对于需要24/7监控的关键系统来说非常重要。
-
负载均衡:在高负载情况下,警报可以在多个Alertmanager实例之间进行分配,从而提高处理能力。
-
冗余:每个Alertmanager实例都会存储所有的警报和静默状态,即使某个实例发生故障,也不会丢失数据。
-
灵活性:你可以根据需要增加或减少Alertmanager实例,以适应你的监控需求的变化。
# 所有节点配置必须一样
alertmanager --config.file /etc/alertmanager/alertmanager.yml --cluster.listen-address 192.168.20.174:8001
alertmanager --config.file /etc/alertmanager/alertmanager.yml --cluster.listen-address 192.168.20.173:8001 --cluster.peer 192.168.20.174:8001

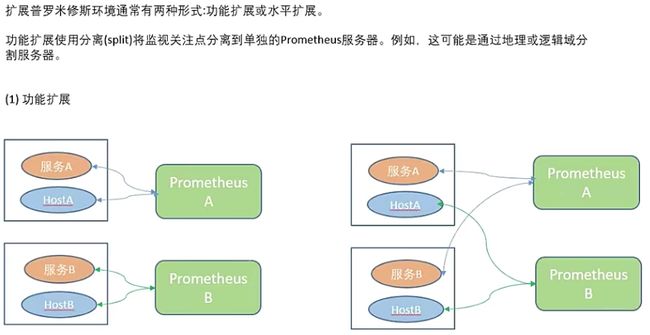
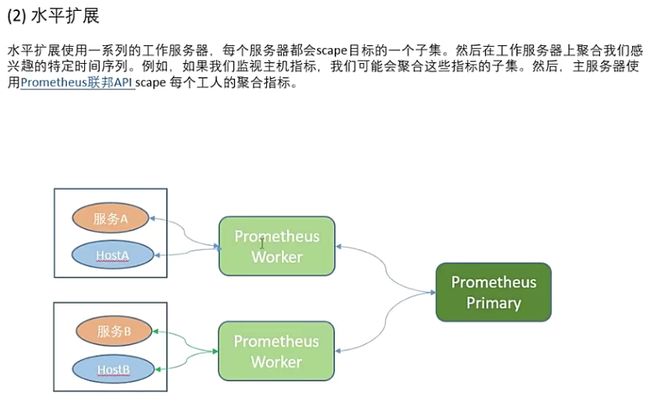
2.prometheus集群
10.探测
探测监视探测应用程序的外部。可以查询应用程序的外部特征:它是否响应开放端口上的轮询并返回正确的数据或响应代码?探测监视的一个示例是执行ICMP或echo检查并确认收到了响应。这种类型的探测也被成为黑盒监控。
Prometheus探测工作时通过运行一个blackbox exporter–来探测远程目标,并公开在本地端点上收集的任何时间序列,然后,普罗米修斯的工作从端点中提取任何指标
探测有三个限制:
- 需要能够达到探测的资源地
- 探测的位置需要测试到资源的正确路径
- 探测exporter的位置需要能够被Prometheus scape
通常将探测定位在组织网络之外的位置,以确保最大限度的覆盖故障检测和收集相关应用程序用户体验的数据
由于在外部部署探测的复杂性,如果需要广泛分布探测,通常将这些探测外包给第三方服务。
1.使用blackbox exporter
blackbox导出器是一个在Apache 2.0许可下许可的二进制GO应用程序。导出器允许通过HTTP、HTTPS、DNS、TCP和ICMP探测端点。它的结构与其他导出器不同。在导出器中,定义了一些列执行特定检车的模块,例如:检查正在运行的web服务器,或者DNS记录解析。当导出程序运行时,它会在URL上公开这些模块和API。普罗米修斯将运行在这些目标上的目标和特定模块作为参数传递给URL。导出器执行检查并将结果返回给普罗米修斯
# 下载
wget https://github.com/prometheus/blackbox_exporter/releases/download/v0.24.0/blackbox_exporter-0.24.0.linux-amd64.tar.gz
# 创建目录
mkdir /etc/prober
# 复制配置文件
cp blackbox_exporter/blackbox.yml /etc/prober/
# 配置
modules:
mysql_check:
prober: tcp
timeout: 5s
tcp:
query_response:
- send: "SELECT 1"
expect: "1"
# 配置Prometheus
- job_name: 'http_probe'
metrics_path: '/probe' # 默认为/probe
params:
module: [mysql_check]
static_configs:
- targets:
- 192.168.19.133:3306 # 目标地址为要探测的地址
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.19.133:9115
# 启动
blackbox_exporter --config.file /etc/prober/blackbox.yml
11.PushGateway
Prometheus的设计理念是基于拉取模式,而不是推送模式。这意味着Prometheus服务器会定期从被监控的服务中拉取指标。这种设计有几个优点:
- 简化了被监控服务的配置:在推送模式中,每个被监控的服务都需要知道Prometheus服务器的位置,并且需要配置如何将指标发送到Prometheus服务器。在拉取模式中,被监控的服务只需要提供一个HTTP端点来公开它们的指标,而Prometheus服务器则负责发现这些服务并从它们那里拉取指标。
- 提供了更好的可靠性:在推送模式中,如果Prometheus服务器出现故障,被监控的服务可能会因为无法发送指标而受到影响。在拉取模式中,即使Prometheus服务器出现故障,被监控的服务也可以继续运行。
- 更容易进行扩展和复制:在拉取模式中,你可以简单地添加更多的Prometheus服务器来拉取相同的指标,以实现负载均衡和冗余。
在某些Prometheus不能拉取到指标的场景,原因有:
- 由于安全性和连通性,无法到达目标资源。当服务或应用程序只允许进入特定端口或路径时
- 目标资源的生命周期太短–例如:容器的启动、执行和停止
- 目标资源没有可以scape的端点,例如批作业。批处理作业不太可能具有可以scape正在运行的HTTP服务
以上无法拉取到指标的场景可以使用Pushgateway解决
Pushgateway是一个独立的服务,Pushgateway位于应用程序发送指标和Prometheus服务器之间。Pushgateway接收指标,然后将其作为目标被Prometheus服务器拉取。可以看做是一个代理服务器
Pushgateway本质上是一个监控资源的工作区,由于特殊原因有一些资源无法被Prometheus服务器scape。网关并不是一个完美的解决方案,应该只作为有限的解决方案使用,特别是用于监控否则无法访问的资源
过度使用Pushgateway可能会带来一些问题,例如:
-
当通过单个Pushgateway监视多个实例时,Pushgateway可能会成为单点故障和潜在的瓶颈。
-
你会失去Prometheus通过up指标(在每次抓取时生成)自动进行实例健康监控的能力。
-
Pushgateway永远不会忘记推送到它的指标,并将永远向Prometheus公开这些指标,除非这些指标通过Pushgateway的API手动删除。
应该将网关集中于监控短生命周期资源
1.Pushgateway
# 下载
wget https://github.com/prometheus/pushgateway/releases/download/v1.6.2/pushgateway-1.6.2.linux-amd64.tar.gz
# 启动,并指定持久化文件
Pushgateway --web.listen-address="0.0.0.0:9091" --persistence.file='/tmp/push.data'
# 可以访问web端
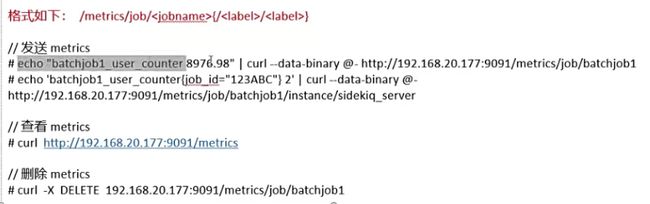
12.PromQL
PromQL是Prometheus提供的一种查询语言,查询与聚合汇总指标数据,用于数据图标展示,并且通过HTTP API暴露给外部系统查询
一种嵌套的函数式语言,里层表达式的值用作外部表达式的参数或操作数

查询类型:
- 即使查询:通过顺势向量选择器,查询给定时间戳的时间序列样本数据
- 范围查询:通过范围向量选择器,查询距离当前时间戳的一段时间范围内的序列样本数据

- 时间单位

- 算术运算符

- 比较运算符

- 逻辑运算符

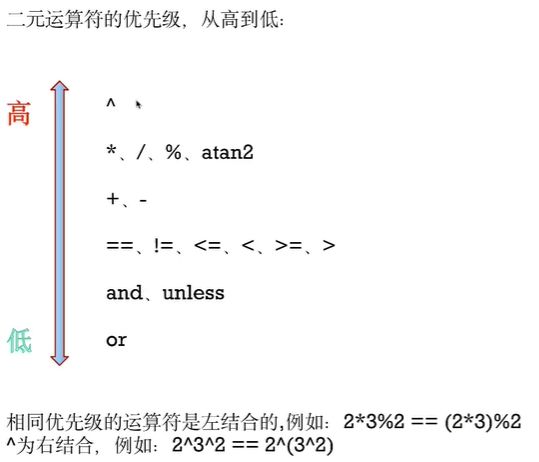
- 向量匹配


- 聚合运算


13.自定义exporter
from prometheus_client import start_http_server, Metric, REGISTRY
import time
import random
class CustomCollector(object):
def collect(self):
metric = Metric('my_custom_metric', 'This is my custom metric.', 'gauge')
metric.add_sample('my_custom_metric', value=random.random(), labels={})
yield metric
if __name__ == '__main__':
# 注册自定义收集器
REGISTRY.register(CustomCollector())
# 启动http服务器,端口为8000
start_http_server(8000)
# 模拟请求处理
while True:
time.sleep(1)