NHibernate变的简单
前言
这篇文章出自于我尝试学习使用Nhiberbnate的挫败感。我发现好像Nhibernate全部的介绍材料不是很模糊就是太详细。我所需要的就是一个简单直接的教程,能让我尽快对NHibernate熟悉起来。我从来没有找到。幸运的是,这篇文章将会满足别人的这些需求。
这篇文章有些长,但是我鼓励你以你的方式来阅读。NHibernate是一个复杂的程序,是一个绵延曲折的学习过程。这篇文章将为你踏平曲折,从几天或是几周缩短到几个小时。
问题
NHibernate目的是解决一个众所周知的问题,对象持久代码在开发过程中的瓶颈问题。很多文章表明:1/4到1/3的程序代码是关于对象持久化,从数据库中读取数据,和将数据写回数据库。代码是重复的,耗费时间的,还有很多琐碎的代码要写。
对于这个问题,有很多解决方案是可用的。代码生成可以在几秒钟生成数据访问代码。但是如果业务模型改变,这些代码需要重新生成。"对象关系映射"(ORMs)使用了一种新的方式,像NHibernate。他们管理数据访问更加透明,提供了很多简洁的API,可以使用一辆行代码来实现加载和保存整个对象。
介绍NHibernate
NHibernate是一个持久化引擎框架。它从数据库中加载业务对象,以及将这些对象的变化更新到数据库中。从文章上面可以看出,它可以只使用一两行代码实现业务对象的加载和保存。
NHibernate使用映射文件来引导从数据库数据到业务对象的转换。还有一种方法,你可以使用类的特性和属性来替代映射文件。为了让事情尽量简单,我们在这篇文章中将使用映射文件,而不是使用类特性。另外,映射文件能够很清晰的将业务逻辑和持久化代码分开。
好了,我们只需要在程序中添加几行代码,和为每一个映射文件创建持久化类,而且NHibernate可以照顾到所有的数据库操作。真不知道使用NHibernate将为我们节省多少开发时间。
记住在.NET环境下,NHibernate并不是唯一的ORM框架。有许多商业的和开源的产品可以提供这样的服务。NHibernate是其中最流行的,主要是因为他遗传自强大的Hibernate,一个Java环境下非常流行的ORM框架。另外,微软也为ADO.NET提供了"Entity Framework",来提供ORM服务。但是,这个产品已经延迟,好长时间已经没有再释放了。
安装NHibernate
使用NHibernate的第一步就是下载NHibernate和Log4Net(一个开源的日志记录程序,NHibernate使用它来记录错误和警告),NHibernate包含了Log4Net最新的版本,你也可以下载整个Log4Net安装包,这里是下载地址:
NHibernate不是直接需要Log4Net,可是在调试期间它的自动记录日志功能非常有用。
现在开始
在这篇文章中,我将使用一个简单的示例程序,而不是解说如何使用NHibernate来进行数据访问。这是一个控制台应用程序,通过消除UI代码让程序变的更加简单。这个程序将创建很多个业务对象,来使用NHibernate来对他们进行持久化,然后将他们从数据库中读取出来。
为了程序运行起来,你需要做一下几个事情:
- 为陈旭添加NHibernate和Log4Net的程序集引用
- 为程序添加数据库
- 修改数据库连接字符串
这个示例程序引用NHibernate和Log4Net。这些应用应该被你的机器识别,如果你的NHibernate和log4net安装在默认的目录里。如果这些引用不被识别,你可以分别使用NHibernate.dll和Log4Net.dll来替换引用位置。这些DLL文件可以在NHibernate的安装目录中找到。
这个示例程序是按照SQL Server Express 2005来配置的,数据库文件(NhibernateSimpleDemo.mdf和NhibernateSimpleDemo.ldf)已经打包在压缩文件里。你可以将数据库搭在你机器的SQL Server上。
最后,数据库的连接字符串配置在App.config文件中,默认你使用的是SQL Server数据库。你可以自己根据自己机器SQL Server的版本,来修改数据库的连接字符串。
业务模型
这里有两种方法使用NHibernate创建应用程序。第一种是“以数据为中心”的方法,它从数据模型和创建业务对象开始。第二种是“以对象为中心”的方法,从业务模型和创建数据库来持久化这个模型开始。这个示例程序使用以对象为中心的方式。
这里示例中的业务模型:
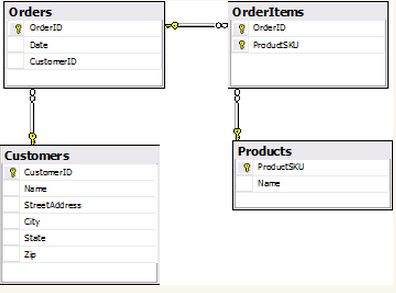
这个模型表现了一个订单系统的框架,这个模型是不完整的,这里只是使用了几个类来解说使用NHibernate对象持久化。显然这个模型的设计不能代表最佳实践,但是用来展示NHibernate是怎样工作的已经足够应付了。
此文将使用这个模型来解说使用NHibernate进行对象持久化的几个概念。
- 处理简单属性
- 处理Components
- 处理one-to-many
- 处理many-to-one
- 处理many-to-many
此文不会涉及高级主题,像继承。
这个模型由5个类组成,其中的4个是要持久化的类,非持久化类OraderSystem当做这个对象模型的宿主。我们将会在程序运行时初始化OrderSystem对象,然后我们将加载其他的对象到OrderSystem中来。
OrderSystem.Customers属性拥有销售者的客户列表,Customers可以通过CustomerID来访问,每一个Customer对象拥有一个ID,name,和address、一个序列的orders。address将被包成一个单独的Address类中。
Order类包含了一个订单的ID,时间,顾客信息,和许多购买的产品信息。
Product类包含ID,名称。
请注意我们只注重NHibernate是怎么工作的,程序初始化时,Product对象将被实例化放入OrderSystem.Catalog属性中,当一个订单被创建时,Product对象引用将不复制到Order.OrderItems属性中。
NHibernate一个强大的特点就是不需要为业务类实现特别的接口。事实上,业务对象通常不会担心被持久化机制来加载和保存他们。NHibernate使用的映射数据保存在分离的XML文件中。
数据库
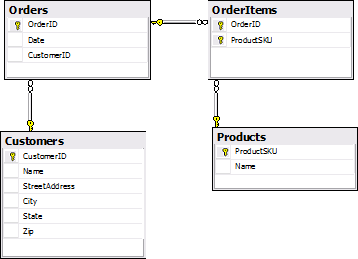
数据库和对象模型并不是完全匹配,对象模型中包含一个Address类,但是数据库中并没有与之对应的表。数据库中有OrderItems表,但是对象模型中并没有与之对应的持久化的类。这里的不匹配并不是故意的,我们想展示的NHibernate其中的一个概念就是这里并不需要数据库中的表跟类是一一对应的。
这里是为什么不完全匹配的原因:
- Address类并不能代表业务模型的一个实体,相反,它只代表一个实体的值,在这个示例中,代表Customer.Address 属性,我们将Address分离一个单独的类,这样我们可以解说什么叫NHibernate使用“Component mapping”。
- OrderItems表是多对多关系中Orders和Products的连接表,这样也不能代表对象模型中的一个实体。
Customer表包含了一个普通Customer信息的骨架,包含Customer的Address信息。最佳实践不会像我们这样,将会把Address分离在一个单独的表中。我们把Address信息保存在Customer表中,这样我们可以解释什么是NHibernate使用‘Components’类,而不使用Address自己的表,我们将在下面讨论Components的详细用法。
Orders表只包含一个订单的最简单的信息,只有ID,时间,和CustomerID。Orders和Customers之间的关系通过一个外键orders.ustomerID 列对应 Customer.ID列。
所有的订单学要一个多对多的关系(每一条订单包含很多条商品信息,每一条商品信息又被包含在很多订单里),所以我们需要OrderItems表来当作中介,简单的连接Order编号和Product编号。
这个数据库并不是一个最佳实践,它所包含的信息仅仅用来展示NHibernate是怎样工作的。
映射业务模型
许多介绍NHibernate的文章都是以配置文件开始的,但是从另一个地方开始:映射类。映射是NHibernate的核心,而且配置也给初学者一个很大的绊脚石。当我们讨论完映射,我们再回来介绍NHibernate的配置部分。
映射简单的指定哪一个表对应哪一个类。我们把映射的类对应的表叫这个类的“映射表”。
我们在上面就已经说了,Nhibernate不需要特定的接口或是特定的代码写在要映射的类里。但是它需要被声明成Virtual,这样可以在需要的时候创建代理。NHibernate文档里讨论了为什么这样,现在我们把所有业务模型中的类声明成Virtual。
映射可以同过分离的XML文件实现,也可以通过在类属性上添加特性来实现。被用于映射的XML文件可以在任何一个项目里引用。为了简单,我们将展示其中一个方法:通过XML文件映射,映射文件需要被编译成程序集的嵌入式资源。
你可以映射很多类在同一个映射文件中,但是通常都会为每一个类创建一个映射文件。这样可以保持映射文件的短小,而且容易阅读。
开始我们映射实验之前,先让我们看看Customer.hbm.xml文件。hbm.xml后缀的文件是NHibernate标准的映射文件的后缀。我们把映射文件放在Model文件下,但是我们可以把他们放在项目的任何一个地方。最关键的一点是将文件的 BuildAction 属性设置为 Embedden Resource(嵌入式资源)。这个设置将会把映射文件编译到程序集里,这样把他们从程序中脱离出来。
映射文件都是标准的格式:
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2"
namespace="NHibernateSimpleDemo"
assembly="NHibernateSimpleDemo">
第一个标签是XML声明,第二个标签定义了XML的命名空间,你可以在这里加入一个XSD信息。第二个标签还包含了属性信息,定义了映射文件要被使用在的程序集名称,这样可以让我们避免在映射标签里写所有的类名。
<class>标签
下一个标签用来识别我们需要映射的类:
<class name="Customer" table="Customers" lazy="false">
<class>标签的属性指定了要映射的类,以及它的映射表:
- name属性指定要映射的类名
- table属性指定类的映射表
- lazy属性告知NHibernate对这个类不用使用'lazy loading'
'lazy loading' 告知NHibernate不要从数据库表中加载这个类对象,直到程序中需要访问这个对象的数据时才加载。这种方式可以减少一个业务对象的内存占用,从而提高性能。处于简单,我们将在这个示例程序中不使用lazy loading。但是在以后使用NHibernate做项目的时候,一直到早点知道它的来龙去脉。
<class>标签中还有很多属性,可以查阅NHibernate的帮助文档。
<id>标签
我们已经标识了类和类对应的映射表,接下来我们需要标识类的标识属性和映射表中的标识列。当我们创建数据的时候,我们需要标识CustomerID为主键(primary key)。
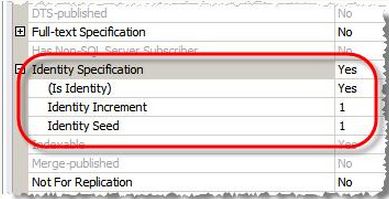
所以要这些:
- 指定Customer类的标识属性
- 指定Customer表记录的标识列
- 告知NHibernate让SQL Server设置CustomerID列的值
<id name="ID">
<column name=" CustomerID " />
<generator class="native" />
</id>
<generator>标签指定数据库记录的标识列的值由SQL Server数据库原生生成。
简单属性
我们设置好类的标识属性,我们接下来设置类的一般属性,Customer类有一个简单属性:Name。我们把它跟数据库Customer表Name列匹配,属性名和列名相同,所以映射文件很简单:
<property name="Name" />
我们可以匹配Name属性到一个不同名称的列上(如CustomerName)。
Component映射
NHibernate使用component来映射那些在数据库中没有相应的表来映射的类,就像上面提到的Address类,只是作为Customer的一个属性值,数据库中没有对应的Address表,它遵循一个区别往往出现在"实体类"和"值类"。
- 一个实体类在业务模型中代表着一个实体,在我们的业务模型中,实体类是Customer、Order、和OrderItem。这些类对应着一个业务对象。
- Address类并不代表一个业务对象,它提供了一种封装类值的方式,在NHibernate的术语里,它是一个Customter对象的一个组件。
NHibernate用'Component'与.NET使用这个词语无关。一个Component只是一个实体对象的一个值,数据库中没有与之映射的表。

<component name="Address">
<property name="StreetAddress" />
<property name="City" />
<property name="State" />
<property name="Zip" />
</component>
<component>标签是一个集合标签。NHibernate将使用.NET反射机制来判断它的真实类型,你也可以通过 class 属性来指定所对应的类名。Customer.hbm.xml文件将匹配两个类。
联合映射
面向对象设计建立在业务模型中的类相互关联的概念上。
- One-to-one:一个对象至于另外一个对象关联。像一夫一妻。
- One-to-many:指容器,像一个Customer对象可以包含很多Order对象。
- Many-to-one:许多对象可以指向另外同一个对象,像许多Order对应着一个单独的Customer对象。
- Many-to-many:许多对象可以指定另一种对象的任何一个。像一个订单有很多产品,一个产品又可以被包含在很多订单里。
集合映射:One-To-Many
在Customer类里,你会发现有一个Orders属性,表示客户的所有订单信息。需要注意的一点是:Orders 属性并不是List<T>类型,而是IList<T>。
private IList<Order> p_Orders = new List<Order>();
public IList<Order> Orders
{
get { return p_Orders; }
set { p_Orders = value; }
}
Orders属性被声明为IList<order>,却被实例化为List<Order>。
这是因为NHibernate需要集合被声明为接口,而不是接口实现。像上面说的,需要被定义成接口,而不是具体的类。这种被认为是很好的编程实践。定义为接口,使NHibernate更加灵活,而且能够提高效率。
NHibernate提供了好几种标签来匹配集合。因为当前集合是个IList<T>,现在我们可以使用<bag>来匹配关联。
<bag name="Orders" cascade="all-delete-orphan" lazy="false">
<key column="CustomerID" />
<one-to-many class="Order" />
</bag>
name属性可以指定要匹配的类的属性,cascade属性的设定表示NHibernate将会操作所有的子对象,包括加载、保存以及删除。all-delete-orphan表示NHibernate将联机保存、删除所有对当前类对应的子对象。
像:当我们删除Customer这个对象时,Customer下的属性Orders所有的Order也将会删除。
在所有的关联映射中,cascade必须要指定值,否则NHibernate将不会联机保存或删除。另外<class>标签可以指定一个默认的cascade,使用default-cascade。但是这个值只会提供在保存和更新操作上使用联机操作,不会对删除也使用联机操作。所以,最好还是设置cascade这个属性的值。
跟上面一样,为了简单,我们依旧不会使用lazy loading。
<bag>标签里包含了两个标签:
- <key>标签的column属性为目标类指定映射表里的列,这一列被用作当前类的映射表和目标类的映射表的外键。
- <ont-to-many>标签表示当前类与以name属性指定的类之间是一对多的关系。name属性指定Order类,当前类Customer与Order之间是一对多的关系。
这里我们好像忘记了一点东西,我们指定了目标类,但是没有指定目标类的映射表。<key>标签指定了映射表的列的名称,而不是映射表的名称。但是NHibernate是怎么知道使用哪个表的呢?这是因为当我们指定好了目标类的名称之后,NHibernate会通过目标类的XML映射文件来获取其所应的映射表。所以在这里我们不需要指定目标类的映射表。
现在,我们已经完成了Customer类的映射,我开始转向Order类。
集合映射:Many-To-One
打开 Order.hbm.xml 文件,现在看的话,里面的内容对你来说已经非常熟悉了。<class>标签、<property>标签、还有一个<set>标签是为了一个订单和订单中的商品的一对多关系。但是在Order类和Customer类之间,这里存在着一种新的关系。每一个订单信息需要知道它是哪个顾客的。
一开始看,这里有点像一对一的关系,一个订单对应一个顾客,但是这样是不对的,很多条订单可以被包含在一个顾客中,尽管一个订单只对应一个顾客,但是在类的角度上,这是多对一关系。
<many-to-one>标签适于这中关系。此标签内不允许有别的标签,尽管关系是 many-to-one, 'many'个对象同时关联到一个对象上。它其实跟<property>一样简单。
<many-to-one name="Customer"
class="Customer"
column="CustomerID"
cascade="all" />
这里的属性名称意思非常直接明了:
- name属性指定要映射的当前类的属性,这个示例中,Customer是Order类的一个属性。
- class属性指定目标类。这个示例中,目标类就是Customer。
- column属性指定当前类的映射表与目标类用作外键的列。这个示例中,CustomerID是Order与Customer的使用的外键。
- cascade属性指定这种关系的级联类型。
class属性不是必需的,NHibernate可以通过.NET反射机制来判断这个类的真实类型;如果映射表中此列于这个类的属性名相同,column属性可以省略。
集合映射:Many-To-Many
在Order.hbm.xml文件中最后一种有趣的关系就是映射OrderItems属性。OrderItems是IList<Product>类型的,包含了一个序列的Product对象。
这种关系跟One-To-Many关系差不多,因为一个订单信息包含很多商品信息。但是一种商品信息可以被包含在很多订单信息里,所以这里是Many-To-Many关系。
在数据库中,我们使用 OrderItems 表当作 Orders 表和 Products 表的连接表。OrderItems 表中包含Order编号和Product编号。这种方式通常表示多对多的关系。这种方式是单向的多对多关系,是Order类对Product类。双向的多对多关系是非常复杂的,在本文中我们不会涉及。
那我们怎样映射多对多关系呢?其实与映射一对多的关系大致相同,我们可以使用<bag>标签,它包含一个<many-to-many>标签。
<bag name="Orders" table="OrderItems" cascade="none" lazy="false">
<key column ="OrderID" />
<many-to-many class="Product" column="ProductID" />
</bag>
解释一下:
- <bag>标签中的name属性用来指明要映射的 Customer 类的属性,这个示例中,就是Orders属性。
- <bag>标签中的table属性用来指明连接表。这里示例中,就是指 OrderItems 表。
- <bag>标签中的cascade属性用来指明这种多对多关系的联机类型。
- <bag>标签中的lazy属性用来指明是否使用lazy loading特性。
- <key>标签用来指明连接表与当前类的映射表实现连接的外键。这里是指OrderID。
- <many-to-many>标签中的class属性用来指明多对多关系中的目标类。这里是指Product类。
- <many-to-many>标签中的column属性用来指定连接表与目标类的映射表链接的外键。这里当然是ProductID.
这里我们跟映射one-to-many关系时一样,我们没有必要指定目标类的映射表,因为我们已经指定了目标类,NHibernate会通过目标类的映射文件来找到它的映射表。
这里的<bag>标签中的cadcade属性设置为none,这是因为我们在删掉一个订单信息时,不想连订单里的产品信息一并删掉。
Order类中现在只剩一一个简单类型,Date,我们不会再花费时间,现在你可以关闭Order类的映射文件。
我们将不再检查 Product.hbm.xml 文件,上面的文章已经涵盖了所有 Product 中的关系映射,打开文件去检查每一项的映射对读者来说是一个很好的练习。
调试映射文件
大多数映射文件的调试都是在运行期间。当一个程序开始配置NHibernate,程序就会尝试去编译所有它能找到的映射文件。如果NHibernate出现问题,将会抛NHibernate.MappingException异常。你可以捕捉这些异常,也可以让它停止执行。另外,这些异常的异常信息可以在 Log4Net 日志文件中找到。最常见的异常信息将会是这样:
NHibernateSimpleDemo.Model.Order.hbm.xml --->
NHibernate.PropertyNotFoundException: Could not find a getter for
property 'OrderItems' in class 'NHibernateSimpleDemo.Order'
调试符合一般调试模式,解决Bug,重新编译,重新执行。如果你的程序能够完成配置NHibernate,你就应该知道你的映射文件是没有问题的。下面我们来讨论如何配置。
如何NHibernate抱怨其中的一个类没有映射,尽管你一直为这里类创建了映射文件,那你可以检查映射文件<class>定义,确定class与映射表匹配是正确的。如果这些都很正确,请确认映射文件的编译类型是嵌入式资源。
整合NHibernate
这里没有正确的方式把NHibernate整合到你的应用程序中,但作者的本意是遵循一般的三层架构,把NHibernate的配置和处理代码放在数据层,示例程序中包含一个 Persistence 文件夹,其中包含一个 PersistenceManager 类。
PersistenceManager类包含了持久化业务模型中的每一个实体的一般函数。单单一个类就已经满足了示例程序,但是对于软件产品这并不是一个很好的实践。在现实的软件编程中,你可以把这些方法分成多个持久化类。
PersistenceManager类配置NHibernate,而且持有一个SessionFactory对象的引用。一个SessionFactory 可以产生多个 Session 对象。Session是NHiberante中一个工作单元。一个Session代表了一次你的程序和NHibernate的一次交互。
你可以把它们当作成交易层次上一级。一个Session通常只有一次交互,但是它可以包含好几个。你一个打开一个Session,进行一次或是多次事务,然后关闭它,最后释放它。
Session通过SessionFactory创建。SessionFactory是密集型资源,而且它的初始化成本较高,从另一方面讲,Session使用了有限的资源,而且强加一些初始化成本。所以,一般的做法是在程序初始化时,创建一个全局的SessionFactory。并且在需要使用Session时,才进行创建。
示例程序中,PersistenceManager的初始化只是程序初始化的一部分。PersistenceManager配置了一个SessionFactory。程序使用PersistenceManager.SessionFactory来创建Session。
配置NHibernate
配置NHibernate有两个元素:配置文件和配置代码。
配置文件可以放在程序根目录下的一个单独的文件里,也可以放在App.config文件里。
在文章的开始,我们建议您下载Log4Net,Log4Net拥有它本身的配置文件,我们也把它放在App.config文件中,NHibernate和Log4Net的配置文件需要放置在App.config文件中的<configSections>标签中。
NHibernate的配置文件很简单,这个配置主要是让NHibernate来创建一个SessionFactory。
- Connection provider:提供连接的工厂。NHibernate应该使用IConnectionProvider。示例程序将使用默认提供的Provider。
- Dialect:数据库方言。示例程序将使用SQL Server 2005方言。
- Connection driver:数据库连接驱动。示例程序将使用SQL Server 客户端驱动。
- Connection String:数据库连接字符串。
示例程序中的数据库连接字符串只适合作者的开发环境。你应该修改成符合自己的。
配置NHibernate、配置Log4Net
您应该回忆起我们向示例程序添加了Log4Net的引用。所以配置NHibernate的第一步就是配置Log4Net。Log4Net的配置不是必需的。
现在我们在App.config文件中添加配置:
<!-- Specify the logging level for NHibernates -->
<logger name="NHibernate">
<level value="DEBUG" />
</logger>
接下来为你的类添加下列特性:
namespace NHibernateSimpleDemo
{
public class PersistenceManager : IDisposable
{
// ...
}
最后一步调用 Configure() 配置Log4Net。
最后在 PersistenceManager 类的构造方法中调用下列方法:
{
log4net.Config.XmlConfigurator.Configure();
}
配置NHibernate、配置代码
{
// Initialize
Configuration cfg = new Configuration();
cfg.Configure();
// Add class mappings to configuration object
Assembly thisAssembly = typeof(Customer).Assembly;
cfg.AddAssembly(thisAssembly);
// Create session factory from configuration object
m_SessionFactory = cfg.BuildSessionFactory();
}
首先我们创建一个NHibernate的Configuration对象,通过它来实现从映射文件中映射类。AddAssembly()方法需要所有的映射文件嵌入到项目的程序集中,所以所有的映射文件的BuildAction(编译方式)设置为Embedded Resource(嵌入式资源)。
接下来我们需要它来创建一个SessionFactory。我们不需要指定配置文件是放在App.config中,还是一个单独的文件中。
BuildSessionFactory()返回一个SessionFactory对象,传递给持久化类的成员变量SessionFactory。
以后程序就可以调用SessionFactory,不管什么时候想使用一个Session对象,它是一个全局的变量。
如果我们使用了很多复杂的类:一个实体类对应一个持久化类,这样的话我们就需要为每一个类传递一个SessionFactory对象的引用。因为示例程序中,我们只有一个持久化类(PersistenceManager),所以我们可以把SessionFactory当作成员变量来调用。
使用NHibernate持久化类
NHibernate一个非常强大的特性就是实现联级地保存和删除。例如:当我们保存Customer对象时,NHibernate也会自动将Customer对象下的所有的Order中变化的部分也保存进去。这个功能大大简化了我们持久化的代码。
PersistenceManager类包含了实现了基本的增删改查操作的方法。
Save():保存实体。
RetrieveAll():从数据库中遍历给定类型的所有对象。
RetrieveEquals():返回对象中的一个属性等于给定值的所有对象。
Delete():这个方法有两个重载方法,第一个方法删除一个实体,第二个方法删除一个序列的实体。
所有的方法遵循以下几个常规模式:
使用 using 来包装一个NHibernate Session对象,这样可以保证Session在方法执行完毕时自动关闭和自动释放,即使方法执行过程中出现异常。
Save()和Delete()方法都是用 using 来包装一个 Transaction。同样是为了自动释放和关闭Transaction的资源。
这些方法都调用Session对象的一般方法。
PersistenceManager类包含一个 Close()方法,而且实现IDisposible接口。这就意味着在程序关闭的时候,必须释放PersistenceManager的所有资源。
PersistenceManager类中的CRUD(创建,遍历,更新,删除)方法不代表一个对象持久化的所有实现。CRUD方法只是用来显示基本的NHibernate的持久化是怎样工作的。NHibernate文档里有详细的解释。
回报
到了现在你也许会有疑问,NHibernate是一个如此复杂的配置过程,那他应该和手动写CRUD函数一样简单。我个人认为NHibernate的学习过程是非常艰难的,而且进展很慢。
好了,现在就是他回报的时候,你是不是觉得到现在我们只不过创建了几个映射文件,还有添加那么几行代码而已。一旦你了解了这个系统,它真的不是很坏。你获得的也是相关可观的。
想想我们以前通过手写代码获取Customer序列,然后获取每一个Customer的Order对象序列,还有每一个Order的Product对象序列。
看看NHibernate是怎么做的:
下面就是保存的代码:
{
using (ISession session = m_SessionFactory.OpenSession())
{
using (session.BeginTransaction())
{
session.SaveOrUpdate(item);
session.Transaction.Commit();
}
}
}
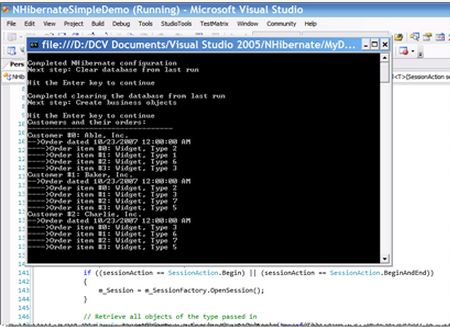
运行实例程序
示例程序是一个控制台的应用程序,所有它没有用户入口。但是Program类承担了这个角色。Main()方法跟Controller类交互。另外Program类注册了OrderSystem.Populate事件,当OrderSystem被重新重载时触发。
这种方式是对MVC架构的一种实现。如果想对MVC有一个深入的了解,阅读这里。如果你对MVC还不够熟悉,通过阅读Main()方法对MVC流程有很好的帮助。
保存一个业务模型
当清理完数据库,程序在内存中创建业务模型。OrderSystem.Populate()方法开始工作,当其执行完毕后,触发Populated事件,这个事件提示程序业务模型已经从数据库中重新加载。Program类注册这个事件,用它来打印所有Customer信息和Order信息。
一旦业务模型被创建,程序就会保存。PersistenceManager中的Save<T>()方法展现了使用NHibernate来持久化代码是多么简单。我们甚至不用再考虑数据库。Controller简单的叙述了PersistenceManager怎样来保存对象。
(OrderSystem OrderSystem, PersistenceManager persistenceManager)
{
// Save Products
foreach (Product product in OrderSystem.Catalog)
{
persistenceManager.Save<Product>(product);
}
// Save Customers (also saves Orders)
foreach (Customer Customer in OrderSystem.Customers)
{
persistenceManager.Save<Customer>(Customer);
}
}
SaveBusinessObjects()方法保存了Products和Customers信息,但是没有保存Orders信息。因为我们已经在Customer.Orders属性上把cascading打开,所以Customer.Orders信息在我们保存Customer时将会自动保存。
NHibernate也会关注为OrderItems表创建条目,即使我们没有为这些写代码。这是因为在Order类的映射文件中,我们已经指定OrderItems表作为连接表在于Order.OrderItems关联的多对多关系中。
删除业务对象
保存了业务模型之后,程序需要将它们从RAM中清理。从RAM中删除业务对象并不代码从数据库中删除。如果我们从RAM删除了业务对象,NHibernate可以从数据库中随时加载出来。
使用NHibernate加载对象
一旦业务模型在RAM中被删除,程序就会从数据库中重新加载出来。这一步我们将演示怎样加载持久阿虎对象。程序使用Controller。LoadBusinessObjects()方法来加载对象,这个方法跟Program类中的方法一样简单,也使用 using 来包装。它使用NHibernate中很流行的“Query By Criteria”特性。
{
using (ISession session = m_SessionFactory.OpenSession())
{
// Retrieve all objects of the type passed in
ICriteria targetObjects = m_Session.CreateCriteria(typeof(T));
IList<T> itemList = targetObjects.List<T>();
// Set return value
return itemList;
}
}
对象的类型通过T参数来制定,这个函数创建一个ICriteria对象,调用List<T>()方法,来返回符合标准的一个对象的集合。
示例程序加载了两次Order对象,一次是明确的,一次是含蓄的。
当加载OrderSystem.Orders集合时,明确加载了一次Orders对象
当加载OrderSystem.Customers集合时含蓄的加载了一次Orders对象。由于Customer映射文件 中的<bag>标签中的cascade属性的设置,程序会在加载Customer对象的时候自动加载Orders对 象。
话句话说,cascading会作用在加载时,同样也会作用在保存的时候。如果没有Order集合,我们就不用明确的加载它了。但是加载Orders对象会导致一个风险,就是当我们想创建两个不用引用的Orders对象时,创建两个不同的Orders对象“他们代表着同一个Orders”。
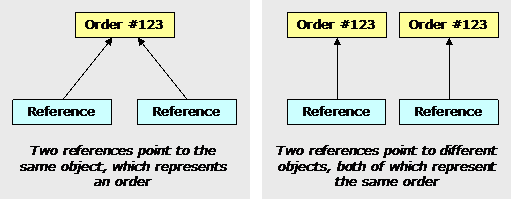
这里是我们怎么解决这个问题。首先我们设定Session变量为成员变量,而不是本地变量。这样可以保证每一个Session变量加载的是同一种对象。接下来我们为这个方法添加一个新的参数,SessionAction。这个参数用来指定函数使用哪一个session。
Begin:这个方法返回一个新的Session对象。
Continue:这个方法持续一个已经存在的session对象。
End:这个方法持续一个已经存在的session对象,并且在方法完毕时结束它。
BeginAndEnd:这个方法开始一个新的session(会话)并在方法结束时结束它。
修改后的方法可以加载许多类型不同的对象,因为他们需要在同一个会话中加载,保证了对象的标识加载了不止一次。
{
// Open a new session if specified
if ((sessionAction == SessionAction.Begin) || (sessionAction ==
SessionAction.BeginAndEnd))
{
m_Session = m_SessionFactory.OpenSession();
}
// Retrieve all objects of the type passed in
ICriteria targetObjects = m_Session.CreateCriteria(typeof(T));
IList<T> itemList = targetObjects.List<T>();
// Close the session if specified
if ((sessionAction == SessionAction.End) || (sessionAction ==
SessionAction.BeginAndEnd))
{
m_Session.Close();
m_Session.Dispose();
}
// Set return value
return itemList;
}
程序只会在最上面的持久化类上调用RetrieveAll<T>()方法,这些类是:Product,Customer,Orders。我们没有必要明确地遍历OrderItems,也没有必要明确的为Customer加载Orders,或者为Orders加载OrderItems。NHibernate会照顾到所有子对象。
NHibernate在查询数据库上有好几种特性:
1.Query by criteria:通过创建Criteria对象查询数据库。
2.Query by example:通过创建一个你想要遍历类型的对象,设置它的属性来指定某个criteria来查询数据库。
3.Hibernate Query Language:一种跟SQL差不多的查询语言。
4.SQL语句:也可以通过原生SQL来查询数据库,如果上面几个方法不能满足你的需求的话。
SQL语句的方式应该是您选择的最后一种方式,如果上面几种方法不适合您的话。NHibernate文档有详细的解释。
验证对象标识
一旦示例程序重新加载业务模型以后,它标识对象的标识已经被保存。事实上有两个对象加载了两次:
Order对象在OrderSystem.Orders中明确加载一次,在OrderSystem.Customers[i].Orders中含蓄的加载一次。
另外,Customer对象在OrderSystem.Customers中明确加载一次,在OrderSystem.Orders[i].Customer中含蓄的加载一次。
第一个Customer放置了第一个Order。我们可以测试这个:
1.Customer集合中的第一个Customer和Order集合中的第一个Order的Customer是同一个对象。
2.Order集合中的第一个Order和Customer集合中的第一个Customer对象的Order是同一个对象。
我们通过使用object.ReferenceEquals()方法来判断两个对象是不是同一个引用。
Customer CustomerA = OrderSystem.Customers[0];
Customer CustomerB = OrderSystem.Orders[0].Customer;
bool sameObject = object.ReferenceEquals(CustomerA, CustomerB);
// Compare Order #1 to the Customer #1 order--should be equal
Order orderA = OrderSystem.Orders[0];
Order orderB = OrderSystem.Customers[0].Orders[0];
sameObject = object.ReferenceEquals(CustomerA, CustomerB);
从数据库中删除对象
上面我们已经提到从对象模型中删除一个对象,并不会从数据库删除。示例程序将通过从对象模型中删除一个对象,再从数据库从新加载来解释这一点。
从数据库中删除对象,我们需要明确的告诉NHibernate。
{
using (ISession session = m_SessionFactory.OpenSession())
{
foreach (T item in itemsToDelete)
{
using (session.BeginTransaction())
{
session.Delete(item);
session.Transaction.Commit();
}
}
}
}
示例程序展示了从数据库删除第一个Customer对象。然后将会清理对象模型,在清理之前,会重新从数据库中加载对象模型。NHibernate在删除Customer记录的同时,同时也删除了Customer的Orders,还有每一个Order下的OrderItems。
把焦点返回到它属于哪里
现在我们已经完成了NHibernate基本的CRUD操作。NHibernate将会大大简化你程序中的持久化代码层,我希望你可以带着这个观点离开。一旦你为你的类创建了映射文件,就可以忘记你的持久层,而且你也不用花费几天时间或是几周来编写一个累赘的持久层,才知道NHibernate这么多好处。
这里还有另外一个好处,也许是最重要的一个。在VS 2005的项目浏览器中看看这个示例程序,你会发现不部分的工作已经在Model层实现了,Controller管理业务模型和持久管理器中的工作和代理任务。这样的结果就是你可以自由地把你的注意致力于业务模型上。减轻了你写持久化代码的苦差事,NHibernate能够让你的焦点放在你的业务模型上,这是它属于的地方。
英文原版:http://www.codeproject.com/KB/database/Nhibernate_Made_Simple.aspx
总结
有些术语翻译的不对的地方,请大家多多指正,一起学习NHibernate。
上面介绍的加载映射文件,以及配置PersistenceManager、SessionFactory如果搭配Spring.NET,上面的所有配置代码,完全可以通过Spring的依赖注入实现,让代码看起来更加简单。
上面还有提到所有要映射的类的属性需要声明为Virtual,当然现在也可以不用声明为virtual。
上面提到的一个对象实际上加载两次,在现实的项目中,我们一般是不会把lazy设置为true的,因为当一个对象的子对象非常多的时候,NHibernate遍历其子对象是一个非常耗资源的过程。
Spring.NET搭配NHibernate对于.NET绝对是一个非常合适的选择。
Xuem www.cnblogs.com/daydayfree
转载 :http://www.cnblogs.com/daydayfree/archive/2011/02/26/1961391.html