Java集合框架图析(Collection-List)
Java集合框架图析(Collection-List)
前言
Java 集合,也称作容器,主要是由两大接口 (Interface) 派生出来的:Collection 和 Map,顾名思义,容器就是用来存放数据的。那么这两大接口的不同之处在于:
Collection存放单一元素;Map存放key-value键值对。
集合框架

Java集合里使用接口来定义功能,是一套完善的继承体系。
Iterator是所有集合的总接口,其他所有接口都继承于它,该接口定义了集合的遍历操作,Collection接口继承于Iterator,是集合的次级接口(Map独立存在),定义了集合的一些通用操作。
Collection
Collection接口集成于Iterator,Collection里还定义了很多方法,这些方法也都会继承到各个子接口和实现类里,而这些 API 的使用也是日常工作和面试常见常考的.
集合的使用最常用的就是CRUD功能:
| 功能 | 方法 |
|---|---|
| 增 | add()/addAll() |
| 删 | remove()removeAll() |
| 改 | Collection Interface 里并没有直接改元素的操作 |
| 查 | contains()/ containsAll() |
| 其他 | isEmpty()/size()/toArray() |
//确保此集合包含指定的元素(可选操作)。
boolean add(E e);
//将指定集合中的所有元素添加到此集合中(可选操作)。
boolean addAll(Collection<? extends E> c);
//从此集合中移除指定元素的单个实例(如果存在)(可选操作)。
boolean remove(Object o);
//把集合中的所有元素都删掉
boolean removeAll(Collection<?> c);
//查下集合中有没有某个特定的元素:
boolean contains(Object o);
//如果此集合包含指定集合中的所有元素,则返回 true
boolean containsAll(Collection<?> c);
//判断集合是否为空
boolean isEmpty();
//集合的大小
int size();
//把集合转成数组
Object[] toArray();
//返回此集合的哈希码值。
int hashCode()
这些就是Collection中常用的API了,在接口中已经定义好了,子类中也可以实现这些API,子类同时也可以有自己的实现.
List
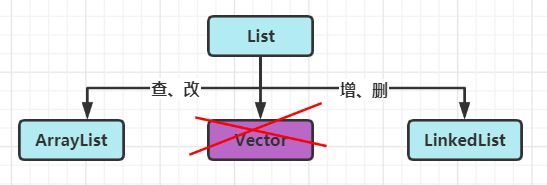
List是Collection的子接口,List的特点主要是:有序,可重复
官网文档的描述是:有序集合(也称为序列 )。 该接口的用户可以精确控制列表中每个元素的插入位置。 用户可以通过整数索引(列表中的位置)访问元素,并搜索列表中的元素。
ArrayList
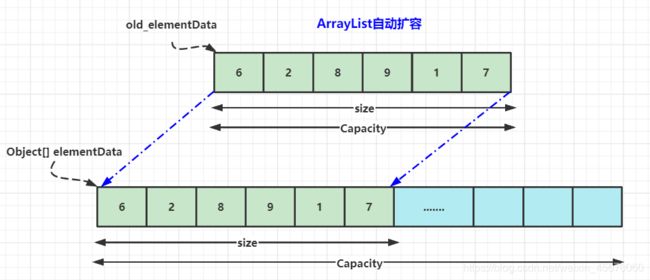
ArrayList实现了List接口,是顺序容器,允许放入null元素,底层通过数组实现,每个ArrayList都有一个容量,容器内存储的元素个数不能超过这个容量,当超过时容器会自动扩容。
ArrayList自动扩容
每次当向数组中添加元素时,都要检查添加的元素会不会超过当前数组的长度, 如果超出, 数组将会扩容, 以满足添加数据的需求, 数组扩容通过
ensureCapacity(int minCapacity)来实现, 倘若需要添加大量元素之前也可以手动配置ensureCapacity(int minCapacity).
每次扩容, 都会将老数组的内容拷贝到新数组中, 每次数组容量的增长是oldCapacity + (oldCapacity >> 1), 大约是原数组的1.5倍, 这种代价还是蛮高的, 所以我们可以使用之前, 预知需要的元素空间, 在构造ArrayList时, 就指定容量, 避免扩容过程, 或者根据生产的大量需求, 手动配置ensureCapacity(int minCapacity).
/**
* Increases the capacity of this ArrayList instance, if
* necessary, to ensure that it can hold at least the number of elements
* specified by the minimum capacity argument.
* @param minCapacity the desired minimum capacity
*/
public void ensureCapacity(int minCapacity) {
if (minCapacity > elementData.length
&& !(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
&& minCapacity <= DEFAULT_CAPACITY)) {
modCount++;
grow(minCapacity);
}
}
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
}
private Object[] grow() {
return grow(size + 1);
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private int newCapacity(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity <= 0) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
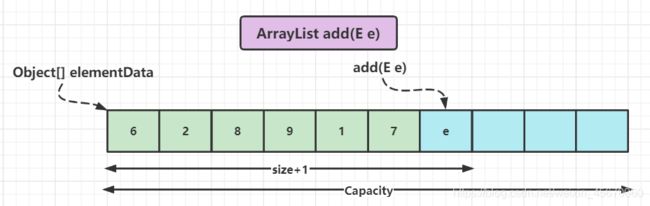
图析:
add(E e) add(int index E e)
分析一下:
add(E e)是在尾部加上元素,add方法中可能会有扩容情况出现,但是平均下来复杂度还是O(1)的.
结合源码分析一下:
进入add()方法:
/**
* Appends the specified element to the end of this Vector.
*
* @param e element to be appended to this Vector
* @return {@code true} (as specified by {@link Collection#add})
* @since 1.2
*/
public synchronized boolean add(E e) {
modCount++;
add(e, elementData, elementCount);
return true;
}
add()中第一个参数
e是我们传输的数据, 第二个参数elementData是是存数据的数组, 第三个参数size是当前数组的长度(当前有效数组的长度). 接着往里面分析
/**
* This helper method split out from add(E) to keep method
* bytecode size under 35 (the -XX:MaxInlineSize default value),
* which helps when add(E) is called in a C1-compiled loop.
*/
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
elementCount = s + 1;
}
先进 行一个
if判断s是否等于当前数组长度, 如果一直就说明存满了, 就grow()方法扩容, 扩容完产生新的数组给elementData[s], 然后后续就正常存了, 存了就siez+1, 继续往里分析grow()
private Object[] grow() {
return grow(elementCount + 1);
}
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
* @throws OutOfMemoryError if minCapacity is less than zero
*/
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
}
grow()方法传入
minCapacity就是目前数组长度, 比如一开始是0, siez+1那长度就变为了1,Arrays.copyOf()将旧数组根据新长度(newCapacity(minCapacity)), 产生一个新数组, 然后旧数据的数据给到新数组. 接着往里分析newCapacity()
/**
* Returns a capacity at least as large as the given minimum capacity.
* Will not return a capacity greater than MAX_ARRAY_SIZE unless
* the given minimum capacity is greater than MAX_ARRAY_SIZE.
*
* @param minCapacity the desired minimum capacity
* @throws OutOfMemoryError if minCapacity is less than zero
*/
private int newCapacity(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity <= 0) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
/**
* The maximum size of array to allocate (unless necessary).
* Some VMs reserve some header words in an array.
* Attempts to allocate larger arrays may result in
* OutOfMemoryError: Requested array size exceeds VM limit
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
这个方法传入最小需要的长度
minCapacity来获取新的长度
- 获取旧数组长度, 因为存满了才需要扩容, 所以就是当前数组的总长度
- 新长度是旧长度+旧长度右移一位(也就是除2)
- 进行判断新的-旧的长度<=0,如果目前存储的数据是默认的是第一次创建,没有传长度默认是0,然后
Math.max取(10,1),这里的10是DEFAULT_CAPACITY默认的长度,然后如果是第一次创建经过size+1,minCapacity就是1,所以经过Math.max取的就是10.- 如果是溢出的话就会报错扔了一个异常, 这里的溢出是:因为是int类型的,最大值是2 的 31 次方 - 1, 如果达到最大值再+1, int类型就存不下了, 就溢出了, 超出了位数, 最终因为符号的改变, 变为负数.
- 如果都不是3.4的情况,就返回需要的
minCapacity- 如果不是就入3的if判断, 说明newCapacity内存扩容够用, 就进行三元运算判断, 如果
newCapacity-MAX_ARRAY_SIZE<=0 , (MAX_ARRAY_SIZE也就是我们允许的最大长度,就是Integer.MAX_VALUE- 8) 那就说明是比最大的要小的, 那就返回newCapacity. 就比如现在要20长度, 那肯定是比最大值要小的, 那就直接取的20. 否则就是hugeCapacity(minCapacity)方法, 接着分析.
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
第一个同样是判断是否溢出,前面分析过了, 接着return返回看
minCapacity是否在MAX_ARRAY_SIZE到Integer.MAX_VALUE - 8之间,如果是就返回Integer.MAX_VALUE, 否则就是返回MAX_ARRAY_SIZE.
add(int index, E e):
是在特定的位置上加元素,LinkedList 需要先找到这个位置,再加上这个元素,虽然单纯的加这个动作是 O(1) 的,但是要找到这个位置还是 O(n) 的。
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
- 图析:
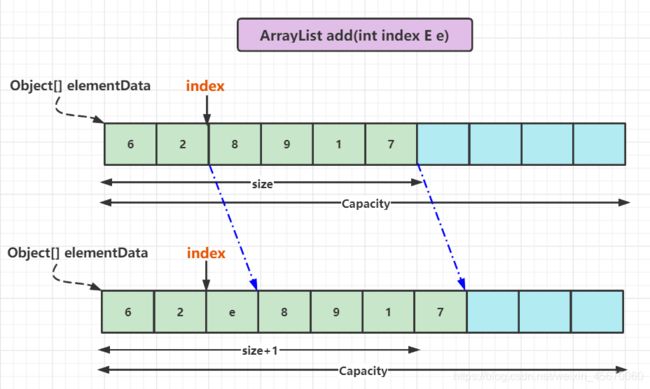
set()
直接对数组指定位置赋值,十分简单
public E set(int index, E element) {
//下标越界检查
rangeCheck(index);
E oldValue = elementData(index);
//完成对应index赋值
elementData[index] = element;
return oldValue;
}
get()
get()同样比较简单,获取对应位置元素
public E get(int index) {
rangeCheck(index);
//注意类型转换
return (E) elementData[index];
}
remove()
有两种方式,一种通过remove对应下标,另一种通过remove见到的第一次满足
o.equals(es[i])的元素.
remove(int index) 是移除对应index上的元素:
public E remove(int index) {
Objects.checkIndex(index, size);
checkForComodification();
E result = root.remove(offset + index);
updateSizeAndModCount(-1);
return result;
}
remove(E e) 是 remove 见到的第一个这个元素:
public boolean remove(Object o) {
final Object[] es = elementData;
final int size = this.size;
int i = 0;
found: {
if (o == null) {
for (; i < size; i++)
if (es[i] == null)
break found;
} else {
for (; i < size; i++)
if (o.equals(es[i]))
break found;
}
return false;
}
fastRemove(es, i);
return true;
}
LinkedList
LinkedList实现了List接口和Deque接口, 也就说可以看作顺序容器,也可以看作一个队列, 又可以看作是栈, 这样看来LinkedList很全能, 当需要使用栈或者队列的时候, 可以考虑使用LinkedList.
基础属性:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
//长度
transient int size = 0;
//指向头结点
transient Node<E> first;
//指向尾结点
transient Node<E> last;
}
private static class Node<E> {
//元素
E item;
//指向后一个元素的指针
Node<E> next;
//指向前一个元素的指针
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
内部结构图:
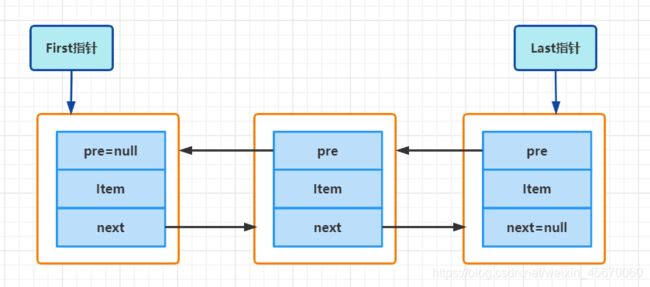
可以看出一个节点中包含三个属性,就是上面源码中的属性, LinkedList底层是一种双向链表的实现.
构造方法
- public LinkedList() :空的构造方法,啥事情都没有做
- public LinkedList(Collection c) : 将一个元素集合添加到LinkedList中
添加节点
public boolean add(E e) {
linkLast(e);
return true;
}
//在链表的最后添加元素
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
- 记录当前末尾节点,通过构造另外一个指向末尾节点的指针l
- 产生新节点,在末尾添加,next为null
- last指向新节点
- 做判断链表中原本有无节点,无的话newNode为第一节点,有的话原本记录的末尾节点指向newNode
- size++ 计数modCount++
删除节点
LinkedList中有两种方法删除节点
//方法1.删除指定索引上的节点
public E remove(int index) {
//检查索引是否正确
checkElementIndex(index);
//这里分为两步,第一通过索引定位到节点,第二删除节点
return unlink(node(index));
}
//方法2.删除指定值的节点
public boolean remove(Object o) {
//判断删除的元素是否为null
if (o == null) {
//若是null遍历删除
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
//若不是遍历删除
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
通过源码可以看出两个方法都是通过unlink()删除, 还有另一种是通过下标找到对应的节点.
- 首先确定index的位置,是靠近first还是last
- 若靠近first从头开始查询, 否则从尾部开始查询,很好的运用了双向链表的特征
/**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
unlink()方法的源码分析, 这也是删除节点的核心方法
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//删除的是第一个节点,first向后移动
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
//删除的是最后一个节点,last向前移
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null; //GC
size--;
modCount++;
return element;
}
- 获取到需要删除元素当前的值,指向它前一个节点的引用,以及指向它后一个节点的引用。
- 判断删除的是否为第一个节点,若是则first向后移动,若不是则将当前节点的前一个节点next指向当前节点的后一个节点
- 判断删除的是否为最后一个节点,若是则last向前移动,若不是则将当前节点的后一个节点的prev指向当前节点的前一个节点
- 将当前节点的值置为null
- size减少并返回删除节点的值
获取节点
getFirst(), getLast():获取第一个元素,获取最后一个元素
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
ArrayList和LinkedList比较
List 的实现方式有 LinkedList 和 ArrayList 两种,面试常考的就是这两个数据结构如何选择,那就要考虑这两种数据结构能完成什么功能以及效率.
先看两个classes的API和时间复杂度:
| 功能 | 方法 | ArrayList | LinkedList |
|---|---|---|---|
| 增 | add(E e) | O(1) | O(1) |
| 增 | add(int index, E e) | O(n) | O(n) |
| 删 | remove(int index) | O(n) | O(n) |
| 删 | remove(E e) | O(n) | O(n) |
| 改 | set(int index, E e) | O(1) | O(1) |
| 查 | get(int index) | O(1) | O(n) |
| 方法 | ArrayList | LinkedList |
|---|---|---|
| add(E e) | 在尾部加上元素,虽然会有扩容的情况出现, 平均下来时间复杂度为O(1) | 在尾部添加元素,直接改变原本末节点的next指向新节点 |
| add(int index, E e) | 先找是O(n),单纯加是O(1) | 先通过线性查找找到具体位置,然后修改相关引用完成插入操作 |
| remove(int index) | 找到这个元素的过程是 O(1),但是 remove 之后,后续元素都要往前移动一位,所以均摊复杂度是 O(n) | 也是要先找到这个 index,这个过程是 O(n) 的,所以整体也是 O(n) |
| remove(E e) | 要先找到这个元素,这个过程是 O(n),然后移除后还要往前移一位,这个更是 O(n),总的还是 O(n) | 也是要先找,这个过程是 O(n),然后移走,这个过程是 O(1),总的是 O(n). |
ArrayList是实现了基于动态数组的数据结构,因地址连续,一旦数据存储好了,查询操作效率会比较高(在内存里是连着放的),ArrayList要移动数据,所以插入和删除操作效率比较低.LinkedList基于链表的数据结构 地址是任意的, 对于新增和删除数据有较好的性能,查询较慢 因为LinkedList查询需要移动指针遍历.
public class Test {
private static ArrayList<Integer> arrayList= new ArrayList<>();
private static LinkedList<Integer> linkedList = new LinkedList<>();
public static void main(String[] args) {
int count = 1000000; //循环次数
System.out.println("循环 " + count + " 次,arrayList LinkedList 尾部插入性能测试:");
testInsert(arrayList, count);
testInsert(linkedList, count);
int index = 0; //插入位置
count = 100000;
System.out.println("\n循环 " + count + " 次,arrayList LinkedList 指定位置插入性能测试:");
testInsertForIndex(arrayList, count, index);
testInsertForIndex(linkedList, count, index);
System.out.println("\n循环 " + count + " 次,arrayList LinkedList 查询性能测试");
getElements(arrayList, count);
getElements(linkedList, count);
}
/**
* 向默认位置插入元素
* @param count 循环次数
*/
public static void testInsert(List<Integer> list, int count){
long beginTime = System.currentTimeMillis();
for(int i=0; i<count; i++){
list.add(1);
}
long endTime = System.currentTimeMillis();
System.out.println(list.getClass().getName() + " 共耗时:" + (endTime - beginTime) + " ms");
}
/**
* 向指定位置插入元素
* @param count 循环次数
* @param index 插入位置
*/
public static void testInsertForIndex(List<Integer> list, int count, int index){
long beginTime = System.currentTimeMillis();
for(int i=0; i<count; i++){
list.add(index,1);
}
long endTime = System.currentTimeMillis();
System.out.println(list.getClass().getName() + " 共耗时:" + (endTime - beginTime) + " ms");
}
/**
* 获取元素
* @param list
* @param count
*/
public static void getElements(List<Integer> list, int count){
Long beginTime = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
list.get(i);
}
Long endTime = System.currentTimeMillis();
System.out.println(list.getClass().getName() + " 共耗时:" + (endTime - beginTime) + " ms");
}
}
结果如下图:
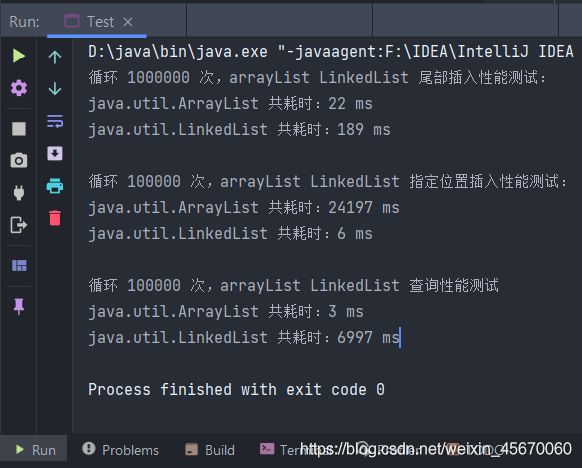
LinkedList插入、删除指定位置的性能是优于ArrayList的,因为ArrayList需要额外的移动损耗,以及拷贝元素.ArrayList在查找和尾部插入删除的性能时优于LinkedList的.