【8. Redis 的设计、实现】
Redis 的设计、实现
数据结构和内部编码
数据结构和内部编码
type命令
type 命令实际返回的就是当前键的数据结构类型,它们分别是:string(字符 串)hash(哈希)、list(列表)、set(集合)、zset (有序集合),但这些只是 Redis 对外的 数据结构。
每种数据结构都有两种以上的编码
例如 list 数据结构包含了 linkedlist 和 ziplist 两种内部编码。同时有些内部编码,例如 ziplist,可以作为多种 外部数据结构的内部实现,可以通过 object encoding 命令查询内部编码。
好处:
- 可以改进内部编码, 而对外的数据结构没有影响
- 多种内部编码可以在不同的场景发挥优势
redisObject 对象
redis存储的所有值对象内部都定义为redisObject结构体
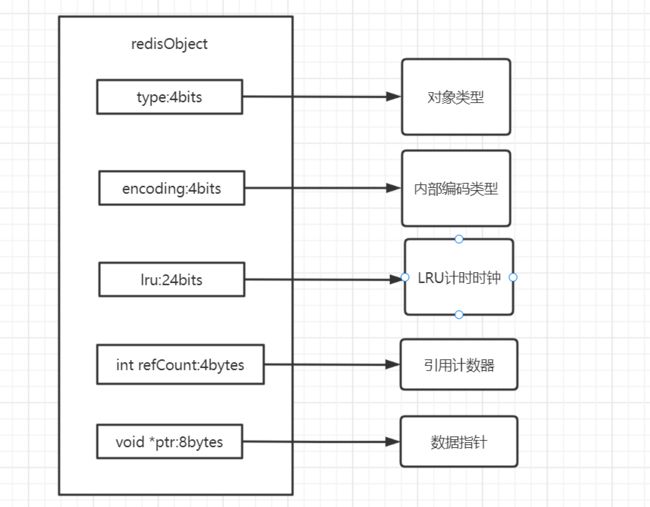
Redis 存储的数据都使用 redis0bject 来封装,包括 string、hash、list、set,zset 在内的所有数据类型。
type字段:表示当前对象使用的数据类型,Redis主要支持5种数据类型:string, hash、 list,set,zset。可以使用 type { key}命令查看对象所属类型,type 命令返回的 是值对象类型,键都是 string 类型。
encoding 字段:表示 Redis 内部编码类型,encoding 在 Redis 内部使用,代表当 前对象内部采用哪种数据结构实现。理解 Redis 内部编码方式对于优化内存非常重要,同一个对象采用不同的编码实现内存占用存在明显差异。
lru 字段:记录对象最后次被访问的时间,当配置了 maxmemory 和 maxmemory-policy=volatile-lru 或者 allkeys-lru 时,用于辅助 LRU 算法删除键数据。 可以使用 object idletime {key}命令在不更新 lru 字段情况下查看当前键的空闲时 间。
PS:可以使用 scan + object idletime 命令批量查询哪些键长时间未被访问, 找出长时间不访问的键进行清理,可降低内存占用。
也就是说,redis在内存不足时候可以将低频访问的数据从内存中替换掉, 但是并不是删除没了,而是放入硬盘中去,
refcount 字段:记录当前对象被引用的次数,用于通过引用次数回收内存,当 refcount=0 时,可以安全回收当前对象空间。使用 object refcount(key}获取当前 对象引用。当对象为整数且范围在[0-9999]时,Redis 可以使用共享对象的方式来 节省内存。
PS:当数据大量使用[0-9999]的整数时,共享对象池可以节约大量内存,最 多可以达到 30%。但是当设置 maxmemory 并启用 LRU 相关淘汰策略 如:volatile-lru,allkeys-lru 时,Redis 禁止使用共享对象池。同时 ziplist 编码的值对象,
即使内部数据为整数也无法使用共享对象池,因为 ziplist 使用压缩且内存连续的 结构,对象共享判断成本过高。
*ptr 字段:与对象的数据内容相关,如果是整数,直接存储数据;否则表示指 向数据的指针。Redis 在 3.0 之后对值对象是字符串且长度<=39 字节的数据,内 部编码为 embstr 类型,字符串 sds 和 redisobject 一起分配,从而只要一次内存操 作即可。
字符串
内部编码
int: 8字节长整型
embstr: < 44 字节 的字符串
raw: > 44 字节的字符串
redis字符串是可以修改的字符串
我们知道 C 语言里面的字符串标准形式是以 NULL 作为结束符,但是在 Redis 里面字符串不是这么表示的。因为要获取 NULL 结尾的字符串的长度使用 的是 strlen 标准库函数,这个函数的算法复杂度是 O(n),它需要对字节数组进 行遍历扫描。
Redis 的字符串叫着「SDS」,也就是 Simple Dynamic String。
在字符串比较小时,SDS 对象头的大小是 capacity+3,至少是 3。意味着分配一个字符串的最小空间占用为 19 字节 (16+3)。
struct SDS<T> {
T capacity; // 数组容量, 至少1bytes
T len; // 数组长度, 至少1bytes
byte flags; // 特殊标识位,不理睬它 , 至少1bytes
byte[] content; // 数组内容, 长度为capacity
}
当长度超过 44 时,使用 raw 形式存储。?
struct RedisObject {
int4 type; // 4bits
int4 encoding; // 4bits
int24 lru; // 24bits
int32 refcount; // 4bytes
void *ptr; // 8bytes,64-bit system
} robj; 共16bytes,
embstr 存储形式是这样一种存储形式,它将 RedisObject 对象头和 SDS 对 象连续存在一起,使用 malloc 方法一次分配。而 raw 存储形式不一样,它需要两次 malloc,两个对象头在内存地址上一般是不连续的。
而内存分配器 jemalloc/tcmalloc 等分配内存大小的单位都是 2、4、8、16、 32、64 等等,为了能容纳一个完整的 embstr 对象,jemalloc 最少会分配 32 字 节的空间,如果字符串再稍微长一点,那就是 64 字节的空间。
64 - 16 = 50 -10 + 14 - 6 = 40 + 8 = 48
48 -3 = 45(头部最少字节数3)
45 -1 = 44(字符串是以0结尾的)
而且字符串在长度小于 1M 之前,扩容空间采用加倍策略,也就是保留 100% 的冗余空间。当长度超过 1M 之后,为了避免加倍后的冗余空间过大而导 致浪费,每次扩容只会多分配 1M 大小的冗余空间。
字典/哈希
dict 是 Redis 服务器中出现最为频繁的复合型数据结构,除了 hash 结构 的数据会用到字典外,整个 Redis 数据库的所有 key 和 value 也组成了一个全 局字典,还有带过期时间的 key 集合也是一个字典。zset 集合中存储 value 和 score 值的映射关系也是通过 dict 结构实现的。
struct RedisDb {
dict* dict; // all keys key=>value
dict* expires; // all expired keys key=>long(timestamp)
...
}
struct zset { //
dict *dict; // all values value=>score
zskiplist *zsl;
}
dict 结构内部包含两个 hashtable,通常情况下只有一个 hashtable 是有值 的。但是在 dict 扩容缩容时,需要分配新的 hashtable,然后进行渐进式搬迁, 这时候两个 hashtable 存储的分别是旧的 hashtable 和新的 hashtable。待搬迁 结束后,旧的 hashtable 被删除,新的 hashtable 取而代之。
字典数据结构的精华就落在了 hashtable 结构上了。hashtable 的结 构和 Java 的 HashMap 几乎是一样的,都是通过分桶的方式解决 hash 冲突。 第一维是数组,第二维是链表。数组中存储的是第二维链表的第一个元素的指针。
渐进式 rehash
两个hashtable慢慢搬迁数据, 避免单线程的阻塞
-
被动搬迁: hset/hdel的指令触发
-
主动搬迁: 定时任务触发
查找过程
Redis 代码中有个 hash_func,它会将 key 映射为一个整数,不同的 key 会 被映射成分布比较均匀散乱的整数。
hash 函数
**hashtable 的性能好不好完全取决于 hash 函数的质量。**hash 函数如果可以 将 key 打散的比较均匀,那么这个 hash 函数就是个好函数。Redis 的字典默认 的 hash 函数是 siphash。
siphash 算法即使在输入 key 很小的情况下,也可以 产生随机性特别好的输出,而且它的性能也非常突出,同时还能很大程度避免哈希洪水攻击。对于 Redis 这样的单线程来说,字典数据结构如此普遍,字典操 作也会非常频繁,hash 函数自然也是越快越好。
hash洪水攻击:
利用hash算法的偏向性, 输入特定模式的key, 导致hash集中到一个链表, 查询效率从O(1)变成O(n)
siphash 算法针对这种情况做了很好的改进。Java 自带的字符串哈希函数, 使用的是“DJBX33A 算法”的变种,安全性不是很高
这个成本具体有多低呢?
依 2011 年的实验数据,攻击一台基于 Java (Tomcat)的服务器时,仅仅需要 6KB/s 的流量就能打瘫一颗 Intel i7 处理器, 1GB/s 的流量可以打瘫 100000 颗 Intel i7 处理器。
算法中加入一个黑客不知道的秘 密参数?每建一张哈希表,我们就随机生成一个新的秘密参数。
这个黑客不知道的秘密参数,称之为哈希种子(Hash Seed)。而 这类使用哈希种子的哈希算法,我们称之为带密钥哈希算法(Keyed Hash Function)。这些年来,设计了许多新的哈希函数:SipHash、MurmurHash、CityHash 等等。Rust、Python、Ruby 等语言更是把 SipHash 作为默认的哈希表实现方法, 用这些语言编写的项目天生免疫哈希洪水攻击。
Java 提出的解决方案其实大家应该知道,HashMap、LinkedHashMap 和 ConcurrentHashMap 三个类引入了一套新的策略来处理哈希碰撞。当一个位置存储的元素个数小于 8 个时,仍然使用链表存储。当一个位置存储的元素个数大于 等于 8 个时,改为使用平衡树来存储。(所以红黑树另一个作用就是防洪水攻击), 一个位置, table默认是16
为什么要设立“8 个元素”(TREEIFY threshold)这样一个限制呢?
因为平衡树相比链表而言有着更高的开销,以及更散乱的内存布局(影响缓存命中率)。 在正常情况下,哈希表的一个位置大约只会存储 1~4 个左右的元素,所以没有必要专门开一个平衡树来存储冲突的元素,对一些性能敏感的应用来说会造成显著的负面影响。
扩容条件
正常情况下,当 hash 表中元素的个数等于第一维数组的长度时,就会开始 扩容,扩容的新数组是原数组大小的 2 倍。不过如果 Redis 正在做 bgsave,为 了减少内存页的过多分离 (Copy On Write),Redis 尽量不去扩容 (dict_can_resize),但是如果 hash 表已经非常满了,元素的个数已经达到了第一 维数组长度的 5 倍 (dict_force_resize_ratio),说明 hash 表已经过于拥挤了,这 个时候就会强制扩容。
缩容条件
当 hash 表因为元素的逐渐删除变得越来越稀疏时,Redis 会对 hash 表进 行缩容来减少 hash 表的第一维数组空间占用。缩容的条件是元素个数低于数组长度的 10%。缩容不会考虑 Redis 是否正在做 bgsave。
列表
**ziplist(压缩列表)*当列表的元素个数小于 list-max-ziplist-entries 配置(默认 512 个),同时列表中每个元素的值都小于 list-max-ziplist-value 配置时(默认 64 字 节),Redis 会选用 ziplist 来作为列表的内部实现来减少内存的使用。
**linkedlist(链表)*当列表类型无法满足 ziplist 的条件时,Redis 会使用 linkedlist 作为列表的内部实现。
Redis 3.2 版本提供了 quicklist 内部编码,简单地说它是以一个 ziplist 为节点 的 linkedlist,它结合了 ziplist 和 linkedlist 两者的优势,为列表类型提供了一种 更为优秀的内部编码实现。
Redis 5.0 又引入了一个新的数据结构 listpack,它是对 ziplist 结构的改进, 在存储空间上会更加节省,而且结构上也比 ziplist 要精简。它的整体形式和 ziplist 还是比较接近的,
linkedlist结构
// 链表的节点
struct listNode {
listNode* prev;
listNode* next;
T value;
}
// 链表
struct list {
listNode *head;
listNode *tail;
long length;
}
ziplist(压缩列表)
除了列表类型,zset 和 hash 容器对象在元素个数较少的时候,也采用压缩 列表 (ziplist) 进行存储。压缩列表是一块连续的内存空间,元素之间紧挨着存储, 没有任何冗余空隙。
struct ziplist {
int32 zlbytes; // 整个压缩列表占用字节数
int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于 快速定位到最后一个节点
int16 zllength; // 元素个数
T[] entries; // 元素内容列表,挨个挨个紧凑存储
int8 zlend; // 标志压缩列表的结束,值恒为 0xFF
}
压缩列表为了支持双向遍历,所以才会有 ztail_offset 这个字段,用来快速 定位到最后一个元素,然后倒着遍历。
entry 块随着容纳的元素类型不同,也会有不一样的结构。
struct entry {
int prevlen; // 前一个 entry 的字节长度
int encoding; // 元素类型编码
optional byte[] content; // 元素内容
}
Redis 为了节约存储空间,对 encoding 字段进行了相当复杂的设计。Redis 通过这个字段的前缀位来识别具体存储的数据形式。比如 00xxxxxx 表示最大长 度位 63 的短字符串,后面的 6 个位存储字符串的位数,剩余的字节就是字符 串的内容;11010000 表示 int32,后跟四个字节表示整数;11100000 表示 int64, 后跟八个字节表示整数;11110000 表示 int24,后跟三个字节表示整数; 11111110 表示 int8,后跟一个字节表示整数等等。
因为 ziplist 都是紧凑存储,没有冗余空间 (对比一下 Redis 的字符串结构)。 意味着插入一个新的元素就需要调用 realloc 扩展内存。取决于内存分配器算法 和当前的 ziplist 内存大小,realloc 可能会重新分配新的内存空间,并将之前的 内容一次性拷贝到新的地址,也可能在原有的地址上进行扩展,这时就不需要进 行旧内容的内存拷贝。
如果 ziplist 占据内存太大,重新分配内存和拷贝内存就会有很大的消耗。 所以 ziplist 不适合存储大型字符串,存储的元素也不宜过多。
前面提到每个 entry 都会有一个 prevlen 字段存储前一个 entry 的长度。 如果内容小于 254 字节,prevlen 用 1 字节存储,否则就是 5 字节。这意味着 如果某个 entry 经过了修改操作从 253 字节变成了 254 字节,那么它的下一 个 entry 的 prevlen 字段就要更新,从 1 个字节扩展到 5 个字节;如果这个 entry 的长度本来也是 253 字节,那么后面 entry 的 prevlen 字段还得继续更 新。
前面提到每个 entry 都会有一个 prevlen 字段存储前一个 entry 的长度。 如果内容小于 254 字节,prevlen 用 1 字节存储,否则就是 5 字节。这意味着 如果某个 entry 经过了修改操作从 253 字节变成了 254 字节,那么它的下一 个 entry 的 prevlen 字段就要更新,从 1 个字节扩展到 5 个字节;如果这个 entry 的长度本来也是 253 字节,那么后面 entry 的 prevlen 字段还得继续更 新。
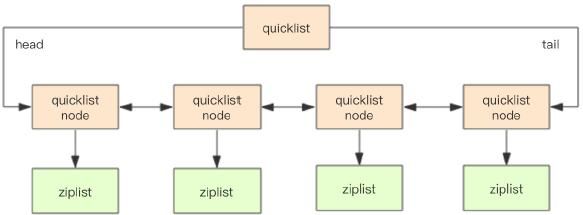
quicklist
Redis 早期版本存储 list 列表数据结构使用的是压缩列表 ziplist 和普通的 双向链表 linkedlist,也就是元素少时用 ziplist,元素多时用 linkedlist。
考虑到链表的附加空间相对太高,prev 和 next 指针就要占去 16 个字节 (64bit 系统的指针是 8 个字节),另外每个节点的内存都是单独分配,会加剧内 存的碎片化,影响内存管理效率。后续版本对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist。
quicklist 是 ziplist 和 linkedlist 的混合体,它将 linkedlist 按段切分,每一 段使用 ziplist 来紧凑存储,多个 ziplist 之间使用双向指针串接起来。
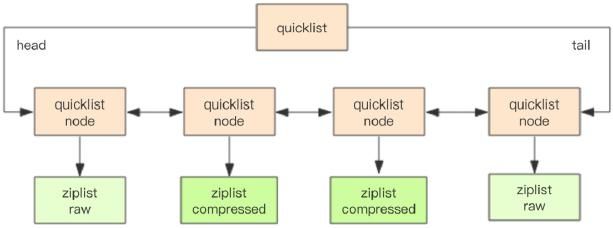
为了进一步节约空间,Redis 还会对 ziplist 进行压缩存储,使用 LZF 算法 压缩,可以选择压缩深度。
quicklist 内部默认单个 ziplist 长度为 8k 字节,超出了这个字节数,就会 新起一个 ziplist。
**quicklist 默认的压缩深度是 0,也就是不压缩。**压缩的实际深度由配置参数 list-compress-depth 决定。为了支持快速的 push/pop 操作,quicklist 的首尾两个 ziplist 不压缩,此时深度就是 1。如果深度为 2,就表示 quicklist 的首尾第 一个 ziplist 以及首尾第二个 ziplist 都不压缩。
listpack
Redis 5.0 又引入了一个新的数据结构 listpack,它是对 ziplist 结构的改进, 在存储空间上会更加节省,而且结构上也比 ziplist 要精简。它的整体形式和 ziplist 还是比较接近的,也是比较容易理解的。
struct listpack {
int32 total_bytes; // 占用的总字节数
int16 size; // 元素个数
T[] entries; // 紧凑排列的元素列表
int8 end; // 同 zlend 一样,恒为 0xFF
}
listpack 跟 ziplist 的结构几乎一摸一样,只是少了一个 zltail_offset 字段。 ziplist 通过这个字段来定位出最后一个元素的位置,用于逆序遍历。**不过 listpack 可以通过其它方式来定位出最后一个元素的位置,**所以 zltail_offset 字段就省掉 了。
struct lpentry {
int encoding;
optional byte[] content;
int length;
}
元素的结构和 ziplist 的元素结构也很类似,都是包含三个字段。不同的是 长度字段放在了元素的尾部,而且存储的不是上一个元素的长度,是当前元素的 长度。正是因为长度放在了尾部,所以可以省去了 zltail_offset 字段来标记最后 一个元素的位置,这个位置可以通过 total_bytes 字段和最后一个元素的长度字段 计算出来。
Redis 为了让 listpack 元素支持很多类型,它对 encoding 字段也进行了较 为复杂的设计。
**listpack 的设计彻底消灭了 ziplist 存在的级联更新行为,元素与元素之间完 全独立,**不会因为一个元素的长度变长就导致后续的元素内容会受到影响。
因为有很多兼容性的问题需要考虑,ziplist 在 Redis 数据结构中使用太广泛 了,替换起来复杂度会非常之高。它目前只使用在了新增加的 Stream 数据结构 中。
集合
Redis 里面 set 的结构底层实现也是字典(dirt, hash),只不过所有的 value 都是 NULL, 其它的特性和字典一模一样。(java中的HashSet也是HashMap)
IntSet 小整数集合
当 set 集合容纳的元素都是整数并且元素个数较小时,Redis 会使用 intset 来存储结合元素。intset 是紧凑的数组结构,同时支持 16 位、32 位和 64 位 整数。
有序集合
Redis 的 zset 是一个复合结构,一方面它需要一个 hash 结构来存储 value 和 score 的对应关系,另一方面需要提供按照 score 来排序的功能,还需要能 够指定 score 的范围来获取 value 列表的功能,这就需要另外一个结构「跳跃 列表」。
zset 的内部实现是一个 hash 字典加一个跳跃列表 (skiplist)。hash 结构在 讲字典结构时已经详细分析过了,它很类似于 Java 语言中的 HashMap 结构。 跳跃列表复杂点。
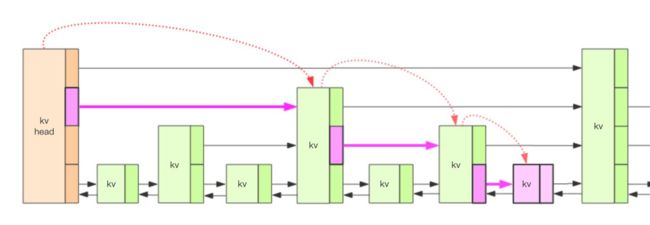
上图就是跳跃列表的示意图,图中只画了四层,Redis 的跳跃表共有 64 层, 意味着最多可以容纳 2^64 次方个元素。每一个 kv 块对应的结构如下面的代码 中的 zslnode 结构,kv header 也是这个结构,只不过 value 字段是 null 值—— 无效的,score 是 Double.MIN_VALUE,用来垫底的。kv 之间使用指针串起来形 成了双向链表结构,它们是 有序 排列的,从小到大。不同的 kv 层高可能不一 样,层数越高的 kv 越少。同一层的 kv 会使用指针串起来。每一个层元素的遍 历都是从 kv header 出发。
struct zslnode {
string value;
double score;
zslnode*[] forwards; // 多层连接指针
zslnode* backward; // 回溯指针
}
struct zsl {
zslnode* header; // 跳跃列表头指针
int maxLevel; // 跳跃列表当前的最高层
map ht; // hash 结构的所有键值对
}
我们要定位到那个紫色的 kv,需要从 header 的最高层开始遍历找到第一 个节点 (最后一个比「我」小的元素),然后从这个节点开始降一层再遍历找到第 二个节点 (最后一个比「我」小的元素),然后一直降到最底层进行遍历就找到了 期望的节点 (最底层的最后一个比我「小」的元素)。
我们将中间经过的一系列节点称之为「搜索路径」,它是从最高层一直到最 底层的每一层最后一个比「我」小的元素节点列表。
有了这个搜索路径,我们就可以插入这个新节点了。不过这个插入过程也不 是特别简单。因为新插入的节点到底有多少层,得有个算法来分配一下,跳跃列 表使用的是随机算法。
对于每一个新插入的节点,都需要调用一个随机算法给它分配一个合理的层 数。直观上期望的目标是 50% 的 Level1,25% 的 Level2,12.5% 的 Level3, 一直到最顶层 2^-63,因为这里每一层的晋升概率是 50%。
不过 Redis 标准源码中的晋升概率只有 25%,也就是代码中的 ZSKIPLIST_P 的值。所以官方的跳跃列表更加的扁平化,层高相对较低,在单个层上需要遍历 的节点数量会稍多一点。
也正是因为层数一般不高,所以遍历的时候从顶层开始往下遍历会非常浪费。 跳跃列表会记录一下当前的最高层数 maxLevel,遍历时从这个 maxLevel 开始遍 历性能就会提高很多。
在一个极端的情况下,zset 中所有的 score 值都是一样的,zset 的查找性 能会退化为 O(n) 么?Redis 作者自然考虑到了这一点,所以 zset 的排序元素不 只看 score 值,如果 score 值相同还需要再比较 value 值
元素排名是怎么算出来的?
前面我们啰嗦了一堆,但是有一个重要的属性没有提到,那就是 zset 可以 获取元素的排名 rank。那这个 rank 是如何算出来的?如果仅仅使用上面的结 构,rank 是不能算出来的。Redis 在 skiplist 的 forward 指针上进行了优化,给 每一个 forward 指针都增加了 span 属性,span 是「跨度」的意思,表示从前 一个节点沿着当前层的 forward 指针跳到当前这个节点中间会跳过多少个节点。
struct zslforward {
zslnode* item;
long span; // 跨度
}
struct zsl {
String value;
double score;
zslforward*[] forwards; // 多层连接指针
zslnode* backward; // 回溯指针
}
这样当我们要计算一个元素的排名时,只需要将「搜索路径」上的经过的所 有节点的跨度 span 值进行叠加就可以算出元素的最终 rank 值。
通信协议
Redis 的作者认为数据库系统的瓶颈一般不在于网络流量,而是数据库自身 内部逻辑处理上。所以即使 Redis 使用了浪费流量的 RESP 文本协议,依然可以 取得极高的访问性能。
RESP(Redis Serialization Protocol)
优势在于实 现异常简单,解析性能极好
Redis 协议将传输的结构数据分为 5 种最小单元类型,单元结束时统一加 上回车换行符号\r\n。
1、单行字符串 以 + 符号开头。
2、多行字符串 以 $ 符号开头,后跟字符串长度。
3、整数值以 : 符号开头,后跟整数的字符串形式。
4、错误消息 以 - 符号开头。
5、数组 以 * 号开头,后跟数组的长度。
单行字符串 hello world
+hello world\r\n
多行字符串 hello world
$11\r\nhello world\r\n
多行字符串当然也可以表示单行字符串。
整数 1024
:1024\r\n
错误 参数类型错误
-WRONGTYPE Operation against a key holding the wrong kind of value
数组 [1,2,3]
*3\r\n:1\r\n:2\r\n:3\r\n
NULL 用多行字符串表示,不过长度要写成-1。
$-1\r\n
空串用多行字符串表示,长度填 0。
$0\r\n\r\n
注意这里有两个\r\n。为什么是两个? 因为两个\r\n 之间,隔的是空串。
客户端 -> 服务器
客户端向服务器发送的指令只有一种格式,多行字符串数组。比如一个简单 的 set 指令 set lang java 会被序列化成下面的字符串。
*3\r\n$3\r\nset\r\n$7\r\nteacher$4\r\mark\r\n
在控制台输出这个字符串很好阅读。
服务器 -> 客户端
服务器向客户端回复的响应要支持多种数据结构,所以消息响应在结构上要 复杂不少。不过再复杂的响应消息也是以上 5 中基本类型的组合。
单行字符串响应
127.0.0.1:6379> set author codehole
OK
这里的 OK 就是单行响应,没有使用引号括起来。
+OK
错误响应
127.0.0.1:6379> incr author
(error) ERR value is not an integer or out of range
试图对一个字符串进行自增,服务器抛出一个通用的错误。
-ERR value is not an integer or out of range
整数响应
127.0.0.1:6379> incr books
(integer) 1
这里的 1 就是整数响应
:1
多行字符串响应
127.0.0.1:6379> get author
"codehole"
这里使用双引号括起来的字符串就是多行字符串响应
$8
codehole
数组响应
127.0.0.1:6379> hset info name laoqian
(integer) 1
127.0.0.1:6379> hset info age 30
(integer) 1
127.0.0.1:6379> hset info sex male
(integer) 1
127.0.0.1:6379> hgetall info
1) "name"
2) "laoqian"
3) "age"
4) "30"
5) "sex"
6) "male"
这里的 hgetall 命令返回的就是一个数值,第 0|2|4 位置的字符串是 hash 表的 key,第 1|3|5 位置的字符串是 value,客户端负责将数组组装成字典再返 回。
*6
$4
name
$6
laoqian
$3
age
$2
30
$3
sex
$4
male
嵌套
127.0.0.1:6379> scan 0
1) "0"
2) 1) "info"
2) "books"
3) "author"
scan 命令用来扫描服务器包含的所有 key 列表,它是以游标的形式获取, 一次只获取一部分。
scan 命令返回的是一个嵌套数组。数组的第一个值表示游标的值,如果这 个值为零,说明已经遍历完毕。如果不为零,使用这个值作为 scan 命令的参数 进行下一次遍历。数组的第二个值又是一个数组,这个数组就是 key 列表。
*2
$1
0
*3
$4
info
$5
books
$6
author
小结
Redis 协议里有大量冗余的回车换行符,但是这不影响它成为互联网技术领 域非常受欢迎的一个文本协议。有很多开源项目使用 RESP 作为它的通讯协议。 在技术领域性能并不总是一切,还有简单性、易理解性和易实现性,这些都需要 进行适当权衡。
Redis6 中的 RESP3
RESP3 是 RESP version 2 的更新版本。RESP v2 大致从 Redis 2.0 开始支持, 相对 RESP v2,RESP3 支持的数据类型更多,比如:
Null:一个空值,用来替代 RESP v2 的 *-1 和 $-1
Double:浮点数
Boolean:true 或 false
Blob error:二进制感觉错误码和消息
Verbatim string:二进制安全字符串,应在不进行任何转义或过滤的情况下显示
Map:键值对的有序集合。键和值可以是任何其他 RESP3 类型
Set:N 个其他类型的无序集合
Attribute:与 Map 类似。
Push:与 Array 类似。
Hello:与 Map 类似。仅用在客户端与服务端建立连接时
Big number:无法用数字类型表示的大数字
作为 Redis 6 中最重要的特性升级,仅仅支持的更多数据类型肯定是不够的, 按照Redis作者antirez 表示全新的 Redis 协议 RESP3 将是 Redis 6 中最重要的 特性,并解释了他为何如此急切地改进 Redis 协议,原因主要有两个,一是因 为希望能为客户端提供更多的语义化回复(semantical replies),以开发使用旧 协议难以实现的功能;另一个原因也是 antirez 认为最重要的一个,实现 Client side caching(客户端缓存)功能
当使用者需要进行快速存储或快速取操作时,就需要在客户端内存中存储一 小部分信息,这是为了降低程序获取数据时的延迟。此功能在大规模的应用程序 上十分重要,因为数据离应用程序越近,程序就能更快获取到数据。
client cache 的问题是缓存应该何时失效,更确切的说是如何保持与远端数据 的一致性。
为 client cache 设置过期时间是一个选择,但时间设置多久是一个问题。太 长会有时效性问题,太短缓存的效果会打折扣。
redis 在服务端记录访问的连接和相关的 key, 当 key 有变化时,通知相应 的连接(应用)。应用收到请求后自行处理有变化的 key, 进而实现 client cache 与 redis 的一致。
redis 对客户端缓存的支持方式被称为 Tracking,分为两种模式:默认模式, 广播模式。
默认模式
Server 端记录每个 Client 访问的 Key,当发生变更时,向 client 推送数据过 期消息。
优点:只对 Client 发送其访问过的被修改的数据
缺点:Server 端需要额外存储较大的数据量。
广播模式
客户端订阅 key 前缀的广播(空串表示订阅所有失效广播),服务端记录 key 前缀与 client 的对应关系。当相匹配的 key 发生变化时,通知 client。
优点:服务端记录信息比较少
缺点:client 会收到自己未访问过的 key 的失效通知。
线程和 IO 模型
Reactor 模式
单线程 Reactor 模式流程
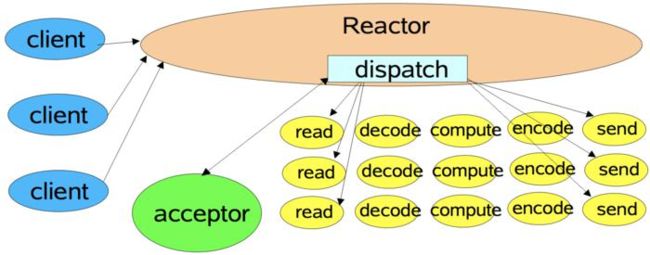
单线程 Reactor,工作者线程池
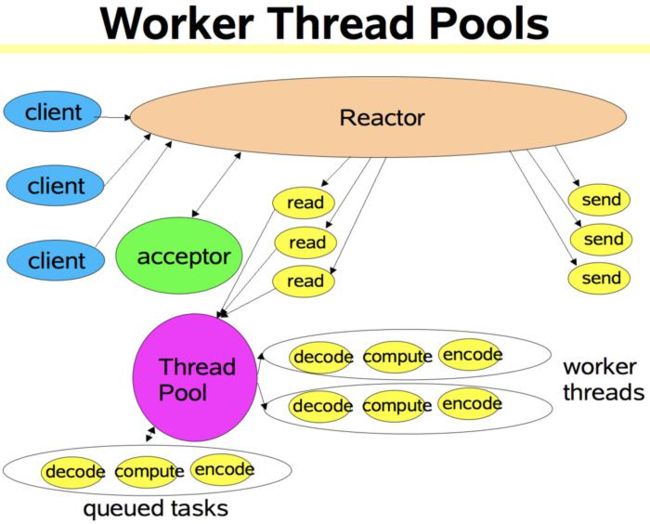
多 Reactor 线程模式

和观察者模式的区别
观察者模式:
也可以称为为 发布-订阅 模式,主要适用于多个对象依赖某一个对象 的状态, 并当某对象状态发生改变时,要通知其他依赖对象做出更新。是一种一 对多的关系。当然,如果依赖的对象只有一个时,也是一种特殊的一对一关系。 通常,观察者模式适用于消息事件处理,监听者监听到事件时通知事件处理者对 事件进行处理(这一点上面有点像是回调,容易与反应器模式和前摄器模式的回调搞混淆)。
Reactor 模式:
reactor 模式,即反应器模式,是一种高效的异步 IO 模式,特征是回调, 当 IO 完成时,回调对应的函数进行处理。这种模式并非是真正的异步,而是运 用了异步的思想,当 IO 事件触发时,通知应用程序作出 IO 处理。模式本身并不调用系统的异步 IO 函数。
reactor 模式与观察者模式有点像。不过,观察者模式与单个事件源关联, 而反应器模式则与多个事件源关联 。当一个主体发生改变时,所有依属体都得到通知。
Redis 中的线程和 IO 模型
Redis 基于 Reactor 模式开发了自己的网络事件处理器 - 文件事件处理器 (file event handler,后文简称为 FEH),而该处理器又是单线程的,所以 redis 设计为单线程模型。
采用 I/O 多路复用同时监听多个 socket,根据 socket 当前执行的事件来为 socket 选择对应的事件处理器。
当被监听的 socket 准备好执行 accept、read、write、close 等操作时,和操 作对应的文件事件就会产生,这时 FEH 就会调用 socket 之前关联好的事件处理 器来处理对应事件。
所以虽然 FEH 是单线程运行,但通过 I/O 多路复用监听多个 socket,不仅实 现高性能的网络通信模型,又能和 Redis 服务器中其它同样单线程运行的模块 交互,保证了 Redis 内部单线程模型的简洁设计。
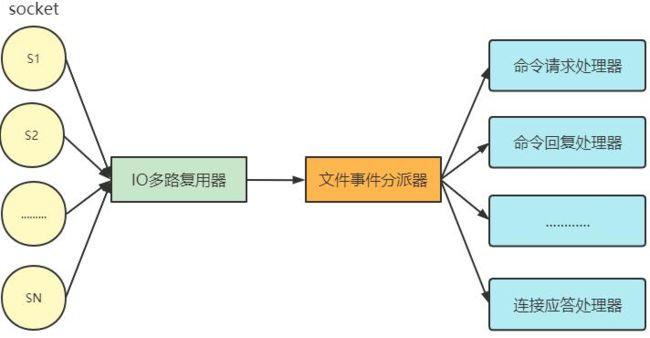
socket
文件事件就是对 socket 操作的抽象, 每当一个 socket 准备好执行连接 accept、read、write、close 等操作时, 就会产生一个文件事件。一个服务器通 常会连接多个 socket, 多个 socket 可能并发产生不同操作,每个操作对应不同 文件事件。
I/O 多路复用程序
I/O 多路复用程序会负责监听多个 socket。
尽管文件事件可能并发出现, 但 I/O 多路复用程序会将所有产生事件的 socket 放入队列, 通过该队列以有序、同步且每次一个 socket 的方式向文件事件分派器传送 socket。
当上一个 socket 产生的事件被对应事件处理器执行完后, I/O 多路复用程 序才会向文件事件分派器传送下个 socket, 如下:
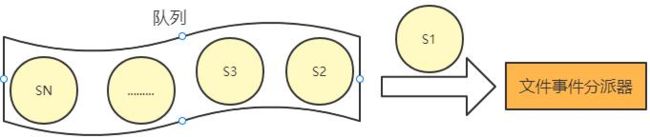
I/O 多路复用程序的实现
Redis 的 I/O 多路复用程序的所有功能都是通过包装常见的 select、epoll、 evport 和 kqueue 这些 I/O 多路复用函数库实现的。
evport = Solaris 10
epoll = Linux
kqueue = OS X*,*FreeBSD
select =通常作为 fallback安装在所有平台上
Evport,Epoll 和 KQueue 具有 O(1)描述符选择算法复杂度,并且它们都使用 内部内核空间内存结构.他们还可以提供很多(数十万个)文件描述符.
除其他外,select 最多只能提供 1024 个描述符,并且对描述符进行完全扫 描(因此每次迭代所有描述符以选择一个可使用的描述符),因此复杂性是 O(n)
文件事件分派器
文件事件分派器接收 I/O 多路复用程序传来的 socket, 并根据 socket 产生 的事件类型, 调用相应的事件处理器。
文件事件处理器
服务器会为执行不同任务的套接字关联不同的事件处理器, 这些处理器是 一个个函数, 它们定义了某个事件发生时, 服务器应该执行的动作。
Redis 为各种文件事件需求编写了多个处理器,若客户端连接 Redis,对连 接服务器的各个客户端进行应答,就需要将 socket 映射到连接应答处理器写数 据到 Redis,接收客户端传来的命令请求,就需要映射到命令请求处理器从 Redis 读数据,向客户端返回命令的执行结果,就需要映射到命令回复处理器当主服务 器和从服务器进行复制操作时, 主从服务器都需要映射到特别为复制功能编写 的复制处理器。
文件事件的类型
I/O 多路复用程序可以监听多个 socket 的 ae.h/AE_READABLE 事件和 ae.h/AE_WRITABLE 事件, 这两类事件和套接字操作之间的对应关系如下:
当 socket 可读(socket有数据可以读取写入到redis)(比如客户端对 Redis 执行 write/close 操作),或有新的可应答的 socket 出现时(即客户端对 Redis 执行 connect 操作),socket 就会产生一 个 AE_READABLE 事件。(文件处理器去操作socket,所以说是socket事件, socket是读事件, 文件处理器就是从socket读,写入到应用程序, 所以这里socket是读事件发生, 处理器监听到后读取数据写入到应用程序, 这里的引用程序值的是客户端或服务端, 客户端和服务端都有自己的IO模型, 可能不相同,但是类似)
当 socket 可写时(socket有数据可以写从redis读取)(比如客户端对 Redis 执行 read 操作),socket 会产生一个 AE_WRITABLE 事件。
I/O 多路复用程序可以同时监听 AE_REABLE 和 AE_WRITABLE 两种事件,要是 一个 socket 同时产生这两种事件,那么文件事件分派器优先处理 AE_REABLE 事 件。即一个 socket 又可读又可写时, Redis 服务器先读后写 socket。
总结
Redis 启动初始化时,将连接应答处理器跟 AE_READABLE 事件关联。
若一个客户端发起连接,会产生一个 AE_READABLE 事件,然后由连接应答 处理器负责和客户端建立连接(写事件不一定会导致数据写入),创建客户端对应的 socket,同时将这个 socket 的 AE_READABLE 事件和命令请求处理器关联,使得客户端可以向主服务器发送 命令请求。
当客户端向 Redis 发请求时(不管读还是写请求),客户端 socket 都会产生 一个 AE_READABLE 事件(总是需要知道命令才能知道读还是写操作,所以对于IO复用器, 处理的总是请求和响应, 读取,写入,删除是我们更具请求和响应结果的不同抽象出来的含义),触发命令请求处理器。处理器读取客户端的命令内容, 然后传给相关程序执行。(socket的读事件总是对应请求处理, socket的写总是对应响应)
当 Redis 服务器准备好给客户端的响应数据后,会将 socket 的 AE_WRITABLE 事件和命令回复处理器关联,当客户端准备好读取响应数据时,会在 socket 产生一个 AE_WRITABLE 事件,由对应命令回复处理器处理,即将准备好的响应数 据写入 socket,供客户端读取。
命令回复处理器全部写完到 socket 后,就会删除该 socket 的 AE_WRITABLE 事件和命令回复处理器的映射。(一般值值保留socket读事件)
Redis6 中的多线程
-
Redis6.0 之前的版本真的是单线程吗?
Redis 在处理客户端的请求时,包括获取 (socket 读)、解析、执行、内容返 回 (socket 写) 等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。 但如果严格来讲从 Redis4.0 之后并不是单线程,除了主线程外,它也有后台线程 在处理一些较为缓慢的操作,例如清理脏数据、无用连接的释放、大 key 的删 除等等。
-
Redis6.0 之前为什么一直不使用多线程?
官方曾做过类似问题的回复:使用 Redis 时,几乎不存在 CPU 成为瓶颈的情况, Redis 主要受限于内存和网络。例如在一个普通的 Linux 系统上,Redis 通过 使用 pipelining 每秒可以处理 100 万个请求,所以如果应用程序主要使用 O(N)或 O(log(N))的命令,它几乎不会占用太多 CPU。
使用了单线程后,可维护性高。多线程模型虽然在某些方面表现优异,但是 它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,增加了系 统复杂度、同时可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗。Redis 通过 AE 事件模型以及 IO 多路复用等技术,处理性能非常高,因此没有必要使用 多线程。单线程机制使得 Redis 内部实现的复杂度大大降低,Hash 的惰性 Rehash、Lpush 等等 “线程不安全” 的命令都可以无锁进行。
-
Redis6.0 为什么要引入多线程呢?
Redis 将所有数据放在内存中,内存的响应时长大约为 100 纳秒,对于小数 据包,Redis 服务器可以处理 80,000 到 100,000 QPS,这也是 Redis 处理的极限了, 对于 80%的公司来说,单线程的 Redis 已经足够使用了。
但随着越来越复杂的业务场景,有些公司动不动就上亿的交易量,因此需要 更大的 QPS。常见的解决方案是在分布式架构中对数据进行分区并采用多个服务 器,但该方案有非常大的缺点,例如要管理的 Redis 服务器太多,维护代价大; 某些适用于单个 Redis 服务器的命令不适用于数据分区;数据分区无法解决热点 读/写问题;数据偏斜,重新分配和放大/缩小变得更加复杂等等。
从 Redis 自身角度来说,因为读写网络的 read/write 系统调用占用了 Redis 执行期间大部分 CPU 时间,瓶颈主要在于网络的 IO 消耗, 优化主要有两个方向:
-
提高网络 IO 性能,典型的实现比如使用 DPDK 来替代内核网络栈的方式
-
使用多线程充分利用多核,典型的实现比如 Memcached。
-
协议栈优化的这种方式跟 Redis 关系不大,支持多线程是一种最有效最便 捷的操作方式。所以总结起来,redis 支持多线程主要就是两个原因:
- 可以充分利用服务器 CPU 资源,目前主线程只能利用一个核
- 多线程任务可以分摊 Redis 同步 IO 读写负荷
-
Redis6.0 默认是否开启了多线程?
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改 redis.conf 配置文件:
io-threads-do-reads yes# io-threads 4 # # Setting io-threads to 1 will just use the main thread as usual. # When I/O threads are enabled, we only use threads for writes, that is # to thread the write(2) syscall and transfer the client buffers to the # socket. However it is also possible to enable threading of reads and # protocol parsing using the following configuration directive, by setting # it to yes: # # io-threads-do-reads no # # Usually threading reads doesn't help much.开启多线程后,还需要设置线程数,否则是不生效的。
关于线程数的设置,官方有一个建议:4 核的机器建议设置为 2 或 3 个线程, 8 核的建议设置为 6 个线程,线程数一定要小于机器核数。还需要注意的是,线 程数并不是越大越好,官方认为超过了 8 个基本就没什么意义了。
-
Redis6.0 采用多线程后,性能的提升效果如何?
特性对性能提升至少是一倍以上。国内也有大牛曾使用 unstable 版本在阿里 云 esc 进行过测试,GET/SET 命令在 4 线程 IO 时性能相比单线程是几乎是翻倍 了。如果开启多线程,至少要 4 核的机器,且 Redis 实例已经占用相当大的 CPU 耗时的时候才建议采用,否则使用多线程没有意义。
-
Redis6.0 多线程的实现机制?
流程简述如下:
1、主线程负责接收建立连接请求,获取 socket 放入全局等待读处理队列
2、主线程处理完读事件之后,通过 RR(Round Robin) 将这些连接分配给这些IO线程
3、主线程阻塞等待 IO线程读取 socket 完毕
4、主线程通过单线程的方式执行请求命令,请求数据读取并解析完成,但并不执行回写 socket
5、主线程阻塞等待 IO 线程将数据回写 socket 完毕
6、解除绑定,清空等待队列
该设计有如下特点:
1、IO 线程要么同时在读 socket,要么同时在写,不会同时读或写
2、IO 线程只负责读写 socket 解析命令,不负责命令处理
-
开启多线程后,是否会存在线程并发安全问题?
从上面的实现机制可以看出,Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程顺序执行。所以我们不需要去考虑控制 key、lua、事务,LPUSH/LPOP 等等的并发及线程安全问题。
-
Redis6.0 的多线程和 Memcached 多线程模型进行对比
Memcached 服务器采用 master-woker 模式进行工作,服务端采用 socket 与客户端通讯。主线程、工作线程 采用 pipe 管道进行通讯。主线程采用 libevent 监听 listen、accept 的读事件,事件响应后将连接信息的数据结构封装起来,根据算法选择合适的工作线程,将连接任务携带连接信息分发出去,相应的线程利 用连接描述符建立与客户端的 socket 连接 并进行后续的存取数据操作。
相同点:都采用了 master 线程-worker 线程的模型
不同点:Memcached 执行主逻辑也是在 worker 线程里,模型更加简单, 实现了真正的线程隔离,符合我们对线程隔离的常规理解。而 Redis 把处理逻辑交还给 master 线程,虽然一定程度上增加了模型复杂度,但也解决了线程并 发安全等问题
缓存淘汰算法
当实际内存超出 maxmemory 时,Redis 提供了几种可选策略 (maxmemory-policy) 来让用户自己决定该如何腾出新的空间以继续提供读写服 务。
noeviction 不会继续服务写请求 (DEL 请求可以继续服务),读请求可以 继续进行。这样可以保证不会丢失数据,但是会让线上的业务不能持续进行。这 是默认的淘汰策略。
volatile-lru 尝试淘汰设置了过期时间的 key,最少使用的 key 优先被淘 汰。没有设置过期时间的 key 不会被淘汰,这样可以保证需要持久化的数据不 会突然丢失。
volatile-ttl 跟上面一样,除了淘汰的策略不是 LRU,而是 key 的剩余寿 命 ttl 的值,ttl 越小越优先被淘汰。
volatile-random 跟上面一样,不过淘汰的 key 是过期 key 集合中随机的 key。
allkeys-lru 区别于 volatile-lru,这个策略要淘汰的 key 对象是全体的 key 集合,而不只是过期的 key 集合。这意味着没有设置过期时间的 key 也会被淘 汰。
allkeys-random 跟上面一样,不过淘汰的策略是随机的 key。
总得来说,volatile-xxx 策略只会针对带过期时间的 key 进行淘汰, allkeys-xxx 策略会对所有的 key 进行淘汰。
使用场景
如果你只是拿 Redis 做缓存,那应 该使用 allkeys-xxx,客户端写缓存时不必携带过期时间。如果你还想同时使用Redis 的持久化功能,那就使用 volatile-xxx 策略,这样可以保留没有设置过期 时间的 key,它们是永久的 key 不会被 LRU 算法淘汰。
所以给key设置一个Long.MAX_VALUE过期时间和不设置过期时间是不同的, 因为设置过期时间的可能会被LRU算法淘汰掉
LRU 算法
实现 LRU 算法除了需要 key/value 字典外,还需要附加一个链表,链表中 的元素按照一定的顺序进行排列。当空间满的时候,会踢掉链表尾部的元素。当 字典的某个元素被访问时,它在链表中的位置会被移动到表头。所以链表的元素 排列顺序就是元素最近被访问的时间顺序。
位于链表尾部的元素就是不被重用的元素,所以会被踢掉。位于表头的元素 就是最近刚刚被人用过的元素,所以暂时不会被踢。
近似 LRU 算法
Redis 使用的是一种近似 LRU 算法,它跟 LRU 算法还不太一样。之所以不 使用 LRU 算法,是因为需要消耗大量的额外的内存,需要对现有的数据结构进行较大的改造。近似 LRU 算法则很简单,在现有数据结构的基础上使用随机采样法来淘汰元素,能达到和 LRU 算法非常近似的效果。Redis 为实现近似 LRU 算法,它给每个 key 增加了一个额外的小字段,这个字段的长度是 24 个 bit, 也就是最后一次被访问的时间戳。(redisObject的数据结构, java中 int 是四字节)
上一节提到处理 key 过期方式分为集中处理和懒惰处理,LRU 淘汰不一样, 它的处理方式只有懒惰处理。当 Redis 执行写操作时,发现内存超出 maxmemory,就会执行一次 LRU 淘汰算法。这个算法也很简单,就是随机采样 出 5(可以配置 maxmemory-samples) 个 key,然后淘汰掉最旧的 key,如果淘汰 后内存还是超出 maxmemory,那就继续随机采样淘汰,直到内存低于 maxmemory 为止。
如何采样就是看 maxmemory-policy 的配置,如果是 allkeys 就是从所有的 key 字典中随机,如果是 volatile 就从带过期时间的 key 字典中随机。每次采 样多少个 key 看的是 maxmemory_samples 的配置,默认为 5。
同时 Redis3.0 在算法中增加了淘汰池,新算法会维护一个候选池(大小为 16),池中的数据根据访问时间进行排序,第一次随机选取的 key 都会放入池中, 随后每次随机选取的 key 只有在访问时间小于池中最小的时间才会放入池中,直 到候选池被放满。当放满后,如果有新的 key 需要放入,则将池中最后访问时间 最大(最近被访问)的移除。进一步提升了近似 LRU 算法的效果。
Redis 维护了一个 24 位时钟,可以简单理解为当前系统的时间戳,每隔一定 时间会更新这个时钟。每个 key 对象内部同样维护了一个 24 位的时钟,当新增 key 对象的时候会把系统的时钟赋值到这个内部对象时钟。比如我现在要进行 LRU,那么首先拿到当前的全局时钟,然后再找到内部时钟与全局时钟距离时间 最久的(差最大)进行淘汰,这里值得注意的是全局时钟只有 24 位,按秒为单 位来表示才能存储 194 天,所以可能会出现 key 的时钟大于全局时钟的情况,如 果这种情况出现那么就两个相加而不是相减来求最久的 key。
LFU 算法
LFU 算法是 Redis4.0 里面新加的一种淘汰策略。它的全称是 Least Frequently Used,它的核心思想是根据 key 的最近被访问的频率进行淘汰,很少被访问的优 先被淘汰,被访问的多的则被留下来。
LFU 算法能更好的表示一个 key 被访问的热度。假如你使用的是 LRU 算法, 一个 key 很久没有被访问到,只刚刚是偶尔被访问了一次,那么它就被认为是热 点数据,不会被淘汰,而有些 key 将来是很有可能被访问到的则被淘汰了。如果 使用 LFU 算法则不会出现这种情况,因为使用一次并不会使一个 key 成为热点数 据。LFU 原理使用计数器来对 key 进行排序,每次 key 被访问的时候,计数器增 大。计数器越大,可以约等于访问越频繁。具有相同引用计数的数据块则按照时 间排序。
LFU 一共有两种策略:
volatile-lfu:在设置了过期时间的 key 中使用 LFU 算法淘汰 key
allkeys-lfu:在所有的 key 中使用 LFU 算法淘汰数据
LFU 把原来的 key 对象的内部时钟的 24 位分成两部分,前 16 位 ldt 还代表时钟,后 8 位 logc 代表一个计数器。
logc 是 8 个 bit,用来存储访问频次,因为 8 个 bit 能表示的最大整数值为 255,存储频次肯定远远不够,所以这 8 个 bit 存储的是频次的对数值,并且这 个值还会随时间衰减,如果它的值比较小,那么就很容易被回收。为了确保新创 建的对象不被回收,新对象的这 8 个 bit 会被初始化为一个大于零的值 LFU INIT_VAL(默认是=5)。
ldt 是 16 个 bit,用来存储上一次 logc 的更新时间。因为只有 16 个 bit,所 精度不可能很高。它取的是分钟时间戳对 2 的 16 次方进行取模。
ldt 的值和 LRU 模式的 lru 字段不一样的地方是, ldt 不是在对象被访问时更新的,而是在 Redis 的淘汰逻辑进行时进行更新,淘汰逻辑只会在内存达到 maxmemory 的设置时才会触发,在每一个指令的执行之前都会触发。每次淘汰 都是采用随机策略,随机挑选若干个 key,更新这个 key 的“热度”,淘汰掉 “热度”最低的 key。因为 Redis 采用的是随机算法,如果 key 比较多的话,那 么 ldt 更新得可能会比较慢。不过既然它是分钟级别的精度,也没有必要更新得 过于频繁。ldt 更新的同时也会一同衰减 logc 的值。
为什么 Redis 要缓存系统时间戳
我们平时使用系统时间戳时,常常是不假思索地使用 System.currentTimeInMillis 或者 time.time()来获取系统的毫秒时间戳。Redis 不能 这样,因为每一次获取系统时间戳都是一次系统调用,系统调用相对来说是比较费时间的,作为单线程的 Redis 承受不起,所以它需要对时间进行缓存,由一个 定时任务,每毫秒更新一次时间缓存,获取时间都是从缓存中直接拿。
过期策略和惰性删除
过期
Redis 所有的数据结构都可以设置过期时间,时间一到,就会自动删除。但 是会不会因为同一时间太多的 key 过期,以至于忙不过来。同时因为 Redis 是单 线程的,收割的时间也会占用线程的处理时间,如果收割的太过于繁忙,会不会导 致线上读写指令出现卡顿。
过期的 key 集合
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定时遍历这个字典来删除到期的 key。除了定时遍历之外,它还会使用惰性策略来删除过期的 key,所谓惰性策略就是在客户端访问这个 key 的时候,redis 对 key 的过期时间进行检查,如果过期了就立即删除。定时删除是集中处理,惰性删除是零散处理。
定时扫描策略
Redis 默认会每秒进行十次过期扫描,过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
1、从过期字典中随机 20 个 key;
2、删除这 20 个 key 中已经过期的 key;
3、如果过期的 key 比率超过 1/4,那就重复步骤 1;
毫无疑问,Redis 会持续扫描过期字典 (循环多次),直到过期字典中过期的 key 变得稀疏,才会停止 (循环次数明显下降)。这就会导致线上读写请求出现明 显的卡顿现象。导致这种卡顿的另外一种原因是内存管理器需要频繁回收内存页, 这也会产生一定的 CPU 消耗。
所以业务开发人员一定要注意过期时间,如果有大批量的 key 过期,要给 过期时间设置一个随机范围,而不能全部在同一时间过期。(所以缓存雪崩对服务器的内存集中挥手也有影响)
从库的过期策略
从库不会进行过期扫描,从库对过期的处理是被动的。主库在 key 到期时, 会在 AOF 文件里增加一条 del 指令,同步到所有的从库,从库通过执行这条 del 指令来删除过期的 key。
因为指令同步是异步进行的,所以主库过期的 key 的 del 指令没有及时同 步到从库的话,会出现主从数据的不一致,主库没有的数据在从库里还存在。(所以redis默认从库只是一个主备方案(高可用), 不是一个读写分离方案(提高吞吐量, 给主库分担压力))
惰性删除
所谓惰性策略就是在客户端访问这个 key 的时候,redis 对 key 的过期时间进 行检查,如果过期了就立即删除,不会给你返回任何东西。
定期删除可能会导致很多过期 key 到了时间并没有被删除掉。所以就有了惰 性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非 你的系统去查一下那个 key,才会被 redis 给删除掉。这就是所谓的惰性删除, 即当你主动去查过期的 key 时,如果发现 key 过期了,就立即进行删除,不返回任何 东西.
总结:定期删除是集中处理,惰性删除是零散处理。
lazyfree
使用 DEL 命令删除体积较大的键, 又或者在使用 FLUSHDB 和 FLUSHALL 删除包含大量键的数据库时,造成 redis 阻塞的情况;另外 redis 在清理过期数据 和淘汰内存超限的数据时,如果碰巧撞到了大体积的键也会造成服务器阻塞。
为了解决以上问题, redis 4.0 引入了 lazyfree 的机制,它可以将删除键或 数据库的操作放在后台线程里执行, 从而尽可能地避免服务器阻塞。
lazyfree 的原理不难想象,就是在删除对象时只是进行逻辑删除,然后把对 象丢给后台,让后台线程去执行真正的 destruct,避免由于对象体积过大而造成 阻塞。redis 的 lazyfree 实现即是如此,下面我们由几个命令来介绍下 lazyfree 的 实现。
4.0 版本引入了 unlink 指令,它能对删除操作进行懒处理,丢给后台线程 来异步回收内存。
UNLINK 的实现中,首先会清除过期时间,然后调用 dictUnlink 把要删除的对 象从数据库字典摘除,再判断下对象的大小(太小就没必要后台删除),如果足 够大就丢给后台线程,最后清理下数据库字典的条目信息。
主线程将对象的引用从「大树」中摘除后,会将这个 key 的内存回收操作 包装成一个任务,塞进异步任务队列,后台线程会从这个异步队列中取任务。任 务队列被主线程和异步线程同时操作,所以必须是一个线程安全的队列。
Redis 提供了 flushdb 和 flushall 指令,用来清空数据库,这也是极其缓慢 的操作。Redis 4.0 同样给这两个指令也带来了异步化,在指令后面增加 async 参 数就会进入后台删除逻辑。
AOF Sync 也很慢,Redis 需要每秒一次(可配置)同步 AOF 日志到磁盘,确保 消息尽量不丢失,需要调用 sync 函数,这个操作会比较耗时,会导致主线程的 效率下降,所以 Redis 也将这个操作移到异步线程来完成。执行 AOF Sync 操作的 线程是一个独立的异步线程,和前面的懒惰删除线程不是一个线程,同样它也有 一个属于自己的任务队列,队列里只用来存放 AOF Sync 任务。
Redis 回收内存除了 del 指令和 flush 之外,还会存在于在 key 的过期、 LRU 淘汰、rename 指令以及从库全量同步时接受完 rdb 文件后会立即进行的 flush 操作。Redis4.0 为这些删除点也带来了异步删除机制,打开这些点需要额 外的配置选项。
1、slave-lazy-flush 从库接受完 rdb 文件后的 flush 操作
2、lazyfree-lazy-eviction 内存达到 maxmemory 时进行淘汰
3、lazyfree-lazy-expire key 过期删除
4、lazyfree-lazy-server-del rename 指令删除 destKey