【原创】这道Java基础题真的有坑!我也没想到还有续集。
前情回顾
自从我上次发了《这道Java基础题真的有坑!我求求你,认真思考后再回答。》这篇文章后。我通过这样的一个行文结构:

解析了小马哥出的这道题,让大家明白了这题的坑在哪里,这题背后隐藏的知识点是什么。

但是我是万万没想到啊,这篇文章居然还有续集。因为有很多读者给我留言,问我为什么?怎么回事?啥情况?
问题片段一:到底循环几次?
有很多读者针对文章的下面的这个片段:

来问了一些问题:为什么会循环三次?循环二次?循环一次?
源码看的脑袋疼。那我觉得我需要"拯救"一下这个哥们了。

问题片段二:为什么删除第一个不出错?
还有这个片段,对于为什么删除第一个元素不会抛出异常,也是一众选手,不明就里:

为什么?为什么没有问题啊?


提炼问题
上面看着有点乱是不是呢?
那肯定是你没看过我这篇文章《这道Java基础题真的有坑!我求求你,认真思考后再回答。》。没关系,我先把问题提炼出来,然后有兴趣你可以再去看看这篇文章。
在描述问题之前,需要说明一下,为了方便演示说明,我会去掉Java的foreach语法糖,直接替换为编译后的代码,如下:

请坐稳扶好,下面的几个问题有点绕。主要是看图,先知道这几个现象。之后我还会把问题再简化一下。
问题一:如图所示,为什么删除第一个元素(公众号)可以正常执行,删除第二个元素(why技术)就会抛出异常呢?


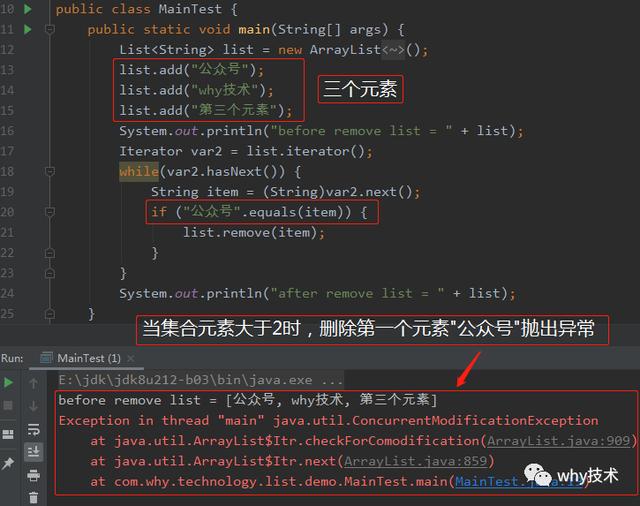
问题二:为什么当集合大小大于2时,删除第一个元素(公众号)也抛出了异常?
问题三:为什么删除倒数第二个元素可以正常执行?删除倒数第二个元素以外的任意元素就会抛出异常?


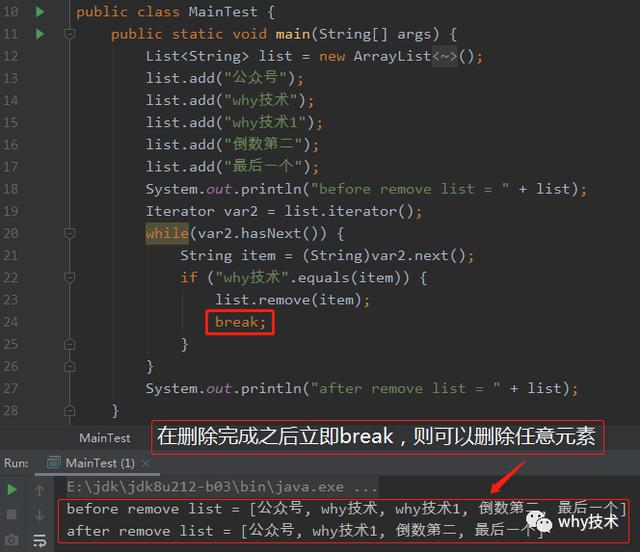
问题四:为什么在删除完成之后立即break,则可以删除任意元素呢?
问题五:如图所示,为什么注释掉判断语句直接remove("why技术")不会报错,而加上判断语句就报错了呢?


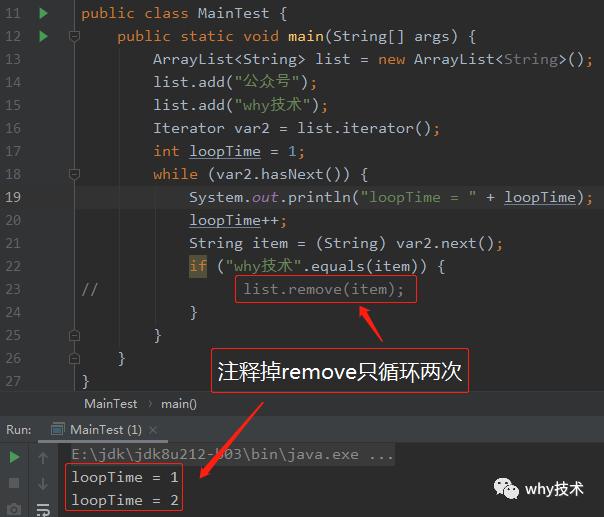
问题六:为什么判断"why技术"并remove的时候循环三次?为什么注释掉remove只循环两次?为什么判断"公众号"并remove的时候只循环一次?


我再把问题汇总一下,你瞟一眼就行,不用细读:
问题一:当集合大小等于2时,为什么删除第一个元素(公众号)可以正常执行,删除第二个元素(why技术)就会抛出异常呢?
问题二:为什么当集合大小大于2时,删除第一个元素(公众号)也抛出了异常?
问题三:为什么删除倒数第二个元素可以正常执行?删除倒数第二个元素以外的任意元素就会抛出异常?
问题四:为什么在删除完成之后立即break,则可以删除任意元素不会报错呢?
问题五:为什么注释掉判断语句直接remove(why技术)不会报错,而加上判断语句就报错了呢?
问题六:为什么判断"why技术"并remove的时候循环三次?为什么注释掉remove只循环两次?为什么判断"公众号"并remove的时候只循环一次?
晕不晕?
不要晕。上面我只是为了把各种情况都执行一下,然后截图出来,方便大家有个直观的理解。其实,上面的这六个问题,我在看来就只有两个问题:
1.当前循环会执行几次?
2.为什么会抛出异常?
而这两个问题中的第二个问题【为什么会抛出异常?】我已经在《这道Java基础题真的有坑!我求求你,认真思考后再回答。》这篇文章中进行了十分详尽的解答。所以,就不在这篇文章中讨论了。
那么,现在就只剩下一个问题了:当前循环会执行几次?
本文会围绕这个问题进行展开,当你明白这个问题后,上面的所有问题都迎刃而解了。
明确分析程序
我们就拿下面这个程序来进行分析:

我写文章之前,在Debug模式下碰到了一些不是程序导致的意外bug(我怀疑是jdk或idea版本的问题),我最后会讲一下,而且我觉得Debug模式也不太好对这个问题进行直观的文字描述,需要截取大量图片,这样不太方便阅读。所以为了更好的解释这个问题,更加方便大家阅读,我们先进行几个"骚"操作,对程序进行一下改造。
正如上图红色粗线框起来的代码所示。由于这个循环体循环几次是由while里面的条件hasNext()方法,即【cursor!=size】这个条件决定的。
hasNext()方法是ArrayList中一个叫做Itr内部类中的一个方法。

如果我们能把hasNext()方法修改成这个样子,加上几行输出,对于我们的分析来说简直完美,直观,漂亮。(Java程序员确实是靠日志活着。)
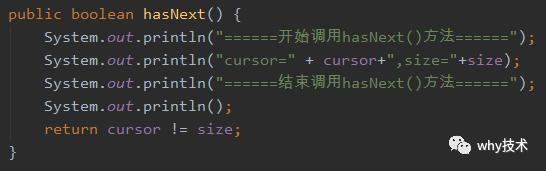
这里我们就不去编译一套JDK然后修改源码了,可以投机取个巧,和我之前的文章中说的一样,我们自定义一个ArrayList。
改造点一:自定义ArrayList
我们怎么自定义ArrayList呢?
首先,我们的需求是为了演示问题方便,但是我们的前提是得保证实验对象的一致性,换句话说就是:我们自定义的ArrayList需要和JDK的ArrayList的实现,一模一样,只是换个名称而已。
所以,我们直接把JDK的ArrayList拷贝一份出来并修改一个名字即可。
直接拷贝一个ArrayList过来后你发现会有报错的地方:

具体报错的信息如下:
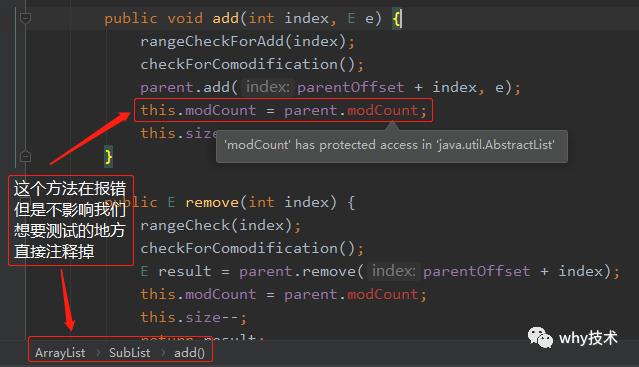
并不影响我们这次的测试。所以直接注释掉相关报错的地方。为了便于区分,我们修改名称为WhyArrayList,并修改对应的代码:

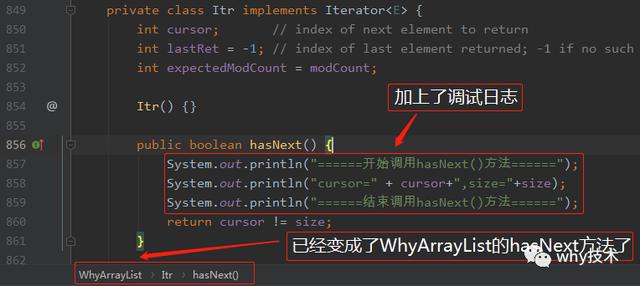
到这一步我们自定义的ArrayList就算是改造完成了。只需要把他用起来即可,怎么用,很简单,替换原来的ArrayList即可,如下图所示(如果不清晰,可以点看看大图哦):

但是我觉得输出的日志还是不够清晰,直观。我想要直接输出当前是第几次循环,如下:

那我们怎么实现呢?这就是我们的第二个改造点了。
改造点二:自定义Iterator
要实现上面的日志输出我们很容易能想到第一个修改点,如下:

现在我们的问题是怎么把loopTime(循环次数)这个值传进来。直接调用肯定是不行的, Iterator并没有这个方法。可以看看提示:

那怎么办呢?
你想啊,Iterator是一个接口,既然它没有这个方法,那我们也就自定义一个WhyIterator继承JDK的Iterator,然后在WhyIterator里面定义我们想要的接口即可:
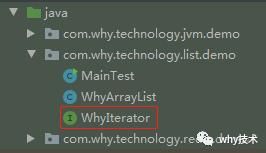

然后我们在WhyArrayList里面只需要让内部类Itr实现WhyIterator接口即可:

最后一步,调用起来,修改程序,并执行如下:
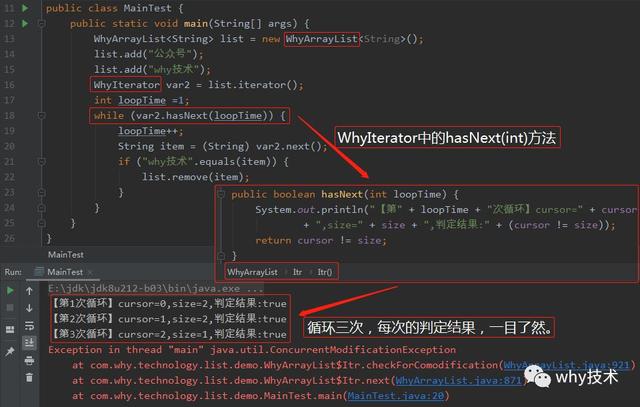
啊,这日志,舒服了!
接下来,我们进行丧心病狂的第三个改造点:
改造点三:一步一输出
这一个改造点,我就不进行详细说明了,授人以鱼不如授人以渔,前面两个改造点你如果会了,那你也能继续改造,得到下面的程序,并搞出一步一输出日志:
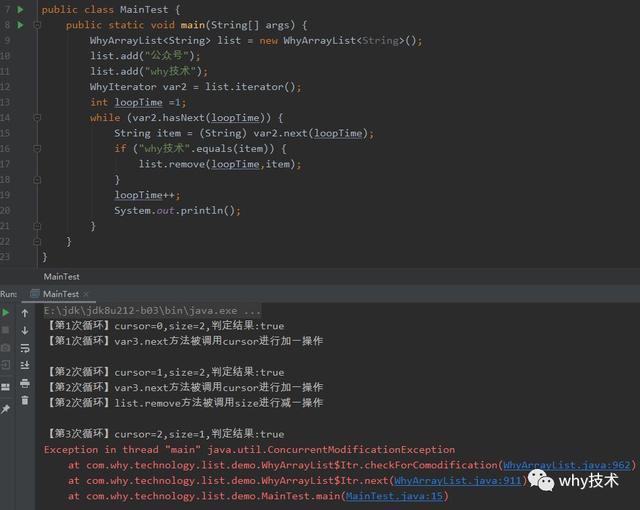
上面这图,就是我们最后需要分析的程序和日志了。
如果你对于得到上面的输出还是有点困难的话,你可以在文末找到我的git地址,我把程序都上传到了git上。
真相已经摆在眼前了
其实你想一想,还用分析吗?经过上面的三个"骚"操作后,真相已经摆在眼前了。
以这位读者的问题举例.
第一个问题:为什么判断"why技术"并remove的时候循环三次?
你品一品这个输出,这就是真相呀!为什么会循环三次,一目了然了啊!
【第1次循环】cursor=0,size=2,判定结果:true
【第1次循环】var3.next方法被调用cursor进行加一操作
【第2次循环】cursor=1,size=2,判定结果:true
【第2次循环】var3.next方法被调用cursor进行加一操作
【第2次循环】list.remove方法被调用size进行减一操作
【第3次循环】cursor=2,size=1,判定结果:true

再回答另外一个问题:为什么注释掉remove只循环两次?
你再品一品这个输出:

第三个问题:为什么判断"公众号"并remove的时候只循环一次?
继续品这个输出:

致命一问,灵魂一击
对于之前列举的其他问题,你有没有发现其实有很多共同的地方,但是我故意扰乱了你的判断,你仔细读这几个问题:
当集合大小等于2时,为什么删除第一个元素(公众号)可以正常执行?
当集合大小大于2时,删除第一个元素(公众号)也抛出了异常?
为什么删除倒数第二个元素可以正常执行?
上面的三个问题其实是在说一个问题,你发现了吗?
当集合大小等于2时第一个元素(公众号),是不是就是倒数第二个元素?!
恍然大悟有没有?
再看一个示例:

下图是上面示例的输出:

敲黑板,数学推理来了:
在单线程的情况下,只要你的ArrayList集合大小大于等于2(假设大小为n,即size=n),你删除倒数第二个元素的时候,cursor从0进行了n-1次的加一操作,size(即n)进行了一次减1的操作,所以n-1=n-1,即cursor=size。
因为判断条件返回为fales,虽然你的modCount变化了。但是不会进入下次循环,就不会触发modCount和expectedModCount的检查,也就不会抛出ConcurrentModifyException.
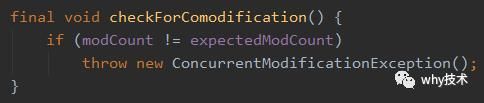
所以这个问题我也就回答了。

意外收获
我在写文章的过程中,还有意外收获。就是一个读者提出的这个问题:为什么迭代器里面的hasNext()里面要用!=来判断index和size之间的关系,而不是用<符号呢。


当时我并没有留意到这个问题,我觉得就是都可以,无关紧要。但是写的时候我突然想明白了,这可不是无关紧要的事,这地方必须是 【!=】。
我给你看个表格:

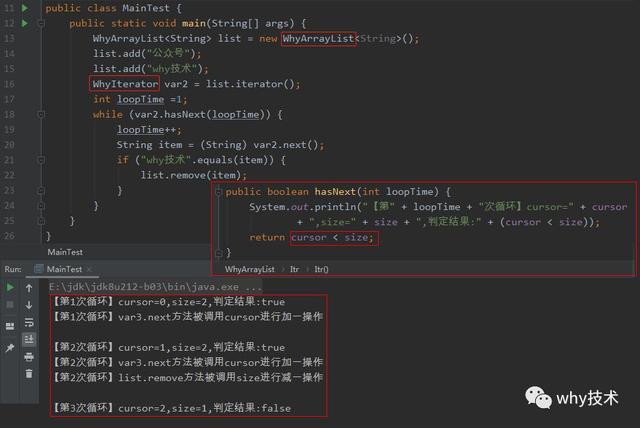
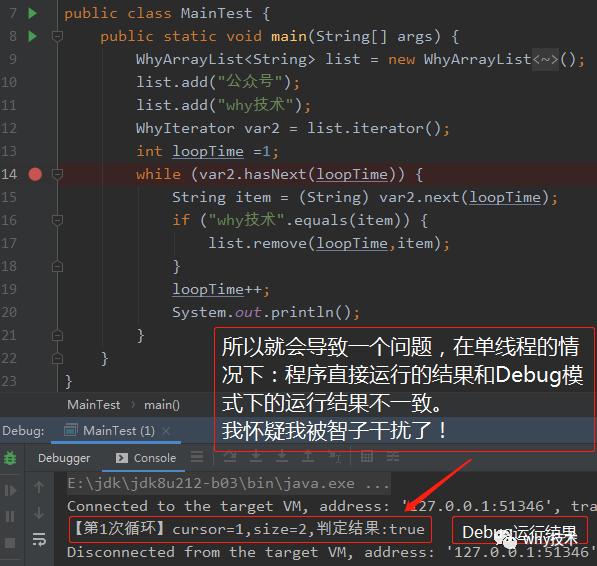
在上面的程序中我把判断条件改为了【cursor 正如我截图中说的:这里用【!=】判断,是符合它的语境的。用迭代器循环的时候,循环结束的条件就是循环到最后一个元素就停止循环。但是这一条件的前提是在我循环的过程中,集合大小是固定的。如果集合大小发生了变化,那就会触发fail-fast机制。 说到这个问题,我真的觉得我被智子封锁了,我开始理解那些科学家为什么要自杀了。如果你读过《三体》,你知道我在说什么。 不论是用我们自定义的WhyArrayList还是JDK的ArrayList结果都是一样的,为了结果的直观,我用WhyArrayList给你演示一下: 第一步是没有问题的: 但是当进入第一次循环,cursor=1,return之前又变成了2。 所以程序在Debug模式下的输出变成了这样: 我的Idea版本是:IntelliJ IDEA 2019.2.4 (Ultimate Edition) 我的JDK版本信息如下: openjdk version "1.8.0_212" OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_212-b03) OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.212-b03, mixed mode) 如果你也碰到过,你知道是怎么情况,请你告诉我究竟是怎么回事,是不是计划的一部分。 本文前传 答应我,如果你不知道这个知识点,想完全掌握的话,一定要去读一读本文的前传《这道Java基础题真的有坑!我求求你,认真思考后再回答。》。两篇文章合计一起食用,味道更佳。 本文代码 本文的源码我已经上传到git上了,git地址如下: git clone [email protected]:thisiswanghy/WhyArrayList.git fail-fast机制和fail-safe机制 文中多次提到了"fail-fast"机制(快速失败),与其对应的还有"fail-safe"机制(失败安全)。 这种机制是一种思想,它不仅仅是体现在Java的集合中。在我们常用的rpc框架Dubbo中,在集群容错时也有相关的实现。 Dubbo 主要提供了这样几种容错方式: Failover Cluster - 失败自动切换 Failfast Cluster - 快速失败 Failsafe Cluster - 失败安全 Failback Cluster - 失败自动恢复 Forking Cluster - 并行调用多个服务提供者 如果对这两种机制感兴趣的朋友可以查阅相关资料,进行了解。如果想要了解Dubbo的集群容错机制,可以看官方文档,地址如下: http://dubbo.apache.org/zh-cn/docs/source_code_guide/cluster.html Java语法糖 文中说到foreach循环的时候提到了Java的语法糖。如果对这一块有兴趣的读者,可以在网上查阅相关资料,也可以看看《深入理解Java虚拟机》的第10.3节,有专门的介绍。 书中说到: 总而言之,语法糖可以看做是编译器实现的一些“小把戏”,这些“小把戏”可能会使得效率“大提升”,但我们也应该去了解这些“小把戏”背后的真实世界,那样才能利用好它们,而不是被它们所迷惑。 阿里Java开发手册 阿里Java开发手册中也有对该问题的描述,强制要求: 不要在foreach循环里面进行元素的remove/add操作。remove元素请使用Iterator方式,如果并发操作,需要对Iterator对象加锁。 阿里的孤尽大佬作为主要作者写的这本《阿里Java开发手册》,可以说是呕心沥血推出的业界权威,非常值得阅读。读完此书,你不仅能够获得很多干货,甚至你还能读出一点技术情怀在里面。 对于技术情怀,孤尽大佬是这样的说的: 热爱、思考、卓越。热爱是一种源动力,而思考是一个过程,而卓越是一个结果。如果给这三个词加一个定语,使技术情怀更加立体、清晰地被解读,那就是奉献式的热爱,主动式的思考,极致式的卓越。 如果你之前对于这个知识点掌握的不牢固,读完这篇文章之后你会知道有这么一个知识点,但是仅仅是知道,不是一个十分具化的印象。只有你实际的操作一下之后,才能算是掌握了,源码会刻在你的潜意识里面。久久不会忘记。这部分现在对我来说,我输出了共计1万3千多字的文章,在我的脑海中固若金汤。 所以我个人建议,最好再去实际操作一下吧。git地址我前面给你了。 再推销一下我公众号:对于写文章,其实想到写什么内容并不难,难的是你对内容的把控。关于技术性的语言,我是反复推敲,查阅大量文章来进行证伪,总之慎言慎言再慎言,毕竟做技术,我认为是一件非常严谨的事情,我常常想象自己就是在故宫修文物的工匠,在工匠精神的认知上,目前我可能和他们还差的有点远,但是我时常以工匠精神要求自己。就像我之前表达的:对于技术文章(因为我偶尔也会荒腔走板的聊一聊生活,写一写书评,影评),我尽量保证周推,全力保证质量。坚持输出原创。 才疏学浅,难免会有纰漏,如果你发现了错误的地方,还请你留言给我指出来,我对其加以修改。
智子封锁:Debug下的问题




扩展阅读



最后说一句
以上。
谢谢您的阅读,感谢您的关注。