教你如何优化MySQL慢查询SQL语句?快速提升系统性能!
前言
应用系统性能测试过程中,性能优化是绕不开的话题,对测试人员而言,性能优化的第一站就是SQL语句的优化与分析。因此本文主要以MySQL数据库为例,介绍常见的慢查询SQL语句执行效率分析与优化方法和简单示例,为致力于应用系统性能优化的从业人员提供一定参考和借鉴。

1、慢查询定位
1)慢查询 慢查询SQL语句,即在数据库执行耗时超过一定阈值的SQL语句,常见阈值为500~2000ms,可根据业务需求适当调整。如存在大量慢查询语句会直接导致系统响应时间变长,降低用户体验感,因此慢查询的定位与优化是SQL语句优化的主要内容。 慢查询调优的第一步是准确定位慢查询语句,需要数据库开启慢查询日志记录功能,然后借助工具对日志进行分析实现慢查询SQL语句的准确定位。 --慢查询开启状态、日志位置 show variables like`slow_query%`; --慢查询命中时长 show variables like`long_query_time`;
2)mysqldumpslow慢查询日志分析
MySql数据库的慢查询SQL语句,可以借助mysqldumpslow工具进行分析;其他类型数据库,可根据官方提供的技术文档采用对应的工具开展慢查询日志分析。
慢查询日志分析的常用参数说明如下:

例:用时最多的10条慢SQL(后半部分为slow_query_log_file地址)
sql mysqldumpslow-s t-t 10-g'select'/data/mysql/data/dcbi-3306/log/slow.log
2 SQL语句执行分析
1)SQL执行顺序 分析SQL语句执行效率的第一步,需要了解一条SQL语句的执行顺序,从而为语句优化提供依据。一般而言,执行顺序为: from->where->group by->聚合函数(sum、avg)->having->计算公式->select字段->order by->limit
2)explain关键字 SQL语句执行分析可通过在SQL语句前添加“explain”关键字后,在数据库编辑器中执行查看语句具体的执行情况。 explain select*from table_name where columns_1=value_1 and columns_2=vales_2
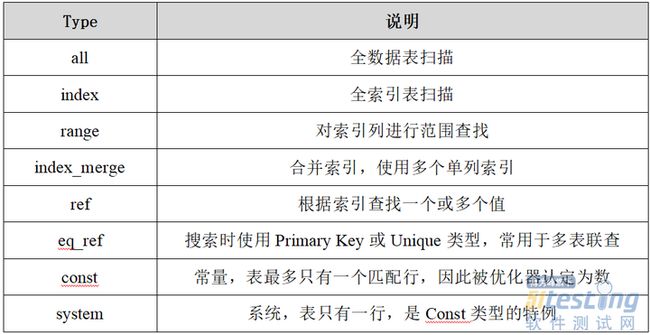
3)SQL执行计划返回结果说明 返回结果各列说明可按需查询相关资料,重点关注【type】、【ref】、【extra】反映查询效率的3列,以【type】为主即可。
![]()
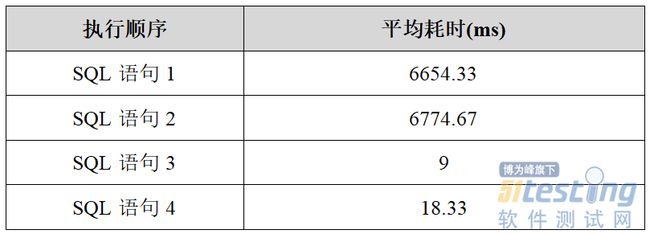
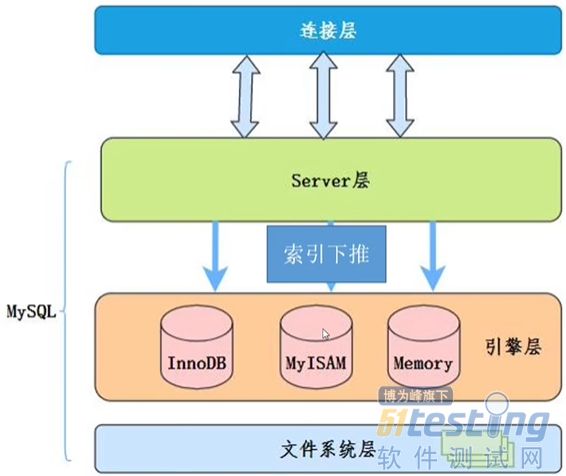
4)SQL执行效率分析 explain语句根据【type】列的值判断SQL执行效率,效率从低到高依次为: all 5)SQL语句执行效率对比 在开展SQL优化的过程中,对比两条SQL语句执行时间验证优化效果时,需要明确语句执行过程中数据的存取方式。根据数据库数据查询机制,若数据库内存中已存在目标数据,则直接从内存中获取数据,不再是从数据库物理磁盘获取数据。这种情况下,当优化前SQL语句执行后,目标数据已暂存于数据库内存中时;执行优化后SQL语句时,则直接从数据库内存中获取数据,导致该语句执行时间失真。 为避免验证优化效果时,出现上述SQL语句执行时间失真的情况,需在select关键字后添加SQL_NO_CACHE关键字声明,通过数据库引擎重新查询数据。SQL_NO_CACHE指的是查询结果在内存展示后,直接从内存中释放,并非不从内存中读取数据。因此,若在执行SQL_NO_CACHE之前已经查询过目标数据,导致目标数据已经在数据库内存中,则该语句失效。 用法示例如下: select SQL_NO_CACHE columns from table_name where column_1=vales_1 and columns_2=values_2; 需要说明的是,SQL_CACHE、SQL_NO_CACHE命令在MySQL 5.7.20开始废弃,MySQL 8.0后彻底移除,普通select命令即直接从数据库中获取数据,无需从数据库内存中获取数据。其他类型数据库相关机制,按需查阅对应官方技术文档。 3.常见SQL优化方法 1)索引覆盖 SQL优化最常见的方法,就是实现索引覆盖,即select后的查询列、where后的查询条件均包含索引,通过查询条件即可获得查询列数据。 常见索引覆盖场景: 1)使用主键索引,select后的查询列不包含主键,则无法实现索引覆盖; 2)使用非主键索引,select后的查询列包含非主键索引,可实现索引覆盖; 3)使用非主键索引,select后的查询列包含主键索引,可实现索引覆盖。 2)最左匹配原则 MySQL建立联合索引(多列索引)时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。具体是因为,索引最左列全局有序、其余列局部有序但全局无序,因此根据索引查询必须满足最左匹配原则,否则索引失效。 基于最左匹配原则,在创建索引时,根据业务需求,where中使用最频繁的列放在最左边; 最左匹配原则,遇到范围查询(>、<、between)时会停止匹配,即范围查询后的索引失效; 示例1:某张表索引按序为(a,b,c),如筛选条件为where a=1 and b=2,索引a、b均被使用到;如筛选条件为where b=2,则因未使用a=1,不满足最左匹配,索引失效;where a=1 and b>1 and c=3,因b为范围查询,b、c均索引失效。 示例2:某张表索引按序为(a,b,c),其中b字段在表table的所有值均为常量02003,同一个查询有4种不同的SQL语句写法: --SQL语句1 select*from table where c='62412001090472816354' --SQL语句2 select*from table where b='02003'and c='62412001090472816354' --SQL语句3 select*from table where a='344589'and b='02003'and c='62412001090472816354' --SQL语句4 select*from table where a='344589'and c='62412001090472816354' 上述SQL语句执行3次平均耗时分别为: 结论:SQL语句1、SQL语句2因不满足最左匹配原则,导致索引失效,查询耗时较长;SQL语句3、SQL语句4使用到索引,查询速度较快;但SQL语句4因缺失索引字段b,相对SQL语句3耗时较长,可见索引字段b即便在整张表中均为常量,列入where后的筛选条件,依然能提高查询效率。 3)索引条件下推 目的:检索数据时采用组合索引,且第一索引非等值索引时,尽量利用其他索引条件精准选择目标数据,减少数据多次回表判断是否符合目标数据的次数,以解决慢查询导致的性能问题。 方法:服务层(Server层)把查询工作下推到数据库引擎(InnoDB)去处理。 优势:减少回表查询次数,提高查询效率,降低数据库IO资源消耗。 判断:explain SQL输出【extra】列结果为using index condition。 下面详细对比使用下推和未使用下推时的数据库底层逻辑,进一步说明索引条件下推的优势。 使用下推 第一索引非等值索引的SQL语句使用索引条件时,应用层将查询请求发送至引擎层,引擎层根据索引条件,剔除不满足其他索引的数据,将剩余满足其他索引条件的数据返回应用层,尽量少回表地检索到对应记录。 使用条件下推时,引擎层可直接剔除不满足非第一索引中各列的数据。 未使用下推 SQL语句存在多个索引时,数据库Server层将查询请求发送至引擎层处理,引擎层按索引顺序,返回符合请求的数据到应用层。 数据库Server层完成筛选后,再按序发送下一索引检索条件,多次重复,直到满足所有查询条件。 如此多次循环,导致数据库IO资源消耗较高。 (4)小表驱动大表 根据表的结果集大小选择驱动表,一般使用小表作为驱动表 例如,某系统存在表table_a、表table_b,数据量分别为100万、10万,则查询两表关联数据时,将表table_b作为子表: select*from table_a where column_1=''and column_2 in(select column_2 from table_b where...) 若必须使用大表table_a作为子表,则使用exists关键字。 select*from table_a where exists(select column_2 from table_b where...) (5)in代替or 若where后查询条件中某字段存在多个值,则用in代替or。 select*from ar_ar_41 where ID_SHARD='10800000'and(NUM_SEQ_AR='11090141150000002'or NUM_SEQ_AR='11090141450000005'); select*from ar_ar_41 where ID_SHARD='10800000'and NUM_SEQ_AR in('11090141150000002','11090141450000005'); (6)分组避免排序 MySQL默认对所有group by字段进行排序,非必要情况下,分组避免排序。 SELECT goods_id,count(*)FROM t GROUP BY goods_id ORDER BY NULL; (7)批量INSERT插入 插入多条数据时,尽量避免逐条数据插入,优先选择批量数据插入(插入数据量在50条及以上)。 --批量数据插入 INSERT INTO t(id,name)VALUES(1,’Bea’),(2,’Belle’),(3,’Bernice’); --逐条数据插入 INSERT INTO t(id,name)VALUES(1,’Bea’); INSERT INTO t(id,name)VALUES(2,’Belle’); INSERT INTO t(id,name)VALUES(3,’Bernice’); 4、典型的索引失效案例 表city的联合索引为(ID,CountryCode),非索引列(Name,District,Population) 1)where索引列表达式计算 索引失效 select*from world.city where ID+1=4000; 索引未失效 select*from world.city where ID=4001; 2)where索引列使用函数 索引失效 select*from world.city where substring(CountryCode,1,2)='nl'; 索引未失效 select*from world.city where CountryCode like'nl%';select*from world.city where CountryCode like'nl_'; 3)or条件包含非索引列 索引失效 select*from world.city where ID=4001 or Name='Simi Valley'; 索引未失效 select*from world.city where ID=4001 or CountryCode='USA'; 4)like模糊查询,%在字首 索引失效 select*from world.city where CountryCode like'%nld%'; 索引未失效 select*from world.city where CountryCode like'nld%'; 5)不满足最左匹配原则 索引失效 select*from world.city where CountryCode='USA'and Population=111351; 索引未失效 select*from world.city where ID=4001 and CountryCode='USA'and Population=111351; 备注:最左匹配导致的索引失效情况较多,详见最左匹配部分。 6)索引列未设置为NOT NULL MySQL执行查询时会判断字段是否为NOT NULL,该过程往往需要全表扫描,因此最好为索引添加NOT NULL约束,并设置默认值,利于索引使用、加速查询效率 5关注:insert ignore into导致的性能问题或锁表 insert ignore into会对插入的每一行数据取共享锁(S锁,其他事务只可读)做唯一键的检测,同时会对主键自增ID加意向锁(insert intension); 在主键较为复杂的情况下,检测主键是否唯一时会一直占用主键的插入意向锁,其他进程也想给主键ID添加插入意向锁的时候,产生冲突导致死锁; 此外,代码中存在的insert replace into也需重点关注。 总结 SQL语句优化分析,是从事性能测试分析从业人员开展性能优化中的第一站,也是性能优化的基本技能,对系统性能提升具有重要作用和意义。在掌握性能优化基本技能的基础上,还需结合业务需求、代码逻辑访问路径,准确评估不同优化方法的适用性,综合对比不同优化方法工作成本,采用合理高效的优化方法开展性能优化工作。 文末了: 可以到我的个人号:atstudy-js,可以免费领取一份10G软件测试工程师面试宝典文档资料。同时我邀请你进入我们的软件测试学习交流平台,大家可以一起探讨交流软件测试,共同学习软件测试技术、面试等软件测试方方面面,了解测试行业的最新趋势,助你快速进阶Python自动化测试/测试开发,稳住当前职位同时走向高薪之路。