数仓建模理论之实体和维度建模
数据建模方式
将数据有序的组织和存储起来。
1、ER实体关系模型
ER实体关系模型:是当前几乎所有的 OLTP 系统设数据库设计理论基础,当在信息系统中将事物抽象为“实体”,”属性“,”关系“来表示数据关联和事物描述。
实体:实体是一个数据对象,指应用中可以区别的客观存在的事物。例如:商品、用户、学生、课程等
属性:实体的某一特性称为属性。例如:商品的重量、颜色、尺寸。用户的性别、身高、爱好等。
关系:表示一个或多个实体之间的关联关系。实体不是孤立的,实体之间是有联系的,这就是关系。例如:用户是实体,商品是实体,用户选购商品这个过程就会产生“选购商品数量”,“金额”这些属性,这就是关系。
2、数据仓库
数据仓库是面向主题的、集成的(非简单的数据堆积)、相对稳定的、反应历史变化的数据集合,数仓中的数据是有组织有结构的存储数据集合,用于对管理决策过程的支持。
**面向主题:**主题是指使用数据仓库进行决策时所关心的重点方面,每个主题都对应一个相应的分析领域,一个主题通常与多个信息系统相关。
**数据集成:**数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性
**相对稳定:**数据仓库中一般有大量的查询操作,基本没有修改和删除操作,通常只需要定期的加载、刷新。
反映历史变化:数据仓库中的数据通常包含历史信息,系统地记录企业从过去某一时点(如开始应用数据仓库的时点)到当前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
3、维度建模(重点)
维度建模主要源自数据集市,主要面向分析场景。将数据仓库中的表划分为事实表、维度表两种类型。
**事实表:**一般是指一个现实存在的业务对象,同时也是一个业务过程,类似于日志,记录每次变更,比如用户,商品,商家,销售员:
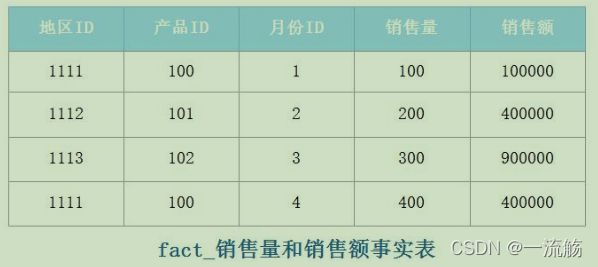
在以上事实表的示例中,“地区 ID”、“产品 ID”、“月份 ID”为键值列,“销售量”、“销售额”为度量列,所谓度量列就是列的数据可度量,度量列一般为可统计的数值列。事实表中每个列通常要么是键值列,要么是度量列。
在事实表中使用代号或者整数键值时,维度成员的名称需要放在另一种表中,也就是维
度表。通常事实表中的每个维度都对应一个维度表。
在数据仓库中,事实表的前缀为“fact”
事实表分类
周期型事实表,一般指随着业务发生不断产生的数据。与事务型不同的是,数据会随着业务周期性的推进而变化。
比如订单,其中订单状态会周期性变化。再比如,请假、贷款申请,随着批复状态在周期性变化。
同步策略
数据同步策略的类型包括:全量表、增量表、新增及变化表
全量表:存储完整的数据。
增量表:存储新增加的数据。
新增及变化表:存储新增加的数据和变化的数据。
实体表同步策略
实体表:比如用户,商品,商家,销售员等
实体表数据量比较小:通常可以做每日全量,就是每天存一份完整数据。即每日全量。
维度表同步策略
维度表:比如订单状态,审批状态,商品分类
维度表数据量比较小:通常可以做每日全量,就是每天存一份完整数据。即每日全量。
说明:
1)针对可能会有变化的状态数据可以存储每日全量。
2)没变化的客观世界的维度(比如性别,地区,民族,政治成分,鞋子尺码)可以只
存一份固定值。
事务型事实表同步策略(最常用)
事务型事实表:比如,交易流水,操作日志,出库入库记录等。
因为数据不会变化,而且数据量巨大,所以每天只同步新增数据即可,所以可以做成每日增量表,即每日创建一个分区存储。
事务事实表的设计流程
设计事务事实表时一般可遵循以下四个步骤。
选择业务过程→声明粒度→确认维度→确认事实
定建立哪张表 设计表结构 设计维度表 确认度量
1)选择业务过程
在业务系统中,业务过程可以概括为一个个不可拆分的行为事件,例如电商交易中的下单,取消订单,付款,退单等,都是业务过程。通常情况下,一个业务过程对应一张事务型事实表。
2)声明粒度
业务过程确定后,需要为每个业务过程声明粒度。即精确定义每张事务型事实表的每行数据表示什么,应该尽可能选择最细粒度,以此来应各种细节程度的需求。
典型的粒度声明如下:
订单事实表中一行数据表示的是一个订单中的一个商品项。
3)确定维度
确定维度具体是指,确定与每张事务型事实表相关的维度有哪些。
确定维度时应尽量多的选择与业务过程相关的环境信息。因为维度的丰富程度就决定了维度模型能够支持的指标丰富程度。
4)确定事实
此处的“事实”一词,指的是每个业务过程的度量值(通常是可累加的数字类型的值,例如:次数、个数、件数、金额等)。
经过上述四个步骤,事务型事实表就基本设计完成了。第一步选择业务过程可以确定有哪些事务型事实表,第二步可以确定每张事务型事实表的每行数据是什么,第三步可以确定每张事务型事实表的维度外键,第四步可以确定每张事务型事实表的度量值字段。
周期型事实表同步策略
周期型事实表:比如,订单、请假、贷款申请等
这类表从数据量的角度,存每日全量的话,数据量太大,冗余也太大。如果用每日增量的话无法反应数据变化。每日新增及变化量,包括了当日的新增和修改。
维度表
维度表,一般是指对应一些业务状态,编号的解释表。主键+维度属性,比如地区表,订单状态,支付方式,审批状态,商品分类等等。

“产品名称”是产品维度表中的一个属性,维度表中可以包含很多属性列。
维度表中的“产品 ID”与事实表中的“产品 ID”相匹配,称为“键属性”,在当前产品维度表中一个“产品 ID”只有一个“产品名称”,显示时使用“产品名称”来代替,所以“产品名称”也被认为是“键属性”的一部分。
每个维度表中的键值属性都与事实表中对应的维度相匹配
在数据仓库中,维度表的前缀为"dim"
在数据仓库中事实表就是我们需要关注的内容,维度表就是我们从哪些角度观察这些内容。例如,某地区商品的销量,是从地区这个角度观察商品销量的。事实表就是销量表,维度表就是地区表。
4、常用的模型
规范化是指使用一系列范式设计数据库的过程,其目的是减少数据冗余,增强数据的一致性。通常情况下,规范化之后,一张表的字段会拆分到多张表。
反规范化是指将多张表的数据冗余到一张表,其目的是减少join操作,提高查询性能。
在设计维度表时,如果对其进行规范化,得到的维度模型称为雪花模型,如果对其进行反规范化,得到的模型称为星型模型。
星型模型:当所有的维度表都由连接键连接到事实表时,结构图如星星一样,这种分析模型就是星型模型。
雪花模型:当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其结构图就像雪花连接在一起,这种分析模型就是雪花模型。
星座模型:多个事实表共用多张维度表,由多个星型模型组成。
星型模型与雪花模型对比:
星型模型和雪花模型主要区别就是对维度表的拆分,对于雪花模型,维度表的设计更加规范,一般符合三范式设计;而星型模型,一般采用降维的操作,维度表设计不符合三范式设计,反规范化,利用冗余牺牲空间来避免模型过于复杂,提高易用性和分析效率。
维度变化
维度属性通常不是静态的,而是会随时间变化的,数据仓库的一个重要特点就是反映历史的变化,所以如何保存维度的历史状态是维度设计的重要工作之一。保存维度数据的历史状态,通常有以下两种做法,分别是全量快照表和拉链表。
1)全量快照表
离线数据仓库的计算周期通常为每天一次,所以可以每天保存一份全量的维度数据。这种方式的优点和缺点都很明显。
优点是简单而有效,开发和维护成本低,且方便理解和使用。
缺点是浪费存储空间,尤其是当数据的变化比例比较低时。
2)拉链表
拉链表的意义就在于能够更加高效的保存维度信息的历史状态。
(1)什么是拉链表
高效的保存维度信息的历史状态,保存新增变化状态
适用于数据会变化,但频率不高
如何使用拉链表
通过生效日期开始日期 <=date && 生效结束日期 >=date
5、数据仓库的分层
基于大数据的数据仓库建设要求快速响应需求,同时需求灵活多变,对实时性有不同的要求,除了面向 DSS、BI 等应用外,还要响应用户画像、个性化推荐、机器学习、数据分析等各种复杂的应用场景,实际上在大数据开发中,涉及到数仓设计都会进行分层设计。
数据分层好处如下:
清晰的数据结构:每层数据都有各自的作用域和职责,在使用表的时候更方便定位
和理解。
减少重复开发:规范数据分层,开发一层公用的中间层数据,减少重复计算流转数
据。
统一数据出口:通过数据分层,提供统一的数据出口,保证对外输出数据口径一致。
简化问题:通过数据分层,将复杂的业务简单化,将复杂的业务拆解为多层数据,
每层数据负责解决特定的问题。
ODS(Operational Data Store)层 - 原始数据层:保存原始数据不做任何处理
数据明细层:DWD(Data Warehouse Detail):存放事实表,保证业务中最小粒度的操作记录保证数据质量,对ODS层数据加工,提供更干净的数据。
数据中间层:DWM(Data Warehouse Middle):存放维度表,对通用维度进行聚合,计算出相应的统计指标,方便复用。
数据服务层:DWS(Data Warehouse Service):减少重复计算问题,存放需求的公用计算结果,用于提供后续的业务查询,OLAP分析,数据分析等。
ADS层:存放各项统计结果,用于后面的使用。
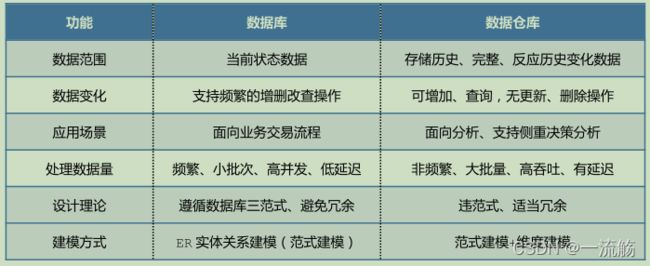
6、数据库和数据仓库的区别
数 据 库 : 传 统 关 系 型 数 据 库 的 主 要 应 用 是 OLTP
数据仓库:数仓系统的主要应用主要是 OLAP