MySQL为什么使用B+树
前言
本文是承接MySQL高新能索引这篇文章的部分内容,单独抽离出来分析MySQL为什么使用B+树,在上文中有提到索引有hash、二叉树、B树(B-树),B+树,而MySQL使用的是B+树,本文就对应这个进行分析!
Hash索引
Hash索引其实就是依赖于Hash表的关于Hash这块详细的可以查看往期文章HashMap底层数据结构(数组+链表+红黑树),这里还是讲解下Hash索引,如下

首先Hash表是一组连续的数组,对要存入的值进行hash取值然后%上Hash的长度,那么得到的余数就对应着Hash
表的下标位置,这是最简单的Hash存储方式,当我们存储的数据量过大的时候,那么就会产生哈希碰撞,那么不同的值就会的到相同的Hash,那么同样也会得到相同的下标,那么这就衍生出了链表和红黑树,关于这其中的细节,在上文中有详细的介绍!MySQL为什么不采用Hash的方式存储索引呢?如下!(并非不支持Hash索引,如Memory引擎就以Hash作为默认索引类型存储,同时支持B-树,值得一提的是Memory引擎是支持的非唯一哈希索引,除Memory引擎之外,NDB集群引擎也支持唯一Hash索引,关于这里不展开说了。)
缺点
- 利用Hash存储索引的话需要将所有数据文件添加到内存,比较消耗内存,(Memory引擎基于内存的)
- Hash索引只支持等值比较,在查询等值操作的时候Hash确实块,但是实际开发中还有许多的范围查询,那么这里就不太适用了
- 我们知道Hash是无序的,同样Hash索引也是无序的,Hash索引数据并不是按照索引值顺序存储的,所以也就无法排序
- Hash索引不支持部分索引列匹配查找,因为Hash始终是使用索引的全部内容来计算Hash值的
- MySQL不只是查询操作的,还用于新增、修改、删除的操作,如果Hash冲突很多的话,索引维护的代价也高,如果在哈希碰撞严重的值上建立Hash索引,那么从表中删除一行时,存储引擎需要遍历对Hash值的链表的每一行,找到并删除对应的索引,冲突越多代价越大
- Hash索引值包含Hash值和行的指针,而不是存储字段值,所以不能使用索引中的值避免读取行,虽然从内存中根据hash得到行地址很快,但是大部分情况下这一点对性能影响并不明显
二叉树和红黑树索引
注意本文并不是讲这些树的,而是着重讲解B+树这玩意,下面简单讲解下二叉树和红黑树

在上图中,这种结构的缺点比较明显,无论是二叉树和红黑树都会因为树的深度过深,而造成IO次数变多,IO次数多了就会影响读取数据的效率
B树
 实例图说明:
实例图说明:
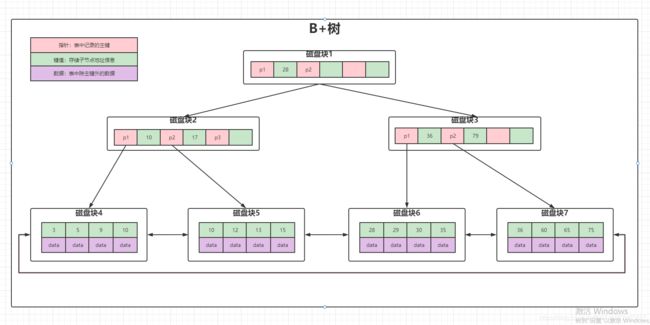
每个磁盘块,可以理解为存储固定大小的的值,每个节点占用一个磁盘块,一个节点上有两个升序排列的关键字,和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址,两个关键词划分成三个范围域对应三个指向子树的数据的范围,以根节点为例,关键字为16和34,p1指针指向子树的数据范围小于16,p2指针指向子树的数据范围为16-34,p3指针指向的子树的数据范围为大于34。
查询过程
- 根据根节点查找到磁盘块1,读入内存(磁盘IO操作1次)
- 比较关键字28在区间(14-34)找到磁盘块1的指针p2
- 根据p2指针找到磁盘块3,读入内存(磁盘IO操作2次)
- 比较关键字28在区间(27-29)找打磁盘块3的指针p2
- 根据p2指针找到磁盘块8,读入内存(磁盘IO操作3次)
- 在磁盘块8中的关键字列表中再到关键字28
B树的特点
- 所有的键值分布在整棵树中
- 搜索有可能在非叶子节点结束,在关键字全集内做一次查找性能逼近二分查找
- 每个节点最多拥有m个子树
- 根节点至少两个子数
- 分支节点至少拥有m/2棵树(除根节点和叶子节点外都是分支节点)
- 所有叶子节点都在同一层,每个节点最多可以有m-1个key并且以升序排列
缺点
- 每个节点都有key,同时也包含data,而每个页面存储空间是有限的,如果data比较大的话,会导致每个节点存储的key数量边小
- 当存储的数据量很大的时候会导致树的深度较大,增大车讯磁盘IO次数,进而影响查询性能
B+树
B+ 树是对 B 树的进一步优化。变化如下!
- B+数每个节点可以相比B树包含更多的节点,这个作用原因有两个,第一个原因为了降低树的高度,第二个原因是
将数据范围变为多个区间,区间越多,数据检索越快 - 非叶子节点存储key,叶子节点存储key和数据,
之所以这么做是因为在数据库中页的大小是固定的,InnoDB 中页的默认大小是 16KB。如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的 IO 次数又会再次减少,数据查询的效率也会更快。另外,B+ 树的阶数是等于键值的数量的,如果我们的 B+ 树一个节点可以存储 1000 个键值,那么 3 层 B+ 树可以存储 1000×1000×1000=10 亿个数据。一般根节点是常驻内存的,所以一般我们查找 10 亿数据,只需要 2 次磁盘 IO。 - 叶子节点两两指针相互连接(符合磁盘的预读特性),数据是按照顺序排列的。顺序查询性能更高
虽然InnoDB和MyISAM存储引擎都是使用B+树,但是具体实现是有不同的,具体如下
InnoDB–B+树
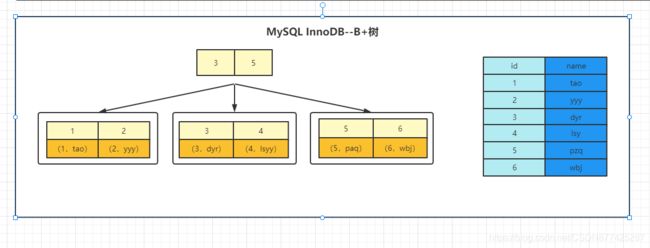
上面3/5是根节点,包括分支节点是不存储数据的,只有对应的叶子节点才存储数据,上面淡黄色的是存储的值,深黄色的存储的是值,我们在建索引的时候是给每个列建索引,在上图中可以看出,3,5将数据划分为三块,当我们要查询3对应的数据时,只需要找到3,然后向下找一次即可找到3对应的数据,并直接得到3对应的数据,直接读取数据完事,这种方式效率比较高,并且这样我们树的深度不会特别深
注意
- InnoDB是通过B+树结构对主键创建索引的,然后叶子节点中存储记录值,如果没有创建之间,那么就会选择唯一键,如果没有唯一键,那么就会生成一个6位的row_id当做主键,当然这个row_id对我们是不可见的
- 如果创建索引的键是其他字段,那么在叶子节点中存储的是该记录的主键,然后在通过主键索引找到对应的记录,也就是这个索引字段也会创建一颗B+数,只是这个B+树子节点的数据是主键索引的值,通过得到主键索引的值后再到主键的B+树(主键的B+树是MySQL自动生成的)中查找得到具体的数据行,如下
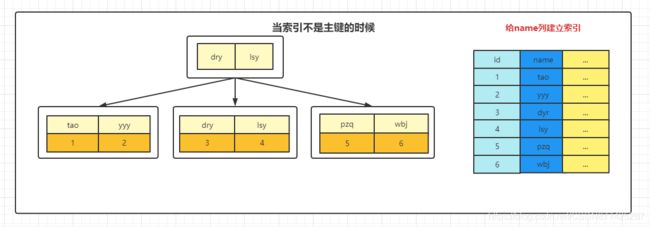
通过名字得到对应的主键索引,然后通过主键索引的B+树得到具体每行的值
MyISAM–B+树

MyISAM 中的 B+ 树索引实现与 InnoDB 中的略有不同。在 MyISAM 中,B+ 树索引的叶子节点并不存储数据,而是存储数据的文件地址。
关联
这里我们回顾一篇往期文章MySQL数据文件,这篇文章中有提到InnoDB和MyISAM存储引擎数据文件的区别,对这上面两种引擎B+数上的实现是相关联的
关于索引的专业术语
回表
关于回表这个专业术语,通过上面介绍InnoDB和MyISAM存储引擎中具体实现的B+树我们知道InnoDB的主键索引的B+树的子节点中是直接存储行的记录值,那么这个就不需要回表操作,但是一张表中不单只有主键索引,还有普通索引,如在上面讲到InnoDB中给name建普通索引,那么通过name维护的B+树索引得到name值对应的主键,然后再通过主键索引维护的B+树在查找到具体的行数据,那么这个过程就叫回表
索引覆盖
这个专业术语也需要结合索引的特性,这里写两条SQL,如下!
select * from t1 where name =‘tao’
select id from t1 where name =‘tao’
二者区别就是第一条查询所有字段,第二条只查询id,这二条语句的区别就再于是否会触发回表操作,第一条就会触发回表操作,是因为我们根据name这个字段的B+树只能得到对应name的id值,需要知道其他的字段还需要通过主键id维护的B+树回表进行查找,否则无法查找其他字段,而第二条SQL就只要id,那么无需查找其他字段,所以不会触发回表操作,那么个这个第二条不会触发回表操作的过程就叫做所以覆盖
最左匹配
这个是面试中的高频问点,索引的最左匹配原则!这个最左匹配原则是发生在建立多字段的组合索引是参数的,如我们有表t1字段有id,name,age,sex 当我们查询条件通常为name和age时,我们给以给name和age建立组合索引(name,age),这里最左匹配原则我们可以理解为(在我们查询地址的时候,必须先根据省查找,然后查询市,在查询区的顺序),我们写几条SQL来理解一下,如下
当前组合索引(name,age)
select * from t1 where name =‘tao’
select * from t1 where name =‘tao’ and age=10
select * from t1 where age=10
select * from t1 where age=10 and name =‘tao’
以上能用到索引的有第一条,第二条,第四条。第一条name能匹配到最左边的索引name所以是可以的,第二条,既能匹配到name也能匹配到age,第三条则是直接跨过了name那么违背了最左匹配原则的,所以不行,第四条,这个有人会质疑了,这里先查询的是age后查询的是name,顺序对不上呀,这里我们需要知道MySQL的逻辑架构,MySQL逻辑架构,MySQL逻辑架构中有一个优化器,这个优化器会帮我们优化SQL,所以这里优化后是name在前,age在后。这个我们可以创建索引使用explain看看。这里不单是在WHERE条件时会优化,在表关联的时候也会优化,如下

使用STRAIGHT_JOIN关键字强制关联顺序

这里为什么会有STRAIGHT_JOIN关键字,原因是在大部分情况下MySQL的优化器是能帮我们优化SQL的,但是少部分情况下还是需要根据我们自己的SQL执行,当我们需要SQL按照我们自己的意思执行的时候就可以使用STRAIGHT_JOIN了
索引下推(5.6之后才有的)
如我们有两个条件name、age,但是只有name做了索引,在正常查询的流程如下
- 根据name列从存储引擎中把符合name条件的数据从存储引擎中拉取到mysql的server层
- 在server层中按照age进行数据过滤
那么采用索引下推后流程就是直接从存储引擎拉取数据的时候按照name和age做判断,将符合的结构返回给mysql的server
结尾
至于MySQL是否真的如我所说的使用B+树,我么可以看看官网!MySQL官网
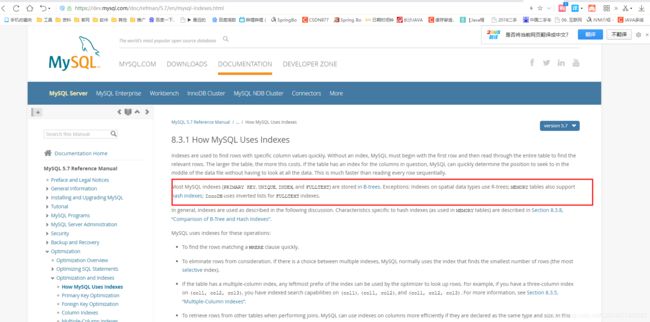
这里B-树其实就是B树,而上面文章说到MySQL使用的则是B树的升级版也就是B+树了,还是信我说的话可以看看高新能MySQL这本书
