Flink源码系列(创建JobMaster并生成ExecutionGraph)-第七期
上一期指路:
上一期
上一期主要讲了flink内部的rm的创建,Dispatcher的创建与启动,之前也说过在Dispatcher的启动过程中会涉及JobMaster的创建与启动,那么这一期的主题是创建JobMaster并生成ExecutionGraph。
承接上一期分析到Dispatcher的onStart函数

1.Dispatcher#startRecoveredJobs->Dispatcher#runRecoveredJob->Dispatcher#runJob
private void runJob(JobGraph jobGraph, ExecutionType executionType) {
Preconditions.checkState(!runningJobs.containsKey(jobGraph.getJobID()));
long initializationTimestamp = System.currentTimeMillis();
CompletableFuture jobManagerRunnerFuture = createJobManagerRunner(jobGraph, initializationTimestamp);
DispatcherJob dispatcherJob = DispatcherJob.createFor(
jobManagerRunnerFuture,
jobGraph.getJobID(),
jobGraph.getName(),
initializationTimestamp);
runningJobs.put(jobGraph.getJobID(), dispatcherJob);
final JobID jobId = jobGraph.getJobID();
final CompletableFuture cleanupJobStateFuture = dispatcherJob.getResultFuture().handleAsync(
(dispatcherJobResult, throwable) -> {
Preconditions.checkState(runningJobs.get(jobId) == dispatcherJob, "The job entry in runningJobs must be bound to the lifetime of the DispatcherJob.");
if (dispatcherJobResult != null) {
return handleDispatcherJobResult(jobId, dispatcherJobResult, executionType);
} else {
return dispatcherJobFailed(jobId, throwable);
}
}, getMainThreadExecutor());
final CompletableFuture jobTerminationFuture = cleanupJobStateFuture
.thenApply(cleanupJobState -> removeJob(jobId, cleanupJobState))
.thenCompose(Function.identity());
FutureUtils.assertNoException(jobTerminationFuture);
registerDispatcherJobTerminationFuture(jobId, jobTerminationFuture);
} 
2.Dispatcher#createJobManagerRunner
CompletableFuture createJobManagerRunner(JobGraph jobGraph, long initializationTimestamp) {
final RpcService rpcService = getRpcService();
return CompletableFuture.supplyAsync(
() -> {
try {
JobManagerRunner runner = jobManagerRunnerFactory.createJobManagerRunner(
jobGraph,
configuration,
rpcService,
highAvailabilityServices,
heartbeatServices,
jobManagerSharedServices,
new DefaultJobManagerJobMetricGroupFactory(jobManagerMetricGroup),
fatalErrorHandler,
initializationTimestamp);
runner.start();
return runner;
} catch (Exception e) {
throw new CompletionException(new JobInitializationException(jobGraph.getJobID(), "Could not instantiate JobManager.", e));
}
},
ioExecutor); // do not use main thread executor. Otherwise, Dispatcher is blocked on JobManager creation
} 
3.DefaultJobManagerRunnerFactory#createJobManagerRunner
public JobManagerRunner createJobManagerRunner(
JobGraph jobGraph,
Configuration configuration,
RpcService rpcService,
HighAvailabilityServices highAvailabilityServices,
HeartbeatServices heartbeatServices,
JobManagerSharedServices jobManagerServices,
JobManagerJobMetricGroupFactory jobManagerJobMetricGroupFactory,
FatalErrorHandler fatalErrorHandler,
long initializationTimestamp) throws Exception {
final JobMasterConfiguration jobMasterConfiguration = JobMasterConfiguration.fromConfiguration(configuration);
final SlotPoolFactory slotPoolFactory = SlotPoolFactory.fromConfiguration(configuration);
final SchedulerNGFactory schedulerNGFactory = SchedulerNGFactoryFactory.createSchedulerNGFactory(configuration);
final ShuffleMaster shuffleMaster = ShuffleServiceLoader.loadShuffleServiceFactory(configuration).createShuffleMaster(configuration);
final JobMasterServiceFactory jobMasterFactory = new DefaultJobMasterServiceFactory(
jobMasterConfiguration,
slotPoolFactory,
rpcService,
highAvailabilityServices,
jobManagerServices,
heartbeatServices,
jobManagerJobMetricGroupFactory,
fatalErrorHandler,
schedulerNGFactory,
shuffleMaster);
return new JobManagerRunnerImpl(
jobGraph,
jobMasterFactory,
highAvailabilityServices,
jobManagerServices.getLibraryCacheManager().registerClassLoaderLease(jobGraph.getJobID()),
jobManagerServices.getScheduledExecutorService(),
fatalErrorHandler,
initializationTimestamp);
}
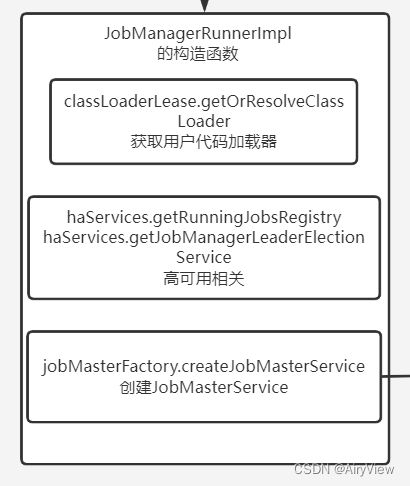
4.JobManagerRunnerImpl的构造函数
public JobManagerRunnerImpl(
final JobGraph jobGraph,
final JobMasterServiceFactory jobMasterFactory,
final HighAvailabilityServices haServices,
final LibraryCacheManager.ClassLoaderLease classLoaderLease,
final Executor executor,
final FatalErrorHandler fatalErrorHandler,
long initializationTimestamp) throws Exception {
this.resultFuture = new CompletableFuture<>();
this.terminationFuture = new CompletableFuture<>();
this.leadershipOperation = CompletableFuture.completedFuture(null);
this.jobGraph = checkNotNull(jobGraph);
this.classLoaderLease = checkNotNull(classLoaderLease);
this.executor = checkNotNull(executor);
this.fatalErrorHandler = checkNotNull(fatalErrorHandler);
checkArgument(jobGraph.getNumberOfVertices() > 0, "The given job is empty");
// libraries and class loader first
final ClassLoader userCodeLoader;
try {
userCodeLoader = classLoaderLease.getOrResolveClassLoader(
jobGraph.getUserJarBlobKeys(),
jobGraph.getClasspaths()).asClassLoader();
} catch (IOException e) {
throw new Exception("Cannot set up the user code libraries: " + e.getMessage(), e);
}
// high availability services next
this.runningJobsRegistry = haServices.getRunningJobsRegistry();
this.leaderElectionService = haServices.getJobManagerLeaderElectionService(jobGraph.getJobID());
this.leaderGatewayFuture = new CompletableFuture<>();
// now start the JobManager
this.jobMasterService = jobMasterFactory.createJobMasterService(jobGraph, this, userCodeLoader, initializationTimestamp);
} 
5.一系列的套娃跳转
DefaultJobMasterServiceFactory#createJobMasterService->JobMaster的构造函数->JobMaster#createScheduler->DefaultSchedulerFactory#createInstance->DefaultScheduler的构造函数->点击super到SchedulerBase的构造函数->SchedulerBase#createAndRestoreExecutionGraph->SchedulerBase#createExecutionGraph->ExecutionGraphBuilder#buildGraph
public static ExecutionGraph buildGraph(
@Nullable ExecutionGraph prior,
JobGraph jobGraph,
Configuration jobManagerConfig,
ScheduledExecutorService futureExecutor,
Executor ioExecutor,
SlotProvider slotProvider,
ClassLoader classLoader,
CheckpointRecoveryFactory recoveryFactory,
Time rpcTimeout,
RestartStrategy restartStrategy,
MetricGroup metrics,
BlobWriter blobWriter,
Time allocationTimeout,
Logger log,
ShuffleMaster shuffleMaster,
JobMasterPartitionTracker partitionTracker,
FailoverStrategy.Factory failoverStrategyFactory,
ExecutionDeploymentListener executionDeploymentListener,
ExecutionStateUpdateListener executionStateUpdateListener,
long initializationTimestamp) throws JobExecutionException, JobException {
checkNotNull(jobGraph, "job graph cannot be null");
final String jobName = jobGraph.getName();
final JobID jobId = jobGraph.getJobID();
final JobInformation jobInformation = new JobInformation(
jobId,
jobName,
jobGraph.getSerializedExecutionConfig(),
jobGraph.getJobConfiguration(),
jobGraph.getUserJarBlobKeys(),
jobGraph.getClasspaths());
final int maxPriorAttemptsHistoryLength =
jobManagerConfig.getInteger(JobManagerOptions.MAX_ATTEMPTS_HISTORY_SIZE);
final PartitionReleaseStrategy.Factory partitionReleaseStrategyFactory =
PartitionReleaseStrategyFactoryLoader.loadPartitionReleaseStrategyFactory(jobManagerConfig);
// create a new execution graph, if none exists so far
final ExecutionGraph executionGraph;
try {
executionGraph = (prior != null) ? prior :
new ExecutionGraph(
jobInformation,
futureExecutor,
ioExecutor,
rpcTimeout,
restartStrategy,
maxPriorAttemptsHistoryLength,
failoverStrategyFactory,
slotProvider,
classLoader,
blobWriter,
allocationTimeout,
partitionReleaseStrategyFactory,
shuffleMaster,
partitionTracker,
jobGraph.getScheduleMode(),
executionDeploymentListener,
executionStateUpdateListener,
initializationTimestamp);
} catch (IOException e) {
throw new JobException("Could not create the ExecutionGraph.", e);
}
// set the basic properties
try {
executionGraph.setJsonPlan(JsonPlanGenerator.generatePlan(jobGraph));
}
catch (Throwable t) {
log.warn("Cannot create JSON plan for job", t);
// give the graph an empty plan
executionGraph.setJsonPlan("{}");
}
// initialize the vertices that have a master initialization hook
// file output formats create directories here, input formats create splits
final long initMasterStart = System.nanoTime();
log.info("Running initialization on master for job {} ({}).", jobName, jobId);
for (JobVertex vertex : jobGraph.getVertices()) {
String executableClass = vertex.getInvokableClassName();
if (executableClass == null || executableClass.isEmpty()) {
throw new JobSubmissionException(jobId,
"The vertex " + vertex.getID() + " (" + vertex.getName() + ") has no invokable class.");
}
try {
vertex.initializeOnMaster(classLoader);
}
catch (Throwable t) {
throw new JobExecutionException(jobId,
"Cannot initialize task '" + vertex.getName() + "': " + t.getMessage(), t);
}
}
log.info("Successfully ran initialization on master in {} ms.",
(System.nanoTime() - initMasterStart) / 1_000_000);
// topologically sort the job vertices and attach the graph to the existing one
List sortedTopology = jobGraph.getVerticesSortedTopologicallyFromSources();
if (log.isDebugEnabled()) {
log.debug("Adding {} vertices from job graph {} ({}).", sortedTopology.size(), jobName, jobId);
}
executionGraph.attachJobGraph(sortedTopology);
if (log.isDebugEnabled()) {
log.debug("Successfully created execution graph from job graph {} ({}).", jobName, jobId);
}
// configure the state checkpointing
JobCheckpointingSettings snapshotSettings = jobGraph.getCheckpointingSettings();
if (snapshotSettings != null) {
List triggerVertices =
idToVertex(snapshotSettings.getVerticesToTrigger(), executionGraph);
List ackVertices =
idToVertex(snapshotSettings.getVerticesToAcknowledge(), executionGraph);
List confirmVertices =
idToVertex(snapshotSettings.getVerticesToConfirm(), executionGraph);
CompletedCheckpointStore completedCheckpoints;
CheckpointIDCounter checkpointIdCounter;
try {
int maxNumberOfCheckpointsToRetain = jobManagerConfig.getInteger(
CheckpointingOptions.MAX_RETAINED_CHECKPOINTS);
if (maxNumberOfCheckpointsToRetain <= 0) {
// warning and use 1 as the default value if the setting in
// state.checkpoints.max-retained-checkpoints is not greater than 0.
log.warn("The setting for '{} : {}' is invalid. Using default value of {}",
CheckpointingOptions.MAX_RETAINED_CHECKPOINTS.key(),
maxNumberOfCheckpointsToRetain,
CheckpointingOptions.MAX_RETAINED_CHECKPOINTS.defaultValue());
maxNumberOfCheckpointsToRetain = CheckpointingOptions.MAX_RETAINED_CHECKPOINTS.defaultValue();
}
completedCheckpoints = recoveryFactory.createCheckpointStore(jobId, maxNumberOfCheckpointsToRetain, classLoader);
checkpointIdCounter = recoveryFactory.createCheckpointIDCounter(jobId);
}
catch (Exception e) {
throw new JobExecutionException(jobId, "Failed to initialize high-availability checkpoint handler", e);
}
// Maximum number of remembered checkpoints
int historySize = jobManagerConfig.getInteger(WebOptions.CHECKPOINTS_HISTORY_SIZE);
CheckpointStatsTracker checkpointStatsTracker = new CheckpointStatsTracker(
historySize,
ackVertices,
snapshotSettings.getCheckpointCoordinatorConfiguration(),
metrics);
// load the state backend from the application settings
final StateBackend applicationConfiguredBackend;
final SerializedValue serializedAppConfigured = snapshotSettings.getDefaultStateBackend();
if (serializedAppConfigured == null) {
applicationConfiguredBackend = null;
}
else {
try {
applicationConfiguredBackend = serializedAppConfigured.deserializeValue(classLoader);
} catch (IOException | ClassNotFoundException e) {
throw new JobExecutionException(jobId,
"Could not deserialize application-defined state backend.", e);
}
}
final StateBackend rootBackend;
try {
rootBackend = StateBackendLoader.fromApplicationOrConfigOrDefault(
applicationConfiguredBackend, jobManagerConfig, classLoader, log);
}
catch (IllegalConfigurationException | IOException | DynamicCodeLoadingException e) {
throw new JobExecutionException(jobId, "Could not instantiate configured state backend", e);
}
// instantiate the user-defined checkpoint hooks
final SerializedValue serializedHooks = snapshotSettings.getMasterHooks();
final List> hooks;
if (serializedHooks == null) {
hooks = Collections.emptyList();
}
else {
final MasterTriggerRestoreHook.Factory[] hookFactories;
try {
hookFactories = serializedHooks.deserializeValue(classLoader);
}
catch (IOException | ClassNotFoundException e) {
throw new JobExecutionException(jobId, "Could not instantiate user-defined checkpoint hooks", e);
}
final Thread thread = Thread.currentThread();
final ClassLoader originalClassLoader = thread.getContextClassLoader();
thread.setContextClassLoader(classLoader);
try {
hooks = new ArrayList<>(hookFactories.length);
for (MasterTriggerRestoreHook.Factory factory : hookFactories) {
hooks.add(MasterHooks.wrapHook(factory.create(), classLoader));
}
}
finally {
thread.setContextClassLoader(originalClassLoader);
}
}
final CheckpointCoordinatorConfiguration chkConfig = snapshotSettings.getCheckpointCoordinatorConfiguration();
executionGraph.enableCheckpointing(
chkConfig,
triggerVertices,
ackVertices,
confirmVertices,
hooks,
checkpointIdCounter,
completedCheckpoints,
rootBackend,
checkpointStatsTracker);
}
// create all the metrics for the Execution Graph
metrics.gauge(RestartTimeGauge.METRIC_NAME, new RestartTimeGauge(executionGraph));
metrics.gauge(DownTimeGauge.METRIC_NAME, new DownTimeGauge(executionGraph));
metrics.gauge(UpTimeGauge.METRIC_NAME, new UpTimeGauge(executionGraph));
executionGraph.getFailoverStrategy().registerMetrics(metrics);
return executionGraph;
} 
6.ExecutionGraph#attachJobGraph
public void attachJobGraph(List topologiallySorted) throws JobException {
assertRunningInJobMasterMainThread();
LOG.debug("Attaching {} topologically sorted vertices to existing job graph with {} " +
"vertices and {} intermediate results.",
topologiallySorted.size(),
tasks.size(),
intermediateResults.size());
final ArrayList newExecJobVertices = new ArrayList<>(topologiallySorted.size());
final long createTimestamp = System.currentTimeMillis();
for (JobVertex jobVertex : topologiallySorted) {
if (jobVertex.isInputVertex() && !jobVertex.isStoppable()) {
this.isStoppable = false;
}
// create the execution job vertex and attach it to the graph
ExecutionJobVertex ejv = new ExecutionJobVertex(
this,
jobVertex,
1,
maxPriorAttemptsHistoryLength,
rpcTimeout,
globalModVersion,
createTimestamp);
ejv.connectToPredecessors(this.intermediateResults);
ExecutionJobVertex previousTask = this.tasks.putIfAbsent(jobVertex.getID(), ejv);
if (previousTask != null) {
throw new JobException(String.format("Encountered two job vertices with ID %s : previous=[%s] / new=[%s]",
jobVertex.getID(), ejv, previousTask));
}
for (IntermediateResult res : ejv.getProducedDataSets()) {
IntermediateResult previousDataSet = this.intermediateResults.putIfAbsent(res.getId(), res);
if (previousDataSet != null) {
throw new JobException(String.format("Encountered two intermediate data set with ID %s : previous=[%s] / new=[%s]",
res.getId(), res, previousDataSet));
}
}
this.verticesInCreationOrder.add(ejv);
this.numVerticesTotal += ejv.getParallelism();
newExecJobVertices.add(ejv);
}
// the topology assigning should happen before notifying new vertices to failoverStrategy
executionTopology = DefaultExecutionTopology.fromExecutionGraph(this);
failoverStrategy.notifyNewVertices(newExecJobVertices);
partitionReleaseStrategy = partitionReleaseStrategyFactory.createInstance(getSchedulingTopology());
} 
7.ExecutionJobVertex#connectToPredecessors
public void connectToPredecessors(Map intermediateDataSets) throws JobException {
List inputs = jobVertex.getInputs();
if (LOG.isDebugEnabled()) {
LOG.debug(String.format("Connecting ExecutionJobVertex %s (%s) to %d predecessors.", jobVertex.getID(), jobVertex.getName(), inputs.size()));
}
for (int num = 0; num < inputs.size(); num++) {
JobEdge edge = inputs.get(num);
if (LOG.isDebugEnabled()) {
if (edge.getSource() == null) {
LOG.debug(String.format("Connecting input %d of vertex %s (%s) to intermediate result referenced via ID %s.",
num, jobVertex.getID(), jobVertex.getName(), edge.getSourceId()));
} else {
LOG.debug(String.format("Connecting input %d of vertex %s (%s) to intermediate result referenced via predecessor %s (%s).",
num, jobVertex.getID(), jobVertex.getName(), edge.getSource().getProducer().getID(), edge.getSource().getProducer().getName()));
}
}
// fetch the intermediate result via ID. if it does not exist, then it either has not been created, or the order
// in which this method is called for the job vertices is not a topological order
IntermediateResult ires = intermediateDataSets.get(edge.getSourceId());
if (ires == null) {
throw new JobException("Cannot connect this job graph to the previous graph. No previous intermediate result found for ID "
+ edge.getSourceId());
}
this.inputs.add(ires);
int consumerIndex = ires.registerConsumer();
for (int i = 0; i < parallelism; i++) {
ExecutionVertex ev = taskVertices[i];
ev.connectSource(num, ires, edge, consumerIndex);
}
}
} 
8.ExecutionVertex#connectSource
public void connectSource(int inputNumber, IntermediateResult source, JobEdge edge, int consumerNumber) {
final DistributionPattern pattern = edge.getDistributionPattern();
final IntermediateResultPartition[] sourcePartitions = source.getPartitions();
ExecutionEdge[] edges;
switch (pattern) {
case POINTWISE:
edges = connectPointwise(sourcePartitions, inputNumber);
break;
case ALL_TO_ALL:
edges = connectAllToAll(sourcePartitions, inputNumber);
break;
default:
throw new RuntimeException("Unrecognized distribution pattern.");
}①connectPointwise
如果是POINTWISE模式,执行
ps:
这种情况就是每个生产子任务都连接到消费任务的一个或多个子任务
本质上还是以IntermediateResultPartition作为输入和ExecutionVertex作为输出构建ExecutionEdge。只不过处理情况要比下面的每个生产子任务连接到消费任务的每个子任务要复杂一点
②connectAllToAll
如果是ALL_TO_ALL模式,执行
ps:
new ExecutionEdge
根据IntermediateResultPartition作为输入和ExecutionVertex作为输出构建ExecutionEdge
③ee.getSource().addConsumer
将ExecutionEdge作为 IntermediateResultPartition 的consumer
总览
这一期涉及到的源码流程图如下:

这一期和上一期主要讲Flink内部的组件rm、jm、Dispatcher,但其实rm和jm的启动还没有分析,只是在上一期分析了rm的创建以及这一期分析的jm的创建,所以下一期是一个善后的内容,主要用于补充rm和jm的真正启动。