JavaEE初阶---HTTP
一 : 概念
1.1引入
HTTP (全称为 "超文本传输协议") 是一种应用非常广泛的 应用层协议,是网页和服务器交互的桥梁.
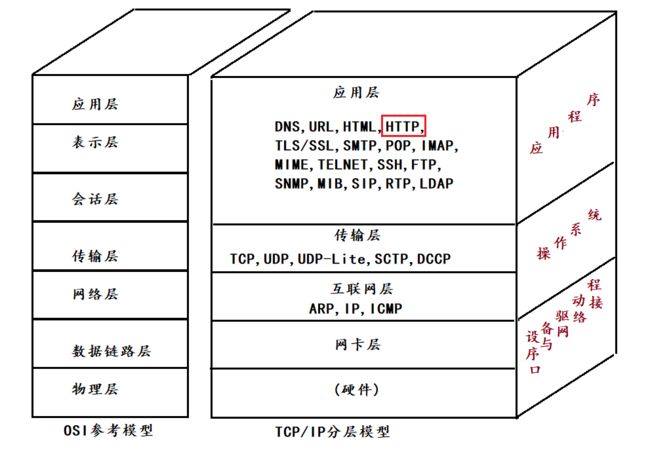
应用层是程序猿自己定义的 , 为了简化程序猿自己定义协议的成本 , 大佬们就研发出了一些比较好的协议 , 可以让程序员直接使用的 , HTTP就是其中之一 .
1.2 HTTP的应用
- 当使用浏览器打开一个网页时 , 浏览器和服务器之间的通信基本上就是基于HTTP的 .
- 当使用手机app打开一个界面时 , app和服务器之间的通信 , 多数是基于HTTP的 .
- 分布式系统中 , 服务器和服务器之间的通信 , 也有一定概率使用HTTP .
1.3 版本
HTTP 往往是基于传输层的 TCP 协议实现的. (HTTP1.0, HTTP1.1, HTTP2.0 均为TCP, HTTP3 基于 UDP实现) 目前我们主要使用的还是 HTTP1.1 和 HTTP2.0 .
1.4 通信模式
HTTP是一问一答的通信模式 .
客户端和服务器之间的通信模式,
1.一问一答.请求和响应是一一对应的.
2.多问一答. N个请求,对应一个响应.(上传文件)
3.一问多答.一个请求,对应N个响应.(下载文件)
4.多问多答. N个请求,对应N个响应.直播/游戏串流/广播 .

1.5 理解应用层协议

二 : HTTP的协议格式
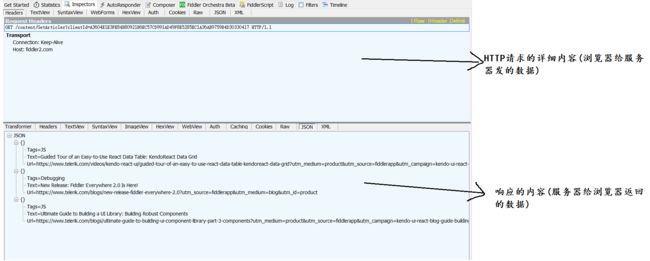
HTTP 是一个文本格式的协议. 可以通过 Chrome 开发者工具或者 Fiddler 抓包, 分析 HTTP 请求/响应的细节.其中,Fiddler是功能更加丰富的抓包工具 .
2.1 Fiddler界面一览

2.2 细节介绍

左侧是一个HTTP的请求列表 , 表示抓到了哪些请求 .
双击左侧列表的某个请求 , 会在右侧显示详细内容 .
fiddler相当于是一个代理,在中间传话的.
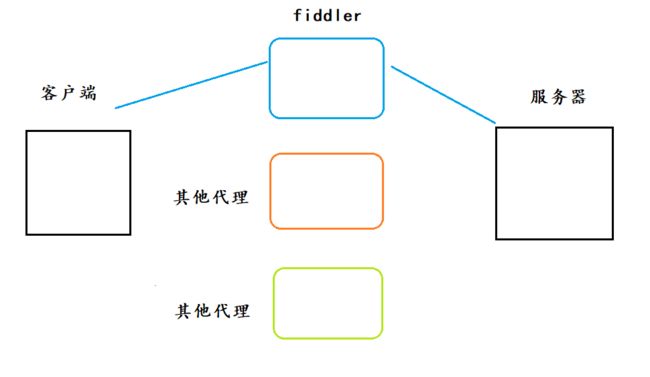
如果电脑上本身就运行了一些其他的代理程序 , 就有可能导致fiddler抓包失败 .

HTTP请求数据 :

HTTP是一个"文本协议" , 协议中的数据是以文本方式组织的 .
HTTP 响应数据 :

响应数据直接乱码 ?
对网络上传输的数据可能会进行压缩. 对于HTTP来说,请求数据一般比较简短,就不必压缩.响应数据可能会比较长!!通过压缩,就可以节省传输的带宽!!

点击这个按钮 , 可以进行解码 !
解码后效果 :

三 : HTTP 请求
3.1 认识 URL
Internet上的每一个网页都具有一个唯一的名称标识,通常称之为URL(Uniform Resource Locator, 统一资源定位器)。它是www的统一资源定位标志,简单地说URL就是web地址,俗称“网址”。
以打开搜狗浏览器为例 .
3.1.1HTTP请求

1.首行

2.请求报头header
3.空行
是请求报头(header)的结束标记 , 报头里有多少个键值对是不确定的 , 遇到空行就认为结束了 .
4.正文
不是每个HTTP协议都有 .

3.1.2HTTP响应

1.首行

2.响应报头

3.空行
![]()
4.正文

这里可能是CSS或JS或图片…
协议格式总结 :

3.2详细情况
3.2.1URL
注意 : 片段标识符起到页面内部跳转的效果 , 可以定位到网页的某个章节 ! 也叫作"锚点" .
URL 的详细规则由 因特网标准RFC1738 进行了约定

URL的可省略部分
- 协议名: 可以省略, 省略后默认为 http://
- ip 地址 / 域名: 在 HTML 中可以省略(比如 img, link, script, a 标签的 src 或者 href 属性). 省略后表示服务器的 ip / 域名与当前 HTML 所属的 ip / 域名一致.
- 端口号: 可以省略. 省略后如果是 http 协议, 端口号自动设为 80; 如果是 https 协议, 端口号自动设为 443.
- 带层次的文件路径: 可以省略. 省略后相当于 / . 有些服务器会在发现 / 路径的时候自动访问/index.html
- 查询字符串: 可以省略
- 片段标识: 可以省略
关于 URL encode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
例如 :

“+” 被转义成了 “%2B”
3.2.2 HTTP协议中的方法

1.GET方法
GET 是最常用的 HTTP 方法. 常用于获取服务器上的某个资源.在浏览器中直接输入 URL, 此时浏览器就会发送出一个 GET 请求.另外, HTML 中的 link, img, script 等标签, 也会触发 GET 请求.
完全可以使用GET让服务器新增一个数据/删除一个数据/修改一个数据…
哪些场景会触发一个GET请求 ?
- 浏览器地址栏输入一个URL , 直接回车 ;
- 很多的HTML标签 , 如a,link,script等也会产生GET请求 ;
- form ;
- ajax .
GET的主要特点有哪些 ?
- URL的query string有时候有 , 有时候没有 .
- body通常是空的 .
注意 : GET请求的URL长度是没有限制的 .(HTTP RFC2016标准中明确规定的)
4.POST方法
POST方法也是一种常见的方法. 多用于提交用户输入的数据给服务器(例如登陆页面).
完全可以使POST让服务器新增一个数据/删除一个数据/修改一个数据…
哪些场景会触发一个POST请求?
- 登录 ;
- 上传文件 .
POST的主要特点有哪些 ?
- 首行的一个部分是POST ;
- URL里通常没有query string ;
- 通常有body .
浏览器和服务器交互的时候,总是需要提交一些数据给服务器的 . 在提交的过程中,相关的信息,可以放到query string里,也可以放到body 中 .
-
query string是固定的键值对格式
-
body中则是可以使用更多的格式来组织
3.GET和POST之间的区别 ?
GET 和 POST之间没有本质区别 , 是可以相互替代的 .
1.GET主要使用用来获取数据. POST主要使用给服务器提交数据(习惯上遵守)
2.GET主要通过query string 来传递数据, POST则是使用body传递数据.(习惯用法)
3.GET请求一般建议实现成"幂等"的 , POST则不要求"幂等" .
4.GET一般是可以缓存的 , 是可以放入收藏夹的 ; POST一般是不要求缓存 , 不能放入收藏夹 .
如果多次输入的内容相同,多次得到的结果也完全相同,称为“幂等"
实际开发中,对于幂等很多时候是有要求的 . 实现"查看账户余额”,这个功能显然就是幂等的 ; 实现"转账”,这个功能显然就不是幂等的 .
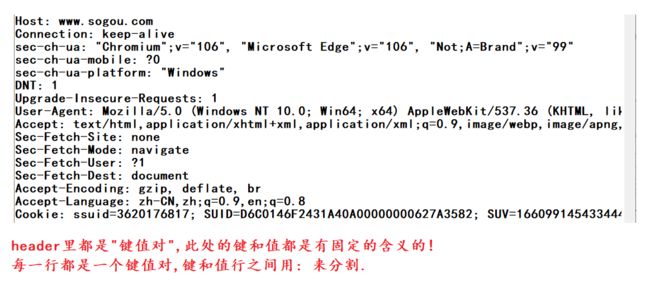
3.2.3 请求报头header
请求报头中有很多键值对,重点认识一些常见的.
1.Host
Host文件主要作用是定义IP地址和主机名的映射关系,是一个映射IP地址和主机名的规定.

访问的服务器的主机/地址是什么 .
2.Content-Length和Content-Type
这俩是搭配body使用的 !
- Content-Length : 表示body中的数据长度 .
- Content-Type : 表示请求的body中的数据格式 .
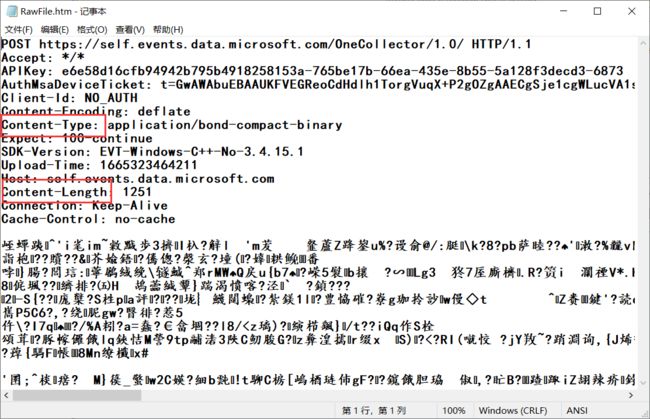
Content-Length
我们知道 , 基于TCP的应用层协议 , 务必需要明确数据报和数据报之间的边界 , 否则就会出现粘包问题 . HTTP也是基于TCP的 , 当HTTP报文带有body时 , 就需要显示地明确指出body到哪里结束 . 一种方法是使用空白行 , 另外一种方法就是使用指定长度(Content-Length) .
Content-Type
这是HTTP请求的body的数据格式 . 常见的有 :
- json ;
- urlencoded : 全称application/x-www-form-urlencoded ,格式和query string一样 , 键值对 , 键值对之间使用&分割 , 键和值之间使用 = 分割 ;
- form-data , 上传文件时会涉及到 .
3.User-Agent (简称UA)
描述了你在使用一个什么样的设备上网.

4.Referer
表明了这个页面是从哪个页面跳转过来的 .

5.Cookie
是浏览器在本地存储数据的一种机制.
Q : cookie是啥?
A : 浏览器允许页面在本地持久化存储数据的一种机制 .
Q : cookie 的内容从哪里来呢?
A : 是从服务器来的 . 网站上面主要的数据存储仍然是在服务器上的 . Cookie的内容是从服务器写回给浏览器的 .
Q : cookie的内容到哪里去呢?
A : 再传回给服务器 . 例如网站通过登录之后,明确了用户的身份信息,就把身份标识返回给了浏览器.浏览器下次访问服务器,就会带着身份标识 , 服务器就可以认出用户是谁了 .


具体的抓包过程 :




抓包过程的简化流程 :
滑稽老铁,首次来到这个医院,先办理一个就诊卡 . 办理就诊卡的时候,就要拿着身份证 . 医院的人来验证你的身份信息!!
医院这边就会在医院的系统中建立一个患者的档案 ,然后给滑稽一个就诊卡 .
就诊卡里保存了当前这个用户的身份标识(id),通过id 就可以在患者的档案中查询出具体的信息 ! (姓名,年龄,性别,以往病史…)
上述建档的过程,就是浏览器首次访问网站的时候.网站进行身份验证,生成对应的信息,并且返回一个身份标识给浏览器的cookie中~
接下来,滑稽老铁去外科看病,只要刷卡,医生就可以知道他的既往信息了 .
因此上述机制的关键,就在于滑稽老铁手中的那一张小小的就诊卡~~在这个卡里就保存着身份信息, 医院的任意科室(服务器的任意页面)都可以知道用户的既往信息(每次访问都会使用到) .
除了就诊卡之外,这些信息都是保存在医院的系统中的.医院的系统就针对滑稽老铁,建立了一份档案.这份档案,称为"会话" session .

3.2.4 HTTP响应报头
1.状态码
状态码表示访问一个页面的结果. (是访问成功, 还是失败, 还是其他的一些情况...)
这是我们访问某页面所得到的HTTP响应 .


例如: 查看码云的私有仓库, 如果不登陆, 就会出现 403. 参考链接


2.正文Content-Type
响应中的 Content-Type 常见取值有以下几种:
- text/html : body 数据格式是 HTML
- text/css : body 数据格式是 CSS
- application/javascript : body 数据格式是 JavaScript
- application/json : body 数据格式是 JSON
3.3 通过代码 , 构造HTTP请求
3.3.1通过 form 表单构造 HTTP 请求
form (表单) 是 HTML 中的一个常用标签. 可以用于给服务器发送 GET 或者 POST 请求.
使用form构造 , 主要是两种方式 :
- 基于form标签 ;
- 基于ajax .
1.form 发送 GET 请求
<form action="https://www.sogou.com/index.html" method="get">
<input type="text" name="username">
<input type="submit">
form>




总结 :
form 效果就是构造HTTP请求.
action描述了HTTP请求URL的地址/端口/路径.
method描述了HTTP请求的方法.
搭配一些input标签,就可以构造出一些键值对数据.
这些键值对根据方法是GET还是POST,来分别通过URL的 query string还是 body 来进行传输~~
2.ajax
是一个更强大,更灵活的构造HTTP的方式.


使用方法 :
方法一 : 直接引入网络路径

方法二 : 把jQuery文件内容拷贝到本地
Step1 : jQuery网址
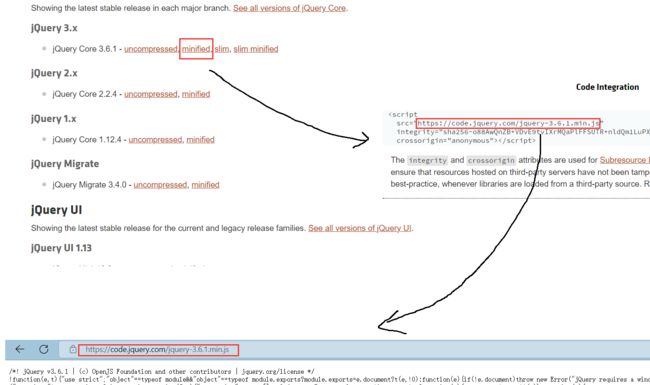
Step2 : 复制文本内容
Step3 : 拷贝到本地
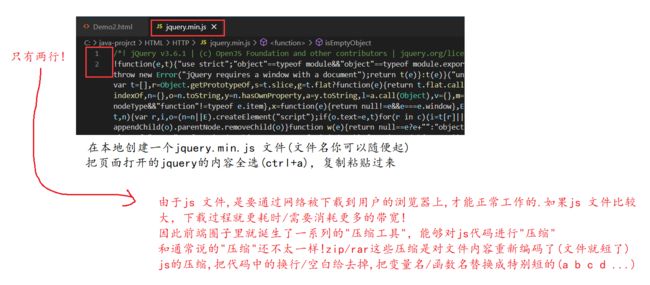
代码书写 :

此时直接运行程序 , 会报错 !

浏览器为了保证网络安全,禁止ajax的跨域访问.要想允许跨域访问,就需要百度的服务器支持. 后面可以搭建一个自己的服务器,就可以使用ajax访问自己的服务器了.
四 : HTTPS
4.1 诞生背景
HTTPS 也是一个应用层协议. 是在 HTTP 协议的基础上引入了一个加密层.
HTTP 协议内容都是按照文本的方式明文传输的. 这就导致在传输过程中出现一些被篡改的情况.
eg :臭名昭著的 “运营商劫持”
下载一个 天天动听
未被劫持的效果, 点击下载按钮, 就会弹出天天动听的下载链接.
演示被劫持的效果 : 点击下载按钮, 就会弹出 QQ 浏览器的下载链接 .
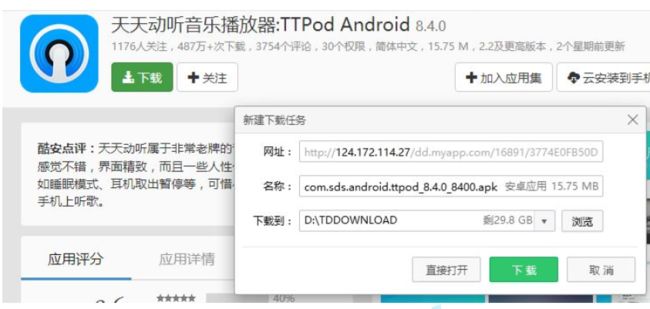


由于我们通过网络传输的任何的数据包都会经过运营商的网络设备(路由器, 交换机等), 那么运营商的网络设备就可以解析出你传输的数据内容, 并进行篡改.
如果黑客黑入侵了某个路由器 , 这个时候就可能获取到所有经过路由器的网络数据报 . 此时运营商路由器可能会受到攻击 , 公共场合的wifi也会是活靶子 .
如何保证数据不被窃取 ? 我们无法阻止黑客入侵路由器 , 但是可以想办法对数据进行加密 , 即使被窃取 , 黑客也不知道是啥意思 .
4.2 加密是什么?
加密 : 明文通过密钥变成密文 .
解密 : 密文通过密钥变成明文 .
如果加密和解密过程中 , 使用的密钥是同一个 , 称为"对称加密" ;
如果加密和解密过程中 , 使用的是不同的密钥 , 称为"非对称加密" .
4.3加密过程
加密中最典型的方法 , 是对称加密 .

但事情没这么简单.

服务器同一时刻其实是给很多客户端提供服务的. 这么多客户端, 每个人用的秘钥都必须是不同的(如果是相同那密钥就太容易扩散了, 黑客就也能拿到了). 因此服务器就需要维护每个客户端和每个密钥之间的关联关系 .
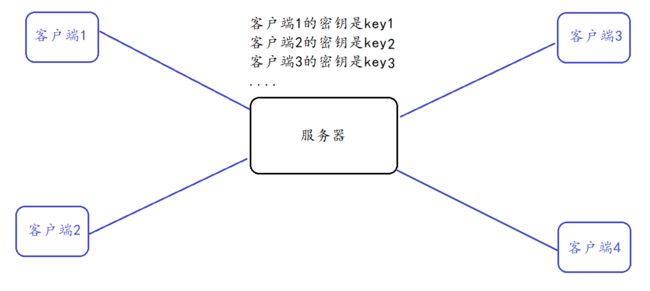
如果直接明文传输密钥 , 那这个密钥还是很可能被黑客截获到 !
此时就需要引入—非对称加密 !
非对称密钥,这里用来加密解密的密钥,是一对有关联的整数 , 通过数学上的一些方法来生成的(背后的道理就是 : 拿两个很大的素数,很容易得到乘积.但是知道乘积,没法还原回这两个素数) , 这是“数论”学科上讨论的话题 .
我们把这一对密钥 , 其中一个公布出来(公钥),另一个自己藏着(私钥) .就可以使用公钥来加密,私钥来解密 ; 或者用私钥来加密 , 公钥来解密 .
注意 :
公钥和私钥成对出现
公开的密钥叫公钥,只有自己知道的叫私钥
用公钥加密的数据只有对应的私钥可以解密
用私钥加密的数据只有对应的公钥可以解密
如果可以用公钥解密,则必然是对应的私钥加的密
如果可以用私钥解密,则必然是对应的公钥加的密
公钥和私钥是相对的,两者本身并没有规定哪一个必须是公钥或私钥。
简单示例 :


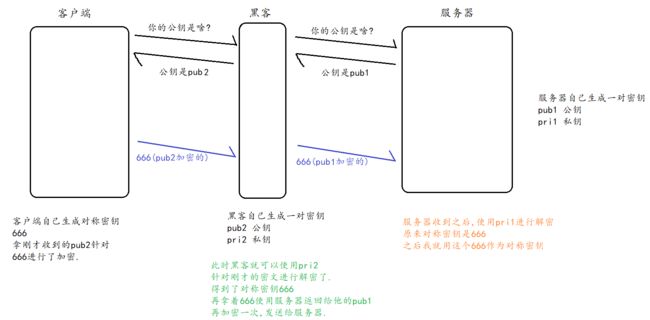
- 客户端在本地生成对称密钥, 通过公钥加密, 发送给服务器.
- 由于中间的网络设备没有私钥, 即使截获了数据, 也无法还原出内部的原文, 也就无法获取到对称密钥
- 服务器通过私钥解密, 还原出客户端发送的对称密钥. 并且使用这个对称密钥加密给客户端返回的响应数据.
- 后续客户端和服务器的通信都只用对称加密即可. 由于该密钥只有客户端和服务器两个主机知道,
- 其他主机/设备不知道密钥即使截获数据也没有意义.
注意 : 非对称加密的加密和解密开销很大 , 不如对称加密轻量 , 但是比对称加密要更安全 .
上述过程是使用非对称加密 , 对对称加密过程中的密钥又进行了一层加密 . 同时 , 还可以直接使用非对称加密对传输的数据进行加密 .
Q : 公钥密码里面,如果一方用自己的私钥加密,解密用自己的公钥,公钥不是公开的吗?这样来说的话,任何人都可以解开,这次加密还有什么用呢?
A :
信息传输有两条路径,一是信息加密,二是身份认证,上面这种只是身法认证环节,任何人拥有了你的公钥,都能确认是“你”发出的(因为你使用自己的私钥加密的,这个环节叫电子签名)。
而具体的密文的加密是使用你的公钥加密的,只有你的私钥可解密,其它人没有你的私钥,虽然收到了消息,也知道是你发出的(即前面说的身份认证过程畅通无阻),但是没法解密,因此无法知道具体信息内容。
也就是说 , 同是加密,但是应用场景是不一样的。
公钥加密为了数据机密,只有对应的私钥可以解密获取。
私钥加密为了数据来源可靠、合法,谁来解开都一样,比如数字证书、签名等。
上述的过程并非无懈可击 , 黑客还有其他手段—“中间人攻击” .
中间人攻击 (Man-in-the-MiddleAttack,简称“MITM 攻击 ”)是指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方直接对话,但事实上整个会话都被攻击者完全控制.
如何解决中间人的攻击呢?
破解中间人攻击的关键,就是让客户端能够验证,当前得公钥是否来自于真实的服务器!

fiddler如何实现抓包HTTPS ? fiddler其实就是在进行中间人攻击 !!! 首次勾选fiddler的https , 提示是否要安装一个证书 , 这个就是fiddler为了进行中间人攻击 , 自己生成的证书 ; 安装了这个证书 , 浏览器才会信任fiddler , 浏览器才不会弹框 !
以上就是HTTP部分的全部内容 !