MapReduce--Shuffle图解详解
Shuffle图解
- 0、前言
- 1、功能
-
- 分区:`决定了Map输出的数据会被哪个Reduce 进行处理`
- 排序:`决定了Map输出的数据按照Key以什么样的方式进行排序`
- 分组:`实现了对Key进行分组,属于同一组的Value会放入同一个迭代器中`
- 2、过程
-
- 图解
- 准备
- Input:`TextInputFormat extends FileInputFormat extends InputFormat`
- Map:`自己定义Map类继承Mapper类`
- ==Shuffle==
-
- Map端的Shuffle过程:`对每个MapTask输出的数据进行处理:流程是一致的`
-
- Spill阶段:`将内存中数据写入磁盘`
-
- ==分区==:对即将写入磁盘的数据调用分区器的getPartition方法,获取这条数据最终会被哪个reduce进行处理,假设有两个reduce
- ==排序==:相同分区的数据放在一起,并且按照key做排序,每个分区内部有序
- Merge阶段:合并的阶段
- Map端Shuffle总结
- ==Reduce端的Shuffle过程==
-
- 拉取数据
- merge:每个ReduceTask将所有从MapTask中取出的数据进行合并
- group:相同key的value放入一个迭代器
- Reduce端shuffle总结
- Reduce
- Output
0、前言
- 早期的大数据主要应用在统计分析:分组和排序
- 数据量非常大,即使我们做分布式,可以处理大数据,但是排序这种无法做到跨机器的整体有序,
每台机器处理一部分数据的排序
- 数据量非常大,即使我们做分布式,可以处理大数据,但是排序这种无法做到跨机器的整体有序,
- 大量数据需要进行排序
- 每台机器对一部分数据进行排序
- 将每台机器排序的结果写入磁盘
- 通过插入排序这种基于磁盘排序 的算法来实现排序
- Shuffle过程必用磁盘:非常慢
能避免不产生shuffle就不产生shuffle
1、功能
分区:决定了Map输出的数据会被哪个Reduce 进行处理
- 默认规则:按照key的hash值取余Reduce的个数实现分区
- 自定义分区
- 继承Partitioner类
- 重写getPartition
- 代码中的设置
job.setPartitionerClass(UsesrFlowPartition.class);
排序:决定了Map输出的数据按照Key以什么样的方式进行排序
- 默认规则:优先调用排序比较器
job.setSortComparatorClass(null);
- 默认规则:如果没有排序器会调用数据类型自带的比较器方法实现排序
- 详细参考自定义数据类型之方式二:构建一个JavaBean实现WritableComparable接口
/**
* 对于这个类型在Shuffle中的排序,按照上行流量降序
* @param o
* @return
*/
@Override
public int compareTo(FlowBean02 o) {
//只按照上行总流量降序排序即可
return -Long.valueOf(this.getUpFlow()).compareTo(Long.valueOf(o.getUpFlow()));
}
分组:实现了对Key进行分组,属于同一组的Value会放入同一个迭代器中
分组的本质:也是比较,如果key相同就是一组,不相同就不是一组
规则- 默认规则:优先调用分组比较器
job.setGroupingComparatorClass(null);
- 默认规则:如果没有分组比较器,调用数据类型自带的比较器方法来实现
- 整体的分组的规则与排序类似
- 排序:要比较大小,构建排序
- 分组:比较是否相等,实现分组
都需要调用比较器来实现
2、过程
图解
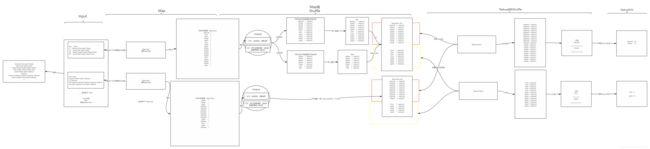
准备
数据:wc.txt
hadoop hive spark hbase
spark hive spark spark
hbase hbase hbase hbase hbase
hive hbase hbase hbase hive
spark hbase spark hadoop
hadoop
hadoop hadoop hadoop hadoop hadoop
spark hadoop hive spark hadoop
Input:TextInputFormat extends FileInputFormat extends InputFormat
- 功能一:将大的数据进行拆分:
分片:getSplit- split1
hadoop hive spark hbase
spark hive spark spark
hbase hbase hbase hbase hbase
hive hbase hbase hbase hive
- split2
spark hbase spark hadoop
hadoop
hadoop hadoop hadoop hadoop hadoop
spark hadoop hive spark hadoop
- 功能二:
每个分片的每条数会被转换KeyValue对:nextKeyValue- Split1
key value
0 hadoop hive spark hbase
10 spark hive spark spark
20 hbase hbase hbase hbase hbase
30 hive hbase hbase hbase hive
- Split2
key value
0 spark hbase spark hadoop
10 hadoop
20 hadoop hadoop hadoop hadoop hadoop
30 spark hadoop hive spark hadoop
所有分片的KeyValue会传递给Map阶段
Map:自己定义Map类继承Mapper类
- 功能:
Map阶段会根据Input传递过来的分片启动对应的MapTask进程- 一个分片 = 一个MapTask
- MapTask1:负责处理Split1的KeyValue对
- MapTask2:负责处理Split2的KeyValue对
- 逻辑:
每个MapTask都会调用map方法对自己负责的每个KeyValue 进行处理- map:对每行的单词分割,输出单词和1
- 输出
- MapTask1
hadoop 1
hive 1
spark 1
hbase 1
spark 1
hive 1
spark 1
spark 1
hbase 1
hbase 1
hbase 1
hbase 1
hbase 1
hive 1
hbase 1
hbase 1
hbase 1
hive 1
- MapTask2
spark 1
hbase 1
spark 1
hadoop 1
hadoop 1
hadoop 1
hadoop 1
hadoop 1
hadoop 1
hadoop 1
spark 1
hadoop 1
hive 1
spark 1
hadoop 1
Shuffle
Map端的Shuffle过程:对每个MapTask输出的数据进行处理:流程是一致的
- 以MapTask1为例,输出
hadoop 1
hive 1
spark 1
hbase 1
spark 1
hive 1
spark 1
spark 1
hbase 1
hbase 1
hbase 1
hbase 1
hbase 1
hive 1
hbase 1
hbase 1
hbase 1
hive 1
Spill阶段:将内存中数据写入磁盘
- 每个MapTask输出的数据【内存】会进入一个环形缓冲区【内存:100M区域】
- 当整个缓冲区存储的数据达到80%{数据和数据的索引},就会触发spill溢写:将缓冲区的数据写入磁盘
- 在写入磁盘之前,这些数据会被锁定:会做两件事情,即
分区和排序 - 留20%的目的:缓冲 溢写不是一瞬间就实现的,要考虑溢写速度跟写缓冲速度,一般写缓冲速度是大于溢写速度的。
分区:对即将写入磁盘的数据调用分区器的getPartition方法,获取这条数据最终会被哪个reduce进行处理,假设有两个reduce
hadoop 1 reduce1
hive 1 reduce2
spark 1 reduce2
hbase 1 reduce1
spark 1 reduce2
hive 1 reduce2
spark 1 reduce2
spark 1 reduce2
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
- 第二批数据
hbase 1 reduce1
hbase 1 reduce1
hive 1 reduce2
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hive 1 reduce2
排序:相同分区的数据放在一起,并且按照key做排序,每个分区内部有序
- 排序方式:要么是排序比较器要么是数据类型的compare
- 排序算法:
内存中的这次排序:归并排序 - 第一批:要写入文件的数据
hadoop 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hive 1 reduce2
hive 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
- 第二批:要写入文件的数据
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hive 1 reduce2
hive 1 reduce2
- 将这些被锁定的数据写入文件,由于不断的触发溢写,会有很多批数据,整个磁盘中会有多个文件
file1
hadoop 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hive 1 reduce2
hive 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
file2
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hive 1 reduce2
hive 1 reduce2
- 直到这个MapTask所处理的所有数据全部写入磁盘,变成多个小文件
- 很多MapTask,每个MapTask都会产生很多小文件
- MapTask1
file1
hadoop 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hive 1 reduce2
hive 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
file2
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hive 1 reduce2
hive 1 reduce2
- MapTask2
file1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hbase 1 reduce1
spark 1 reduce2
spark 1 reduce2
file2
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hive 1 reduce2
spark 1 reduce2
spark 1 reduce2
Merge阶段:合并的阶段
每个MapTask产生的所有的小文件会进行合并
- 合并的过程中会产生排序:相同分区的数据会放在一起,并且分区内部有序
- 排序方法:排序比较器或者compare
- 排序算法:插入排序:适合于基于有序文件大量数据的合并排序
- 最终:每个MapTask产生一个大文件
- MapTask1
hadoop 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hive 1 reduce2
hive 1 reduce2
hive 1 reduce2
hive 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
- MapTask2
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hbase 1 reduce1
hive 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
- 至此:整个Map端的shuffle结束了
Map端Shuffle总结
- spill:将每个MapTask的数据写入磁盘,并且分区和排序,并且多个小文件
- merge:每个MapTask将自己的所有小文件合并并排序,最终得到一个大文件
所有MapTask都生成一个大文件以后,整个Map端shuffle结束,会通知ReduceTask过来取数据
Reduce端的Shuffle过程
取数据:每个ReduceTask会到每个Map输出的结果文件中取属于自己要处理的数据
拉取数据
- ReduceTask1
从MapTask1拉取数据
hadoop 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
从MapTask2拉取数据
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hbase 1 reduce1
- ReduceTask2
从MapTask1拉取数据
hive 1 reduce2
hive 1 reduce2
hive 1 reduce2
hive 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
从MapTask2拉取数据
hive 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
merge:每个ReduceTask将所有从MapTask中取出的数据进行合并
合并的过程中进行排序:插入排序
- ReduceTask1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hadoop 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
hbase 1 reduce1
- ReduceTask2
hive 1 reduce2
hive 1 reduce2
hive 1 reduce2
hive 1 reduce2
hive 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
spark 1 reduce2
group:相同key的value放入一个迭代器
- ReduceTask1
hadoop 1,1,1,1,1,1,1,1,1,1
hbase 1,1,1,1,1,1,1,1,1,1
- ReduceTask2
hive 1,1,1,1,1
spark 1,1,1,1,1,1,1,1
Reduce端shuffle总结
- 拉取数据:每个ReduceTask到每个MapTask生成的大文件中取属于自己的数据
- merge:每个ReduceTask将所有MapTask中自己的数据进行合并并排序
目的:提高分组的效率,相同的key都放在一起 - 分组:相同key的value放入同一个迭代器
Reduce
- reduce方法
每个ReduceTask都对自己的每一条数据调用reduce方法 - ReduceTask1
hadoop 10
hbase 10
- ReduceTask2
hive 5
spark 8
Output
- part-r-00000
- part-r-00001