大型 APP 的性能优化思路
做客户端开发都基本都做过性能优化,比如提升自己所负责的业务的速度或流畅性,优化内存占用等等。但是大部分开发者所做的性能优化可能都是针对中小型 APP 的,大型 APP 的性能优化经验并不会太多,毕竟大型 APP 就只有那么几个,什么是大型 APP 呢?以飞书来说,他的业务有 im,邮箱,日历,小程序,文档,视频会议……等等,包体积就有大几百 M,像这种业务非常多且复杂的 APP 都可以认为是大型 APP。所以我在这篇文章主要讲一下大型 APP 是怎么做性能优化的,给大家在性能优化一块提供一个新的视角和启发。在这篇文章中,我主要会讲一下这两个主题:
-
大型 app 相比于中小型 app 在做性能优化时的异同点
-
大型 app 性能优化的思路
大型和小型应用性能优化的异同点
1.1 相同点
性能优化在本质上以及在优化维度上都是一样的。性能优化的本质是合理且充分的使用硬件资源,让程序表现的更好;并且都需要基于应用层、系统层、硬件层三个维度来进行优化

1.2 不同点
针对系统层和硬件层的优化都是一样,有区别的主要是针对应用层的优化。
中小型 app 做业务和做性能优化的往往是同一个人,在做优化的时候,只需要考虑单个业务最优即可,我们只需要给这些业务充足的硬件资源(比如给更多的内存资源:缓存更多的数据,给更多的 cpu 资源:用更多的线程来执行业务逻辑,给更多的磁盘资源:缓存足够的本地数据),并且合理的使用就能让业务表现的更好。只要这些单个的业务性能表现好,那么这款 app 的整体性能品质是不错

和中小型 APP 不同的是,大型 APP 业务多且复杂,各个业务的团队很可能都不在一个部门,不在同一个城市。在这种情况下,如果每个业务也去追求自己业务的性能最优,同样是在自己的业务中使用更多的线程,使用更多的缓存,使用更多 cpu 的方式来使自己业务表现更好,那么就会导致 APP 整体的性能急剧劣化。因此大型 APP 需要有一个专门团队来做性能优化的,这个团队需要脱离某一个具体业务,站在全局的视角来让 APP 整体表现更优。
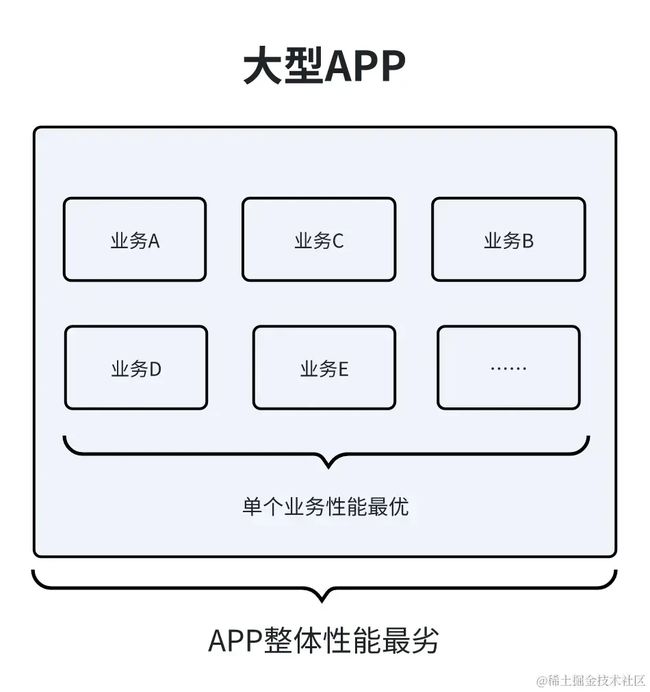
大型应用性能优化方案
总的来说由于资源是有限的,在中小型 APP 上,业务少,资源往往是充足的,我们做性能优化时往往考虑的是怎么将资源充分的发挥出来,而在大型 APP 上,资源往往是不足的,做性能优化时需要考虑即能充分发挥硬件资源,又需要进行合理的分配,当我们站在全局的视角来进行资源分配时,就需要考虑到这三个点:
- 如何管控业务对资源的使用
- 如何度量业务对资源的消耗
- 如何让业务在资源紧张时做出更优的策略
下面我会针对速度及流畅性优化、内存优化这两个方向,讲一讲针对这这三点的体现。
2.1 速度和流畅性优化:如何管控业务对资源的使用
在速度和流畅性方向,中小型 APP 只需要分析和优化主路径的耗时逻辑;将同步任务尽量优化成异步任务;多进行预加载等方案,即能起很好的优化效果。但是对于大型 APP 来说,异步任务往往非常多,cpu 往往都是打满的情况,这种情况下主路径得不到足够的 cpu 资源,导致速度变慢。所以大型 app 中一般都会对业务的异步任务,如启动阶段的预加载进行管控,因此需要预加载框架或者类似的框架,来收敛、管控、以及调度所有业务的预加载任务。我们来看一下在大型 APP 中,通用的预加载框架是怎么做的。
2.1.1 预加载框架
想要管控业务的预加载任务,我们需要考虑这两个点:
-
预加载任务的添加方式
-
预加载任务调度和管理的机制
-
预加载任务的添加方式
首先要将业务的预加载任务和业务进行解耦,要能做到即使该预加载任务不执行,也不会影响到业务的正常使用,并且将预加载任务封装成粒度最小的 task,然后直接将这些 task 丢到到预加载框架中,我们可以通过单例提供一个 addPreloadTask 方法,业务方只需要调用该接口,并传入预加载任务 task 以及一些属性及配置参数即可。将预加载任务添加到预加载框架后,业务方就不需要进行任何其他操作了,是否执行、什么时候执行,都交给预加载框架来管理。

-
预加载任务调度时机
那么预加载框架对于添加进来的 task 如何调度呢?这就是一个预加载框架复杂的的地方的,我们可以有很多策略,比如这三种:
- 关键节点调度策略:比如各个生命周期阶段,页面渲染完成阶段等去执行,也可以在任务添加进来后立刻执行。
- 性能调度策略:比如判断 cpu 是否忙碌,温度是否过高,内存是否充足等,只有在性能较好的情况下才进行调度
- 用户行为调度策略:如果做的更复杂一些,还可以结合用户的行为指标,如该业务用户是否会使用,如果某一个用户从来不适用这个 app 里的这个功能,那么改业务添加进来的预加载任务就可以完全舍弃到,这里面可以用一些端智能的方案来精细化的控制预加载任务的调度
每种调度策略不是单独执行的,我们可以将各种策略整合起来,形成一套完善的调度策略。

2.2 速度和流畅性优化:如何让业务在资源紧张时做出更优的策略
上面提到的是站在全局的视角,如何管控预加载任务的,除了预加载任务,还有很多其他的异步任务我们都可以用一些框架来规范化的管控起来,这里再举一个例子,对于大型 APP 来说,业务在使用的过程中很容易出现因为 cpu 或内存不足导致卡顿,响应慢等性能问题,所以在做性能优化时,是需要推动业务方在资源不足时,做出相应策略的,这个时候我们就需要降级框架来处理了。降级框架需要解决这两个问题:
- 性能指标的采集
- 降级任务的调度
2.2.1 降级框架
-
性能指标的采集
想要再资源紧张时让业务做出优化策略,那么对资源紧张的判断就是必不可少的一步。我们一般通过在程序运行过程中,采集设备性能指标来判断资源是否紧张,最基本的性能指标有 cpu 使用率,温度,Java 内存,机型等,除机型外其他性能指标一般都是以固定的频率进行采集,如 cpu 使用率可以 10s 采集一次,温度可以 30s 采集一次,java 内存可以 1 分钟采集一次,采集的频率需要考虑对性能的影响以及指标的敏感度,比如 cpu 的使用率采集,需要读取 proc/stat 的文件并解析,是有一定性能损耗的,所以我们在采集时,不能太频繁;温度的变化是比较慢的,我们采集的频率也可以长一些。降级框架需要整合这些性能指标的采集,减少各个业务自己采集造成不必要的性能损耗。
当降级框架采集到性能指标,并判断当前资源异常时,通用的做法是通知各个业务,业务收到通知后再进行降级。比如系统的 lowmemorykiller 机制,都是采用通知的方式。

但是在大型 APP 中,仅仅将触发性能阈值的通知给到各个业务方,效果不会太好,因为业务方可能并不会去响应通知,或者个别业务响应了,但是其他业务不响应,依然效果不佳。无法管控业务是否进行降级,这显然不符合在大型 APP 做性能优化的思路,那么我们要怎么做呢?
-
降级任务的调度
添加任务:我们依然可以推动各个业务将降级的逻辑封装在 task 中,并且注册到降级框架中,并由降级框架来进行调度和管理。因为往降级框架注册 task 时,需要带上业务的名称,所以我们能也能清楚的知道,那些业务有降级处理逻辑,哪些业务没有,对于没有注册的业务,需要专门推动进行降级响应以及 task 的注册。
调度任务:和预加载框架一样,对于注册进来的 task,降级框架的任务调度要考虑清楚调度的时机,以 cpu 使用率为例,不同的设备下的阈值也是不一样的,高端机型可能 cpu 的使用率在 70%以上,app 还是流畅的,但是低端机在 50%以上就开始卡顿了,因此不同的机型需要根据经验值或者线上数据设置一个合理的阈值。当 cpu 到达这个阈值时,降级框架便开始执行注册到 cpu 列表中的降级任务,在执行降级任务时,不需要将队列里的 task 全部执行,我们可以分批执行,如果执行到某一批降级 task 时,cpu 恢复到阈值以下了,后面的降级 task 就可以不用在执行了。可以看到,通过降级框架,我们就可以站在全局的维度,去进行更好的管控,比如我们可以度量业务做降级任务的效果,给到一个评分,对于效果不好的,可以推动优化。

2.3 内存优化:如何度量业务对资源的消耗
上面两个例子将的是在大型 app 中,如何管控业务对资源的使用,以及如何让业务在资源紧张时做出更优的策略的思路,我接着基于内存优化的方向,讲一讲如何度量业务对资源的消耗。
当 app 运行过程中,往往只能获得整体的内存的数据占用,没法获的各个业务消耗了多少内存的,因为各个业务的数据都是放在同一个堆中的,对于小型 app 来说这种情况并不是问题,因为就那么几个业务在使用内存,但是对于大型 app 来说就是一个问题了,有些业务为了自己性能指标能更好,会占用更多的内存,导致整体的内存占用过高。所以我们需要弄清每个业务到底使用了多少内存才能推动业务进行优化。

我们可以线下通过分析 hprof 文件或者其他调试的方式来弄清楚每个 app 的内存占用,但是很多时候没有充足的时间在版本都去统计一下,或者即使统计了,也可能因为路径没覆盖全导致数据不准确。所以我们最好能通过线上监控的方式,就能统计到业务的内存消耗,并且在内存消耗异常的时候进行上报。
我在这里介绍一种思路。大部分的业务都是以 activity 呈现的,所以我们可以监听全局的 activity 创建,在业务的 onCreate 最前面统计一下 java 和 native 内存的大小,作为这个业务启动时的基准内存。然后在 acitvity 运行过程中,固定采集在当前 activity 下的内存并减去 onCreate 时的基准内存,我们就能度量出当前业务的一个内存消耗情况了。在该 acitvity 结束后,我们可以主动触发一下 gc,然后在和前面的基准内存 diff 一下,也能统计出该业务结束后的增量内存,理想情况下,增量内存应该是要小于零的,由于 gc 需要 cpu 资源,所以我们只需要开取小部分的采样率即可。

当我们能在运行过程中,统计各个业务的内存消耗,那么就可以推动内存消耗高的业务进行优化,或者当某个版本的某个业务出现较大的劣化时,触发报警等。
除了上面提到的思路,我们也可以统计在业务使用过程中的触顶次数,计算出一个触顶率的指标,触顶及 java 内存占用达到一个阈值,比如 80%,我们就可以认为触顶了,对于触顶次数高的业务,同样也可以进行异常上报,然后推动业务方进行修改。这些数据和指标的统计,都是无侵入的,所以并不需要我们了解业务的细节。
如果我们想做的更细一些,还可以 hook 图片的创建,hook 集合的 add,remove 等方法,当监控到大图片和大集合时,打印堆栈,并将关键信息上报。在飞书,如果是低端机中,图片如果占用内存过大的,都会在 hook 方法中进行一些压缩或者降低质量的兜底处理。
总结
除了速度及流畅性,内存方向的优化外,还有其他方向的优化,如包体积,稳定性,功耗等,在大型 APP 上都要基于管控业务对资源的使用;度量业务对资源的消耗;让业务在资源紧张时做出更优的策略这三个方向去进行优化,这里我就不再一一展开讲了。

当然我这里讲的优化思路并不是大型 app 做性能优化的全部,我讲的只是在做大型 app 的性能时相比于中小型 app 需要额外做的,并且也是效果最好的优化,这些方案在中小型 app 上可能并不需要。除了我这篇文章讲的内容外,还有很多优化的方案,这些方案不管是在大型 app 还是中小型 app 上都是通用的,比如深入了解业务,基于业务逻辑去做分析和优化,抓 trace,分析 trace 等等,或者基于系统层或者硬件层去做一些优化等等,这里就不再展开讲了。
为了帮助到大家更好的全面清晰的掌握好性能优化,准备了相关的核心笔记(还该底层逻辑):https://qr18.cn/FVlo89
性能优化核心笔记:https://qr18.cn/FVlo89
启动优化

内存优化

UI优化
网络优化

Bitmap优化与图片压缩优化:https://qr18.cn/FVlo89

多线程并发优化与数据传输效率优化
体积包优化
《Android 性能监控框架》:https://qr18.cn/FVlo89

《Android Framework学习手册》:https://qr18.cn/AQpN4J
- 开机Init 进程
- 开机启动 Zygote 进程
- 开机启动 SystemServer 进程
- Binder 驱动
- AMS 的启动过程
- PMS 的启动过程
- Launcher 的启动过程
- Android 四大组件
- Android 系统服务 - Input 事件的分发过程
- Android 底层渲染 - 屏幕刷新机制源码分析
- Android 源码分析实战
