Golang教程笔记
性能与优点、不足介绍
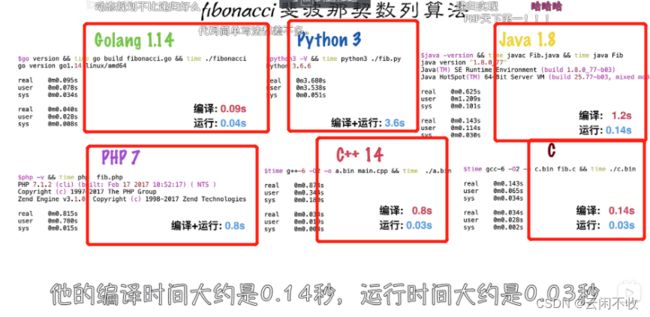
go的性能很好!原生语法支持并发(实现起来很简单)
而且项目能编译成一个文件,部署起来方便!

1、这里不是go mod go modules 这种方式稳定性不好 毕竟github可能是私有仓库 某天突然删了
2、已经加了
3、java 的error是jvm级别 会直接导致jvm停止运行 所以go和java是两个极端 go只有error java都是exception
第一个go程序
package main //package main。package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包。
import "fmt" //基本函数包
func main() { // notice { 不能在单独的行上
fmt.Println("Hello," + " World!")
//1当两句代码不在一行时 不需要行分隔符;
//2go语言连接符为+
//3go的调用方式也类似java 类的写法
}
运行和编译
方法1:编译二进制文件执行
$ go build hello.go //命令行
$ ./hello //命令行
Hello, World! //结果
方法2:
$ go run hello.go
第一行代码 package main 定义了包名。你必须在源文件中非注释的第一行指明这个文件属于哪个包,如:package main。package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包。
下一行的 import “fmt” 告诉 Go 编译器这个程序需要使用 fmt 包(的函数,或其他元素),fmt 包实现了格式化 IO(输入/输出)的函数。
再下一行 func main() 是程序开始执行的函数。main 函数是每一个可执行程序所必须包含的,一般来说都是在启动后第一个执行的函数(如果有 init() 函数则会先执行该函数)。
封装: 当标识符(包括常量、变量、类型、函数名、结构字段等等)以一个大写字母开头,如:Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(客户端程序需要先导入这个包),这被称为导出(像面向对象语言中的 public);标识符如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的(像面向对象语言中的 protected )。
输出

可以这么写 %T是类型输出
变量类型和申明
var identifier type 如:var a int
var b, c int = 1, 2 //bc都是int
也可自动判断类型 var v_name = value
var d = true //这种方式只能用于函数体内 即不能用于全局变量!
还可以使用:=
i := 1
多变量申明
如:vname1, vname2, vname3 := v1, v2, v3//可套用上面其他两种方法,用,分开即可
默认值
- 数值类型(包括complex64/128)为 0
- 布尔类型为 false
- 字符串为 “”(空字符串)
以下几种类型为 nil:
var a *int
var a []int
var a map[string] int
var a chan int
var a func(string) int
var a error // error 是接口
简单来说 就是除了基本类型 数字 字符串 布尔 其他都为nil
值类型和引用类型
所有像 int、float、bool 和 string 这些基本类型都属于值类型,使用这些类型的变量直接指向存在内存中的值:
数值类型的=是拷贝,引用类型的=是地址被复制
你可以通过 &i 来获取变量 i 的内存地址
局部变量一旦申明必须被使用
如果你声明了一个局部变量却没有在相同的代码块中使用它,同样会得到编译错误,例如下面这个例子当中的变量 a:
func main() {
var a string = "abc"
fmt.Println("hello, world")
}
但是可以在全局变量中使用它
交换变量与_
如果你想要交换两个变量的值,则可以简单地使用 a, b = b, a,两个变量的类型必须是相同。
空白标识符 _ 也被用于抛弃值,如值 5 在:_, b = 5, 7 中被抛弃。
真实含义是代表你不关心它,比如range循环 你可能不关心value是多少
常量申明
显式类型定义: const b string = "abc"
隐式类型定义: const b = "abc"
iota—只能和const一起使用
应用场景 比如写错误码 或者用const写枚举类型,iota就很方便了

第一个 iota 等于 0,每当 iota 在新的一行被使用时,它的值都会自动加 1;
package main
import "fmt"
func main() {
const (
a = iota //0
b //1
c //2
d = "ha" //独立值,iota += 1
e //"ha" iota += 1
f = 100 //iota +=1
g //100 iota +=1
h = iota //7,恢复计数
i //8
)
fmt.Println(a,b,c,d,e,f,g,h,i)
}
类型转换
var sum int = 17
var count int = 5
var mean float32
mean = float32(sum)/float32(count)
条件判断
Go 没有三目运算符,所以不支持 ?: 形式的条件判断。
select 语句类似于 switch 语句,但是select会随机执行一个可运行的case。如果没有case可运行,它将阻塞,直到有case可运行。
if
if语句,如
a:=10
if a < 20 {
xxx
}
也可在if中赋值
if a:=10,a < 20 {
xxx
}
注意 go中不能像其他语言那样 if(a)(a是int类型)的判断
val, ok := map[key] //如果key在map里 val 被赋值map[key] ok 是true 否则val得到相应类型的零值;ok是false
//常用写法
if val, ok := map[key]; ok {
//do something here
}
for
和 C 语言的 for 一样:
for init; condition; post { } //初值;循环控制条件;赋值增量或减量
和 C 的 while 一样:
for condition { }
和 C 的 for(;;) 一样:
for { }
init: 一般为赋值表达式,给控制变量赋初值;
condition: 关系表达式或逻辑表达式,循环控制条件;
post: 一般为赋值表达式,给控制变量增量或减量。
range
for 循环的 range 格式可以对 slice、map、数组、字符串等进行迭代循环。格式如下:
for key, value := range oldMap { //依然要写for
newMap[key] = value
}
这个没php的foreach简洁==
函数
go语言至少需要一个main函数
func function_name( [parameter list] ) [return_types] {
函数体
}
//如
func max(num1, num2 int) int {
}
func main() {
var a int = 100
var b int = 200
var ret int
/* 调用函数并返回最大值 */
ret = max(a, b)
fmt.Printf( "最大值是 : %d\n", ret )
}
函数返回多个值—类似php的list方法 其实很好实现
func swap(x, y string) (string, string) {
return y, x
}
func main() {
a, b := swap("Google", "Runoob") //这里也能自动推断
fmt.Println(a, b)
}

这里的返回 只是简便写法 函数外部依然看不到r1 r2
注意!:数组是值传递,切片、Map是引用传递!结构体是值传递。,但是go1.7好像变成了引用传递?
函数作为参数
package main
import (
"fmt"
"math"
)
func main(){
/* 声明函数变量 */
getSquareRoot := func(x float64) float64 {
return math.Sqrt(x)
}
/* 使用函数 */
fmt.Println(getSquareRoot(9))
}
匿名函数(闭包)
package main
import "fmt"
func getSequence() func() int { //后面的func() int 当成一体的 就是一个返回值!
i:=0
return func() int { //实际上就是把这里原封不动抄上去了而已
i+=1
return i
}
}
func main(){
/* nextNumber 为一个函数,函数 i 为 0 */
nextNumber := getSequence()
/* 调用 nextNumber 函数,i 变量自增 1 并返回 */
fmt.Println(nextNumber())//1
fmt.Println(nextNumber())//2
fmt.Println(nextNumber())//3
/* 创建新的函数 nextNumber1,并查看结果 */
nextNumber1 := getSequence()
fmt.Println(nextNumber1())//1
fmt.Println(nextNumber1())//2
}
go方法(类似面向对象的成员函数)
Go 没有面向对象,而我们知道常见的 Java C++ 等语言中,实现类的方法做法都是编译器隐式的给函数加一个 this 指针,而在 Go 里,这个 this 指针需要明确的申明出来,其实和其它 OO 语言并没有很大的区别。
package main
import (
"fmt"
)
/* 定义结构体 */
type Circle struct {
radius float64
}
func main() {
var c1 Circle
c1.radius = 10.00
fmt.Println("圆的面积 = ", c1.getArea())
}
//该 method 属于 Circle 类型对象中的方法
func (c Circle) getArea() float64 {
//c.radius 即为 Circle 类型对象中的属性
return 3.14 * c.radius * c.radius
}
所以 “结构体也就可以近似的看成对象”
数组(静态)
其实记住这2种就够了
var balance [10] float32 //仅仅申明 后续可以用 balance[1]=1 来赋值
var balance = [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0} //三个点也可换成数组 手动指定长度
申明数组,如
var balance [10] float32
var balance = [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
balance := [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
如果数组长度不确定,可以使用 … 代替数组的长度,编译器会根据元素个数自行推断数组的长度:
var balance = [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
或
balance := [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
如果设置了数组的长度,我们还可以通过指定下标来初始化元素:
// 将索引为 0 和 2 的元素初始化
balance := [5]float32{0:2.0,2:7.0}
语言切片(实际就是动态数组)
Go 语言切片是对数组的抽象。
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用(比如函数传参等),Go 中提供了一种灵活,功能强悍的内置类型切片(“动态数组”),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
注意:数组是值传递,切片是引用传递!
[]type
方法 :len、cap等
make的意思是“开辟内存空间” go中 可以不指定初始值 而先开辟一个内存空间给它“占位”
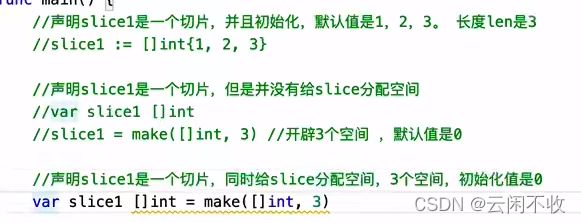
[]int 第一个代表是一个数组 第二个int代表里面的元素是int
//你可以声明一个未指定大小的数组来定义切片:
var identifier []type //!这里和普通数组那里的区别是,这里方括号李既没数字也没三个点!
//也可指定切片的length和容量
var slice1 []type = make([]T, length, capacity) //length 必须写 初始切片的长度 capacity可选 如果超过了capacity go会再扩充一个capicity
// 如
var numbers = make([]int,3,5) //定义
追加元素

如果超过了capacity go会再扩充一个capicity
遍历元素

len和cap函数
func main() {
var numbers = make([]int,3,5)
printSlice(numbers)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
切片截取 用到的时候看https://www.w3cschool.cn/go/go-slice.html
一个实例:
/**
* Definition for a binary tree node.
* type TreeNode struct {//注意这里没有*
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func levelOrder(root *TreeNode) [][]int {
ret := [][]int{} //没有长度 没有三个点 这是一个切片 且为[]([]int{}) 外面是数组 里面是[]int{}
if root==nil{
return ret
}
//由于go有动态数组 所以不需要使用java的queue
queue := []*TreeNode{root}//定义一个切片 里面放的是*TreeNode指针类型 并用root初始化
for i := 0; len(queue) > 0; i++ {//和java不同 没有isEmpty方法 所以用普通循环的形式
this_level :=[]int{}
last_queue_size := len(queue)
for j:=0;j<last_queue_size;j++{
node := queue[j]
this_level = append(this_level, node.Val)//append
if node.Left != nil {
queue = append(queue, node.Left)
}
if node.Right != nil {
queue = append(queue, node.Right)
}
}
queue = queue[last_queue_size:]//使用这个模拟java的pop
ret = append(ret, this_level)
}
return ret;
}
指针

- 定义的时候
*是指针类型 理解为 p (*int) ,p是存放整性的内存地址; make(map[string]*User)这种也是定义
int &a(c++)意思是定义一个引用//引用相当于指针再取值 他和被引用的变量都是表示同一块内存 而int a的意思是定义一个变量a
- 使用的时候,
&是对变量取地址,*是对指针取值
刚好相反
var a int= 20 /* 声明实际变量 */
var ip *int /* 声明指针变量 */
ip = &a /* 指针变量的存储地址 */
fmt.Printf("*ip 变量的值: %d\n", *ip )/* 在指针类型前面加上 * 号(前缀)来获取指针所指向的内容。 */
PS c++中不用&的方式
int swap1 (int &a,int &b){
int c;
c=a;
a=b;
b=c;
}
当一个指针被定义后没有分配到任何变量时,它的值为 nil。nil 指针也称为空指针。
一个指针变量通常缩写为 ptr。
var ptr *int
fmt.Printf("ptr 的值为 : %x\n", ptr )//这里输出的是0!
指向指针的指针
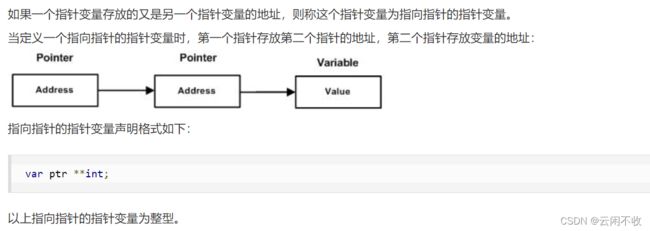
package main
import "fmt"
func main() {
var a int
var ptr *int
var pptr **int
a = 3000
/* 指针 ptr 地址 */
ptr = &a
/* 指向指针 ptr 地址 */
pptr = &ptr
/* 获取 pptr 的值 */
fmt.Printf("变量 a = %d\n", a )
fmt.Printf("指针变量 *ptr = %d\n", *ptr )
fmt.Printf("指向指针的指针变量 **pptr = %d\n", **pptr)
}
函数参数指针
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 100
var b int= 200
swap(&a, &b);
}
func swap(x *int, y *int) {
var temp int
temp = *x /* 保存 x 地址的值 */
*x = *y /* 将 y 赋值给 x */
*y = temp /* 将 temp 赋值给 y */
}
ps 这种形式并不会造成都修改的都是一个"user" 因为首先 是对单次对话而言的 ,其次 user := &User 这个是个定义符 所以是新建 而非修改旧有的
type User struct {
Name string
Addr string
C chan string
conn net.Conn
}
//创建一个用户的API
func NewUser(conn net.Conn) *User {
userAddr := conn.RemoteAddr().String()
user := &User{
Name: userAddr,
Addr: userAddr,
C: make(chan string),
conn: conn,
}
//启动监听当前user channel消息的goroutine
go user.ListenMessage()
return user
}
语言范围 Range ----实际上是foreach
看之前for循环那就行 第一个是索引 第二个是值
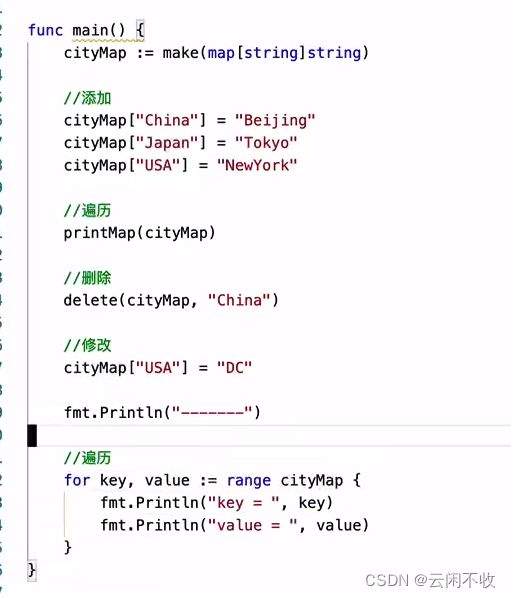
Map集合
法一 用切片的形式
var countryCapitalMap map[string]string /*创建集合 */
countryCapitalMap = make(map[string]string) //正常是比如 []bool 这里中括号里的string规定的是 key
/* map插入key - value对,各个国家对应的首都 */
countryCapitalMap [ "France" ] = "巴黎"
countryCapitalMap [ "Italy" ] = "罗马"
countryCapitalMap [ "Japan" ] = "东京"
countryCapitalMap [ "India " ] = "新德里"
/*使用键输出地图值 */
for country := range countryCapitalMap {
fmt.Println(country, "首都是", countryCapitalMap [country])
}
法二
countryCapitalMap := map[string]string{"France": "Paris", "Italy": "Rome", "Japan": "Tokyo", "India": "New delhi"}
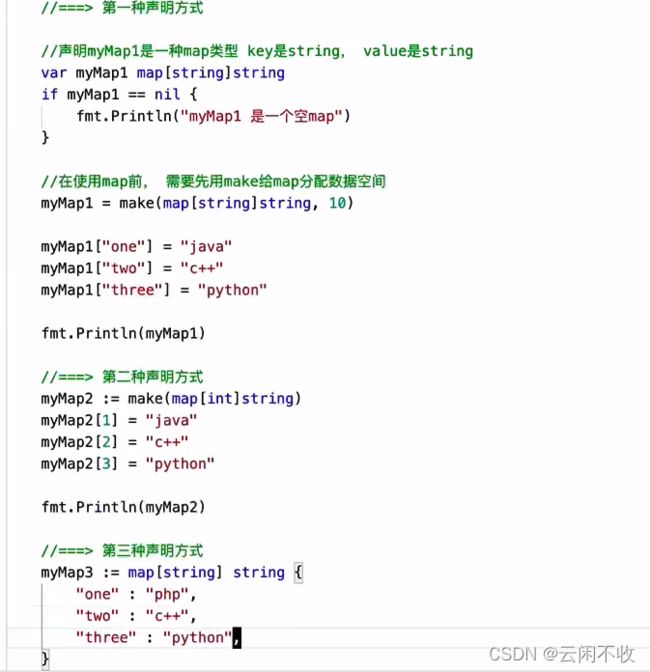
使用
val, ok := map[key] //如果key在map里 val 被赋值map[key] ok 是true 否则val得到相应类型的零值;ok是false
//常用写法
if val, ok := map[key]; ok {
//do something here
}
面向对象
结构体—对象 更准确的说是js那种对象 没有方法的数组对象
结构体可以看成是一种复杂的数据结构(由基本数据组成)

package main
import "fmt"
//这里的type是定义基础类型的意思 是为了后面用var Book1 Books 这种语法
type Books struct { //其实和变量的声明一样 type类似func var 后面是名字 在后面是类型
title string
author string
subject string
book_id int
}
func main() {
// 创建一个新的结构体 使用{}实例化
fmt.Println(Books{"Go 语言", "www.runoob.com", "Go 语言教程", 6495407})
// 也可以使用 key => value 格式
fmt.Println(Books{title: "Go 语言", author: "www.runoob.com", subject: "Go 语言教程", book_id: 6495407})
// 忽略的字段为 0 或 空
fmt.Println(Books{title: "Go 语言", author: "www.runoob.com"})
}
{Go 语言 www.runoob.com Go 语言教程 6495407}
{Go 语言 www.runoob.com Go 语言教程 6495407}
{Go 语言 www.runoob.com 0}
也可用点的形式
func main() {
var Book1 Books //这里是var了!
var Book2 Books
/* book 1 描述 */
Book1.title = "Go 语言"
TAG
类似java的注解

通过反射得到Tag信息,这个需要先看后面的反射是什么
由于go大写是public 所以对一些可能异常 要用tag规定导出格式,而且在这里 还能够实现类似数据表直接重命名,很方便

不加tag的时候,默认就是变量名
类
golang的类就是结构体+绑定的方法
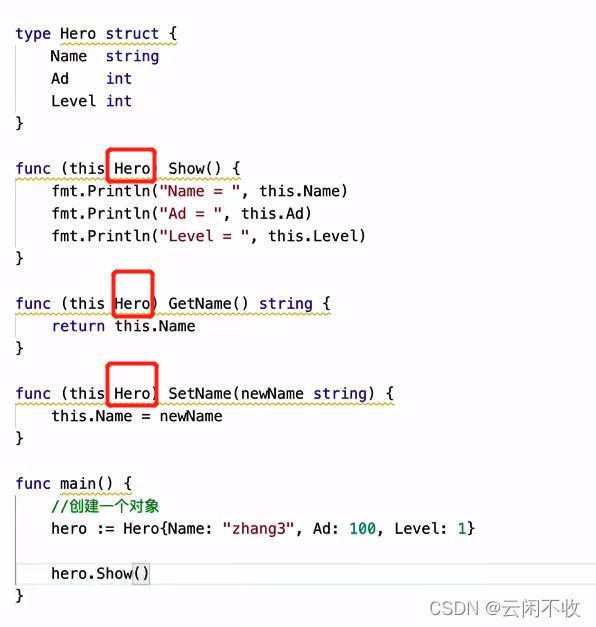
和普通函数的区别在于 func后面多了个括号。而且set方法是不管用的,因为go对待结构体是值复制传递。所以set方法要用指针
这里不写this 好像随便写啥都是可以的 只是一个名字
但是 golang官方好像不推荐 用me this 或者self 作为方法接收者
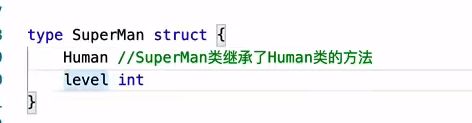
继承


接口
接口的实质是指针
接口和之前继承不一样,只要你实现了接口定义的所有方法 就相当于你实现了这个接口
type Phone interface {
call()
}
type NokiaPhone struct {
}
//func max(num1, num2 int) int 之前的函数定义是这样 这里是在前面括号李又多了
func (nokiaPhone NokiaPhone) call() {
fmt.Println("I am Nokia, I can call you!")
}
type IPhone struct {
}
func (iPhone IPhone) call() {
fmt.Println("I am iPhone, I can call you!")
}
func main() {
var phone Phone
phone = new(NokiaPhone)
phone.call()
phone = new(IPhone)
phone.call()
}
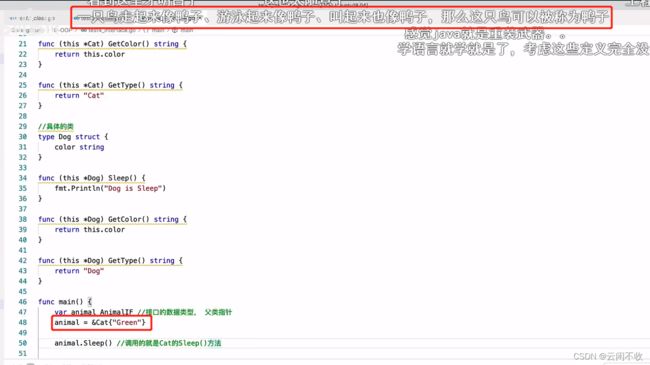

PS 结构体使用指针的原因是 这里没有用return 而上面的例子用了return 如果你想直接改变xx的值 那么就要用指针
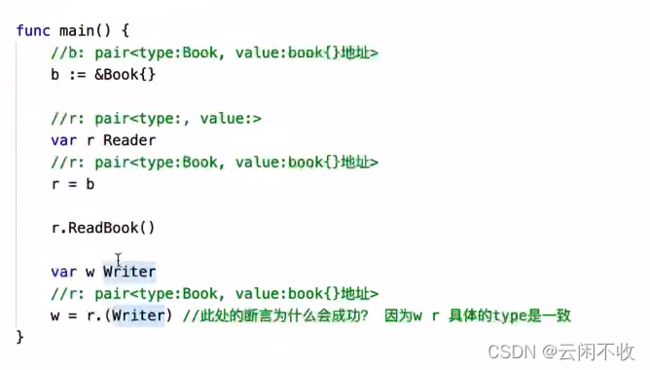
接口可用作万能数据类型。以及断言判断类型。断言相当于java的instance of
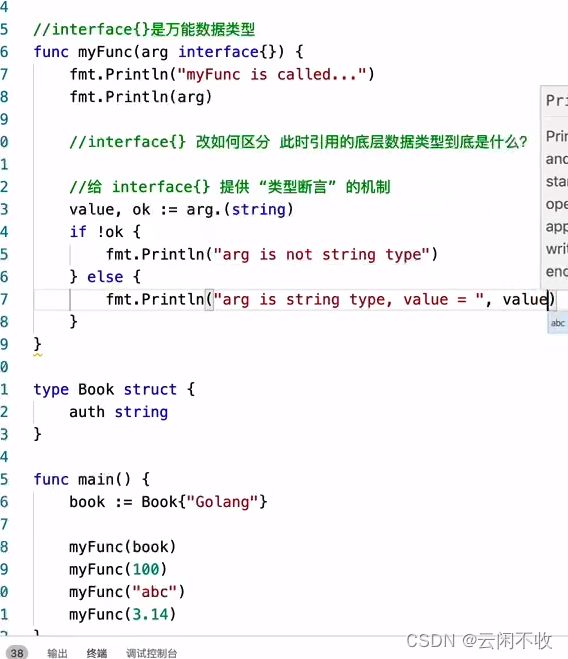
多态
go通过接口实现多态,例子同上
反射
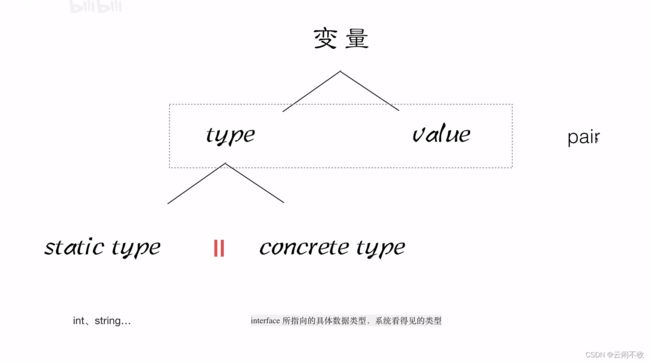
golang变量包含两个属性 type和value,这是一个pair对。
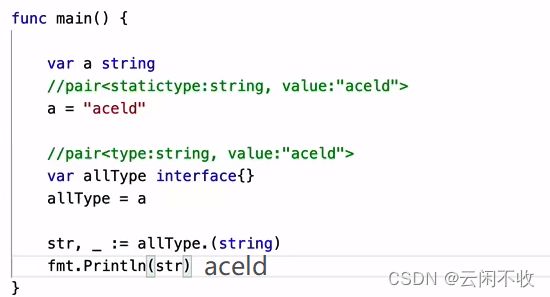

![]()
反射
反射是静态语言具有动态属性的体现

%T不也可以获取类型么?----可能%T就是通过反射来得到的
错误处理
Go 语言通过内置的错误接口提供了非常简单的错误处理机制。
error类型是一个接口类型,这是它的定义:
type error interface {
Error() string
}
我们可以在编码中通过实现 error 接口类型来生成错误信息。
函数通常在最后的返回值中返回错误信息。使用errors.New 可返回一个错误信息:
func Sqrt(f float64) (float64, error) {
if f < 0 {
return 0, errors.New("math: square root of negative number")
}
// 实现
}
并发
1、goruntine go协程
2、通道channel 可用于两个 goroutine 之间通过传递一个指定类型的值来同步运行和通讯
其实很简单 用go前缀开启即可
https://www.runoob.com/go/go-concurrent.html
注意:1、当main中开启了协程,但是main函数提前结束了(没写for循环),此时协程也会提前结束
2、由于赋值和协程同时运行,所以赋值语句无法成功!这时候就要用到通道channel
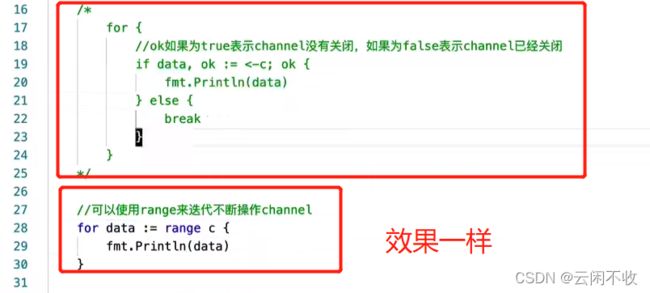
3、可用匿名函数的写法,但是如果不使用管道 依然要for循环,
4,当使用无缓存的channel,main函数无需写for循环,因为这里会自动阻塞,等待写入数据。
5、当使用不超出缓存的channel不会阻塞
6、超出缓存的channel会阻塞


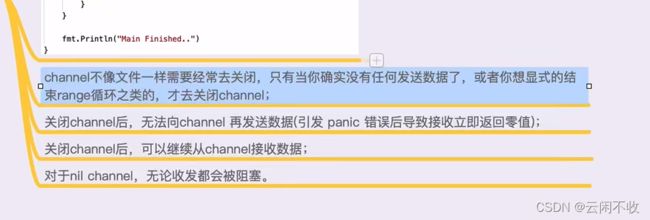
关闭channel
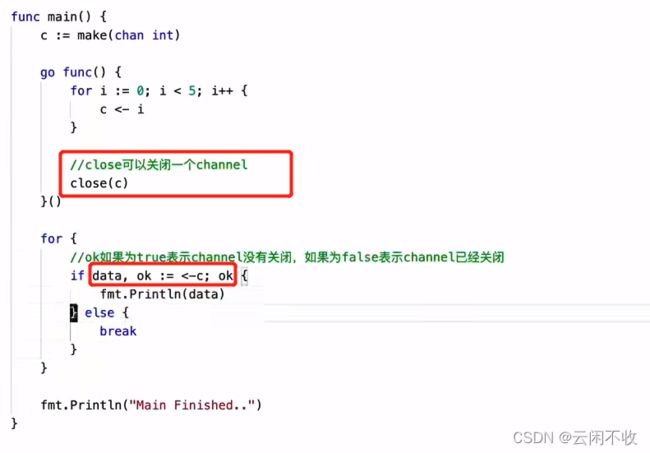
注意那个ok的简写写法
如果不关闭channel 会报错死锁,因为main还在等待写入数据,但是不会有数据了
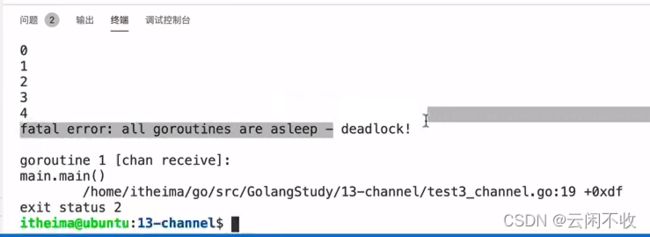
语法糖

select
select 是 Go 中的一个控制结构,类似于用于通信的 switch 语句。每个 case 必须是一个通信操作,要么是发送要么是接收。
在golang语言中,select语句 就是用来监听和channel有关的IO操作,当IO操作发生时,触发相应的case动作。有了 select语句,可以实现 main主线程 与 goroutine线程 之间的互动。
package main
import "fmt"
func main() {
var c1, c2, c3 chan int // c1 c2 c3分别是一个信道
var i1, i2 int
select {
case i1 = <-c1:
fmt.Printf("received ", i1, " from c1\n")
case c2 <- i2:
fmt.Printf("sent ", i2, " to c2\n")
case i3, ok := (<-c3): // same as: i3, ok := <-c3
if ok {
fmt.Printf("received ", i3, " from c3\n")
} else {
fmt.Printf("c3 is closed\n")
}
default:
fmt.Printf("no communication\n")
}
}
select {
case <-ch1 : // 检测有没有数据可读
// 一旦成功读取到数据,则进行该case处理语句
case ch2 <- 1 : // 检测有没有数据可写!
// 一旦成功向ch2写入数据,则进行该case处理语句
default:
// 如果以上都没有符合条件,那么进入default处理流程
注:selectd的原理 第一次运行的时候 如果case不被满足 会从上到下依次执行每个case的判断条件,当执行完了后 就会采用io多路复用模型的通知 当满足条件时候再执行case体(不重新扫描了)所以下面的定时器能运行
go func() {
for {
select {
case <-isLive:
fmt.Println("hello world")
case <-time.After(time.Second * 5):
fmt.Println("exit")
return
}
}
}()
//注意 上面每次for 都会重新执行case的判断条件
//类似的还可用time.NewTicker(time.Second * 1)实现
定时器的内存泄露问题
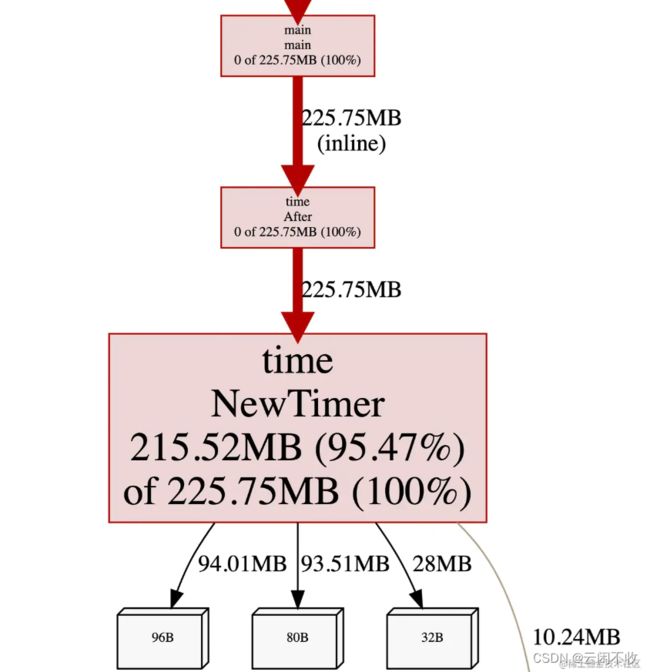
(上图用 go tool pprof 工具分析生成)
这种会造成内存泄露 因为每次for都会新建一个time对象,只有到期后会被回收。
解决方法:用time.NewTimer与time.Reset每次重新激活定时器
背景
我先贴一下会发生内存泄漏的代码段,根据代码可以更好的进行讲解:
func (b *BrokerImpl) broadcast(msg interface{}, subscribers []chan interface{}) {
count := len(subscribers)
concurrency := 1
switch {
case count > 1000:
concurrency = 3
case count > 100:
concurrency = 2
default:
concurrency = 1
}
pub := func(start int) {
for j := start; j < count; j += concurrency {
select {
case subscribers[j] <- msg:
case <-time.After(time.Millisecond * 5):
case <-b.exit:
return
}
}
}
for i := 0; i < concurrency; i++ {
go pub(i)
}
}
复制代码
看了这段代码,你知道是哪里发生内存泄漏了嘛?我先来告诉大家,这里time.After(time.Millisecond * 5)会发生内存泄漏,具体原因嘛别着急,我们一步步分析。
验证
我们来写一段代码进行验证,先看代码吧:
package main
import (
“fmt”
“net/http”
_ “net/http/pprof”
“time”
)
/**
time.After oom 验证demo
*/
func main() {
ch := make(chan string,100)
go func() {
for {
ch <- "asong"
}
}()
go func() {
// 开启pprof,监听请求
ip := "127.0.0.1:6060"
if err := http.ListenAndServe(ip, nil); err != nil {
fmt.Printf("start pprof failed on %s\n", ip)
}
}()
for {
select {
case <-ch:
case <- time.After(time.Minute * 3):
}
}
}
复制代码
这段代码我们该怎么验证呢?看代码估计你们也猜到了,没错就是go tool pprof,可能有些小伙伴不知道这个工具,那我简单介绍一下基本使用,不做详细介绍,更多功能可自行学习。
再介绍pprof之前,我们其实还有一种方法,可以测试此段代码是否发生了内存泄漏,就是使用top命令查看该进程占用cpu情况,输入top命令,我们会看到cpu一直在飙升,这种方法可以确定发生内存泄漏,但是不能确定发生问题的代码在哪部分,所以最好还是使用pprof工具进行分析,他可以确定具体出现问题的代码。
proof 介绍
定位goroutine泄露会使用到pprof,pprof是Go的性能工具,在程序运行过程中,可以记录程序的运行信息,可以是CPU使用情况、内存使用情况、goroutine运行情况等,当需要性能调优或者定位Bug时候,这些记录的信息是相当重要。使用pprof有多种方式,Go已经现成封装好了1个:net/http/pprof,使用简单的几行命令,就可以开启pprof,记录运行信息,并且提供了Web服务,能够通过浏览器和命令行2种方式获取运行数据。
基本使用也很简单,看这段代码:
package main
import (
“fmt”
“net/http”
_ “net/http/pprof”
)
func main() {
// 开启pprof,监听请求
ip := “127.0.0.1:6060”
if err := http.ListenAndServe(ip, nil); err != nil {
fmt.Printf(“start pprof failed on %s\n”, ip)
}
}
复制代码
使用还是很简单的吧,这样我们就开启了go tool pprof。下面我们开始实践来说明pprof的使用。
验证流程
首先我们先运行我的测试代码,然后打开我们的终端输入如下命令:
$ go tool pprof -http=:8081 http://localhost:6060/debug/pprof/heap
复制代码
浏览器会自动弹出,看下图:
看这个图,都爆红了,time.Timer导致占用CPU内存飙升,现在找到问题了,下面我们就可以来分析一下了。
原因分析
分析具体原因之前,我们先来了解一下go中两个定时器ticker和timer,因为不知道这两个的使用,确实不知道具体原因。
ticker和timer
Golang中time包有两个定时器,分别为ticker 和 timer。两者都可以实现定时功能,但各自都有自己的使用场景。
我们来看一下他们的区别:
ticker定时器表示每隔一段时间就执行一次,一般可执行多次。
timer定时器表示在一段时间后执行,默认情况下只执行一次,如果想再次执行的话,每次都需要调用 time.Reset()方法,此时效果类似ticker定时器。同时也可以调用stop()方法取消定时器
timer定时器比ticker定时器多一个Reset()方法,两者都有Stop()方法,表示停止定时器,底层都调用了stopTimer()函数。
原因
上面我们了介绍go的两个定时器,现在我们回到我们的问题,我们的代码使用time.After来做超时控制,time.After其实内部调用的就是timer定时器,根据timer定时器的特点,具体原因就很明显了。
这里我们的定时时间设置的是3分钟, 在for循环每次select的时候,都会实例化一个一个新的定时器。该定时器在3分钟后,才会被激活,但是激活后已经跟select无引用关系,被gc给清理掉。这里最关键的一点是在计时器触发之前,垃圾收集器不会回收 Timer,换句话说,被遗弃的time.After定时任务还是在时间堆里面,定时任务未到期之前,是不会被gc清理的,所以这就是会造成内存泄漏的原因。每次循环实例化的新定时器对象需要3分钟才会可能被GC清理掉,如果我们把上面代码中的3分钟改小点,会有所改善,但是仍存在风险,下面我们就使用正确的方法来修复这个bug。
修复bug
使用timer定时器
time.After虽然调用的是timer定时器,但是他没有使用time.Reset() 方法再次激活定时器,所以每一次都是新创建的实例,才会造成的内存泄漏,我们添加上time.Reset每次重新激活定时器,即可完成解决问题。
func (b *BrokerImpl) broadcast(msg interface{}, subscribers []chan interface{}) {
count := len(subscribers)
concurrency := 1
switch {
case count > 1000:
concurrency = 3
case count > 100:
concurrency = 2
default:
concurrency = 1
}
//采用Timer 而不是使用time.After 原因:time.After会产生内存泄漏 在计时器触发之前,垃圾回收器不会回收Timer
pub := func(start int) {
idleDuration := 5 * time.Millisecond
idleTimeout := time.NewTimer(idleDuration)
defer idleTimeout.Stop()
for j := start; j < count; j += concurrency {
if !idleTimeout.Stop(){
select {
case <- idleTimeout.C:
default:
}
}
idleTimeout.Reset(idleDuration)
select {
case subscribers[j] <- msg:
case <-idleTimeout.C:
case <-b.exit:
return
}
}
}
for i := 0; i < concurrency; i++ {
go pub(i)
}
}
复制代码
总结
不知道这篇文章你们看懂了吗?没看懂的可以下载测试代码,自己测试一下,更能加深印象的呦~~~
这篇文章主要介绍了排查问题的思路,go tool pprof这个工具很重要,遇到性能和内存gc问题,都可以使用golang tool pprof来排查分析问题。不会的小伙伴还是要学起来的呀~~~
最后感谢指出问题的那位网友,让我又有所收获,非常感谢,所以说嘛,还是要共同进步的呀,你不会的,并不代表别人不会,虚心使人进步嘛,加油各位小伙伴们~~~
作者:Golang梦工厂
链接:https://juejin.cn/post/6874561727145443335
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
框架
好像gin beego go Frame比较多?按照顺序学吧==
封装
包
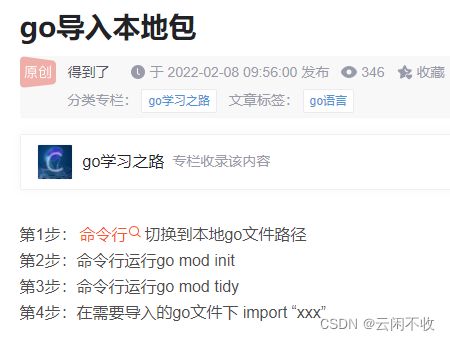
下载包,类似py的pip,官方的包管理工具
go get -u github.com/gin-gonic/gin
导入包,官方、第三方的包用全路劲,自己的项目的包用相对路径,多个的话 用括号括起来
import (
"net/http"
"github.com/gin-gonic/gin"
)
如果你的包引入了三种类型的包,标准库包,程序内部包,第三方包,建议采用如下方式进行组织你的包:
import (
"encoding/json"
"strings"
"myproject/models"
"myproject/controller"
"myproject/utils"
"github.com/astaxie/beego"
"github.com/go-sql-driver/mysql"
)
匿名导入,如果你导入了包不使用 会报错 这时可以用匿名导入,在前面加一个下划线
还可以给包起别名,甚至可以加点,直接调用函数而不加包名

三种特殊的导入
刚接触Go的时候,在看别人的项目源码时,发现在import包的包名前面有一个下划线_,产生疑问,于是搜索查阅资料。
以下示例代码在转载地址:
import (
v2 “github.com/YFJie96/wx-mall/controller/api/v2”
_ “github.com/YFJie96/wx-mall/docs”
. “fmt”
“github.com/gin-gonic/gin”
“github.com/swaggo/gin-swagger”
“github.com/swaggo/gin-swagger/swaggerFiles”
)
相关资料说明:
-
别名
v2:相当于是导入包的一个别名,可以直接使用
v2.调用包内接口或方法。 -
下划线
_:在导入路径前加入下划线表示只执行该库的 init 函数而不对其它导出对象进行真正地导入。因为 Go 语言的数据库驱动都会在 init 函数中注册自己,所以我们只需要进行上述操作即可;否则的话,Go 语言的编译器会提示导入了包却没有使用的错误。
-
点
.:点相当于把导入包的函数,同级导入到当前包,可以直接使用包内函数名进行调用
————————————————
版权声明:本文为CSDN博主「shayvmo」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/shayvmo/article/details/122496762
权限
当命名(包括常量、变量、类型、函数名、结构字段等等,不包括包)以一个大写字母开头,如:Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(客户端程序需要先导入这个包),这被称为导出(像面向对象语言中的 public);
命名如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的(像面向对象语言中的 private )
继承
构造函数 init
常用工具 代码格式化、检查、自动引入包等
gofmt 大部分的格式问题可以通过gofmt解决, gofmt 自动格式化代码,保证所有的 go 代码与官方推荐的格式保持一致,于是所有格式有关问题,都以 gofmt 的结果为准。
goimport 我们强烈建议使用 goimport ,该工具在 gofmt 的基础上增加了自动删除和引入包.
go get golang.org/x/tools/cmd/goimports
go vet vet工具可以帮我们静态分析我们的源码存在的各种问题,例如多余的代码,提前return的逻辑,struct的tag是否符合标准等。
go get golang.org/x/tools/cmd/vet
使用如下:
go vet
defer

有点像析构函数,当执行完的时候调用。更准确的说像java中的finally。
如果同时存在return 那么 return会先执行 然后defer会执行!
go modules
其实很简单 path模式是go get modules 是go install
然后go get 可以不指定目录
go install要先,指定目录go mod init 名字 然后
其实很简单 path模式是直接go get 或者go install
path可以不指定目录
module要
先指定目录
go mod init 名字()
再go get 或者install(install是安装本地包) 会直接加到gomod 和go sum
也可以手动编写
然后直接go run
或者 直接
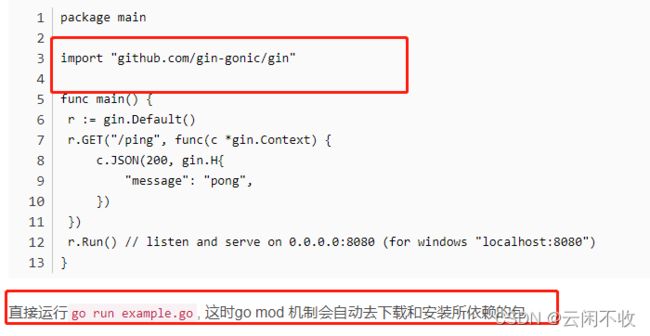
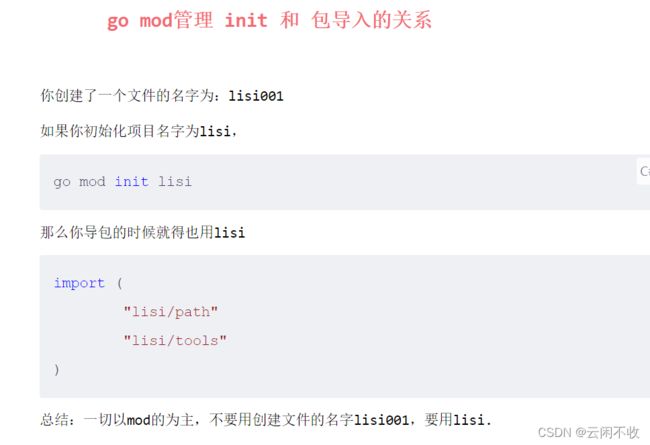

gopath下包含三个文件夹
bin是可执行二进制文件 你的go命令就是这里
pkg是加快你的编译速度的一些文件和依赖。使用 go module后 会把下载的包放这个位置
src就是你导入的包,里面有个github的文件夹
goPath模式(go get )的弊端:无法指定版本号!这样可能会导致 你把自己写的包给别人用的时候,无法保证版本一致。引入的包如果涉及依赖(引入的包也需要引入其他库),也无法保证引入的包能正常运行
也就是说所有的项目都在src下面。不同的项目都在GOPATH/src/下。很显然这种设置方法是不太方便的,因为不同项目引用的package到放到了一起,这用git管理起来很麻烦,比如A项目引用了a,b两个package,B项目引用了c,d两个package,那么如果我在A中修改了package的内容,我提交A项目时想要带着package时就很麻烦。
使用

go mod 正是为了解决上述问题(并不单单是上述问题,还有依赖引用问题)。在1.13以后开始推行。因为没多长时间,所以现在网络上的教程两种版本的都有,很容易混淆。
go mod可以完全替代GOPATH设置。只需要go env -w GO111MODULE=on开启go mod
bin/
hello # command executable
outyet # command executable
src/
myproject/server.go
进入到myproject 执行 go mod init myproject
就会创建出一个go.mod文件。在该目录下执行go mod install myproject即可生成bin文件。这样不同的项目就不要放到一起了,只需要一个gomod文件就可以管理包依赖。项目管理也会更加方便。
这也引出了为什么我在GOPATH目录下无法install,因为我在家里使用的是gomod模式。项目的路径并不是唯一的,所以他也不能在anywhere来执行go mod install myproject正如他教程原文写的:
Commands like go install apply within the context of the module containing the current working directory. If the working directory is not within the example.com/user/hello module, go install may fail.
这时你会发现如果你需要经常测试的话,需要经常在Bin和project目录来切换。官方为了解决这个问题。官方的建议是把Bin目录加到环境变量中,这样便可以在一个目录下,install && run。原文:
For convenience, go commands accept paths relative to the working directory, and default to the package in the current working directory if no other path is given. So in our working directory, the following commands are all equivalent:
$ go install example.com/user/hello
$ go install .
$ go install
Next, let’s run the program to ensure it works. For added convenience, we’ll add the install directory to our PATH to make running binaries easy:
#Windows users should consult https://github.com/golang/go/wiki/SettingGOPATH
# ]for setting %PATH%.
$ export PATH=$PATH:$(dirname $(go list -f '{{.Target}}' .))
$ hello
Hello, world.
$
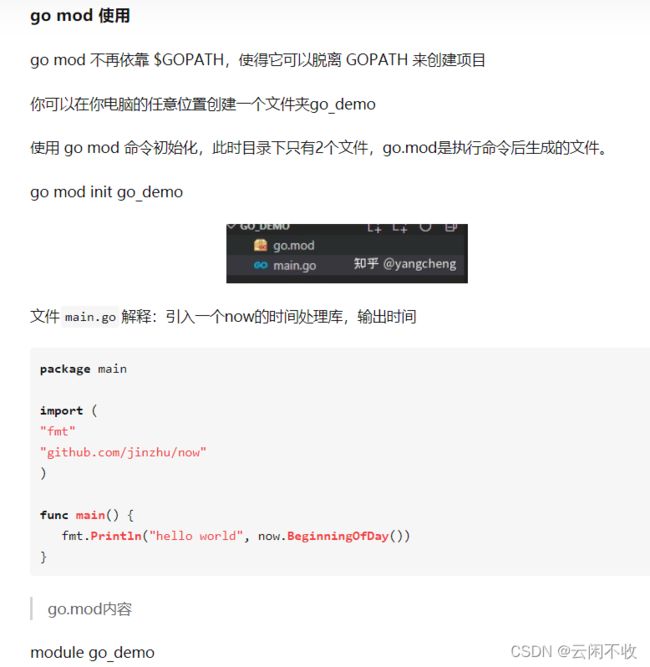
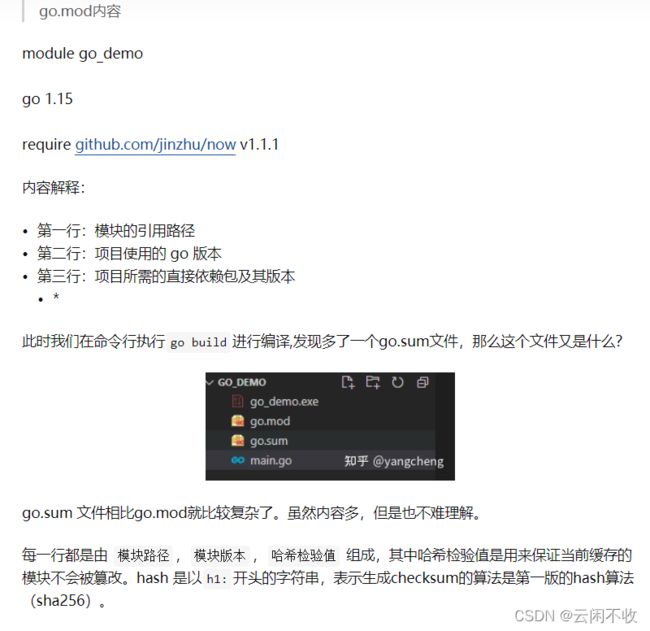
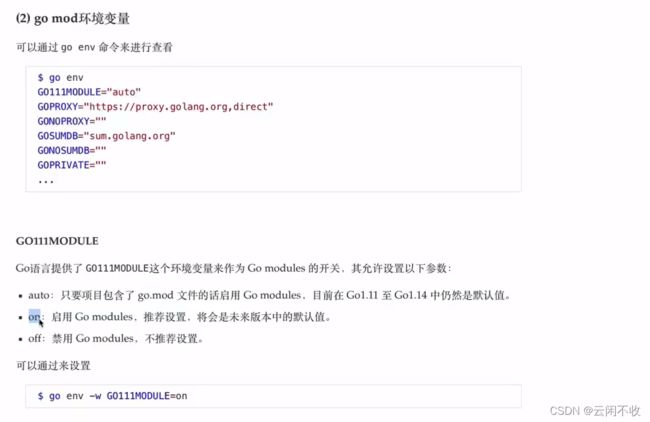
其中111是1.11版本的意思==



使用

gosum文件是保证下的包是完整的


你可能想要升级版本 或者不小心手动get 然后升级了版本,发现不好用。但是go的mod文件似乎会自动变成你新拉的。这时候你可能像变回去,两种方法
1,直接修改require
2,上面的replace语法,但是repalce其实用处是,比如你下载国外的包 很慢下不下来 可以用国内的镜像下载下来的去替代
GOLAND新建项目默认选择go module那个
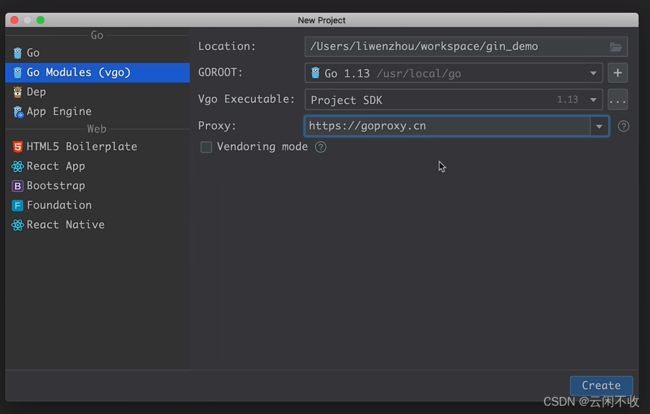
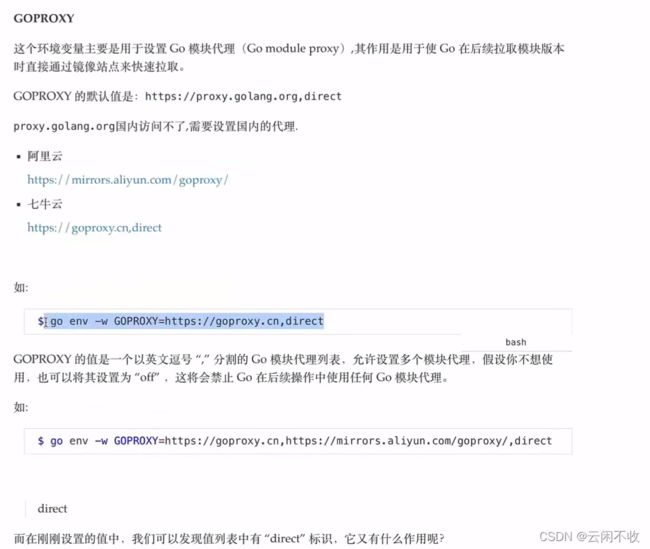
代理填这个 因为直接访问 有的访问不到
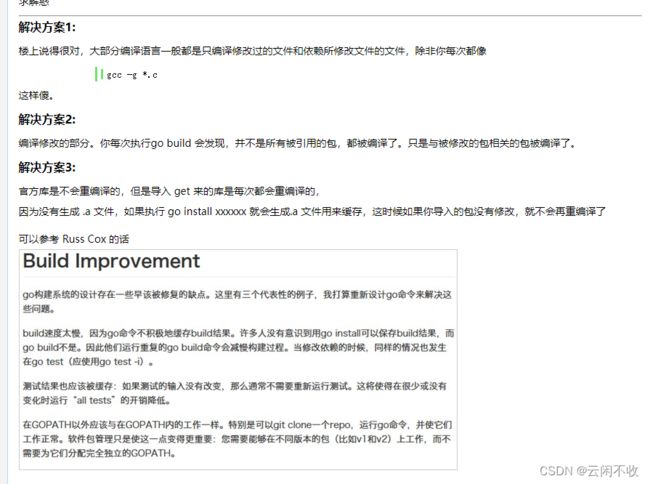
编译
详细可看
http://c.biancheng.net/view/120.html
go build -o myexec main.go lib.go
同时编译两个go文件 并且命名为mywxec
ps:1、windows使用.\可执行文件 2、名字要改成exe Linux不需要后缀名
Suggestion [3,General]: 找不到命令 server,但它确实存在于当前位置。默认情况下,Windows PowerShell 不会从当前位置加载命令。如果信任此命令,请改为键入“.\server”。有关
详细信息,请参阅 “get-help about_Command_Precedence”。
others
https://zhuanlan.zhihu.com/p/360306642
这个讲的很好

推荐
《go语言圣经》http://shouce.jb51.net/gopl-zh/index.html 讲的还行
其他以后在想分类的