利用ClickHouse进行kubernetes Ingress 日志分析
文章目录
-
-
- 前言
- Ingress日志介绍
- 为什么选择ClickHouse
- 日志数据pipeline架构
-
- ClickHouse schema 设计
- 物化视图介绍
- 日志分析
-
- 物化视图设计
- Grafana可视化
- 总结
-
前言
本篇是关于日志分析系统的一篇实践文章, 市面上大多数的做法是基于ElasticSearch的方案,ES的SQL支持不天然, 存储的膨胀,多维分析的复杂性,因此将目光投向了ClickHouse。
Ingress日志介绍
访问日志价值比较高,本次从访问日志入手。一般7层访问日志包括URL、源IP、状态码、响应时间、Agent等。kubernetes的Nginx Ingress Controller还包括namespace、service name、Ingress name等信息。日志分析需要按租户维度进行分析,因此这些字段也需要采集。自定义日志格式使用Sidecar的方式进行采集,日志格式和采集内容配置如下:
log-format upstream '{
"time":"$time_local",
"real_ip":"$the_real_ip",
"client":"$proxy_protocol_addr",
"request_id":"$req_id",
"remote_user":"$remote_user",
"bytes_sent":"$body_bytes_sent",
"request_time":"$request_time",
"status":"$status",
"vhost":"$host",
"request_length":"$request_length",
"http_referrer":"$http_referer",
"http_user_agent":"$http_user_agent",
"proxy_upstream_name":"$proxy_upstream_name",
"upstream_addr":"$upstream_addr",
"upstream_response_length":"$upstream_response_length",
"upstream_response_time":"$upstream_response_time",
"upstream_status":"$upstream_status",
"request_body":"$request_body",
"uri":"$uri",
"http_x_forwarded_for":"$http_x_forwarded_for",
"request_method":"$request_method",
"protocol":"$server_protocol"
}';
access_log logs/access.log upstream;
为什么选择ClickHouse
- 实时查询
- 分布式并行处理
- 预聚合 - 通过物化视图
- 查询速度快 - 参考 https://clickhouse.yandex/benchmark.html
- 支持SQL - 大部分场景用一个SQL就能满足
- 存储成本为ES的1/24
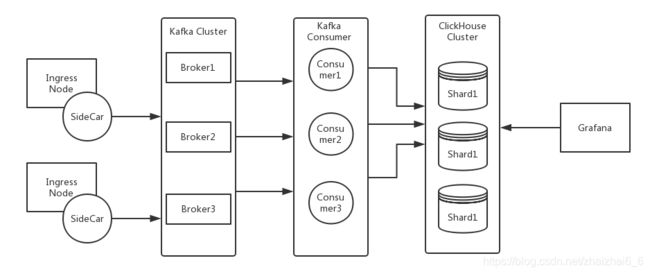
日志数据pipeline架构
架构中使用了kafka作为解耦, 采集和消费日志不依赖于各种agent和语言。同时保留后续对流数据进行清洗、加入外部字典、舆情情报的再处理能力。
ClickHouse schema 设计
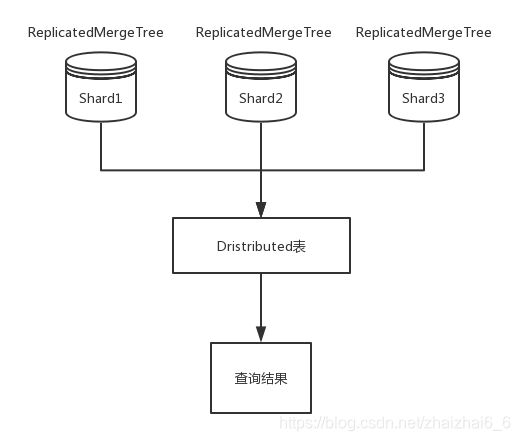
数据摄入的基表使用了ReplicatedMergeTree,Clickhouse最健壮的 *MergeTree引擎系列,同时使用Relicated数据复制,增强数据的可靠性。数据总是批量写入,8192或以上的颗粒度。
物化视图介绍
物化视图是Clickhouse的内部pipeline,根据原始数据表数据流的摄入进行各种聚合运算,聚合运算的结果写入对应物化视图。各种数据统计的压力在用户查询之前就已完成,极大减少查询耗时。以下进行查询耗时比较,可以看出物化视图极大减少了查询耗时。
物化视图如下:
CREATE MATERIALIZED VIEW k8s.INGRESS_PV_hour (
date Date,
t DateTime,
namespace String,
total UInt64
) ENGINE = ReplicatedSummingMergeTree(
'/clickhouse/tables/{layer}-{shard}/k8s/ingress_pv_hour','{replica}'
) PARTITION BY toYYYYMM(date)
ORDER BY
(t, namespace) SETTINGS index_granularity = 8192 AS
SELECT
date,
toStartOfHour(time) AS t,
namespace,
count(*) AS total
FROM
k8s.ingressjq_prd_dist
GROUP BY
date,
t,
namespace
先对原始数据表进行查询,耗时:0.45 sec.| 128,329,684 rows.| 2 GB
SELECT
date,
namespace,
count(*) AS total
FROM
k8s.ingressjq_prd_dist where date > toDate('2019-06-14') group by date,namespace order by date,namespace limit 5000
对物化视图进行查询 (预聚合结果),耗时:0.01 sec.| 9,785 rows.| 258 KB
SELECT
date,
namespace,
sum(total) AS total
FROM
k8s.INGRESS_PV_DAY where date > toDate('2019-06-14') group by date,namespace order by date,namespace limit 5000
日志分析
物化视图主要分为三个时间跨度:分钟,小时和天,聚合引擎主要用到:SummingMergeTree 和AggregatingMergeTree。
物化视图设计
-
访问量

-
速度

-
HTTP状态和方法
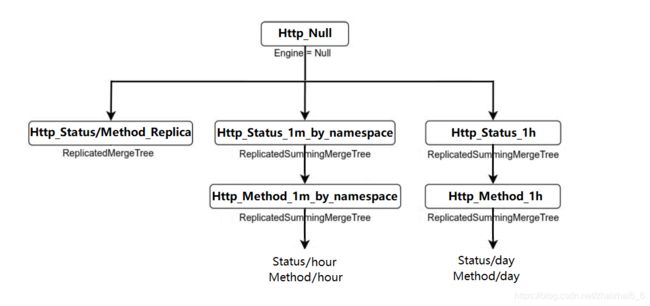
-
访问来源
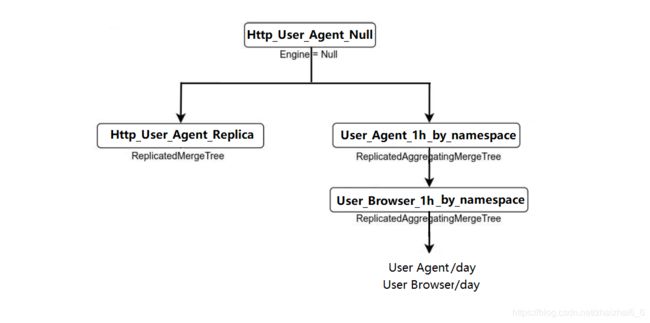
Grafana可视化
最后,在Grafana里通过SQL语句查询相应的物化视图,利用折线图,饼图,列表等不同的方式进行数据展现。
Grafana dashboard 分为两个部分,第一部分分应用展示实时数据如下:
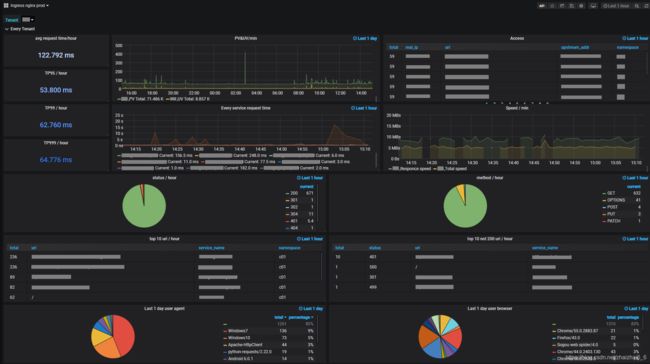
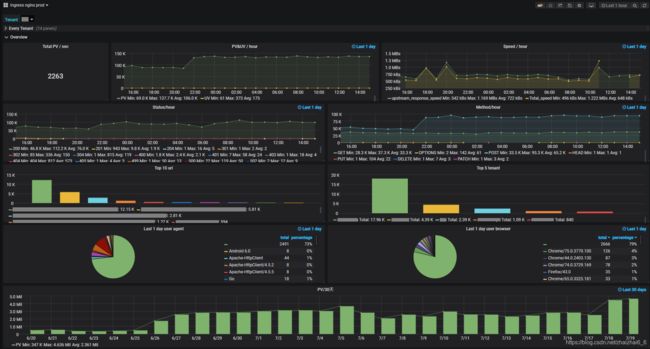
第二部分展示所有应用总的实时数据如下:
总结
ClickHouse是强大的列式数据库,可以用在基于时间序列的metrics,logging的数据分析。Schema需要预先建立,因此后续使用ClickHouse仍需继续开发对应抽象接口,以完成业务的灵活对接。