Linux源码剖析机构,Linux内存管理源码剖析(一)
本篇为基础,讲解内存管理部分的基本原理与进程虚拟空间布局
文章目录
1.独占空间的原理
2.虚拟内存的划分方式
3.Linux虚拟地址与物理地址的转换
4.从mm_struct结构开始讨论进程虚拟空间布局
(1)用户态空间的布局
(2)内核态空间的布局
5.sys_brk系统调用源码剖析
1.独占空间的原理
对于每一个进程都应该有自己看起来独占的内存空间,以实现不同进程之间的隔离,保证安全性。而之所以提出这种巧妙的机制是为了解决无法直接使用物理内存地址的问题。因为考虑到机器多为多进程多任务的运行机制,当多个进程若同时使用相同的物理内存地址,此时显然会产生错误的结果。故需要设计使用虚拟地址,建立虚拟地址与物理地址之间的映射关系,然后使用时由内核数据结构负责为虚拟地址找到合适的物理内存将数据写入进去。
2.虚拟内存的划分方式
32bit机器会有232=4G的虚拟空间,64bit机器(只使用48bit寻址)会有248=256TB的虚拟空间,将这些虚拟空间会按照某种方式划分为两部分,一部分用来存放内核东西叫做内核空间,另一部分用于存放当前进程的东西叫做用户空间,具体划分方式以后讨论。
用户空间的内容划分: 从下到上依次是代码段,数据段(放静态常量),附加段(放未初始化的静态变量),堆,内存映射取,栈。用户若需要访问内核空间就需要调用系统调用陷入内核。和用户空间不同的是,在用户空间每个进程都要自己的用户空间,但进入内核之后却是同一个内核空间,不过每个内核空间都有自己的栈空间,所以在内核里面若要访问公共资源才需要使用锁保护。
注意:可以使用pmap $(pid)或者cat /proc/$(pid)/maps查看Linux系统上某一个进程(pid)的内存空间布局
3.Linux虚拟地址与物理地址的转换
需要注意的是,虽然在地址转换上有分段机制这种操作可以实现地址转换,但Linux并不依靠分段机制,它仅仅只是利用段选择子中的特权标记来区分访问权限。Linux更倾向于使用页表机制来进行虚实地址的转换。
32bit的Linux虚拟地址的构成(两级目录)
页目录项
页表项
页内偏移
10bits
10bits
12bits
64bit的Linux虚拟地址的构成(四级目录)
1
2
3
4
5
全局页目录项PGD
上层页目录项PUD
中间页目录项PMD
页表项PTE
页内偏移地址
4.从mm_struct结构开始讨论进程虚拟空间布局
在每个进程的task_struct结构体中有一个成员变量mm_struct用来管理内存:
struct mm_struct *mm;
该结构体里面有许多成员变量,如其中一个成员变量task_size就是用来划分虚拟内存的用户空间与内核空间的变量。系统空间布局如下图所示:
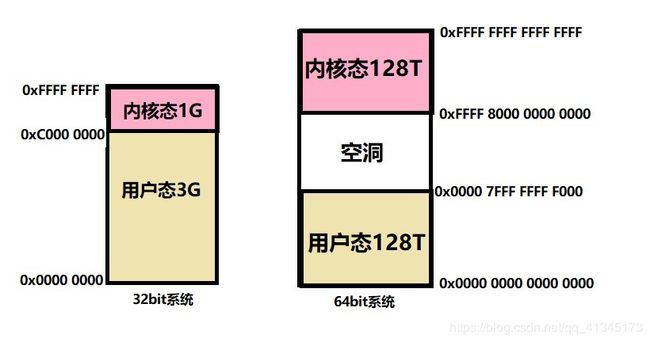
(1)用户态空间的布局
下面来看一看和用户态相关的部分mm_struct成员数据结构的内核定义:
//linux-4.13.16\include\linux\mm_types.h
struct mm_struct {
struct vm_area_struct *mmap;/* 虚拟空间中各个分区构成链表的链表头 */
struct rb_root mm_rb;
...
unsigned long mmap_base;/*表示VA空间中用于内存映射的起始位置*/
...
unsigned long task_size;/* 用户空间与内核空间的分界线 */
...
unsigned long total_vm;/* 总共映射的页的数目 */
unsigned long locked_vm;/* 不能被系统调度换出内存的页面 */
unsigned long pinned_vm;/* 既不能被换出也不能被移到 */
unsigned long data_vm;/* 存放数据的页的数目 */
unsigned long exec_vm;/* 存放可执行文件的数目 */
unsigned long stack_vm;/* 栈所占页的数目 */
unsigned long def_flags;
unsigned long start_code, end_code, start_data, end_data;/*可执行代码开始和结束
的位置,已初始化数据的开始位置和结束位置。*/
unsigned long start_brk, brk, start_stack;/*start_brk指堆的开始位置,brk指目前堆
的结束位置,start_stack指栈的起始位置,栈的终止位置则是在堆栈指针寄存器sp中*/
unsigned long arg_start, arg_end, env_start, env_end;/*分别表示参数列表
和环境变量的位置,他们都在用户栈的最高地址处*/
通过上面的这段代码可以方便的找到我们常常所说的堆,栈,代码段,数据段等的范围定义等等,其实对于他们每一个分段区域我们都有一个对应的结构体struct vm_area_struct,如对于堆区有一个实例化的结构体,对于栈区也有一个等,他们会组合成为一个单链表,起始就是上面的struct vm_area_struct *mmap成员,下面详细看一看这个结构体:
struct vm_area_struct {//linux-4.13.16\include\linux\mm_types.h
unsigned long vm_start;/* 该块区域在用户空间的起始位置,需要注意的是此处是虚拟地址*/
unsigned long vm_end;/* 该块区域在用户空间的结束位置 */
struct vm_area_struct *vm_next, *vm_prev;/*和进程内象征其他内存块的同类结构体相链接的两个指针*/
struct rb_node vm_rb;//将该结构放在上面的红黑树上的指针变量*/
struct anon_vma *anon_vma;/*该内存区域映射到物理内存的指针 */
const struct vm_operations_struct *vm_ops;/*对该内存区域可以进行的操作*/
struct file * vm_file;/* File we map to (can be NULL). */
看起来了解到这儿就可以了哩,但还需要注意的一点是何时OS为每个进程设计并且初始化了这些vm_area_struct结构体哩,我们直到运行一个进程需要加载ELF文件的各个数据段、代码段等最终调用exec函数,其实同时他还会负责建立内存映射初始化我们上面提到的多个vm_area_struct结构体。这些都是在load_elf_binary函数里面实现的。至此用户态空间解析可以告一段落了。
(2)内核态空间的布局
先瞅一瞅内核态的基本布局与实现图示

如上图所示内核布局需要重点关注直接映射区这896M的直接映射区,其特别重要,特别重要的数据结构,如各个进程的task_struct结构体、进程内核栈的分配等都是在这896M的空间内分配的。而且这896M的空间会直接映射到实际物理内存的前896M,并且将物理内存896M以上的空间叫做高端内存,也就是说剩下的128M的线性空间用来映射剩下的大于896M的物理地址空间,这也就是我们通常说的高端内存区。
我们把vmalloc区叫内核动态映射区,就像用户态进程可以使用malloc一样,内核可以使用vmalloc函数在这个区域映射物理内存。
持久映射区可以用于映射页表等不经常发生变动的数据结构。
固定映射区用于满足特殊需要
最上面空白部分用于临时内核映射,如将文件向用户态映射的时候,需要内核协助(因为有IO),故需要一段映射区用于中转到用户映射好的物理内存,使用完毕释放即可。
以上就是个人对于内核布局的粗浅理解。。。
5.sys_brk系统调用源码剖析
经常可以听到malloc分配内存在堆上分配,现在我们已经解开了堆、栈等各个内存区域布局的神秘面纱,也明白了为什么堆上的内存不像栈上一样自动释放,说白了就是更新方式不一样罢了。至此,我们也清楚知道了当使用malloc申请少量空间的时候会在底层调用brk函数,否则会调用mmap进行在内存映射区映射一片区域到物理内存,今天来瞧一瞧brk的系统调用是啥样子的?
SYSCALL_DEFINE1(brk, unsigned long, brk)
{//linux-4.13.16\mm\mmap.c
unsigned long retval;
unsigned long newbrk, oldbrk;
struct mm_struct *mm = current->mm;
struct vm_area_struct *next;
... /*省略部分会进行一些数据参数验证,确保brk输入值合法*/
newbrk = PAGE_ALIGN(brk); //对新的brk进行页对齐
oldbrk = PAGE_ALIGN(mm->brk); //对旧的brk进行页对齐
if (oldbrk == newbrk)
goto set_brk;//此时说明新的指针仍旧和旧的brk在同一个页上,直接调整就好*/
/* Always allow shrinking brk. */
if (brk <= mm->brk) {/*这时是释放内存,do_munmap*/
if (!do_munmap(mm, newbrk, oldbrk-newbrk, &uf))
goto set_brk;
goto out;
}
next = find_vma(mm, oldbrk);//若到这儿说明是扩大内存,而且不算太小
if (next && newbrk + PAGE_SIZE > vm_start_gap(next))//vm_start_gap返回下一个区的开始地址
goto out;/*其实就是计算堆和内存映射区之间是否可以在分配一个页,若不行则说明
申请空间太大了,就失败返回了,若可以申请则调用下面的do_brk函数*/
if (do_brk(oldbrk, newbrk-oldbrk, &uf) < 0)
goto out;
set_brk://设置新的mm->brk值
mm->brk = brk;
...
return brk;
out:
retval = mm->brk;
up_write(&mm->mmap_sem);
return retval;
}
这个do_brk函数主要负责分配计算出来的新旧堆顶之间相差的页数,do_fork会调用do_brk_flags函数:return do_brk_flags(addr, len, 0, uf);
static int do_brk_flags(unsigned long addr, unsigned long request, unsigned long flags, struct list_head *uf)
{//linux-4.13.16\mm\mmap.c
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
unsigned long len;
struct rb_node **rb_link, *rb_parent;
pgoff_t pgoff = addr >> PAGE_SHIFT;
int error;
len = PAGE_ALIGN(request); //对齐为页面数
...
while (find_vma_links(mm, addr, addr + len, &prev, &rb_link,
&rb_parent)) {
if (do_munmap(mm, addr, len, uf))
return -ENOMEM; //看有空间吗?
}
...
/* Can we just expand an old private anonymous mapping? */
vma = vma_merge(mm, prev, addr, addr + len, flags,
NULL, NULL, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;//合并成功了...
/*
* create a vma struct for an anonymous mapping
*/
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) { //创建 vm_area_struct
vm_unacct_memory(len >> PAGE_SHIFT);
return -ENOMEM;
}
INIT_LIST_HEAD(&vma->anon_vma_chain);
。。。
out:
perf_event_mmap(vma);
。。。
return 0;
}
没吃得太透,大致流程就是,先调用sys_brk函数检查是否有地方去映射需求的内存,若有就调用do_brk函数分配内存并更新 vm_area_struct结构的成员的值。