Spark-sql离线抽取全量数据到hive分区表中
先建立spark连接
val spark: SparkSession = SparkSession
.builder()
.appName("test")
.master("local[*])
.enableHiveSupport()
.getOrCreate()控制日期格式并获取当前日期(这里做了-1)
val dateStr = new SimpleDateFormat("yyyyMMdd")
val calendar = Calendar.getInstance()
calendar.add(Calendar.DATE, -1)
var dateFormat = dateStr.format(calendar.getTime)创建存放待抽取表名的数组
val tableArray = Array("customer", "lineitem", "nation", "orders", "part", "partsupp", "region", "supplier")创建存放sql连接信息的Properties变量
val temp = new Properties()
temp.put("user", "root")
temp.put("password", "123456")
temp.put("driver", "com.mysql.jdbc.Driver")遍历tableArray
tableArray.foreach(x=> {
spark.read.jdbc("jdbc:mysql://127.0.0.1:3306/shtd_store", x.toUpperCase(), temp).createOrReplaceTempView(x)
spark.sql(
s"""
insert overwrite table ods.${x} partition (etldate=${dateFormat})
select * from ${x}
""")
})spark-submit执行
[root@master ~]# spark-submit --master spark://127.0.0.1:7077 --name sparkODextraction.SparkODSalldateExtract --class sparkODextraction.SparkODSalldateExtract projects.jar最后到hive里面或者用hdfs查看partitions情况
hive>show partitions ods.customer;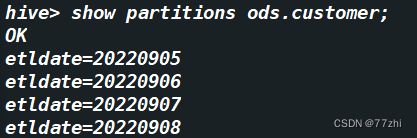
核心代码
tableArray.foreach(x=> {
spark.read.jdbc("jdbc:mysql://127.0.0.1:3306/shtd_store", x.toUpperCase(), temp).createOrReplaceTempView(x)
spark.sql(
s"""
insert overwrite table ods.${x} partition (etldate=${dateFormat})
select * from ${x}
""")
})每次遍历传入使用x接收该表表名,并创建一个临时表x
spark.sql(s"""
insert overwrite table ods.${x} partition (etldate=${dateFormat})
select * from ${x}
""")这里第一个x代表的是x遍历当前存放的表名,第二个x是读取临时表x中的数据
完整代码
package sparkODextraction
import java.text.SimpleDateFormat
import java.util.{Calendar, Properties}
import org.apache.spark.sql.SparkSession
object SparkODSalldateExtract {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.appName("test")
.master("local[*]")
.enableHiveSupport()
.getOrCreate()
val dateStr = new SimpleDateFormat("yyyyMMdd")
val calendar = Calendar.getInstance()
calendar.add(Calendar.DATE, -1)
var dateFormat = dateStr.format(calendar.getTime)
val tableArray = Array("customer", "lineitem", "nation", "orders", "part", "partsupp", "region", "supplier")
val temp = new Properties()
temp.put("user", "root")
temp.put("password", "123456")
temp.put("driver", "com.mysql.jdbc.Driver")
tableArray.foreach(x=> {
spark.read.jdbc("jdbc:mysql://127.0.0.1:3306/shtd_store", x.toUpperCase(), temp).createOrReplaceTempView(x)
spark.sql(
s"""
insert overwrite table ods.${x} partition (etldate=${dateFormat})
select * from ${x}
""")
})
}
}