pyspark案例系列5-Spark ETL将MySQL数据同步到Hive
文章目录
- 一. 需求
- 二. 解决方案
-
- 2.1 全量同步
- 2.2 增量同步
备注:
Spark 2.4.0
一. 需求
最近做数据仓库项目的时候,觉得sqoop有点慢,然后想尝试使用Spark来做ETL。
二. 解决方案
ODS层:
Spark可以从MySQL等数据源读取数据,然后写入到Hive中,所以用Spark来做ETL也是没太大问题的。
数仓其它层:
Spark可以通过Spark SQL直接运行hive的sql语句,所以用Spark来做ETL也是没太大问题的。
我们这边来模拟几个例子:
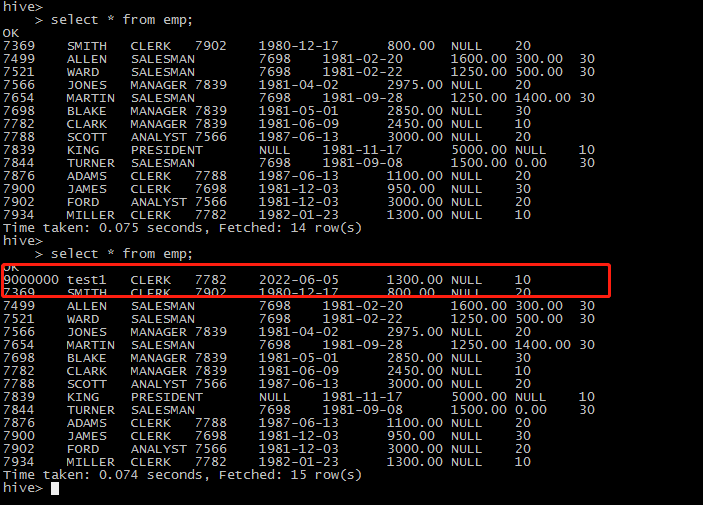
将mysql下的emp表同步到hive中
hive需提前创建好emp表的表结构。
2.1 全量同步
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
from pyspark.sql import SQLContext
# 创建一个连接
spark = SparkSession. \
Builder(). \
appName('local'). \
master('local'). \
getOrCreate()
df1=spark.read.format("jdbc").options(url="jdbc:mysql://10.31.1.123:3306/test", \
driver="com.mysql.jdbc.Driver", \
dbtable="(SELECT * FROM EMP) tmp", \
user="root", \
password="abc123").load()
df1.registerTempTable('emp_mysql')
spark.sql("use test")
df2 = spark.sql("select e1.empno,e1.ename,e1.job,e1.mgr,e1.hiredate,e1.sal,e1.comm,e1.deptno from emp_mysql e1 left join emp e2 on e1.empno = e2.empno where e2.empno is null")
df2.registerTempTable('emp_incre')
spark.sql("insert into emp select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp_incre")
# 关闭spark会话
spark.stop()
数据验证:
2.2 增量同步
我们演练的增量同步以一个时间字段为例
例如上例中的hiredate
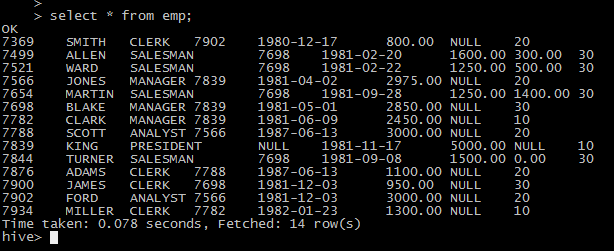
准备增量数据:
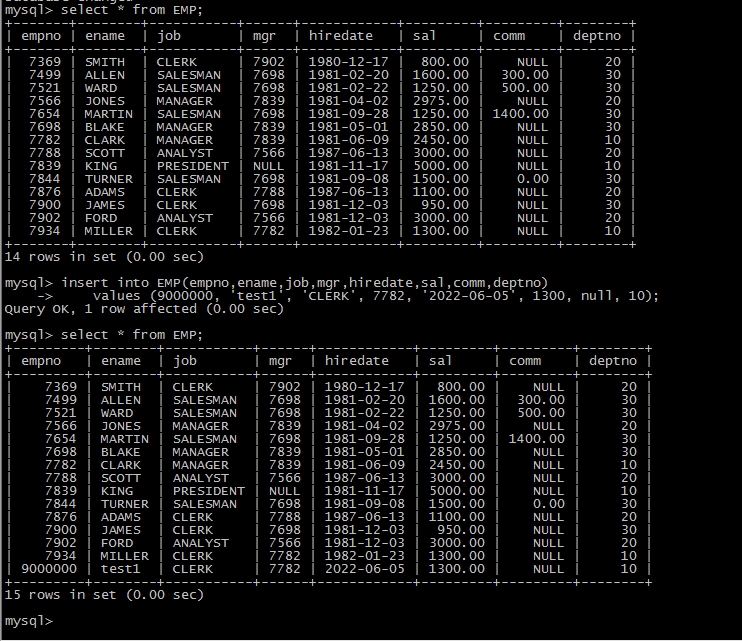
insert into EMP(empno,ename,job,mgr,hiredate,sal,comm,deptno)
values (9000000, 'test1', 'CLERK', 7782, '2022-06-05', 1300, null, 10);
Spark代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
from pyspark.sql import SQLContext
# 创建一个连接
spark = SparkSession. \
Builder(). \
appName('local'). \
master('local'). \
getOrCreate()
df1=spark.read.format("jdbc").options(url="jdbc:mysql://10.31.1.123:3306/test",
driver="com.mysql.jdbc.Driver",
dbtable="(select * from EMP where hiredate >= '2022-06-05') tmp",
user="root",
password="abc123").load()
df1.registerTempTable('emp_mysql')
spark.sql("use test")
spark.sql("insert into emp select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp_mysql")
# 关闭spark会话
spark.stop()
数据验证: