GreenPlum数据库调研及架构介绍
简介
http://docs-cn.greenplum.org/v6/admin_guide/intro/arch_overview.html
Greenplum数据库是一种大规模并行处理(MPP)数据库服务器,其架构特别针对管理大规模分析型数据仓库以及商业智能工作负载而设计。
Greenplum数据库是基于PostgreSQL开源技术的。它本质上是多个PostgreSQL面向磁盘的数据库实例一起工作形成的一个紧密结合的数据库管理系统(DBMS)。其SQL支持、特性、配置选项和最终用户功能在大部分情况下和PostgreSQL非常相似。 与Greenplum数据库交互的数据库用户会感觉在使用一个常规的PostgreSQL DBMS。
Greenplum数据库和PostgreSQL的主要区别在于:
- 在基于Postgres查询规划器的常规查询规划器之外,可以利用GPORCA进行查询规划。
- Greenplum数据库可以使用追加优化的存储。
- Greenplum数据库可以选用列式存储,数据在逻辑上还是组织成一个表,但其中的行和列在物理上是存储在一种面向列的格式中,而不是存储成行。 列式存储只能和追加优化表一起使用。列式存储是可压缩的。当用户只需要返回感兴趣的列时,列式存储可以提供更好的性能。 所有的压缩算法都可以用在行式或者列式存储的表上,但是行程编码(RLE)压缩只能用于列式存储的表。Greenplum数据库在所有使用列式存储的追加优化表上都提供了压缩。
Greenplum数据库也包括为针对商业智能(BI)负载优化PostgreSQL而设计的特性。 例如,Greenplum增加了并行数据装载(外部表)、资源管理、查询优化以及存储增强,这些在PostgreSQL中都是无法找到的。 很多Greenplum开发的特性和优化都在PostgreSQL社区中找到了一席之地。例如,表分区最初是由Greenplum开发的一个特性,现在已经出现在了标准的PostgreSQL中。
整体类别
计算
计算+接口
计算+存储+接口
存储
http://docs-cn.greenplum.org/v6/admin_guide/intro/arch_overview.html
Greenplum数据库可以使用追加优化(append-optimized,AO)的存储格式来批量装载和读取数据,并且能提供HEAP表上的性能优势。 追加优化的存储为数据保护、压缩和行/列方向提供了校验和。行式或者列式追加优化的表都可以被压缩。
Greenplum数据库支持多种存储模型和一种混合存储模型。 当用户创建一个表时,用户会选择如何存储它的数据。
堆存储
默认情况下,Greenplum数据库使用和PostgreSQL相同的堆存储模型。 堆表存储在OLTP类型负载下表现最好,这种环境中数据会在初始载入后被频繁地修改。 UPDATE和DELETE操作要求存储行级版本信息来确保可靠的数据库事务处理。 堆表最适合于较小的表,例如维度表,它们在初始载入数据后会经常被更新。
追加优化存储(AO表)
追加优化表存储在数据仓库环境中的非规范表表现最好。 非规范表通常是系统中最大的表。 事实表通常成批地被载入并且被只读查询访问。 将大型的事实表改为追加优化存储模型可以消除每行中的更新可见性信息负担,这可以为每一行节约大概20字节。 这可以得到一种更加简洁并且更容易优化的页面结构。 追加优化表的存储模型是为批量数据装载优化的,因此不推荐单行的INSERT语句。
选择面向行或者面向列的存储
Greenplum提供面向存储的模型选择:行,列或两者的组合。
- 面向行的存储:适用于具有许多迭代事务的OLTP类型的工作负载以及一次需要多列的单行,因此检索是高效的。
- 面向列的存储:适合于在少量列上计算数据聚集的数据仓库负载,或者是用于需要对单列定期更新但不修改其他列数据的情况。
对于大部分常用目的或者混合负载,面向行的存储提供了灵活性和性能的最佳组合。 不过,也有场景中面向列的存储模型提供了更高效的I/O和存储。 在为一个表决定存储方向模型时,请考虑下列需求:
- 表数据的更新。如果用户会频繁地装载和更新表数据,请选择一个面向行的堆表。 面向列的表存储只能用于追加优化表。
- 频繁的插入。如果频繁地向表中插入行,请考虑面向行的模型。 列存表并未对写操作优化,因为一行的列值必须被写到磁盘上的不同位置。
- 查询中要求的列数。如果在查询的SELECT列表或者WHERE子句中常常要求所有或者大部分列,请考虑面向行的模型。 面向列的表最适合的情况是,查询会聚集一个单一列中的很多值且WHERE或者HAVING谓词也在该聚集列上。
- 表中的列数。在同时要求很多列或者表的行尺寸相对较小时,面向行的存储会更有效。 对于具有很多列的表且查询中访问这些列的一个小子集时,面向列的表能够提供更好的查询性能。
- 压缩。列数据具有相同的数据类型,因此在列存数据上支持存储尺寸优化,但在行存数据上则不支持。 例如,很多压缩方案使用临近数据的相似性来进行压缩。 不过,临近压缩做得越好,随机访问就会越困难,因为必须解压数据才能读取它们。
对于追加优化表,在Greenplum数据库中有两种类型的库内压缩可用:
- 应用于一整个表的表级压缩。
- 应用到一个指定列的列级压缩。用户可以为不同的列应用不同的列级压缩算法。
下面的表总结了可用的压缩算法。
| 表方向 | 可用的压缩类型 | 支持的算法 |
|---|---|---|
| 行 | 表 | ZLIB, ZSTD和 QUICKLZ1 |
| 列 | 列和表 | RLE_TYPE, ZLIB, ZSTD和 QUICKLZ1 |
Note: 1QuickLZ压缩在Greenplum数据库的开源版本中不可用。
在为追加优化表选择一种压缩类型和级别时,要考虑这些因素:
- CPU使用。
- 压缩率/磁盘尺寸。
- 压缩的速度。
- 解压速度/扫描率。
https://zhuanlan.zhihu.com/p/100703300?utm_source=wechat_session
外部表:外部表的数据存储在外部(数据不被Greenplum管理),Greenplum 中只有外部表的元数据信息。Greenplum 支持很多外部数据源譬如 S3、HDFS、文件、Gemfire、各种关系数据库等和多种数据格式譬如 Text、CSV、Avro、Parquet 等。
存储引擎
没有找到具体是用什么数据结构,不过压缩、分区、索引都是有的
平台管理
架构
Greenplum数据库的查询使用一种火山式查询引擎模型,其中的执行引擎拿到一个执行计划并且用它产生一棵物理操作符树,然后通过物理操作符计算表,最后返回结果作为查询响应。
Greenplum数据库通过将数据和处理负载分布在多个服务器或者主机上来存储和处理大量的数据。 Greenplum数据库是一个由基于PostgreSQL 9.4的数据库组成的阵列,阵列中的数据库工作在一起呈现了一个单一数据库的景象。 Master是Greenplum数据库系统的入口。客户端会连接到这个数据库实例并且提交SQL语句。 Master会协调与系统中其他称为Segment的数据库实例一起工作,Segment负责存储和处理数据。
Figure 1. 高层的Greenplum数据库架构
关于Greenplum的Master
Greenplum数据库的Master是整个Greenplum数据库系统的入口,它接受连接和SQL查询并且把工作分布到Segment实例上。Greenplum数据库的最终用户与Greenplum数据库(通过Master)交互时,会觉得他们是在与一个典型的PostgreSQL数据库交互。
Master是全局系统目录的所在地。全局系统目录是一组包含了有关Greenplum数据库系统本身的元数据的系统表。 Master上不包含任何用户数据,数据只存在于Segment之上。 Master会认证客户端连接、处理到来的SQL命令、在Segment之间分布工作负载、协调每一个Segment返回的结果以及把最终结果呈现给客户端程序。
Greenplum数据库使用预写式日志(WAL)来实现主/备镜像。 在基于WAL的日志中,所有的修改都会在应用之前被写入日志,以确保对于任何正在处理的操作的数据完整性。
关于Greenplum的Segment
Greenplum数据库的Segment实例是独立的PostgreSQL数据库,每一个都存储了数据的一部分并且执行查询处理的主要部分。
当一个用户通过Greenplum的Master连接到数据库并且发出一个查询时,在每一个Segment数据库上都会创建一些进程来处理该查询的工作。
Segment运行在被称作Segment主机的服务器上。 一台Segment主机通常运行2至8个Greenplum的Segment,这取决于CPU核数、RAM、存储、网络接口和工作负载。Segment运行在被称作Segment主机的服务器上。 一台Segment主机通常运行2至8个Greenplum的Segment,这取决于CPU核数、RAM、存储、网络接口和工作负载。
关于Greenplum的Interconnect
Interconect是Greenplum数据库架构中的网络层。
Interconnect指的是Segment之间的进程间通信以及这种通信所依赖的网络基础设施。 Greenplum的Interconnect采用了一种标准的以太交换网络。出于性能原因,推荐使用万兆网或者更快的系统。
默认情况下,Interconnect使用带流控制的用户数据包协议(UDPIFC)在网络上发送消息。 Greenplum软件在UDP之上执行包验证。这意味着其可靠性等效于传输控制协议(TCP)且性能和可扩展性要超过TCP。 如果Interconnect被改为TCP,Greenplum数据库会有1000个Segment实例的可扩展性限制。对于Interconnect的默认协议UDPIFC则不存在这种限制。
关于表分区
http://docs-cn.greenplum.org/v6/admin_guide/ddl/ddl-partition.html
分区并不会改变表数据在Segment之间的物理分布。 表分布是物理的:Greenplum数据库会在物理上把分区表和未分区表划分到多个Segment上来启用并行查询处理。 表分区是逻辑的:Greenplum数据库在逻辑上划分大表来提升查询性能并且有利于数据仓库维护任务。
Greenplum数据库支持:
- 范围分区:基于一个数字型范围划分数据,例如按照日期或价格划分。
- 列表分区:基于一个值列表划分数据,例如按照销售范围或产品线划分。
- 两种类型的组合。
关于数据分布策略
Greenplum 6 提供了以下数据分布策略。
- 哈希分布
- 随机分布
- 复制表(Replicated Table)(整张表在每个节点上都有一个完整的拷贝,就是citus广播表)
部署
安装
http://docs.greenplum.org/6-10/install_guide/install_gpdb.html
没有自动化安装,需要手动配置集群的各个选项
文档
http://docs.greenplum.org/6-10/install_guide/install_gpdb.html
有比较全面的安装和运维文档
升级
如果是6.x可以使用工具升级到最新,如果是更老的版本,需要使用数据迁移
高可用
http://docs-cn.greenplum.org/v6/admin_guide/highavail/topics/g-overview-of-high-availability-in-greenplum-database.html
Greenplum数据库系统的高可用可以通过提供容错硬件平台实现,可以通过启用Greenplum数据库高可用特性实现, 也可以通过执行定期监控和运维作业来确保整个系统所有组件保持健康来实现。
硬件平台的最终故障,可能因为常见的持久运行故障或非预期的运行环境。异常断电会导致组件临时不可用。系统可以通过为可能故障的节点配置冗余备份节点,以此来保证异常出现时仍能够不间断提供服务。在一些情况下,系统冗余的成本高于 用户的服务终端容忍度。此时,高可用的目标可以改为确保服务能在预期的时间内恢复。
Greenplum数据库的容错和高可用通过以下几种方式实现:
硬件级别RAID
Greenplum数据库部署最佳实践是采用硬件级别的RAID为单盘失败的情况提供高性能的磁盘冗余,避免只采用 数据库级别的容错机制。该方式可以在磁盘级别提供低级别的冗余保护。
数据存储总和校验
Greenplum数据库采用总和校验机制在文件系统上验证从磁盘加载到内存的数据没有被破坏。
Greenplum数据库有两种存储用户数据的方式:堆表和追加优化表。两种存储模型均采用总和校验机制 验证从文件系统读取的数据,默认配置下,二者采用总和校验机制验证错误的方式基本类似。
Greenplum数据库master和segment实例在他们所管理的自有内存中更新页上的数据。当内存页被更新 并刷新到磁盘时,会执行总和校验并保存起来。当下次该页数据从磁盘读取时,先进行总和校验,只有成功 通过验证的数据才能进入管理内存。如果总和校验失败,就意味着文件系统有损坏等情况发生,此时Greenplum 数据库会生成错误并中断该事务。
Segment镜像
Greenplum数据库将数据存储在多个segment实例中,每一个实例都是Greenplum数据库的一个PostgreSQL实例, 数据依据建表语句中定义的分布策略在segment节点中分布。启用segment镜像时,每个segment实例都由一对 primary和mirror组成。镜像segment采用基于预写日志(WAL)流复制的方式保持与主segment 的数据一致。
Master镜像
在一个高可用集群中,有两种master实例,primary和standby。像segment一样,master和standby 应该部署在不同的主机上,以保证集群不出现单节点故障问题。客户端只能连接到primary master并在上面执行查询。 standby master采用基于预写日志(WAL)流复制的方式保持与primary master的数据一致。
双集群
可以通过维护两套Greenplum数据库集群,都存储相同的数据来提供额外的冗余。
备份和恢复
建议经常备份数据库,可以保证一旦出现问题可以很容易的重新生成数据库集群。备份可以很好的保护 误操作、软件错误和硬件错误。
监控和管控
http://docs-cn.greenplum.org/v6/admin_guide/intro/about_utilities.html
Greenplum数据库提供了标准的命令行工具来执行通常的监控和管理任务。
Greenplum的命令行工具位于 $GPHOME/bin目录中并且在Master主机上执行。Greenplum为下列管理任务提供了实用工具:
管控方面:
- 在一个阵列上安装Greenplum数据库
- 初始化一个Greenplum数据库系统
- 开始和停止Greenplum数据库
- 增加或者移除一个主机
- 扩展阵列并且在新的Segment上重新分布表
- 恢复失效的Segment实例
- 管理失效Master实例的故障切换和恢复
- 备份和恢复一个数据库(并行)
- 并行装载数据
- 在Greenplum数据库之间转移数据
监控方面:
- 系统状态报告
- Greenplum数据库包括一个包含查询状态和系统指标的可选的性能管理数据库。
- gpperfmon_install管理工具创建名为gpperfmon的数据库, 并启用运行在Greenplum数据库Master和Segment节点上的数据收集代理。 数据收集代理会从节点上收集查询状态,还包括诸如CPU和内存使用量等系统指标。 Master节点上的代理周期性的(通常15秒)从节点代理上收集数据并更新gpperfmon数据库。 用户可以查询gpperfmon数据库来查看查询和系统指标。
监控数据库活动和性能
Greenplum数据库包含一个可选的系统监控和管理数据库gpperfmon,管理员可以 选择启用它。
监控系统状态
http://docs-cn.greenplum.org/v6/admin_guide/managing/monitor.html
一个Greenplum数据库系统由横跨多台机器的多个PostgreSQL实例(Master和Segment)构成。要监控一个 Greenplum数据库系统,需要了解整个系统的信息以及个体实例的状态信息。gpstate 工具提供有关一个Greenplum数据库系统的状态信息。
- 查看Master和Segment的状态及配置
- 查看镜像配置和状态
- 检查磁盘空间使用
- 检查分布式数据库和表的大小
- 查看一个数据库的磁盘空间使用情况
- 查看一个表的磁盘空间使用情况
- 查看索引的磁盘空间使用情况
- 检查数据分布倾斜
- 查看数据分布
- 查看数据库对象的元数据信息
- 查看会话内存使用信息
(还有SQL标准错误代码)
错误查询
如果整个Greenplum数据库系统由于一个Segment故障(例如,如果没有启用镜像或者没有足够的Segment在线 以访问全部用户数据)而变得无法运转,用户在尝试连接到数据库时会看到错误。返回给客户端程序的错误可能表明 失效。
如果启用了镜像,Greenplum数据库会在主Segment宕机后自动故障转移到一个镜像Segment上,镜像Segment承担 主Segment的角色和职能,故障主Segment变成镜像,用户感觉不到segment产生了故障。
错误侦测子进程
在Greenplum数据库master主机上,Postgres的postmaster进程会创建一个错误侦测子进程 ftsprobe。该进程也被称为FTS (Fault Tolerance Server)进程。如果FTS进程出现故障, postmaster会重启该进程。FTS进程循环执行,每个循环之间会停顿一会。每一个循环中,FTS都会从gp_segment_configuration 系统表中获取每一个主segment实例的主机名和端口号,并通过与其建立TCP套接字连接的方式连接segment实例 来侦测segment的状态。
当系统中只有主segment正常,其对应的镜像故障时,主segment会进入not synchronizing 状态并继续记录数据库日志变化,一旦镜像修复,便可以将这些变化继续同步,而不用从主segment执行一个完整的拷贝。
gpstate工具
运行gpstate工具并带有-e选项可以展示单个主segment和镜像segment实例 的任何问题。gpstate的另外一些选项也能显示所有主segment或镜像segment实例的信息。
系统表
您也可以从系统表gp_segment_configuration查看当前模式: s (同步状态)n (非同步状态),还有当前状态 u (在线) or d (离线)。
检查日志文件
日志文件可以提供信息来帮助判断一个错误的成因。每个Master和Segment实例都在其数据目录的 pg_log中有它们自己的日志文件。Master的日志文件包含了大部分信息,应该总是首先检查它。
gplogfilter工具可以用来检查Greenplum数据库日志文件。 如果要检查segment日志文件,使用gpssh在segment主机上执行gplogfilter工具。
性能
https://www.cnblogs.com/pbc1984/p/12045886.html
Greenplum :4台8核56G,9个segments 表:列存,无索引
tidb :6台8核56G,ssd
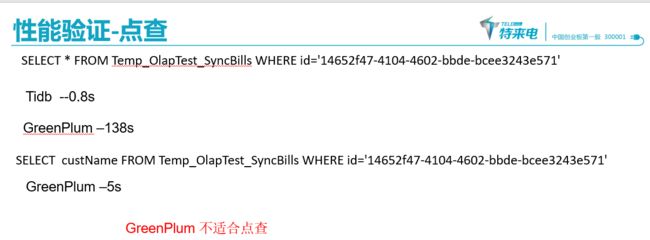

https://zhuanlan.zhihu.com/p/54907288
greenplum在3亿级别的多表关联查询对比测试中表现还行,且当时用的是版本5.7,现在更新到6.10版本,速度应该更快
接口
http://docs-cn.greenplum.org/v6/admin_guide/dml.html
http://docs.greenplum.org/6-10/ref_guide/sql_commands/sql_ref.html
增删改查是全部支持的,而且文档非常全面。
应用
优势
https://segmentfault.com/a/1190000022817663
https://blog.csdn.net/u012564911/article/details/60956500
SQL标准
通过SQL 2003 OLAP控制功能全面支持SQL-92和SQL-99。所有查询信息都并行地在整个系统上执行。
统一分析处理
可以在同一个并行数据流引擎上执行所有查询和分析(SQL、MapReduce、R等)操作,从而允许分析人员、开发人员和统计人员使用同一个基础构架进行数据分析。
可编程并行分析
为从事运算和统计工作的人员提供了更先进的并行分析功能,支持R、线性代数和机器学习功能。
数据库内压缩
采用了业内领先的压缩技术,提高性能的同时,显著地减少存储数据所需的空间。客户可以将所用空间减少3-10倍,并提高有效的I/O性能。
千万亿字节规模的数据加载操作
高性能的并行数据装载器可以在所有节点上同步执行操作,装载速度超过4.5TB/小时。
随地访问数据
不管数据的位置、格式或存储介质如何,都可以从数据库向外部数据源执行查询操作,并行向数据库返回数据。
动态扩展
帮助公司对数据仓库进行便捷的小规模或大规模扩展,同时避免高成本的设备或SMP服务器升级。
工作负载管理
允许管理人员创建基于角色的资源队列,以便划分资源和管理系统负载。
集中管理
提供集群级管理工具和资源,帮助管理人员像管理一台服务器一样管理整个Greenplum数据库平台。
性能监控
通过图形化的性能监控功能,用户可以确定当前运行的情况和历史查询信息,并跟踪系统使用情况和资源信息。
支持索引
Greenplum支持二叉搜索树、哈希、位图、GiST和GIN,从而能够实现多种索引功能,提供给数据架构师实施优化设计所必需的工具。
工业标准接口
支持标准数据库接口(SQL、ODBC、JDBC、DBI),并且可以与市场上先进的商务智能和抽取/转换/加载(ETL)工具互相操作。
约束
(网上找不到啥相关资料)
1.根据我搜到的性能测试,GP数据库支持的数据量在gb和tb级,数据量达到pb级时,gp的性能就达不到那么快了
2.由于gp数据库会将每个查询分发到各个节点上并发执行,所以gp数据库在sql并发量比较高的时候性能会下降很多
3.由于架构本身的问题,集群在扩容时需要等待数据重分布,虽然提出了一致性哈希,但这个过程是很慢的(之前甚至不能在线扩容,6版本之后可以在线扩容了)