Python爬虫原理解析

笔者公众号:技术杂学铺
笔者网站:mwhitelab.com
本文将从何为爬虫、网页结构、python代码实现等方面逐步解析网络爬虫。
1. 何为爬虫
如今互联网上存储着大量的信息。
作为普通网民,我们常常使用浏览器来访问互联网上的内容。但若是想要批量下载散布在互联网上的某一方面的信息(如某网站的所有图片,某新闻网站的所有新闻,又或者豆瓣上所有电影的评分),人为的使用浏览器挨个打开网站搜查则过于费时费力。
人为统计过于耗时耗力。
因此,编写程序来自动抓取互联网上我们想要的特定内容的信息则变得尤为重要。
网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
我们通过程序,模拟浏览器向服务器发送请求、获取信息、分析信息并储存我们想要的内容。
百度/google等搜索网站就是用采用爬虫的方式,定期搜索互联网上的链接并更新其服务器,这样我们才能通过搜索引擎搜到我们想要的信息。
2. 网页结构
访问网页远非我们输入地址后就看到网页这么简单。
在浏览器中按“F12”,或者右键网页,选择“检查”。即可看到网页背后的代码。
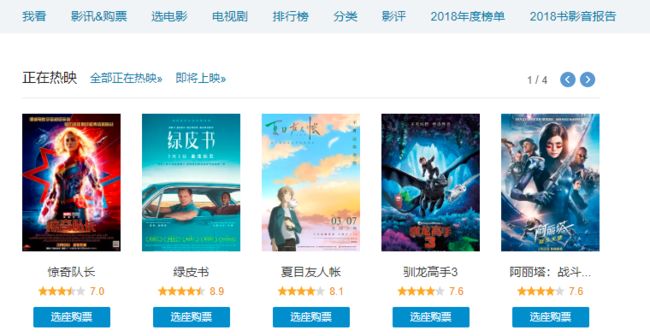
这里以谷歌的Chrome浏览器为例,在任意一个网站,我们按下F12,会出现一个浏览器的检查窗口。默认的Elements窗口为当前界面的HTML代码。

网页和Elements界面
Sources界面会显示浏览器从各服务器下载的所有文件。
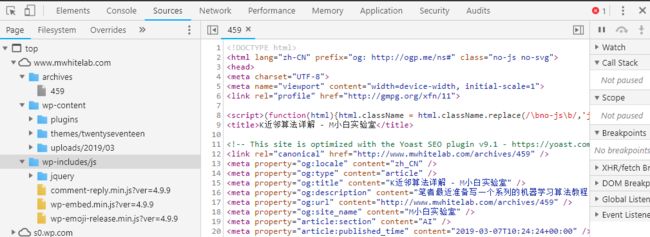
Sources界面
Network界面,在“Record Network log”状态下(按Ctrl+E可切换该状态)可以记录浏览器在各个时间段依次收到的文件和文件的相关数据。
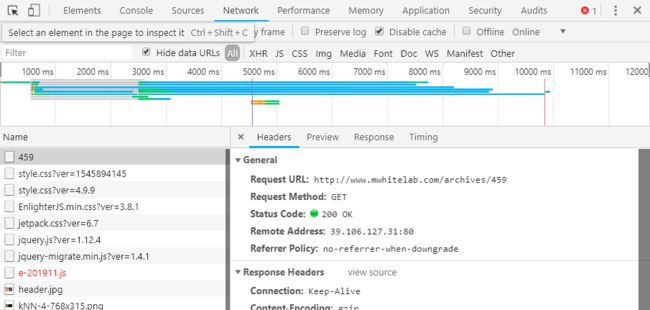
Network界面
我们这里要实现的选取特定信息的爬虫,需要我们先到对应网站去分析其网页的结构。根据网页结构对症下药,编写对应的程序,才能获取我们想要的信息。
3. python代码实现
我们将会以爬取豆瓣上《流浪地球》电影的影评为例,逐步讲解python爬虫的实现方法(使用python3)。以下代码可在github下载。
3.1 基础介绍
本节我们会用到的python的库有:
- requests:用于向服务器发送请求并获取数据
- json:用于分析json格式的数据
- bs4:用于分析html数据(pip install Beautifulsoup4 安装)
- pandas:用于分析数据
除此之外,本节中我们没有讲到,但是平常使用爬虫时可能会用到的库还有:
- sqlite3: 轻量级数据库
- re:用于进行正则表达式匹配
上述python库,bs4可用”pip install Beautifulsoup4″指令安装,其他库可用”pip install 库名词”来直接安装。
我们先新建一个jupyter文件,导入必要的python库。

导入必要python库
3.2 requests的使用

使用requests
上述代码让我们以程序的方式访问了www.baidu.com(百度)网页。
其中 “requests.get(
.find(“标签名”) 网页地址)” 即是以get的方式去访问网页。
访问网页地址分为get和post两种。get和post的区别可见下图(来自w3school)。二者区别简单了解即可,无需深究。

get和post两种HTTP请求方法
关于get、post、使用requests传参更操作,我们会在以后的高级爬虫教程中逐一讲述。
我们已经使用”response = requests.get(url)”将获得到的信息传入到”response”中。但是如果我们输出response,得到的不是网站的代码,而是响应状态码。

响应状态码
响应状态码表示我们之前requests请求的结果。常见的有200,代表成功;403,无权限访问;404文件不存在;502,服务器错误。
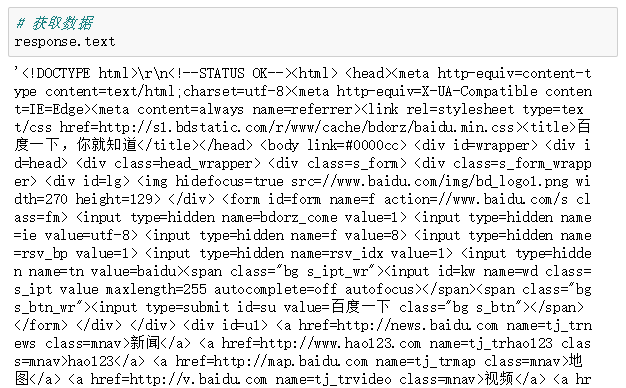
想要看到我们之前使用”requests.get(url)”得到的网页内容。我们需要先进行”response.enconding = ‘utf-8’ “,该步骤是将得到的网页内容进行utf-8编码,否则我们看不到网页中的中文。

对得到的内容进行utf-8编码
之后输入response.text,我们就能看到网页的代码了。
3.3 BeautifulSoup的使用
使用BeautifulSoup之前,建议读者对html有一定的了解。若没有,也无妨。
HTML是一种标记语言,有很强的结构要求。
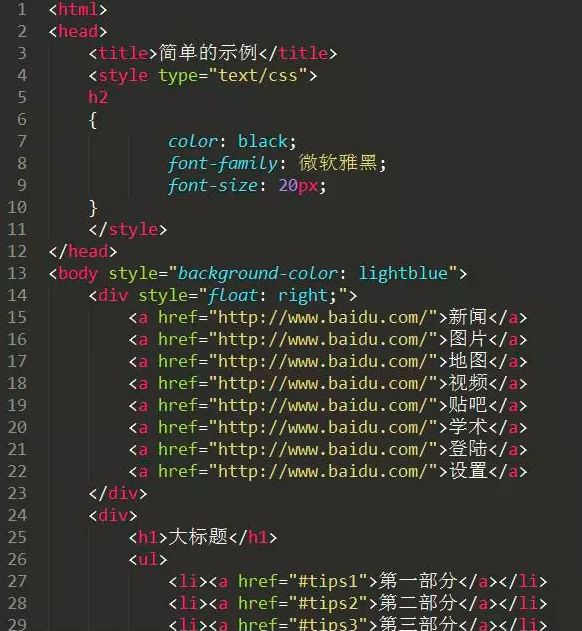
html代码示例
我们使用BeautifulSoup对HTML网页的结构进行分析,从而选出我们想要的内容。
我们使用BeautifulSoup(response.text, “lxml”)即可对我们之前得到的网页代码进行自动分析。分析结果保存在等号左边的变量soup中。

对html内容信息分析
BeautifulSoup的使用方法有很多。
比如 .find(“标签名”) 返回找到的第一个该标签的内容。

.find(“标签名”)
值得注意的是,我们找到的第一个div标签里面还有div标签。不过BeautifulSoup不会注意到这些,.find(“div”)只会返回第一个找到的div标签,以及该标签内的所有内容。
.find_all(“标签名”)则是返回找到的全部标签。

.find_all(“标签名”)
.find_all(“标签名”, class_=”类名”, id=”id名”) 可找到指定类别,指定id的标签。(注意是使用class_而非class)

.find_all(“标签名”, class_=”类名”, id=”id名”)
除此之外,我们还可以对.find(),.find_all()的结果继续进行.find(),.find_all()的查询。
3.4 json的使用
除了html格式的文件,我们还常常需要爬取一些json格式的文件。json是一种轻量级的数据交换格式。
html与json格式文件的区别如下图。(严格来讲,左侧应该为XML格式文件。但大体上也可以认为是HTML)

html与json格式文件的区别
(该图来自于网络)
于是,有的时候,我们对json格式的数据进行解析。
使用 text = json.loads(字符串格式的json数据)
即可将字符串格式的json数据转换为python的字典格式。
3.5 综合使用
我们之前提到:“根据网页结构对症下药,编写对应的程序,才能获取我们想要的信息。”
现在,我们前往豆瓣影评中《流浪地球》的短评界面。(https://movie.douban.com/subject/26266893/comments)

《流浪地球》短评界面
我们按下”F12″,打开检查界面。若是使用Chrome浏览器,可以点击如下图的小箭头或者Ctrl+Shift+C,此时,鼠标移动到页面中某一位置时,浏览器会自动显示出该位置对应的代码位置。

Ctrl+Shift+C 后可查看页面中各元素的位置
具体效果如下:

结合我们之前所讲的requests、Beautifulsoup的相应知识。读者可以自己尝试写一个爬虫,来获取当前网页的所有短评信息。
笔者这里爬取的是”https://movie.douban.com/subject/26266893/comments?start=0&limit=20&sort=new_score&status=P&comments_only=1″,是一个json文件,所以额外用到了python的json库。
代码如下。完整代码可在github上查看。这里建议读者先自己试着从零写一个爬虫,遇到问题先百度/google一下,最后再参照这个完整爬虫代码

完整爬虫代码
3.6 最终结果
最后,为了最终结果美观一点,笔者这里使用了pandas的DataFrame
![]()
使用pandas的DataFrame
爬取的数据结果如下
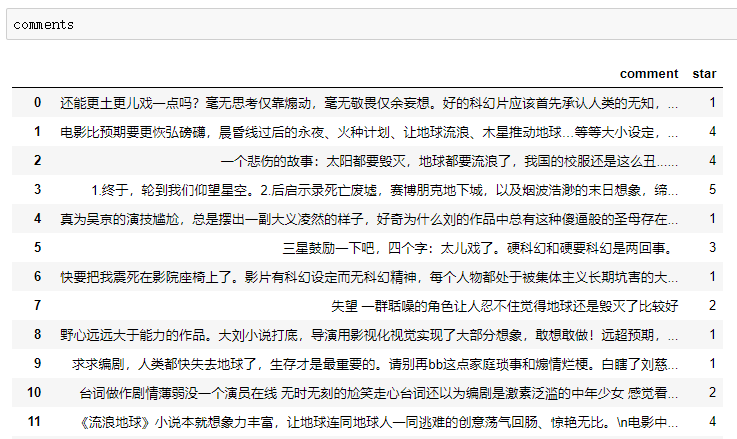
爬取的数据
3.7 拓展
以上的内容仅仅是基础的python爬虫。
若是读者细心,会发现在未登录豆瓣的情况下无法访问”
https://movie.douban.com/subject/26266893/comments?start=220&limit=20&sort=new_score&status=P&comments_only=1 “
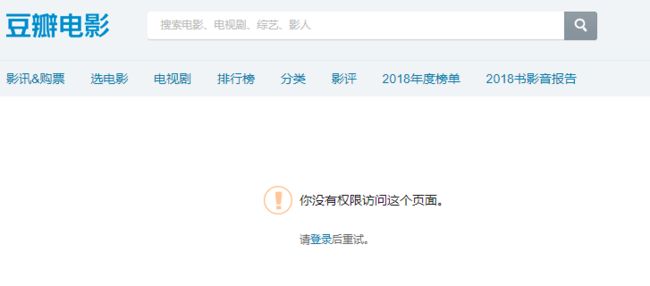
没有权限
这里url链接中start=220,也就是说在未登录的情况下我们无法查看第220条评论以后的内容。
在以后的高级爬虫教程中,我们会介绍如何使用爬虫来进行登录、保存cookie等操作。
除此之外,有些网站可能会使用js进行网站动态渲染、代码加密等等,光光爬取html和json文件是不够的。同时,我们还可以使用多进程来加快爬虫的速度……
敬请期待之后的高级爬虫教程。

文章会第一时间在公众号更新