初识分布式键值对存储etcd
欢迎大家到我的博客浏览。胤凯 (oyto.github.io)
大家好,今天我带大家来学习一下 etcd。
一、什么是 etcd
etcd 是一个开源的分布式键值存储系统,主要用于构建分布式系统中那点服务发现、配置管理、分布式锁等场景。它采用 Raft 一致性算法来确保所有节点上的数据一致性。

下面我们来讲讲 etcd 的基本架构组成要点,以及一些对应的概念:
节点
etcd 集群由多个节点组成。每个节点都运行着 etcd 的服务,并负责存储数据、处理客户端请求以及与其他节点通信。
etcd 架构的节点有三种角色,分别是:Leader、Follower、候选人。
Leader 具有唯一性,Leader 挂掉之后,会从 Follower 选择一个成为候选人,参与新一次的领导人的选举。
在 etcd 节点基础服务中,关键组件包括:
-
boltdb:作为底层存储引擎,boltdb 提供了支持事务的键值存储,用于存储节点的状态和数据。这确保了数据在节点重启后依然可用。
-
Wal(Write-Ahead-Log):Wal 是 etcd 中的预写式日志,记录所有的写入操作。在实际的键值存储操作之前,etcd 将操作写入 Wal,然后再将数据谢日 boltdb。这一机制保证了数据的一致性和持久性。
-
gRPC Server:etcd 节点之间和客户端节点之间的通信采用 gRPC 协议。
Raft 一致性算法
etcd 使用 Raft 算法来保证分布式中节点之间的一致性。Raft 算法将集群中的节点分为 Leader、Follower 和 Candidate 三种角色,通过选举机制选出 Leader,并由 Leader 负载处理客户端请求和更新集群中的数据。Leader 将更新操作复制到其他节点,确保所有节点数据一致性。
数据存储
etcd 使用键值对(Key-Value)的方式存储数据。每个节点都保存着整个集群的数据副本。数据可以通过 HTTP 或 gRPC 接口进行读写操作。etcd 的数据存储是强一致性的,即当数据提交后,所有节点上的数据都会保持一致性。
选主过程
当一个 etcd 集群启动时,所有节点都是 Follower 角色。通过 Raft 选主过程,集群中的节点将选举出一个 Leader。Leader 负责处理客户端的读写请求,并将更新操作同步给其他节点。Follower 负责接收 Leader 的同步请求并保持数据一致。
分布式通信
etcd 集群中的节点通过相互通信来维护一致性。节点之间通过心跳机制保持连接。Leader 定期发送心跳消息给 Follower,以确保节点之间通信正常。同时,Leader 将客户端的写请求同步给其他节点,确保数据的一致性。
快照
为了减少数据传输的开销,etcd 使用快照机制。当节点的数据过大时,etcd 将节点的状态进行快照,只保留最新的快照和后续的变更日志,以便在需要时进行恢复,之前的预写式日志就可以删除了,以此来节省磁盘空间,保持系统的性能。
总体而言,etcd 的基本结构就是通过这样一些机制来实现了分布式系统中的数据一致性,并通过多节点的协同工作来提供可靠、稳定、高性能的分布式键值存储服务。
二、分布式部署 etcd
下面我们将使用虚拟机来部署一个 etcd 集群,为了避免对我们的虚拟机造成影响,我们这里使用 docker 的方式来进行部署。
官方示例
打开链接 Releases · etcd-io/etcd (github.com) ,我们可以看到有教我们如何使用 docker 进行部署,下面我们来看看这些命令:
rm -rf /tmp/etcd-data.tmp && mkdir -p /tmp/etcd-data.tmp && \
docker rmi gcr.io/etcd-development/etcd:v3.5.10 || true && \
docker run \
-p 2379:2379 \
-p 2380:2380 \
--mount type=bind,source=/tmp/etcd-data.tmp,destination=/etcd-data \
--name etcd-gcr-v3.5.10 \
gcr.io/etcd-development/etcd:v3.5.10 \
/usr/local/bin/etcd \
--name s1 \
--data-dir /etcd-data \
--listen-client-urls http://0.0.0.0:2379 \
--advertise-client-urls http://0.0.0.0:2379 \
--listen-peer-urls http://0.0.0.0:2380 \
--initial-advertise-peer-urls http://0.0.0.0:2380 \
--initial-cluster s1=http://0.0.0.0:2380 \
--initial-cluster-token tkn \
--initial-cluster-state new \
--log-level info \
--logger zap \
--log-outputs stderr
docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcd --version
docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcdctl version
docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcdutl version
docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcdctl endpoint health
docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcdctl put foo bar
docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcdctl get foo-
rm -rf /tmp/etcd-data.tmp && mkdir -p /tmp/etcd-data.tmp:删除并创建/tmp/etcd-data.tmp目录,这是为了防止我们的目录下已经存在该目录,用于存储 etcd 的数据。 -
docker rmi gcr.io/etcd-development/etcd:v3.5.10 || true: 删除 etcd 镜像,如果不存在则不报错。 -
docker run ...:启动 etcd 容器,参数如下:-
-p 2379:2379:映射容器的 2379 端口到主机的 2379 端口。 -
-p 2380:2380: 映射容器的 2380 端口到主机的 2380 端口。 -
--mount type=bind,source=/tmp/etcd-data.tmp,destination=/etcd-data: 将主机的/tmp/etcd-data.tmp目录绑定到容器的/etcd-data目录,用于持久化 etcd 的数据。 -
--name etcd-gcr-v3.5.10: 指定容器的名称为etcd-gcr-v3.5.10。 -
gcr.io/etcd-development/etcd:v3.5.10: 使用 etcd 官方提供的 Docker 镜像。 -
/usr/local/bin/etcd ...: 启动 etcd 的命令及相关参数。这里后面会做讲解。
-
-
docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcd --version: 在容器内执行etcd --version命令,输出 etcd 的版本信息。 -
docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcdctl version: 在容器内执行etcdctl version命令,输出 etcdctl 的版本信息。 -
docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcdutl version: 这一行命令有误,应为docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcdutl version。这个命令在容器内执行etcdutl version,输出 etcdutl 的版本信息。 -
docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcdctl endpoint health: 在容器内执行etcdctl endpoint health,检查 etcd 集群的健康状态。 -
docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcdctl put foo bar: 在容器内执行etcdctl put foo bar,将键值对foo: bar存储到 etcd 集群中。 -
docker exec etcd-gcr-v3.5.10 /usr/local/bin/etcdctl get foo: 在容器内执行etcdctl get foo,获取键foo对应的值。
上面只是官方给我们的使用示例,我们做一个参考就行,我们可以按照自己的方式进行部署。
开始部署
创建容器
由于我们采用 docker 的方式进行部署,故第一步肯定是下载镜像。
我们这里通过 coreos/etcd · Quay 找到我们想要的 docker 镜像,我这里下载 v3.5.5 ,选择 Docker Pull(by tag),获取到对应的下载链接。
然后来到我们的虚拟机,执行 docker pull quay.io/coreos/etcd:v3.5.5 拉取镜像,当前前提是需要在虚拟机上安装并启动 docker 服务,安装这里就不再讲解了,大家可以去查看对应的资料进行安装和启动。
拉取完成后,我们可以通过 docker images 命令检查一下是否成功拉取到镜像:
根据我们拉取到的镜像,启动容器 docker run -dit quay.io/coreos/etcd:v3.5.5 sh,通过 docker ps -a 查看容器 ID,根据进入 etcd 容器的交互模式 docker exec -it eeb9a5e45d9e sh。
验证并认识参数
我们可以使用 etcd -h 命令检查是否能够访问 etcd 服务

出现上面这个界面,就说明我们的 etcd 容器已经成功创建了,刚好借着 etcd -h 这个命令我们来看一些启动 etcd 集群需要了解的参数:
-
--name:指定 etcd 服务器的名称,以此来区分集群中不同的 etcd 节点
-
--data-dir:指定 etcd 保存数据的目录,用于存储 etcd 数据库文件,包括 kv 数据和元数据
-
--wal-dir:指定 etcd 预写式日志的目录,它记录了 etcd 数据库所有的变更,以确保数据的一致性和持久性
-
snapshot-count:设置 etcd 触发快照的触发次数,当写入预写式日志的次数达到该值,就会生成一次快照。
-
listen-peer-urls:指定 etcd 服务器监听的对等节点通信地址, 用于集群中节点之间的通信,传递心跳、日志复制等信息。端口通常为 2380,即暴露给其他节点的通信地址。
-
--listen-client-urls:指定
etcd服务器监听的客户端通信地址。 用于客户端与etcd服务器进行通信,包括查询和修改 key-value 数据等操作。通常端口为 2379,即对外提供的 etcd 服务节点。 -
--initial-advertise-peer-urls: 指定
etcd服务器用于集群中通信的地址。用于告知其他节点该节点的通信地址,集群中其他节点将通过这个地址与该节点进行通信。 -
--initial-cluster: 指定初始集群的成员信息。用于告知
etcd服务器集群中的其他节点。格式为= -
--initial-cluster-state:指定
etcd服务器在集群启动时的状态。 'new' 表示新的集群,'existing' 表示已经存在的集群。 -
--initial-cluster-token:指定新创建的集群的 token。用于标识一个集群,确保不同的集群拥有不同的 token。
-
advertise-client-urls:指定
etcd服务器广播给客户端的地址。用于告知客户端与etcd服务器进行通信的地址。
配置集群信息
认识并了解了启动集群所必备的参数和信息,我们开始配置集群信息。
我们的集群,以同一台虚拟机使用 docker 启动 3 个不同的 etcd 服务,来模拟集群中的三个节点,并且为了展示集群的功能,所以我们再准备第四个配置文件。所以我们需要去写 4 个 etcd 节点配置文件。
我们可以在虚拟机 root 目录下创建 etcd 文件夹,并在 etcd 文件夹里创建 etcdconf 文件夹,使用 vim etcd0.yaml 创建配置文件,配置内容如下:
etcd0.yaml
# 节点名称
name: "etcdnode0"
# 数据存储目录
data-dir: "/etcd-data/data"
# 预写式日志存储目录
wal-dir: "/etcd-data/wal"
# 集群成员之间通讯使用URL
listen-peer-urls: "http://0.0.0.0:2380"
# 集群提供给外部客户端访问的URL,即外部客户端必须通过制定的IP加端口访问etcd
listen-client-urls: "http://0.0.0.0:2379"
# 集群配置
initial-advertise-peer-urls: "http://192.168.235.128:2380"
# 集群初始成员配置,是etcd静态部署的核心初始化配置,它说明了当前集群由哪些URLs组成,此处default为节点名称
initial-cluster: "etcdnode0=http://192.168.235.128:2380,etcdnode1=http://192.168.235.128:12380,etcdnode2=http://192.168.235.128:22380"
# 初始化集群状态(new 或 existing)
initial-cluster-state: "new"
# 引导期间etcd集群的初始集群令牌,防止不同集群之间产生交互
initial-cluster-token: "etcd-cluster"
# 向客户端发布的服务端节点
advertise-client-urls: "http://192.168.235.128:2379"
logger: "zap"
# 配置日志级别,仅支持 debuf、info、warn、error、panic、or fatal
log-level: "warn"
log-outputs:
- "stderr"参数的意义,我们已经在上面讲解过了,下面就讲所有的配置文件一并给大家:
etcd1.yaml
# 节点名称
name: "etcdnode1"
# 数据存储目录
data-dir: "/etcd-data/data"
# 预写式日志存储目录
wal-dir: "/etcd-data/wal"
# 集群成员之间通讯使用URL
listen-peer-urls: "http://0.0.0.0:12380"
# 集群提供给外部客户端访问的URL,即外部客户端必须通过制定的IP加端口访问etcd
listen-client-urls: "http://0.0.0.0:12379"
# 集群配置
initial-advertise-peer-urls: "http://192.168.235.128:12380"
# 集群初始成员配置,是etcd静态部署的核心初始化配置,它说明了当前集群由哪些URLs组成,此处default为节点名称
initial-cluster: "etcdnode0=http://192.168.235.128:2380,etcdnode1=http://192.168.235.128:12380,etcdnode2=http://192.168.235.128:22380"
# 初始化集群状态(new 或 existing)
initial-cluster-state: "new"
# 引导期间etcd集群的初始集群令牌,防止不同集群之间产生交互
initial-cluster-token: "etcd-cluster"
# 向客户端发布的服务端节点
advertise-client-urls: "http://192.168.235.128:12379"
logger: "zap"
# 配置日志级别,仅支持 debuf、info、warn、error、panic、or fatal
log-level: "warn"
log-outputs:
- "stderr"etcd2.yaml
# 节点名称
name: "etcdnode2"
# 数据存储目录
data-dir: "/etcd-data/data"
# 预写式日志存储目录
wal-dir: "/etcd-data/wal"
# 集群成员之间通讯使用URL
listen-peer-urls: "http://0.0.0.0:22380"
# 集群提供给外部客户端访问的URL,即外部客户端必须通过制定的IP加端口访问etcd
listen-client-urls: "http://0.0.0.0:22379"
# 集群配置
initial-advertise-peer-urls: "http://192.168.235.128:22380"
# 集群初始成员配置,是etcd静态部署的核心初始化配置,它说明了当前集群由哪些URLs组成,此处default为节点名称
initial-cluster: "etcdnode0=http://192.168.235.128:2380,etcdnode1=http://192.168.235.128:12380,etcdnode2=http://192.168.235.128:22380"
# 初始化集群状态(new 或 existing)
initial-cluster-state: "new"
# 引导期间etcd集群的初始集群令牌,防止不同集群之间产生交互
initial-cluster-token: "etcd-cluster"
# 向客户端发布的服务端节点
advertise-client-urls: "http://192.168.235.128:22379"
logger: "zap"
# 配置日志级别,仅支持 debuf、info、warn、error、panic、or fatal
log-level: "warn"
log-outputs:
- "stderr"etcd3.yaml
# 节点名称
name: "etcdnode3"
# 数据存储目录
data-dir: "/etcd-data/data"
# 预写式日志存储目录
wal-dir: "/etcd-data/wal"
# 集群成员之间通讯使用URL
listen-peer-urls: "http://0.0.0.0:32380"
# 集群提供给外部客户端访问的URL,即外部客户端必须通过制定的IP加端口访问etcd
listen-client-urls: "http://0.0.0.0:32379"
# 集群配置
initial-advertise-peer-urls: "http://192.168.235.128:32380"
# 集群初始成员配置,是etcd静态部署的核心初始化配置,它说明了当前集群由哪些URLs组成,此处default为节点名称
initial-cluster: "etcdnode0=http://192.168.235.128:2380,etcdnode1=http://192.168.235.128:12380,etcdnode2=http://192.168.235.128:22380,etcdnode3=http://192.168.235.128:32380"
# 初始化集群状态(new 或 existing)
initial-cluster-state: "existing"
# 引导期间etcd集群的初始集群令牌,防止不同集群之间产生交互
initial-cluster-token: "etcd-cluster"
# 向客户端发布的服务端节点
advertise-client-urls: "http://192.168.235.128:32379"
logger: "zap"
# 配置日志级别,仅支持 debuf、info、warn、error、panic、or fatal
log-level: "warn"
log-outputs:
- "stderr"由于第四个配置文件中,集群配置里有四个节点并且初始化集群状态会已存在,故我们在后面的以第四个配置文件启动 etcd 服务的时候,需要先在集群中创建该节点,告诉其他节点有新节点来了,才能在使用该配置文件启动服务时与其他节点成功建立通信。
启动 etcd 服务
写好配置文件之后,我们仿照官网示例来启动 etcd 服务了,我们这里是采用读取配置文件的方式进行启动服务的,与官方示例不同。
使用下面的命令创建并允许一个容器,这个命令主要是将 docker 设置在后台允许容器,以及一些端口映射、命名、配置文件路径的配置:
docker run -d -p 2379:2379 -p 2380:2380 -v /tmp/etcd0-data:/etcd-data -v /root/etcd/etcdconf:/etcd-conf --name etcd0 quay.io/coreos/etcd:v3.5.5 /usr/local/bin/etcd --config-file=/etcd-conf/etcd0.yaml可以通过 docker ps 观察容器是否启动起来了,如果启动了,就说明没有说明问题;如果没有成功启动,可以使用 docker log etcd0 查看 etcd0 的日志输出,找到错误信息进行排查。
接着可以再检查一下我们的目录映射有没有问题,
ls /tmp/etcd0-data/
再看看我们的日志,
docker logs -f etcd0会发现一直在报 warn 错,因为我们配置在其他几个节点,但是其他集群几个节点还没有启动,所以就会一直报错。
然后我们依次去把其他两个节点启动,
docker run -d -p 12379:12379 -p 12380:12380 -v /tmp/etcd1-data:/etcd-data -v /root/etcd/etcdconf:/etcd-conf --name etcd1 quay.io/coreos/etcd:v3.5.5 /usr/local/bin/etcd --config-file=/etcd-conf/etcd1.yaml
docker run -d -p 22379:22379 -p 22380:22380 -v /tmp/etcd2-data:/etcd-data -v /root/etcd/etcdconf:/etcd-conf --name etcd2 quay.io/coreos/etcd:v3.5.5 /usr/local/bin/etcd --config-file=/etcd-conf/etcd2.yaml启动完成后,使用 docker ps 查看容器:

然后再次查看我们的日志,就发现我们的日志报错停止了,就说明我们的 etcd 集群启动成功了。
三、etcd 集群运维基本操作
由于虚拟机本地没有下载 etcd,我们只能去访问容器内的 etcd 服务了,使用下面的命令进入 etcd 容器交互模式
docker exec -it etcd0 bash然后我们开始我们的功能讲解,以及一些参数讲解。
健康检查
健康检查功能是值系统能够自动检测节点的健康状态,以确保集群的正常运行。
集群节点心跳间隔
--heartbeat-interval:这个参数用于设置 etcd 集群中节点之间发送心跳的时间间隔。默认值为 100 毫秒。你可以通过以下方式修改为 500 毫秒:
etcd --heartbeat-interval=500心跳间隔最长时间
--election-timeout: 这个参数用于设置选举超时时间,即节点在多长时间内没有收到心跳信号后就可能发起一次选举。默认值为 1000 毫秒。你可以通过以下方式修改为 3000 毫秒:
etcd --election-timeout=3000获取集群各节点状态信息
etcdctl endpoint status:这个命令用于获取 etcd 集群中各节点的详细状态信息,包括节点的 ID、地址、健康状况等。
常用的参数有:
-
--cluster:打印所有节点 -
-w table:表格格式展示 -
--endpoints:指定访问的节点

详细解释:
-
ID:节点的唯一标识符。 -
Version:etcd 版本。 -
Endpoint:节点的监听地址。 -
Status:节点的健康状况,通常包括healthy、unhealthy或unknown。 -
Duration:节点的运行时间。 -
Peer URLs:节点的对等节点通信地址。 -
Client URLs:节点的客户端通信地址。
检查 etcd 集群的健康状况
etcdctl endpoint health:该命令用于检查 etcd 集群的健康状况,判断是否所有节点都处于正常运行状态。
常用参数:
-
--cluster:打印所有节点 -
-w table:表格格式展示 -
--endpoints:指定访问的节点

详细解释:
-
cluster is healthy:表示集群中的所有节点都处于健康状态。 -
unhealthy:表示集群中存在不健康的节点。
告警管理:
在 etcd 中,告警管理是一种机制,用于帮助管理员和操作人员监测和响应 etcd 集群中可能发生的问题。通过设置告警规则和配置,管理员可以在集群遇到异常或潜在问题时得到通知,以便及时采取必要的措施。
常见的命令有:
-
alarm disarm-
作用:解除etcd集群中的告警状态,允许集群继续正常运行。
-
-
alarm list-
作用:列出etcd集群中的告警信息,提供了对当前集群告警状态的查看。
-
数据规模检查
在 etcd 中,数据规模检查通常是指对 etcd 存储的数据规模(数据量的大小)进行监测和检查的机制。这涉及到集群中存储的键值对数量、数据大小等方面的指标。
常见的命令有:
-
etcdctl check datascale:检查 etcd 集群数据规模的工具,常用参数如下:-
--auto-compact:启用自动压缩功能。etcd 存储中的历史版本可能会占用磁盘空间,自动压缩可以清理不再需要的历史版本,释放磁盘空间。 -
--auto-defrag: 启用磁盘自动碎片整理功能。etcd 存储在删除键值对时可能会导致碎片,自动碎片整理有助于提高磁盘空间的利用率。 -
--load:指定不同规模的集群来进行性能测试。可以用于模拟不同负载下 etcd 集群的性能表现。 -
--endpoints: 对指定节点进行数据规模检查。可以通过--endpoints参数指定 etcd 集群的节点地址。
-
-
etcdctl check perf:执行 etcd 集群的性能检查,用于评估集群的性能表现。 -
etcdctl del /etcdctl-check-datascale/ --prefix:删除以指定前缀的所有键,通常用于清理测试数据。在进行数据规模检查之前,可以使用该命令清理之前的测试数据。
快照操作
在 etcd 中,快照操作是指对 etcd 存储中的当前状态进行备份的操作。快照是一个在某个时间点捕获的 etcd 存储的状态副本,它包含了该时间点的所有键值对数据以及相应的元数据信息。
常见命令有:
-
etcdctl snapshot save-
保存etcd集群的快照,用于备份和恢复。
-
-
etcdutl snapshot restore-
恢复etcd集群的快照,用于在需要时还原数据。
-
-
etcdutl snapshot status-
查看etcd集群快照的状态信息,包括快照文件的大小、创建时间等。
-
集群管理
在 etcd 中,集群管理涉及到对 etcd 集群进行配置、监控、维护和优化等一系列操作。
常见的命令有:
-
etcdctl move-leader:手动移动etcd集群的领导者节点,用于修改集群中的领导者。
节点管理
在 etcd 中,节点管理是指对 etcd 集群中的节点进行监控、维护和操作的一系列管理任务。
常见的命令有:
-
etcdctl member add-
作用:向etcd集群中添加新的节点。
-
-
etcdctl member list-
作用:列出etcd集群中的所有节点。
-
-
etcdctl member promote-
作用:提升etcd集群中普通节点的权限,使其具备领导者选举资格。
-
-
etcdctl member remove-
作用:从etcd集群中移除指定节点。
-
-
etcdctl member update-
作用:更新etcd集群中节点的信息,如名称、地址等。
-
四、etcd 数据操作之租约与事务
数据操作
在 etcd 中,数据操作的确主要涉及 put、get、del 这三个基本操作,分别用于存储、检索和删除键值对。
下面带大家一一熟悉:
put
etcdtcl put 是用于将键值对存储到 etcd 中的命令。
常见的参数及其功能如下:
-
--ignore-lease: 忽略租约。使用此参数可以在存储键值对时忽略租约的存在。
-
--ignore-value: 忽略值。即使键已经存在,也强制写入新值。
-
--lease="0": 设置租约的持续时间,0 表示无租约。
-
--prev-kv: 在更新操作时,检查前一个键值对的存在性,只有存在时才执行更新。
get
etcdctl get 用于从 etcd 中检索键值对。
常见的参数及其功能如下:
-
-w json: 指定输出格式为 JSON,并提供详细的键值对信息。
-
--prefix: 指定前缀,以获取匹配指定前缀的所有键值对。相当于 SQL 中的
LIKE 'key%'。 -
--consistency="l or s": 设置一致性级别,
l表示与 leader 节点比较数据的一致性较高,s表示仅在当前节点上检查键值对的存在性。 -
--count-only: 仅返回匹配条件的键值对数量而不返回具体的键值对。
-
--from-key: 获取键大于或等于指定键的所有键值对。相当于 SQL 中的
WHERE key >= 'specified_key'。
del
etcdctl del 用于从 etcd 中删除键值对。
租约
在etcd中,租约(Lease)是一种用于为键值对分配时间的机制,用于管理临时性的关联性数据。租约的主要目的是为了在一段时间内提供对键值对的持久性,而在租约到期后,键值对会自动从存储中删除。
租约的主要特性:
-
时间控制: 每个租约都有一个预定的时间期限,称为TTL(Time-to-Live)。该TTL指定了租约的生命周期,通常以秒为单位。
-
续约: 租约可以续约,即在TTL期限内,持有者可以通过向etcd发送心跳继续使用租约。如果续约失败或终止,租约将在TTL到期后失效。
-
关联键值对: 租约通常与键值对相关联。在创建键值对时,可以将租约ID与其关联,从而确定键值对的生命周期。
-
自动删除: 当租约到期时,关联的键值对将自动从etcd中删除,释放资源。
租约中常用参数:
-
lease grant:
-
用于创建一个新的租约,并返回租约的 ID。
-
用法:
etcdctl lease grant
-
-
lease keep-alive:
-
保持租约的活动状态,防止租约过期。该命令会持续发送心跳以保持租约的有效性。
-
用法:
etcdctl lease keep-alive
-
-
lease list:
-
列出当前存在的所有租约。
-
用法:
etcdctl lease list
-
-
lease revoke:
-
用于撤销(取消)指定的租约。
-
用法:
etcdctl lease revoke
-
-
lease timetolive:
-
获取指定租约的剩余生存时间。
-
用法:
etcdctl lease timetolive
-
下面带大家一起使用一下:
-
我们先使用
etcdctl lease grant 60创建一个 60s 的租约,它会返回一个租约 ID, -
然后我们拿着这个租约 ID 去给我们的设置租约,
etcdctl put k v --lease=, -
然后使用
etcdctl lease timetolive查看还有多久过期, -
在未过期时,可以使用
etcdctl get k查看到键值对,在租约过期后,就无法查看到了。
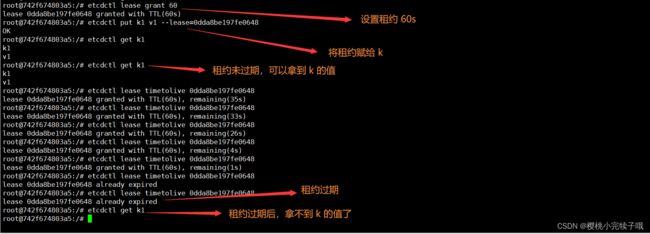
大家可以自己实践一下,而且只要租约还未过期,我们就可以为租期设置为永不过期 etcdctl lease keep-alive 。
事务
在etcd中,事务是一组对键值存储的原子操作,可以确保这些操作要么全部成功,要么全部失败。etcd的事务支持在单个事务中包含多个操作,这些操作可以是读取、写入、修改等,事务将这些操作组合在一起执行。
etcd 中的事务本质上是由 if 语句 + then语句 + else 语句 组成。if 语句检查通过,则执行 then 语句里面的内容,否则执行 else 语句里面的内容
if 语句里面可以判断的条件包括但不限于:
-
mod_revision:检查键的修改版本号是否满足条件。
-
create_revision:检查键的创建版本号是否满足条件。
-
version:检查键的版本号是否满足条件。
-
value:检查键的值是否满足条件。
-
evalue:检查键的值是否匹配指定的正则表达式。
开启事务
下面我们带大家写一个简单的 etcd 事务。
使用 etcdctl txn -i 开启事务,具体的流程图如下:

小结
今天我们对 etcd 的介绍就只讲这么多了,后面还会带大家手把手用 Go 语言去操作 etcd 的客户端。