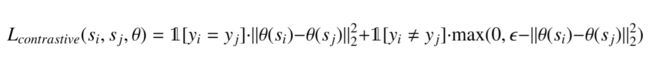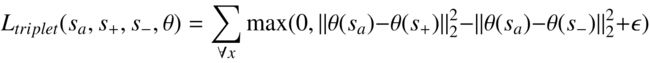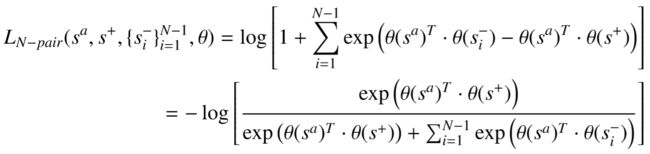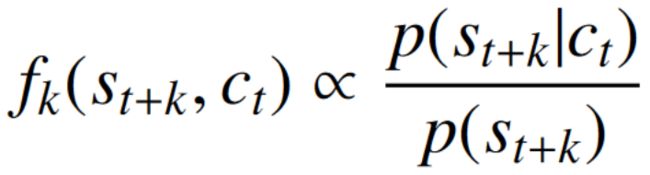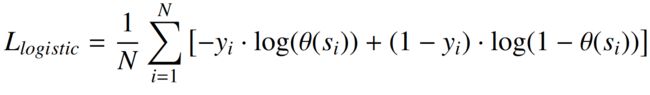对比学习是一种机器学习技术,算法学习区分相似和不相似的数据点。对比学习的目标是学习数据的表示,以捕捉不同数据点之间的基本结构和关系。
在对比学习中,算法被训练最大化相似数据点之间的相似度,并最小化不相似数据点之间的相似度。通常的做法是通过训练算法来预测两个数据点是否来自同一类别。
对比学习已经在各种应用中得到了应用,如图像识别、自然语言处理和语音识别。对比学习的一种流行方法是孪生网络,它使用一对相同的神经网络来学习数据点之间的相似度函数。
总的来说,对比学习是一种强大的技术,可以用于学习数据的表示,并可用于各种下游任务。
什么是对比学习?
对比学习是一种机器学习范例,其中将未标记的数据点相互并列,以教导模型哪些点相似,哪些点不同。
也就是说,顾名思义,样本相互对比,属于同一分布的样本在嵌入空间中被推向彼此。相比之下,属于不同分布的那些则相互拉扯。
对比学习的重要性
监督学习是一种机器学习技术,其中使用大量标记示例来训练模型。数据标签的质量对于监督模型的成功至关重要。
专业提示:查看监督学习与无监督学习:有什么区别?
但是,获取如此高质量的标记数据是一项繁琐的任务,尤其是在生物医学成像等领域,需要专家医生对数据进行注释。这既昂贵又费时。在监督学习 ML 项目中,80% 的时间都花在了获取和清理模型训练的数据上。
因此,最近深度学习研究的重点是减少模型训练中对监督的要求。为此,已经提出了几种方法,如半监督学习、无监督学习和自监督学习。
在半监督学习中,使用少量标记数据和大量未标记数据来训练深度模型。在无监督学习中,模型试图理解没有任何数据标签的非结构化数据。
专业提示:阅读更多关于训练-验证-测试集的信息。
自我监督学习 (SSL) 的方法略有不同。
与无监督学习一样,非结构化数据作为输入提供给模型。但是,该模型会自行注释数据,并且在模型训练的未来迭代中使用已被高置信度预测的标签作为基本事实。
这不断改进模型权重以做出更好的预测。与传统监督方法相比,SSL 方法的功效引起了一些计算机视觉研究人员的注意。
专业提示:通过阅读什么是数据标记以及如何高效地进行标记,了解如何更快地标记数据 [教程]。
SSL 中使用的最古老和最受欢迎的技术之一是对比学习,它使用“正”和“负”样本来指导深度学习模型。
此后,对比学习得到了进一步发展,现在被用于完全监督和半监督的环境中,并提高了现有技术水平的性能。
现在让我们讨论一下对比学习的工作原理。
对比学习如何在 Vision AI 中发挥作用?
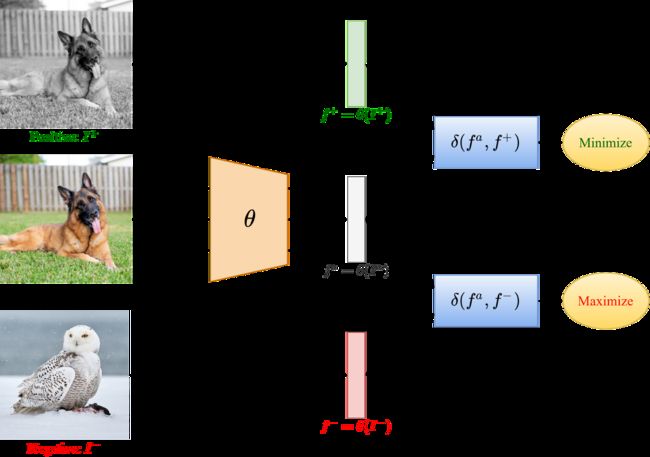
对比学习模仿人类的学习方式。例如,我们可能不知道什么是水獭或什么是灰熊,但看到图像(如下所示),我们至少可以推断出哪些图片显示的是相同的动物。
基本的对比学习框架包括选择一个数据样本,称为“锚点”,一个与锚点属于相同分布的数据点,称为“正”样本,以及另一个属于不同分布的数据点,称为“负”样本样本。
SSL模型试图在潜在空间中最小化anchor和正样本(即属于同一分布的样本)之间的距离,同时最大化anchor和负样本之间的距离。
如上例所示,属于同一类的两幅图像在嵌入空间(“ d+ ”)中彼此靠近,而属于不同类的两幅图像彼此之间的距离较远(“ d- ”)。因此,对比学习模型(在上例中用“ theta ”表示)试图最小化距离“ d+ ”并最大化距离“ d- ”。
有几种技术可以根据锚点选择正样本和负样本,我们将在接下来讨论。
实例判别法
在这类对比学习中,整个图像都经过转换并用作锚图像的正样本。例如,如果我们选择狗的图像作为锚点,我们可以将图像镜像或将其转换为灰度图像以用作正样本。负样本可以是数据集中的任何其他图像。
下图展示了基于实例区分的对比学习技术的基本框架。距离函数可以是任何东西,从欧几里得距离到嵌入空间中的余弦距离。
常用的基于实例判别对比学习的一些图像增强方法如下:
- 颜色抖动:在这里,RGB 图像的亮度、对比度和饱和度随机变化。此技术有助于确保模型不会通过场景的颜色记住给定的对象。虽然输出图像的颜色对于人类的解释可能看起来很奇怪,但这种增强有助于模型考虑对象的边缘和形状,而不仅仅是颜色。
- 图像旋转:图像在 0-90 度范围内随机旋转。由于旋转图像不会改变其中包含的核心信息(即图像中的狗仍然是狗),因此模型被训练为旋转不变性以进行稳健的预测。
- 图像翻转:图像围绕其中心垂直或水平翻转(镜像)。这是基于图像旋转的增强概念的扩展。
- 图像噪声:随机噪声按像素添加到图像中。这种技术允许模型学习如何将信号与图像中的噪声分开,并使其在测试期间对图像的变化更加稳健。例如,将图像中的某些像素随机更改为白色或黑色称为椒盐噪声(示例如下所示)。
- 随机仿射:仿射是一种保留直线和平行度但不一定保留距离和角度的几何变换。

上图显示了本节中描述的图像增强的一些示例
图像子采样/修补方法
此类对比学习方法将单个图像分解为固定尺寸的多个补丁(例如,10x10 补丁窗口)。补丁之间可能存在某种程度的重叠。
现在,假设我们拍摄一只猫的图像,并使用它的一个补丁作为锚点,同时利用其余部分作为正样本。来自其他图像的补丁(例如,浣熊、猫头鹰和长颈鹿各有一个补丁)用作负样本。
对比学习:目标
对比学习文献中定义了许多损失函数,用于不同问题的应用,每个损失函数都有自己的一组功能。让我们在本节中讨论其中的一些。
1. Max margin Contrastive Loss
它是对比学习文献(论文)中提出的最古老的损失函数之一。
这里的基本思想是,如果样本不属于同一分布,损失函数会最大化样本之间的距离,如果样本属于同一分布,则损失函数会最小化它们之间的距离。它在数学上表示如下:
这里,“ s_i ”和“ s_j ”是需要比较的对应标签“ y_i ”和“ y_j ”的两个样本,“ theta ”是嵌入网络,“ epsilon ”是超参数,定义下界距离不同类别的样本之间。
样本的标签由样本是否属于同一分布生成。例如,如果两个样本是同一图像的裁剪版本或同一样本的增强版本,则标签将相同。
2.三元组损失
三元组损失(在本文中提出)与对比损失非常相似,两者都试图最小化相似分布之间的距离并最大化不同分布之间的距离。三元组损失的主要区别在于,正样本和负样本同时作为锚样本的输入来计算损失。在数学上它表示如下:
这里,“ s_a ”、“ s+ ”、“ s- ”分别代表anchor、正样本和负样本。对于使用三元组损失函数的模型的成功,负样本难以与正样本分开是至关重要的。
例如,浣熊和环尾猫看起来非常相似(见下图)。两者都有条纹、浓密的尾巴和相似的体毛颜色。当对浣熊进行负样本采样时,选择环尾会使模型更有效地区分类别,而不是选择大象作为负样本。
3. N-pair Loss
N 对损失是三元组损失函数的扩展。不是对单个负样本进行采样,而是对“N”个负样本以及一个锚点和一个正样本进行采样。这种损失的数学表示如下:
上面显示的 N 对损失函数是为(N+1)个训练样本定义的,其中第一个样本是锚点“ s^a ”,第二个样本是正样本“ s+ ”,其余的(N -1)样本是反例。
在这个等式中,如果我们只有一个负样本而不是(N-1),那么得到的等式将等同于多类分类问题的 softmax 损失函数。
4.InfoNCE
InfoNCE,其中 NCE 代表噪声对比估计,是另一种类型的对比损失函数。
如果“ S = {s_1, s_2, …, s_N} ”表示包含一个正样本和“ N-1 ”个负样本的“ N ”个随机样本集合,则损失函数可以在数学上表示如下:
优化此损失将导致“ f_k ”估计由下式给出的密度比:
密度比保留了未来观测值“ s_{t+k} ”和上下文潜在表示“ c_t ”之间的互信息。“ p(s_{t+k}) ”是一个生成模型。
5.物流损失
逻辑损失函数是监督学习文献中广泛使用的一种简单的凸损失函数。它在数学上表示为:
损失是为“ N ”个样本定义的,这些样本由“ s_i ”表示,相应的标签(无论样本是否属于同一分布)由“ y_i ”表示。
6. NT-Xent 损失
Normalized Temperature-scaled Cross-Entropy 或 NT-Xent 损失是多类 N 对损失的修改,增加了温度 (T) 参数。它在数学上表示如下:
“ sim(.) ”表示余弦相似度函数,“ z_i ”和“ z_j ”分别是样本“ s_i ”和“ s_j ”的编码特征。
上面的等式显示了自监督学习中使用的 NT-Xent 损失的表达式。对于监督学习,上面显示的对比损失无法处理由于标签的存在,已知不止一个样本属于同一类的情况。推广到任意数量的积极因素导致在多个可能的功能之间进行选择。
因此,NT-Xent 损失在监督学习范式中的扩展表示如下:
这里,( 2N_{y_i} -1 ) 表示多视图批处理中不同于“ i ”的所有正样本的索引集。
监督对比学习 (SSCL) 与自我监督对比学习 (SCL)
监督学习是指一种学习范式,其中数据及其对应的标签都可用于训练模型。另一方面,在自监督学习中,模型在没有任何外部支持的情况下使用原始输入数据生成标签。
专业提示:查看机器学习中数据预处理的简单指南。
在自监督对比学习 (SSCL) 中,由于没有类标签,正样本和负样本是通过各种数据增强技术从锚图像本身生成的。所有其他图像的增强版本被视为“负”样本。
这些挑战阻碍了模型训练。例如,如果我们有一张狗的图像作为锚样本,那么只有该图像的增强版本才能形成正样本。因此,其他狗的图像也属于负样本集。
因为,根据自监督学习框架,对比损失函数将迫使两个不同的狗图像在嵌入空间中远离,而实际上,它们应该尽可能靠近。
因此,监督对比学习 (SCL) 有效地利用了标签信息,并允许相同分布的样本(如不同狗的几张图像)在潜在空间中靠得很近,而属于不同类别的样本在潜在空间中被排斥。
因此,SCL 框架的损失函数也不同于 SSCL 框架中使用的损失函数。上一节在解释 NT-Xent 损失函数时探讨了一个这样的例子。
这里提到的与 SSCL 相关的问题也引发了自监督学习的非对比学习领域,我们根本不使用任何负样本。
我们只使用正样本来训练模型,其目的是将样本的表示(属于同一分布)推到嵌入空间中彼此靠近。这是一个广阔的研究领域,本文无法进一步详述。