redis非关系型数据库详解
Redis:
学习redis和mysql是一样的:
首先要明白,redis在6.0之前是单线程,过后是多线程的(实际好像还是单线程),redis是支持事务的,只是不支持事务回滚
Redis 是以key-value形式存储,和传统的关系型数据库不一样。不一定遵循传统数据库的一些基本要求,比如说,不遵循sql标准,事务,表结构等等,redis严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
redis提供了一堆操作方法【一堆命令操作数据】,我们使用这些方法就可以存入字符串,组织成各种数据结构(string,list,set,map等),使用起来更加方便。
数据结构:String set list zset(有序并且不可重复集合) hash(map)等 redis存储数据都是以字符串的方式进行存放,它只是把最终存储的结果值,以一定结构进行存储
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,它泛指非关系型的数据库。随着互联网2003年之后web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的交友类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
关系型数据库:以关系(由行和列组成的二维表)模型建模的数据库。 有表的就是关系型数据库。
RDBMS: mysql,oracle,SQL server,DB2 ,postgresql等
RBDMS 就是指 关系型数据库
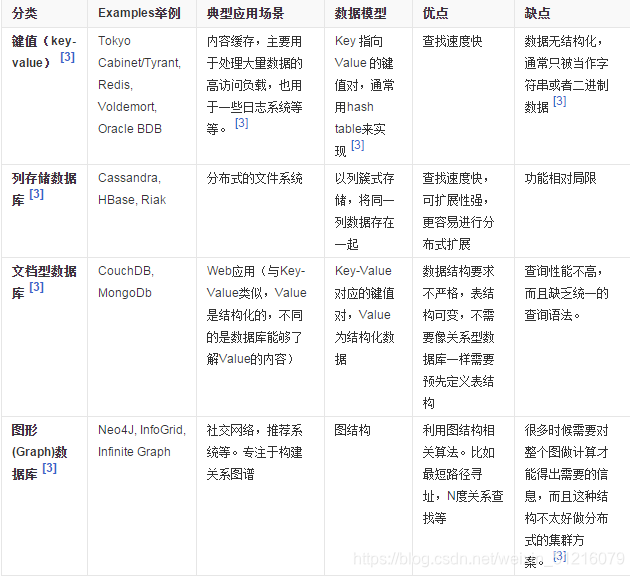
NoSql:非关系型数据库:Redis、MongoDb…
注意:Redis是弥补关系型数据库不足之处,不是用来替代关系型数据库的
关系型数据库缺点:
1.关系型数据库存储数据量是有极限的
2.关系型数据库不支持高并发访问 (这点很重要)
3.关系型数据库对列也是有限制的
数据量大的时候就要考虑集群 分库 分表
非关系型数据库优点:
1.只要内存足够,它可以存储数据量是无限的
2.非关系型数据库它支持高并发访问,
补充特点(优势)
1.数据保存在内存,存取速度快,并发能力强
2.它支持存储的value类型相对更多,包括string(字符串)、list(列表)、set(集合)、 zset(sorted set --有序集合)和hash(哈希类型 - map)。
3.redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库(如MySQL)起到很好的补充作用。
4.它提供了Java,C/C++,C#,PHP,JavaScript等客户端,使用很方便。
5.Redis支持集群(主从同步)。数据可以主服务器向任意数量从的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。
6.支持持久化,可以将数据保存在硬盘的文件中
7.支持订阅/发布(subscribe/publish)功能 QQ群 - 群发
Redis 是存储在内存和磁盘中,不写sql语句,使用场景 :做缓存
redis存储数据都是以字符串形式进行存储,它只是把存储的值 排列成有一定的格式,支持5种格式 String 、 list(集合)、 set(无序集合)、 hash(key value)、 zset (有序集合,并且不可重复)
点赞 评论 转发这些就只能用redis来做,解决高并发问题
光靠redis 解决不了高并发问题,还要靠集群 、分布式 、队列 等等
Mysql、Memcached和Redis的比较
| mysql | redis | memcached | |
|---|---|---|---|
| 类型 | 关系型 | 非关系型 | 非关系型 |
| 存储位置 | 磁盘 | 磁盘和内存 | 内存 |
| 存储过期 | 不支持 | 支持 | 支持 |
| 读写性能 | 低 | 非常高 | 非常高 |
Redis使用场景:
中央缓存:
经常查询数据,放到读速度很快的空间(内存),以便下次访问减少时间。减轻数据库压力,减少访问时间.而redis就是存放在内存中的。
Hibernte二级缓存
计数器应用:
网站通常需要统计注册用户数,网站总浏览次数等等
新浪微博转发数、点赞数
实时防攻击系统
暴力破解:使用工具不间断尝试各种密码进行登录。防:ip—>num,到达10次以后自动锁定IP,30分钟后解锁
解决方案:
1、存数据库
登录操作的访问量非常大
2、static Map
Map存储空间有限,大批量就不行,并且断电以后数据丢失。
问题:
1、每次查询数据库,查询速度慢,多次写 内存
2、断电会丢失数据,多个节点,不能共用 redis集群,容量可以无限大,可以共享数据、并且支持过期
设定有效期的应用:
vip,红包,当session使用,存储登录对象, 设定一个数据,到一定的时间失效。 自动解锁,购物券 游戏道具(7)
自动去重应用:
Uniq 操作,获取某段时间所有数据排重值 这个使用 Redis 的 set 数据结构最合适了,只需要不断地将数据往 set 中扔就行了,set 意为 集合,所以会自动排重。
队列:
构建队列系统 使用 list 可以构建队列系统,使用 sorted set 甚至可以构建有优先级的队列系统。
秒杀:可以把名额放到内存队列(redis),内存就能处理高并发访问。
消息订阅系统:
Pub/Sub 构建实时消息系统 Redis 的 Pub/Sub 系统可以构建实时的消息系统,比如很多用 Pub/Sub 构建的实时聊天系统 的例子。比如QQ群消息
排行榜:
zset有排序功能 ,可以实现各种排行榜
安装redis
redis.windows.conf redis核心配置文件
redis-server.exe 启动redis服务核心文件
redis-cli.exe 启动客户端
默认端口 为 :6379
连接redis服务命令:redis -cli.exe -h 127.0.0.1 -p 6379
可以简写 redis -cli.exe 默认连接本机服务,并且端口号6379
支持的五种数据格式:
String操作命令:
set key value 一次性设置一个key值和value值
get key 通过key值获取value值
mset key1 value1 key2 value2…一次性设置多个key值和value
mget key1 key2 key3 …通过多个key值获取对应的value值
redis对key的操作命令:
keys * 把当前库所有的key值展示出来,
expire key seconds 设置指定的key值有效期为seconds秒
ttl key 查询指定的key值,存活有效期,值>0 存活多少秒 值=-2没有该值,不存在 ,值=-1 永久存活
incr key 自增1(前提:你的值必须是数字型字符串)
decr key 自减1(前提:你的值必须是数字型字符串)
incrby key number 自增number (前提:你的值必须是数字型字符串)
decrby key number 自减number(前提:你的值必须是数字型字符串)
del key1 key2 key3 …删除指定的键值对
redis对库的操作
redis默认有16个库 索引 :0-15
选择指定的库 :select index
清空当前库: flushdb (慎用)
清空所有的库:flushall(慎用)
redis 对list的操作命令:
栈:FiLO(先进后出),控制同一边进出。
队列:FIFO(先进先出),控制从一边进,另一边出。
list集合可以看成是一个左右排列的队列(列表)
lpush key value //将一个或多个值 value 插入到列表 key 的表头(最左边)
rpush key value //将一个或多个值 value 插入到列表 key 的表尾(最右边)
lpop key //移除并返回列表 key 的头(最左边)元素。
rpop key //移除并返回列表 key 的尾(最右边)元素。
一个key 对应多个value值
lpush key value1 value2 value3 …向左添加数据
rpush key value1 value2 value3 …向右添加数据
lindex key index 根据指定的索引查询集合中的数据
lrange key begin end 查询指定范围的集合数据
lrange key 0 -1查询集合中所有的数据
lrem key number value 删除 number 大于0从左向右删除,number个value值
number小于0 从右向左删除number个value值
number等于0 删除所有的value值
lpop key 移除并返回列表 key 的头 (最左边) 元素
rpop key 移除并返回列表 key 的尾 (最右边) 元素
redis 对set的操作命令:
set 无序 去重
sadd key value1 value2 value3… 添加值
smembers key 查询所有的值
srem key value1 value2 …删除值
redis 对hash的操作命令:
hash类型类似于php的数组
hset key name value//添加一个name=>value键值对到key这个hash类型
hget key name //获取hash类型的name键对应的值
hmset key name1 key1 name2 key2 //批量添加name=>value键值对到key这个hash类型
hmget key name1 name2//批量获取hash类型的键对应的值
hkeys //返回哈希表 key 中的所有键
hvals //返回哈希表 key 中的所有值
hgetall //返回哈希表 key 中,所有的键和值
我们将user:1(name:zhangsan,age:18,sex:nv)的信息保存在hash表.
redis对zset的操作命令:
有序集合
zadd key value key2 value
redis设置密码:
核心配置文件里面搜索requirepass 默认注释的,填上密码即可
启动服务要根据配置文件来
登陆autu 密码
java操作数据库:
创建普通java项目 引入 jar包
IDEA Ctrl + P 查看需要哪些参数信息
public class jedisTest {
@Test
public void testName(){
//设置Ip
String host="127.0.0.1";
//设置端口号
int port = 6379;
//超时时间
int timeout =10000;
//创建jedis客户端
Jedis jedis = new Jedis(host,port,timeout);
//有密码的时候输入
//jedis.auth("123456");
//设置多个key value
jedis.mset("name", "空灵", "age", "25");
//通过key获取value值
List<String> values = jedis.mget("name", "age");
for (String value : values) {
System.out.println(value);
}
//关闭资源
jedis.close();
}
}
连接池操作:
//连接池
@Test
public void poll(){
JedisPoolConfig config = new JedisPoolConfig();
//设置最大连接数量
config.setMaxTotal(10);
//设置最小连接
config.setMinIdle(2);
//创建连接池,有密码的时候就加上 总共有5个参数,
//1 配置参数、连接地址、端口号、超时时间、密码
JedisPool jedisPool = new JedisPool(config, "127.0.0.1", 6379, 2000);
//获取连接对象
Jedis jedis = jedisPool.getResource();
//设置多个key value
jedis.mset("name","李东来","age","26","sex","1");
//根据KEY取值
List<String> values = jedis.mget("name", "age", "sex");
//遍历
for (String value : values) {
//输出values值
System.out.println(value);
}
//关闭资源
jedis.close();
}
连接池属于重量级资源 ,不要关闭
//jedis获取连接池对象工具类
public enum JedisUtil {
Instance;
private static JedisPool jedisPool;
static {
try {
JedisPoolConfig config = new JedisPoolConfig();
//设置最大连接数量
config.setMaxTotal(10);
//设置最小连接
config.setMinIdle(2);
//创建连接池
jedisPool = new JedisPool(config, "127.0.0.1", 6379,
2000);
} catch (Exception e) {
e.printStackTrace();
System.out.println("创建连接失败");
}
}
//获得连接池对象的方法
public Jedis getResource() {
return jedisPool.getResource();
}
//设置key value
public void setKeyValue(String key, String value) {
Jedis jedis = null;
try {
jedis = getResource();
jedis.set(key, value);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (jedis != null) {
//关闭资源
jedis.close();
}
}
}
//通过key 取value
public String get(String key) {
Jedis jedis = null;
try {
jedis = getResource();
return jedis.get(key);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (jedis != null) {
//关闭资源
jedis.close();
}
}
return null;
}
}
Redis持久化配置(重点)
1.1. 配置文件中常见配置
bind logfile lognotice save oppenonly
1.2. 简介

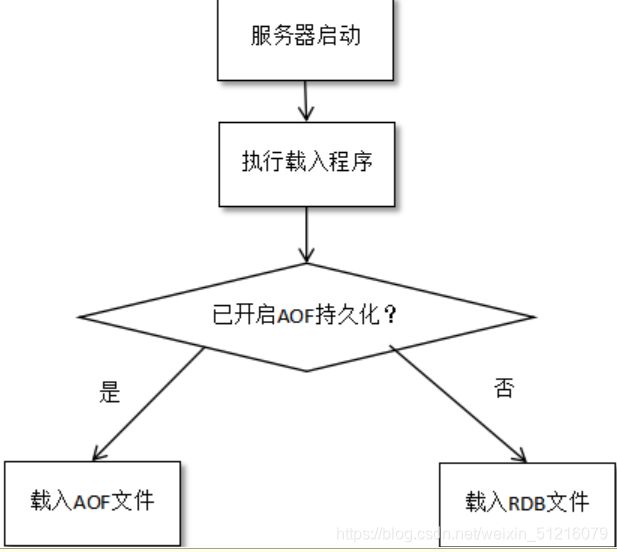
Redis 提供了两种不同级别的持久化方式:RDB和AOF,可以通过修改redis.conf来进行配置.
1.3. RDB模式
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照,默认开启该模式.
如何关闭 rdb 模式:
save “”
# save 900 1 //至少在900秒的时间段内至少有一次改变存储同步一次
# save xxx
# save 60 10000
1.4. AOF追加模式
AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集,默认关闭该模式。
如何开启aof模式:
appendonly yes //yes 开启,no 关闭
# appendfsync always //每次有新命令时就执行一次fsync
#这里我们启用 everysec
appendfsync everysec //每秒 fsync 一次
# appendfsync no //从不fsync(交给操作系统来处理,可能很久才执行一次fsync)
其它的参数请大家看redis.conf配置文件详解
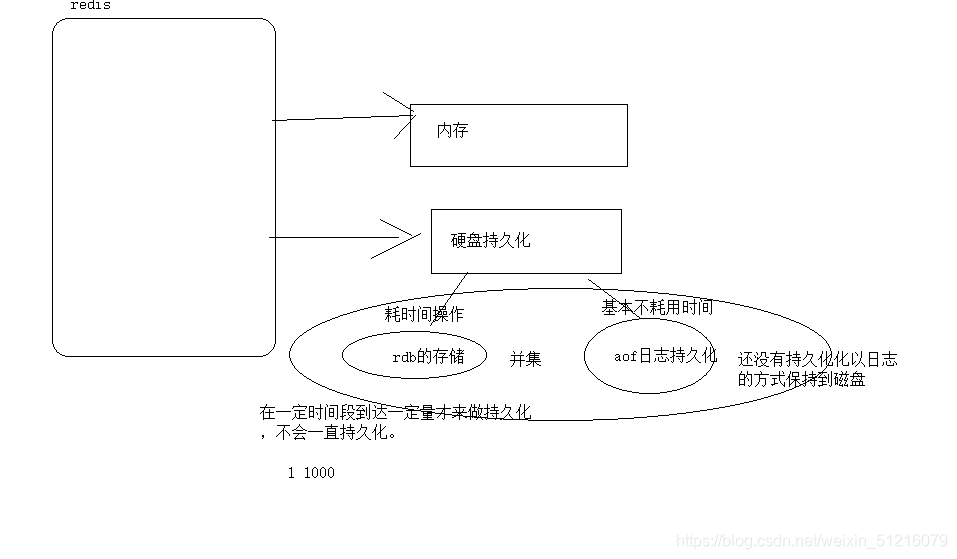
redis是怎么保存数据?
redis为了考虑效率,保存数据在内存中.并且考虑数据安全性,还做数据持久化,如果满足保存策略,就会把内存的数据保存到数据rdb文件,还来不及保存那部分数据存放到aof更新日志中。在加载时,把两个数据做一个并集
淘汰策略:
为什么要淘汰数据
淘汰一些数据,达到redis数据都是有效的,节约内存资源。选择合适的淘汰策略进行淘汰。
怎么淘汰
淘汰一些数据,达到redis数据都是有效的。选择合适的淘汰策略进行淘汰。
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从所有数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从所有数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
redis 确定驱逐某个键值对后,会删除这个数据并,并将这个数据变更消息发布到本地(AOF 持久化)和从机(主从连接)。
Redis存放数据永远过期。 allkeys-lru
volatile-lru,volatile-ttl随意就OK
并且对于缓存而已,就算错误删除也没有关系,如果不是缓慢,集群。
回顾mysql连表查询:
1 外联接
1.1左外连接 只记左外连接就好
select * from A a left join B b on a.id =b.aid
多表查询:左表所有数据都会展示出来,右边满足条件的则把数据展示 出来,如果右表不能满足条件,则以null进行填充
1.2右外连接 :和左外连接相反
2 内联接: 多表查询,左表右表同时满足条件的展示出来,不满足条件的全部过滤掉
2.1显示内连接 只记这个
select * from A a [inner] join B b on a .id =a_id
2.2隐式内连接
select * from A a ,B b where a.id=b.a_id
idea打断点:
必须是debug模式运行项目