目标检测 Faster RCNN全面解读复现
Faster RCNN
解读
经过R-CNN和Fast RCNN的积淀,Ross B. Girshick在2016年提出了新的Faster RCNN,在结构上,Faster RCNN已经将特征抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
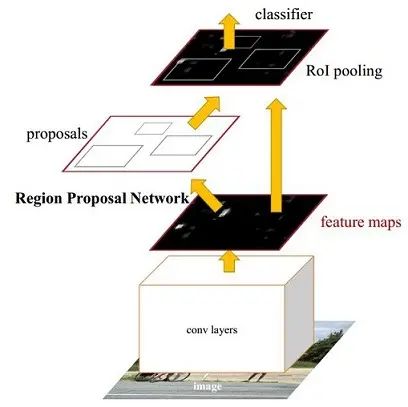
图1 Faster RCNN基本结构(来自原论文)
依作者看来,如图1,Faster RCNN其实可以分为4个主要内容:
- Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
- Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
- Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
所以本文以上述4个内容作为切入点介绍Faster R-CNN网络。
图2展示了python版本中的VGG16模型中的faster_rcnn_test.pt的网络结构,可以清晰的看到该网络对于一副任意大小PxQ的图像:
- 首先缩放至固定大小MxN,然后将MxN图像送入网络;
- 而Conv layers中包含了13个conv层+13个relu层+4个pooling层;
- RPN网络首先经过3x3卷积,再分别生成positive anchors和对应bounding box regression偏移量,然后计算出proposals;
- 而Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。
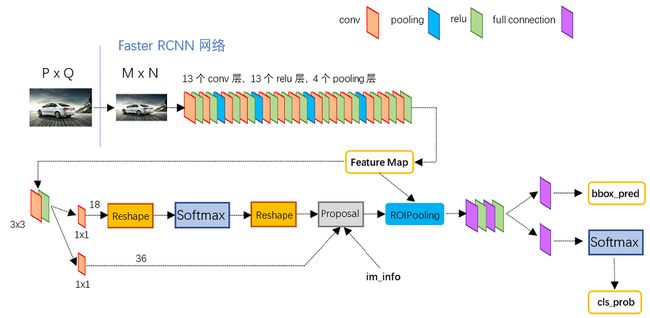
图2 faster_rcnn_test.pt网络结构 (pascal_voc/VGG16/faster_rcnn_alt_opt/faster_rcnn_test.pt)
本文不会讨论任何关于R-CNN家族的历史,分析清楚最新的Faster R-CNN就够了,并不需要追溯到那么久。实话说我也不了解R-CNN,更不关心。有空不如看看新算法。
新出炉的pytorch官方Faster RCNN代码导读:
1 Conv layers
Conv layers包含了conv,pooling,relu三种层。以python版本中的VGG16模型中的faster_rcnn_test.pt的网络结构为例,如图2,Conv layers部分共有13个conv层,13个relu层,4个pooling层。这里有一个非常容易被忽略但是又无比重要的信息,在Conv layers中:
- 所有的conv层都是:kernel_size=3,pad=1,stride=1
- 所有的pooling层都是:kernel_size=2,pad=0,stride=2
为何重要?在Faster RCNN Conv layers中对所有的卷积都做了扩边处理( pad=1,即填充一圈0),导致原图变为 (M+2)x(N+2)大小,再做3x3卷积后输出MxN 。正是这种设置,导致Conv layers中的conv层不改变输入和输出矩阵大小。如图3:

图3 卷积示意图
类似的是,Conv layers中的pooling层kernel_size=2,stride=2。这样每个经过pooling层的MxN矩阵,都会变为(M/2)x(N/2)大小。综上所述,在整个Conv layers中,conv和relu层不改变输入输出大小,只有pooling层使输出长宽都变为输入的1/2。
那么,一个MxN大小的矩阵经过Conv layers固定变为 ( M / 16 ) x ( N / 16 ) (M/16)x(N/16) (M/16)x(N/16)!这样Conv layers生成的feature map中都可以和原图对应起来。
2 Region Proposal Networks(RPN)
经典的检测方法生成检测框都非常耗时,如OpenCV adaboost使用滑动窗口+图像金字塔生成检测框;或如R-CNN使用SS(Selective Search)方法生成检测框。而Faster RCNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN生成检测框,这也是Faster R-CNN的巨大优势,能极大提升检测框的生成速度。

图4 RPN网络结构
上图4展示了RPN网络的具体结构。可以看到RPN网络实际分为2条线,上面一条通过softmax分类anchors获得positive和negative分类,下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。而最后的Proposal层则负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
2.1 多通道图像卷积基础知识介绍
在介绍RPN前,还要多解释几句基础知识,已经懂的看官老爷跳过就好。
- 对于单通道图像+单卷积核做卷积,第一章中的图3已经展示了;
- 对于多通道图像+多卷积核做卷积,计算方式如下:

图5 多通道卷积计算方式
如图5,输入有3个通道,同时有2个卷积核。对于每个卷积核,先在输入3个通道分别作卷积,再将3个通道结果加起来得到卷积输出。所以对于某个卷积层,无论输入图像有多少个通道,输出图像通道数总是等于卷积核数量!
对多通道图像做1x1卷积,其实就是将输入图像于每个通道乘以卷积系数后加在一起,即相当于把原图像中本来各个独立的通道“联通”在了一起。
2.2 anchors
提到RPN网络,就不能不说anchors。所谓anchors,实际上就是一组由rpn/generate_anchors.py生成的矩形。直接运行作者demo中的generate_anchors.py可以得到以下输出:
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
其中每行的4个值 (x_1, y_1, x_2, y_2) 表矩形左上和右下角点坐标。9个矩形共有3种形状,长宽比为大约为 \text{width:height}\in{1:1, 1:2, 2:1} 三种,如图6。实际上通过anchors就引入了检测中常用到的多尺度方法。

图6 anchors示意图
注:关于上面的anchors size,其实是根据检测图像设置的。在python demo中,会把任意大小的输入图像reshape成800x600(即图2中的M=800,N=600)。再回头来看anchors的大小,anchors中长宽1:2中最大为352x704,长宽2:1中最大736x384,基本是cover了800x600的各个尺度和形状。
那么这9个anchors是做什么的呢?借用Faster RCNN论文中的原图,如图7,遍历Conv layers计算获得的feature maps,为每一个点都配备这9种anchors作为初始的检测框。这样做获得检测框很不准确,不用担心,后面还有2次bounding box regression可以修正检测框位置。
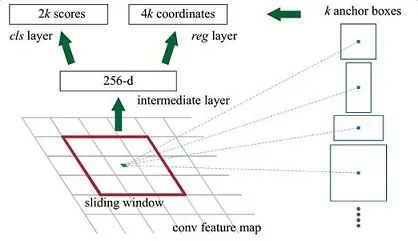
图7
解释一下上面这张图的数字。
- 在原文中使用的是ZF model中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-dimensions
- 在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息(猜测这样做也许更鲁棒?反正我没测试),同时256-d不变(如图4和图7中的红框)
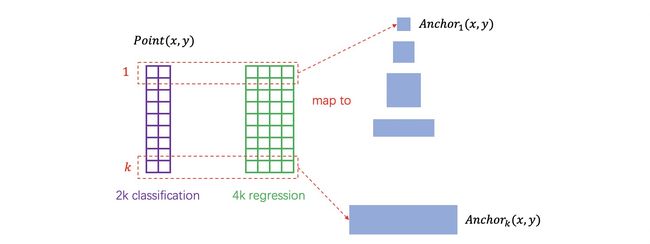
- 假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分positive和negative,所以每个点由256d feature转化为cls=2•k scores;而每个anchor都有(x, y, w, h)对应4个偏移量,所以reg=4•k coordinates
- 补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练(什么是合适的anchors下文5.1有解释)
注意,在本文讲解中使用的VGG conv5 num_output=512,所以是512d,其他类似。
其实RPN最终就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的positive anchor,哪些是没目标的negative anchor。所以,仅仅是个二分类而已!
那么Anchor一共有多少个?原图800x600,VGG下采样16倍,feature map每个点设置9个Anchor,所以:
ceil ( 800 / 16 ) × ceil ( 600 / 16 ) × 9 = 50 × 38 × 9 = 17100 (1) \text{ceil}(800/16) \times \text{ceil}(600/16) \times 9=50\times38 \times9=17100 \tag{1} ceil(800/16)×ceil(600/16)×9=50×38×9=17100(1)
其中ceil()表示向上取整,是因为VGG输出的feature map size= 50*38。

图8 Gernerate Anchors
2.3 softmax判定positive与negative
一副MxN大小的矩阵送入Faster RCNN网络后,到RPN网络变为(M/16)x(N/16),不妨设 W=M/16,H=N/16。在进入reshape与softmax之前,先做了1x1卷积,如图9:

图9 RPN中判定positive/negative网络结构
该1x1卷积的caffe prototxt定义如下:
layer {
name: "rpn_cls_score"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_cls_score"
convolution_param {
num_output: 18 # 2(positive/negative) * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
}
}
可以看到其num_output=18,也就是经过该卷积的输出图像为WxHx18大小(注意第二章开头提到的卷积计算方式)。这也就刚好对应了feature maps每一个点都有9个anchors,同时每个anchors又有可能是positive和negative,所有这些信息都保存WxHx(9*2)大小的矩阵。为何这样做?后面接softmax分类获得positive anchors,也就相当于初步提取了检测目标候选区域box(一般认为目标在positive anchors中)。
那么为何要在softmax前后都接一个reshape layer?其实只是为了便于softmax分类,至于具体原因这就要从caffe的实现形式说起了。在caffe基本数据结构blob中以如下形式保存数据:
blob=[batch_size, channel,height,width]
对应至上面的保存positive/negative anchors的矩阵,其在caffe blob中的存储形式为[1, 2x9, H, W]。而在softmax分类时需要进行positive/negative二分类,所以reshape layer会将其变为[1, 2, 9xH, W]大小,即单独“腾空”出来一个维度以便softmax分类,之后再reshape回复原状。贴一段caffe softmax_loss_layer.cpp的reshape函数的解释,非常精辟:
"Number of labels must match number of predictions; "
"e.g., if softmax axis == 1 and prediction shape is (N, C, H, W), "
"label count (number of labels) must be N*H*W, "
"with integer values in {0, 1, ..., C-1}.";
综上所述,RPN网络中利用anchors和softmax初步提取出positive anchors作为候选区域(另外也有实现用sigmoid代替softmax,输出[1, 1, 9xH, W]后接sigmoid进行positive/negative二分类,原理一样)。
2.4 bounding box regression原理
如图9所示绿色框为飞机的Ground Truth(GT),红色为提取的positive anchors,即便红色的框被分类器识别为飞机,但是由于红色的框定位不准,这张图相当于没有正确的检测出飞机。所以我们希望采用一种方法对红色的框进行微调,使得positive anchors和GT更加接近。

图10
对于窗口一般使用四维向量 (x, y, w, h) 表示,分别表示窗口的中心点坐标和宽高。对于图 11,红色的框A代表原始的positive Anchors,绿色的框G代表目标的GT,我们的目标是寻找一种关系,使得输入原始的anchor A经过映射得到一个跟真实窗口G更接近的回归窗口G’,即:
- 给定anchor A=(A_{x}, A_{y}, A_{w}, A_{h}) 和 GT=[G_{x}, G_{y}, G_{w}, G_{h}]
- 寻找一种变换**F,**使得:F(A_{x}, A_{y}, A_{w}, A_{h})=(G_{x}^{‘}, G_{y}^{’}, G_{w}^{‘}, G_{h}{'}),其中(G_{x}{’}, G_{y}^{‘}, G_{w}^{’}, G_{h}^{'})≈(G_{x}, G_{y}, G_{w}, G_{h})
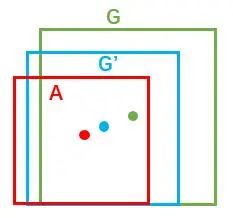
图11
那么经过何种变换F才能从图10中的anchor A变为G’呢? 比较简单的思路就是:
- 先做平移
G x ′ = A w ⋅ d x ( A ) + A x (2) G_x'=A_w\cdot d_x(A) +A_x\tag{2} Gx′=Aw⋅dx(A)+Ax(2)
G y ′ = A h ⋅ d y ( A ) + A y (3) G_y'=A_h\cdot d_y(A) +A_y\tag{3} Gy′=Ah⋅dy(A)+Ay(3)
- 再做缩放
G w ′ = A w ⋅ exp ( d w ( A ) ) (4) G_w'=A_w\cdot \exp(d_w(A)) \tag{4} Gw′=Aw⋅exp(dw(A))(4)
G h ′ = A h ⋅ exp ( d h ( A ) ) (5) G_h'=A_h\cdot \exp(d_h(A))\tag{5} Gh′=Ah⋅exp(dh(A))(5)
观察上面4个公式发现,需要学习的是 d_{x}(A),d_{y}(A),d_{w}(A),d_{h}(A) 这四个变换。当输入的anchor A与GT相差较小时,可以认为这种变换是一种线性变换, 那么就可以用线性回归来建模对窗口进行微调(注意,只有当anchors A和GT比较接近时,才能使用线性回归模型,否则就是复杂的非线性问题了)。
接下来的问题就是如何通过线性回归获得 d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) d_{x}(A),d_{y}(A),d_{w}(A),d_{h}(A) dx(A),dy(A),dw(A),dh(A) 了。线性回归就是给定输入的特征向量X, 学习一组参数W, 使得经过线性回归后的值跟真实值Y非常接近,即 Y=WX 。对于该问题,输入X是cnn feature map,定义为Φ;同时还有训练传入A与GT之间的变换量,即 ( t x , t y , t w , t h ) (t_{x}, t_{y}, t_{w}, t_{h}) (tx,ty,tw,th)。输出是 d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) d_{x}(A),d_{y}(A),d_{w}(A),d_{h}(A) dx(A),dy(A),dw(A),dh(A)四个变换。那么目标函数可以表示为:
d ∗ ( A ) = W ∗ T ⋅ ϕ ( A ) (6) d_*(A)=W_*^T\cdot \phi(A)\tag{6} d∗(A)=W∗T⋅ϕ(A)(6)
其中 \phi(A) 是对应anchor的feature map组成的特征向量, W_* 是需要学习的参数, d_(A) 是得到的预测值(表示 x,y,w,h,也就是每一个变换对应一个上述目标函数)。为了让预测值 d_(A) 与真实值 t_ 差距最小,设计L1损失函数:
Loss = ∑ i N ∣ t ∗ i − W ∗ T ⋅ ϕ ( A i ) ∣ (7) \text{Loss}=\sum_{i}^{N}{|t_*^i-W_*^T\cdot \phi(A^i)|} \tag{7} Loss=i∑N∣t∗i−W∗T⋅ϕ(Ai)∣(7)
函数优化目标为:
W ^ ∗ = argmin W ∗ ∑ i n ∣ t ∗ i − W ∗ T ⋅ ϕ ( A i ) ∣ + λ ∣ ∣ W ∗ ∣ ∣ (8) \hat{W}_*=\text{argmin}_{W_*}\sum_{i}^{n}|t_*^i- W_*^T\cdot \phi(A^i)|+\lambda||W_*|| \tag{8} W^∗=argminW∗i∑n∣t∗i−W∗T⋅ϕ(Ai)∣+λ∣∣W∗∣∣(8)
为了方便描述,这里以L1损失为例介绍,而真实情况中一般使用smooth-L1损失。
需要说明,只有在GT与需要回归框位置比较接近时,才可近似认为上述线性变换成立。
说完原理,对应于Faster RCNN原文,positive anchor与ground truth之间的平移量 (t_x, t_y) 与尺度因子 (t_w, t_h) 如下:
t x = ( x − x a ) / w a t y = ( y − y a ) / h a (9) t_x=(x-x_a)/w_a\ \ \ \ t_y=(y-y_a)/h_a \tag{9} tx=(x−xa)/wa ty=(y−ya)/ha(9)
t w = log ( w / w a ) t h = log ( h / h a ) (10) t_w=\log(w/w_a)\ \ \ \ t_h=\log(h/h_a) \tag{10} tw=log(w/wa) th=log(h/ha)(10)
对于训练bouding box regression网络回归分支,输入是cnn feature Φ,监督信号是Anchor与GT的差距 ( t x , t y , t w , t h ) (t_x, t_y, t_w, t_h) (tx,ty,tw,th),即训练目标是:输入 Φ的情况下使网络输出与监督信号尽可能接近。那么当bouding box regression工作时,再输入Φ时,回归网络分支的输出就是每个Anchor的平移量和变换尺度 ( t x , t y , t w , t h ) (t_x, t_y, t_w, t_h) (tx,ty,tw,th),显然即可用来修正Anchor位置了。
2.5 对proposals进行bounding box regression
在了解bounding box regression后,再回头来看RPN网络第二条线路,如图12。

图12 RPN中的bbox reg
先来看一看上图11中1x1卷积的caffe prototxt定义:
layer {
name: "rpn_bbox_pred"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_bbox_pred"
convolution_param {
num_output: 36 # 4 * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
}
}
可以看到其 num_output=36,即经过该卷积输出图像为WxHx36,在caffe blob存储为[1, 4x9, H, W],这里相当于feature maps每个点都有9个anchors,每个anchors又都有4个用于回归的变换量。
[ d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) ] (11) [d_{x}(A),d_{y}(A),d_{w}(A),d_{h}(A)] \tag{11} [dx(A),dy(A),dw(A),dh(A)](11)
回到图8,VGG输出 50x38x512 的特征,对应设置 50x38xk anchors,而RPN输出:
- 大小为 50x38x2k 的positive/negative softmax分类特征矩阵
- 大小为 50x38x4k 的regression坐标回归特征矩阵
恰好满足RPN完成positive/negative分类+bounding box regression坐标回归.
2.6 Proposal Layer
Proposal Layer负责综合所有 [ d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) ] [d_{x}(A),d_{y}(A),d_{w}(A),d_{h}(A)] [dx(A),dy(A),dw(A),dh(A)] 变换量和positive anchors,计算出精准的proposal,送入后续RoI Pooling Layer。还是先来看看Proposal Layer的caffe prototxt定义:
layer {
name: 'proposal'
type: 'Python'
bottom: 'rpn_cls_prob_reshape'
bottom: 'rpn_bbox_pred'
bottom: 'im_info'
top: 'rois'
python_param {
module: 'rpn.proposal_layer'
layer: 'ProposalLayer'
param_str: "'feat_stride': 16"
}
}
Proposal Layer有3个输入:positive vs negative anchors分类器结果rpn_cls_prob_reshape,对应的bbox reg的 [ d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) ] [d_{x}(A),d_{y}(A),d_{w}(A),d_{h}(A)] [dx(A),dy(A),dw(A),dh(A)] 变换量rpn_bbox_pred,以及im_info;另外还有参数feat_stride=16,这和图4是对应的。
首先解释im_info。对于一副任意大小PxQ图像,传入Faster RCNN前首先reshape到固定MxN,im_info=[M, N, scale_factor]则保存了此次缩放的所有信息。然后经过Conv Layers,经过4次pooling变为 W x H = ( M / 16 ) x ( N / 16 ) WxH=(M/16)x(N/16) WxH=(M/16)x(N/16)大小,其中feature_stride=16则保存了该信息,用于计算anchor偏移量。

图13
Proposal Layer forward(caffe layer的前传函数)按照以下顺序依次处理:
- 生成anchors,利用[d_{x}(A),d_{y}(A),d_{w}(A),d_{h}(A)]对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)
- 按照输入的positive softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的positive anchors
- 限定超出图像边界的positive anchors为图像边界,防止后续roi pooling时proposal超出图像边界(见文章底部QA部分图21)
- 剔除尺寸非常小的positive anchors
- 对剩余的positive anchors进行NMS(nonmaximum suppression)
- Proposal Layer有3个输入:positive和negative anchors分类器结果rpn_cls_prob_reshape,对应的bbox reg的(e.g. 300)结果作为proposal输出
之后输出proposal=[x1, y1, x2, y2],注意,由于在第三步中将anchors映射回原图判断是否超出边界,所以这里输出的proposal是对应MxN输入图像尺度的,这点在后续网络中有用。另外我认为,严格意义上的检测应该到此就结束了,后续部分应该属于识别了。
RPN网络结构就介绍到这里,总结起来就是:
生成anchors -> softmax分类器提取positvie anchors -> bbox reg回归positive anchors -> Proposal Layer生成proposals
3 RoI pooling
而RoI Pooling层则负责收集proposal,并计算出proposal feature maps,送入后续网络。从图2中可以看到Rol pooling层有2个输入:
- 原始的feature maps
- RPN输出的proposal boxes(大小各不相同)
3.1 为何需要RoI Pooling
先来看一个问题:对于传统的CNN(如AlexNet和VGG),当网络训练好后输入的图像尺寸必须是固定值,同时网络输出也是固定大小的vector or matrix。如果输入图像大小不定,这个问题就变得比较麻烦。有2种解决办法:
- 从图像中crop一部分传入网络
- 将图像warp成需要的大小后传入网络

图14 crop与warp破坏图像原有结构信息
两种办法的示意图如图14,可以看到无论采取那种办法都不好,要么crop后破坏了图像的完整结构,要么warp破坏了图像原始形状信息。
回忆RPN网络生成的proposals的方法:对positive anchors进行bounding box regression,那么这样获得的proposals也是大小形状各不相同,即也存在上述问题。所以Faster R-CNN中提出了RoI Pooling解决这个问题。不过RoI Pooling确实是从Spatial Pyramid Pooling发展而来,但是限于篇幅这里略去不讲,有兴趣的读者可以自行查阅相关论文。
3.2 RoI Pooling原理
分析之前先来看看RoI Pooling Layer的caffe prototxt的定义:
layer {
name: "roi_pool5"
type: "ROIPooling"
bottom: "conv5_3"
bottom: "rois"
top: "pool5"
roi_pooling_param {
pooled_w: 7
pooled_h: 7
spatial_scale: 0.0625 # 1/16
}
}
其中有新参数pooled_w和pooled_h,另外一个参数spatial_scale认真阅读的读者肯定已经知道知道用途。RoI Pooling layer forward过程:
- 由于proposal是对应MxN尺度的,所以首先使用spatial_scale参数将其映射回(M/16)x(N/16)大小的feature map尺度;
- 再将每个proposal对应的feature map区域水平分为 pool_w*pool_h 的网格;
- 对网格的每一份都进行max pooling处理。
这样处理后,即使大小不同的proposal输出结果都是 pool_w*pool_h 固定大小,实现了固定长度输出。

图15 proposal示意图
4 Classification
Classification部分利用已经获得的proposal feature maps,通过full connect层与softmax计算每个proposal具体属于那个类别(如人,车,电视等),输出cls_prob概率向量;同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。Classification部分网络结构如图16。
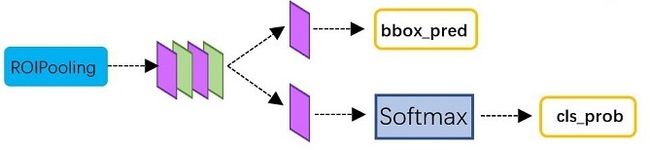
图16 Classification部分网络结构图
从RoI Pooling获取到7x7=49大小的proposal feature maps后,送入后续网络,可以看到做了如下2件事:
- 通过全连接和softmax对proposals进行分类,这实际上已经是识别的范畴了
- 再次对proposals进行bounding box regression,获取更高精度的rect box
这里来看看全连接层InnerProduct layers,简单的示意图如图17,
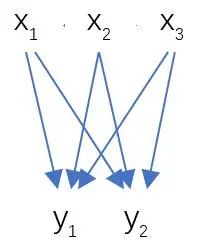
图17 全连接层示意图
其计算公式如下:

其中W和bias B都是预先训练好的,即大小是固定的,当然输入X和输出Y也就是固定大小。所以,这也就印证了之前Roi Pooling的必要性。到这里,我想其他内容已经很容易理解,不在赘述了。
5 Faster RCNN训练
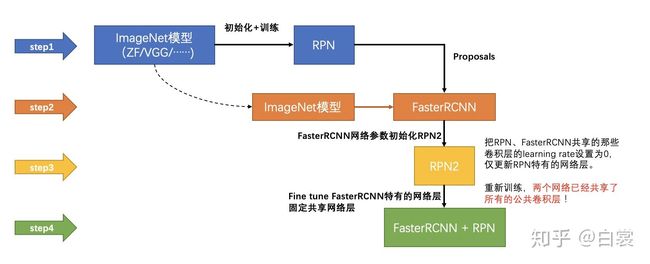
Faster R-CNN的训练,是在已经训练好的model(如VGG_CNN_M_1024,VGG,ZF)的基础上继续进行训练。实际中训练过程分为6个步骤:
- 在已经训练好的model上,训练RPN网络,对应stage1_rpn_train.pt
- 利用步骤1中训练好的RPN网络,收集proposals,对应rpn_test.pt
- 第一次训练Fast RCNN网络,对应stage1_fast_rcnn_train.pt
- 第二训练RPN网络,对应stage2_rpn_train.pt
- 再次利用步骤4中训练好的RPN网络,收集proposals,对应rpn_test.pt
- 第二次训练Fast RCNN网络,对应stage2_fast_rcnn_train.pt
可以看到训练过程类似于一种“迭代”的过程,不过只循环了2次。至于只循环了2次的原因是应为作者提到:“A similar alternating training can be run for more iterations, but we have observed negligible improvements”,即循环更多次没有提升了。接下来本章以上述6个步骤讲解训练过程。
下面是一张训练过程流程图,应该更加清晰:
5.1 训练RPN网络
在该步骤中,首先读取RBG提供的预训练好的model(本文使用VGG),开始迭代训练。来看看stage1_rpn_train.pt网络结构,如图19。

图19 stage1_rpn_train.pt(考虑图片大小,Conv Layers中所有的层都画在一起了,如红圈所示,后续图都如此处理)
与检测网络类似的是,依然使用Conv Layers提取feature maps。整个网络使用的Loss如下:
L ( { p i } , { t i } ) = 1 N cls ∑ i L cls ( p i , p i ∗ ) + λ 1 N reg ∑ i p i ∗ L reg ( t i , t i ∗ ) (12) \text{L}(\{p_i\},\{t_i\})=\frac{1}{N_{\text{cls}}}\sum_{i}\text{L}_\text{cls}(p_i,p_i^*)+\lambda\frac{1}{N_{\text{reg}}}\sum_{i}p_i^*\text{L}_\text{reg}(t_i,t_i^*) \tag{12} L({pi},{ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)(12)
上述公式中 i 表示anchors index, p_{i} 表示positive softmax probability,p_{i}^{}代表对应的GT predict概率(即当第i个anchor与GT间IoU>0.7,认为是该anchor是positive,p_{i}{*}=1;反之IoU<0.3时,认为是该anchor是negative,p_{i}{}=0;至于那些0.3 由于在实际过程中, N cls N_\text{cls} Ncls和 N reg N_\text{reg} Nreg差距过大,用参数λ平衡二者(如 N cls = 256 N_\text{cls}=256 Ncls=256, N reg = 2400 N_\text{reg}=2400 Nreg=2400时设置 $λ=\frac{N_\text{reg}}{N_\text{cls}}\approx10 $,使总的网络Loss计算过程中能够均匀考虑2种Loss。这里比较重要是 \text{L}_\text{reg} 使用的soomth L1 loss,计算公式如下: KaTeX parse error: \tag works only in display equations KaTeX parse error: \tag works only in display equations 了解数学原理后,反过来看图18: 这样,公式与代码就完全对应了。特别需要注意的是,在训练和检测阶段生成和存储anchors的顺序完全一样,这样训练结果才能被用于检测! 在该步骤中,利用之前的RPN网络,获取proposal rois,同时获取positive softmax probability,如图20,然后将获取的信息保存在python pickle文件中。该网络本质上和检测中的RPN网络一样,没有什么区别。 图20 rpn_test.pt 读取之前保存的pickle文件,获取proposals与positive probability。从data层输入网络。然后: 这样就可以训练最后的识别softmax与最终的bounding box regression了。 图21 stage1_fast_rcnn_train.pt 之后的stage2训练都是大同小异,不再赘述了。Faster R-CNN还有一种end-to-end的训练方式,可以一次完成train,有兴趣请自己看作者GitHub吧。 此篇文章初次成文于2016年内部学习分享,再后来经多次修正和完善成为现在的样子。感谢大家一直以来的支持,现在总结常见疑问回答如下: 回顾anchor生成步骤:首先生成9个base anchor,然后通过坐标偏移在 5038 大小的 $\frac{1}{16} $下采样FeatureMap每个点都放上这9个base anchor,就形成了 5038*k 个anhcors。至于这9个base anchor坐标是什么其实并不重要,不同代码实现也许不同。 显然这里面有一部分边缘anchors会超出图像边界,而真实中不会有超出图像的目标,所以会有clip anchor步骤。 图21 clip anchor VGG输出 5038512 的特征,对应设置 5038k 个anchors,而RPN输出 50382k 的分类特征矩阵和 50384k 的坐标回归特征矩阵。 图22 anchor与网络输出如何对应方式 其实在实现过程中,每个点的 2k 个分类特征与 4k 回归特征,与 k 个anchor逐个对应即可,这实际是一种“人为设置的逻辑映射”。当然,也可以不这样设置,但是无论如何都需要保证在训练和测试过程中映射方式必须一致。 由于引入ROI Pooling,从原理上说Faster R-CNN确实能够检测任意大小的图片。但是由于在训练的时候需要使用大batch训练网络,而不同大小输入拼batch在实现的时候代码较为复杂,而且当时以Caffe为代表的第一代深度学习框架也不如Tensorflow和PyTorch灵活,所以作者选择了把输入图片resize到固定大小的800x600。这应该算是历史遗留问题。 另外很多问题,都是属于具体实现问题,真诚的建议读者阅读代码自行理解。 因为faster rcnn发表于2015年,在那个年代只有caffe。当时会把数据送入caffe训练已经是高手了,网络能收敛都已经是高手中的高手。到后来出现tensorflow1.0,再到后面出现pytorch,框架优化做的越来越好,加入越来越多的trick进去,基本不存在大的收敛问题了。所以你看到的文章和现有代码的差异,这应该算是历史问题吧。考虑到和原文的对应问题,我就保留内容以供参考。 我们需要的权重包括 首先来看第一个权重文件 第二个权重文件 顺便训练好的参数我也一并放入了文件夹: 该数据集为 本文使用 根目录就是第一级目录下: 会自动填到 修改 源码对应为: 生成的目录为: 这个我起初是在自己的笔记本上运行的,显卡为3060,显存为 我换到了实验室的电脑, 电脑配置不好的同学可以训练不出来,但是没关系,我把训练好的参数也一并上传了,就在第一份百度盘文件中: 训练结果预测需要用到两个文件,分别是 我们首先需要去 model_path指向训练好的权值文件,在logs文件夹里。 classes_path指向检测类别所对应的txt。 完成修改后就可以运行 本文使用 训练前将标签文件放在 训练前将图片文件放在 在完成数据集的摆放之后,我们需要利用 修改 第一次训练可以仅修改classes_path,classes_path用于指向检测类别所对应的txt。 训练自己的数据集时,可以自己建立一个 例如我们 修改 训练的参数较多,均在train.py中,大家可以在下载库后仔细看注释,其中最重要的部分依然是train.py里的classes_path。 classes_path用于指向检测类别所对应的txt,这个txt和 修改完classes_path后就可以运行 训练结果预测需要用到两个文件,分别是 model_path指向训练好的权值文件,在logs文件夹里。 classes_path指向检测类别所对应的txt。 完成修改后就可以运行 等待一阵子!
5.2 通过训练好的RPN网络收集proposals

5.3 训练Faster RCNN网络

6 QA

复现
Faster R-CNN代码使用说明书(分享在github上)
一、代码的地址
https://github.com/biluko/Faster-RCNN-Pytorch


二、我的配置环境
python == 3.10.6
numpy == 1.23.3
opencv == 4.6.0
pillow == 9.2.0
pycocotools == 2.0.6
pytorch == 1.12.1
scipy == 1.9.3
torchvision == 0.13.1
tqdm == 4.64.1
matplotlib == 3.6.2
hdf5 == 1.12.1
三、参数值文件下载
voc_weights_resnet.pth或者voc_weights_vgg.pth以及主干的网络权重我已经上传了百度云,可以自行下载。voc_weights_resnet.pth,是resnet为主干特征提取网络用到的。voc_weights_vgg.pth,是vgg为主干特征提取网络用到的。

链接:https://pan.baidu.com/s/1IiBMIyw8bF132FQGz79Q6Q
提取码:dpje
四、VOC数据集下载
VOC数据集下载地址如下,里面已经包括了训练集、测试集、验证集(与测试集一样),无需再次划分:VOC07+12的数据集,包括了训练与测试用的数据集。为了训练方便,该数据集中val.txt与test.txt相同。链接:https://pan.baidu.com/s/1STBDRK2MpZfJJ-jRzL6iuA
提取码:vh7m
五、模型训练步骤
(1)训练VOC07+12数据集
1.数据集的准备
VOC格式进行训练,训练前需要下载好VOC07+12的数据集,解压后放在根目录
VOCdevkit文件下面。2.数据集的处理
voc_annotation.py里面的annotation_mode = 2,运行voc_annotation.py生成根目录下的2007_train.txt和2007_val.txt。

3.开始网络训练
train.py的默认参数用于训练VOC数据集,直接运行train.py即可开始训练。6G,但是无法运行,显存不够。Ubuntu18.04,双2080Ti,64G内存,i9处理器,100个batch_size,平均一个花费15分钟左右。
4.预测
frcnn.py和predict.py。frcnn.py里面修改model_path以及classes_path,这两个参数必须要修改。
predict.py进行检测了。运行后输入图片路径即可检测。(2)训练自己的数据集
1.数据集的准备
VOC格式进行训练,训练前需要自己制作好数据集。VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。2.数据集的处理
voc_annotation.py获得训练用的2007_train.txt和2007_val.txt。voc_annotation.py里面的参数。cls_classes.txt,里面写自己所需要区分的类别。
./faster-rcnn-pytorch-master/model_data/cls_classes.txt文件内容为:VOC数据的类别为:aeroplane
bicycle
bird
boat
bottle
bus
car
cat
chair
cow
diningtable
dog
horse
motorbike
person
pottedplant
sheep
sofa
train
tvmonitor
voc_annotation.py中的classes_path,使其对应cls_classes.txt,并运行voc_annotation.py。3.开始网络训练
voc_annotation.py里面的txt一样!训练自己的数据集必须要修改!train.py开始训练了,在训练多个epoch后,权值会生成在logs文件夹中。4.训练结果预测
frcnn.py和predict.py。在frcnn.py里面修改model_path以及classes_path。predict.py进行检测了。运行后输入图片路径即可检测。六、预测步骤
(1)使用预训练权重
1.下载完库后解压,在百度网盘下载
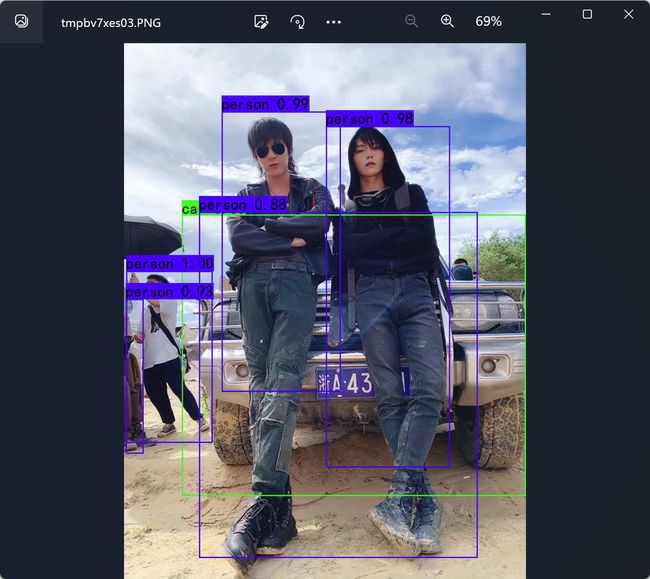
frcnn_weights.pth,放入model_data,运行predict.py,输入:
2.在predict.py里面进行设置可以进行fps测试和video视频检测。

(2)使用自己训练的权重
1.按照训练步骤训练
2.在
frcnn.py文件里面,在如下部分修改model_path和classes_path使其对应训练好的文件;model_path对应logs文件夹下面的权值文件,classes_path是model_path对应分的类。class FRCNN(object):
_defaults = {
#--------------------------------------------------------------------------#
# 使用自己训练好的模型进行预测一定要修改model_path和classes_path!
# model_path指向logs文件夹下的权值文件,classes_path指向model_data下的txt
#
# 训练好后logs文件夹下存在多个权值文件,选择验证集损失较低的即可。
# 验证集损失较低不代表mAP较高,仅代表该权值在验证集上泛化性能较好。
# 如果出现shape不匹配,同时要注意训练时的model_path和classes_path参数的修改
#--------------------------------------------------------------------------#
"model_path" : './faster-rcnn-pytorch-master/model_data/voc_weights_resnet.pth',
"classes_path" : './faster-rcnn-pytorch-master/model_data/voc_classes.txt',
#---------------------------------------------------------------------#
# 网络的主干特征提取网络,resnet50或者vgg
#---------------------------------------------------------------------#
"backbone" : "resnet50",
#---------------------------------------------------------------------#
# 只有得分大于置信度的预测框会被保留下来
#---------------------------------------------------------------------#
"confidence" : 0.5,
#---------------------------------------------------------------------#
# 非极大抑制所用到的nms_iou大小
#---------------------------------------------------------------------#
"nms_iou" : 0.3,
#---------------------------------------------------------------------#
# 用于指定先验框的大小
#---------------------------------------------------------------------#
'anchors_size' : [8, 16, 32],
#-------------------------------#
# 是否使用Cuda
# 没有GPU可以设置成False
#-------------------------------#
"cuda" : True,
}
(3)运行predict.py
(4)在predict.py里面进行设置可以进行fps测试和video视频检测
七、评估步骤
(1)评估VOC07+12的测试集
1.本文使用VOC格式进行评估。
VOC07+12已经划分好了测试集,无需利用voc_annotation.py生成ImageSets文件夹下的txt。2.在
frcnn.py里面修改model_path以及classes_path。model_path指向训练好的权值文件,在logs文件夹里。classes_path指向检测类别所对应的txt3.运行get_map.py即可获得评估结果,评估结果会保存在map_out文件夹中
(2)评估自己的数据集
1.本文使用
VOC格式进行评估。2.如果在训练前已经运行过
voc_annotation.py文件,代码会自动将数据集划分成训练集、验证集和测试集。如果想要修改测试集的比例,可以修改voc_annotation.py文件下的trainval_percent。trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1。train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1。3.利用
voc_annotation.py划分测试集后,前往get_map.py文件修改classes_path,classes_path用于指向检测类别所对应的txt,这个txt和训练时的txt一样。评估自己的数据集必须要修改。4.在
frcnn.py里面修改model_path以及classes_path。model_path指向训练好的权值文件,在logs文件夹里。classes_path指向检测类别所对应的txt。5.运行
get_map.py即可获得评估结果,评估结果会保存在map_out文件夹中。


