【图像分类】【深度学习】【Pytorch版本】Inception-ResNet模型算法详解
【图像分类】【深度学习】【Pytorch版本】Inception-ResNet模型算法详解
文章目录
- 【图像分类】【深度学习】【Pytorch版本】Inception-ResNet模型算法详解
- 前言
- Inception-ResNet讲解
-
- Inception-ResNet-V1
- Inception-ResNet-V2
- 残差模块的缩放(Scaling of the Residuals)
- Inception-ResNet的总体模型结构
- GoogLeNet(Inception-ResNet) Pytorch代码
-
- ## Inception-ResNet-V1
- Inception-ResNet-V2
- 完整代码
-
- Inception-ResNet-V1
- Inception-ResNet-V2
- 总结
前言
GoogLeNet(Inception-ResNet)是由谷歌的Szegedy, Christian等人在《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning【AAAI-2017】》【论文地址】一文中提出的改进模型,受启发于ResNet【参考】在深度网络上较好的表现影响,论文将残差连接加入到Inception结构中形成2个Inception-ResNet版本的网络,它将残差连接取代原本Inception块中池化层部分,并将拼接变成了求和相加,提升了Inception的训练速度。
因为InceptionV4、Inception-Resnet-v1和Inception-Resnet-v2同出自一篇论文,大部分读者对InceptionV4存在误解,认为它是Inception模块与残差学习的结合,其实InceptionV4没有使用残差学习的思想,它基本延续了Inception v2/v3的结构,只有Inception-Resnet-v1和Inception-Resnet-v2才是Inception模块与残差学习的结合产物。
Inception-ResNet讲解
Inception-ResNet的核心思想是将Inception模块和ResNet模块进行融合,以利用它们各自的优点。Inception模块通过并行多个不同大小的卷积核来捕捉多尺度的特征,而ResNet模块通过残差连接解决了深层网络中的梯度消失和梯度爆炸问题,有助于更好地训练深层模型。Inception-ResNet使用了与InceptionV4【参考】类似的Inception模块,并在其中引入了ResNet的残差连接。这样,网络中的每个Inception模块都包含了两个分支:一个是常规的Inception结构,另一个是包含残差连接的Inception结构。这种设计使得模型可以更好地学习特征表示,并且在训练过程中可以更有效地传播梯度。
Inception-ResNet-V1
Inception-ResNet-v1:一种和InceptionV3【参考】具有相同计算损耗的结构。
-
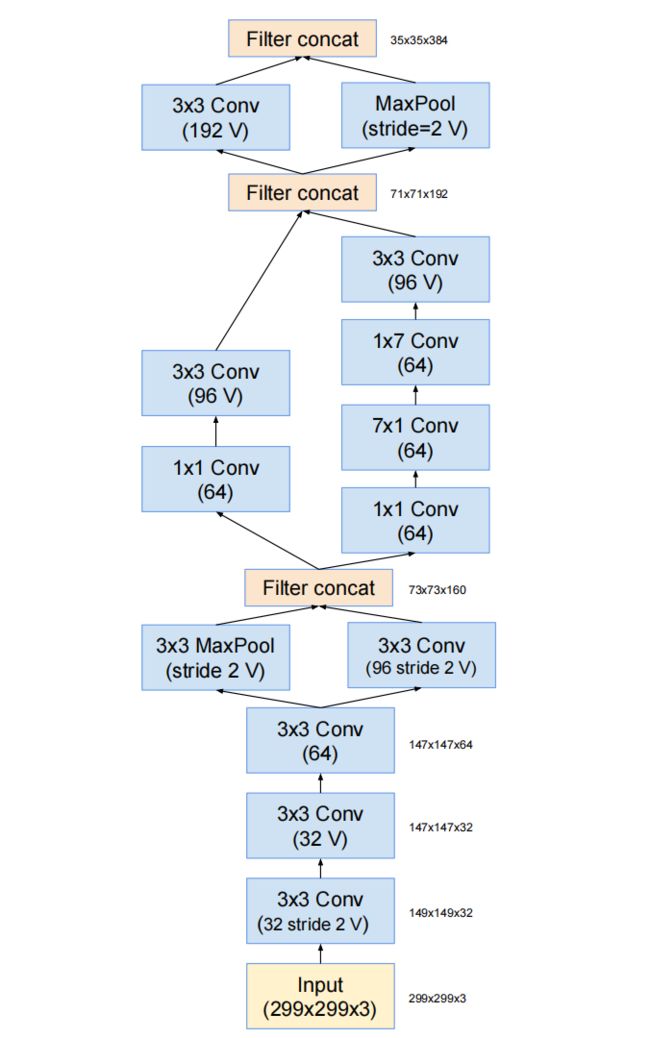
Stem结构: Inception-ResNet-V1的Stem结构类似于此前的InceptionV3网络中Inception结构组之前的网络层。

所有卷积中没有标记为V表示填充方式为"SAME Padding",输入和输出维度一致;标记为V表示填充方式为"VALID Padding",输出维度视具体情况而定。
-
Inception-resnet-A结构: InceptionV4网络中Inception-A结构的变体,1×1卷积的目的是为了保持主分支与shortcut分支的特征图形状保持完全一致。

Inception-resnet结构残差连接代替了Inception中的池化层,并用残差连接相加操作取代了原Inception块中的拼接操作。
-
Inception-resnet-B结构: InceptionV4网络中Inception-B结构的变体,1×1卷积的目的是为了保持主分支与shortcut分支的特征图形状保持完全一致。
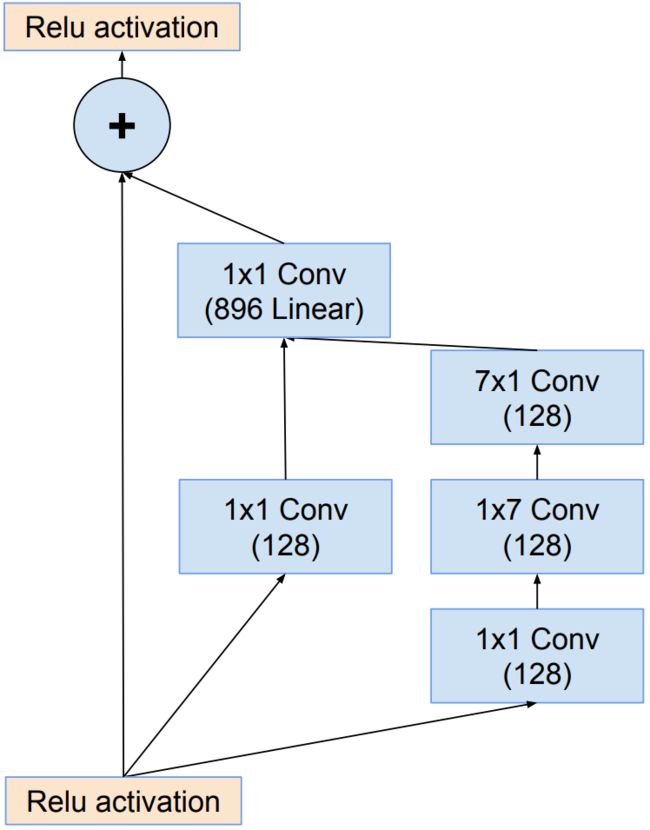
-
Inception-resnet-C结构: InceptionV4网络中Inception-C结构的变体,1×1卷积的目的是为了保持主分支与shortcut分支的特征图形状保持完全一致。
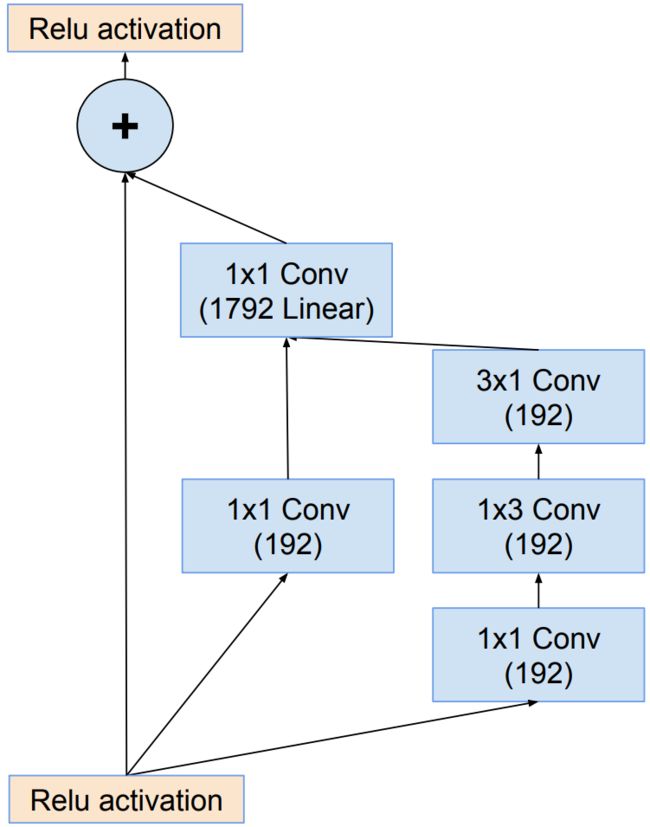
-
Redution-A结构: 与InceptionV4网络中Redution-A结构一致,区别在于卷积核的个数。

k和l表示卷积个数,不同网络结构的redution-A结构k和l是不同的。

-
Redution-B结构:
.
Inception-ResNet-V2
Inception-ResNet-v2:这是一种和InceptionV4具有相同计算损耗的结构,但是训练速度要比纯Inception-v4要快。
Inception-ResNet-v2的整体框架和Inception-ResNet-v1的一致,除了Inception-ResNet-v2的stem结构与Inception V4的相同,其他的的结构Inception-ResNet-v2与Inception-ResNet-v1的类似,只不过卷积的个数Inception-ResNet-v2数量更多。
- Stem结构: Inception-ResNet-v2的stem结构与Inception V4的相同。
- Inception-resnet-A结构: InceptionV4网络中Inception-A结构的变体,1×1卷积的目的是为了保持主分支与shortcut分支的特征图形状保持完全一致。

- Inception-resnet-B结构: InceptionV4网络中Inception-B结构的变体,1×1卷积的目的是为了保持主分支与shortcut分支的特征图形状保持完全一致。
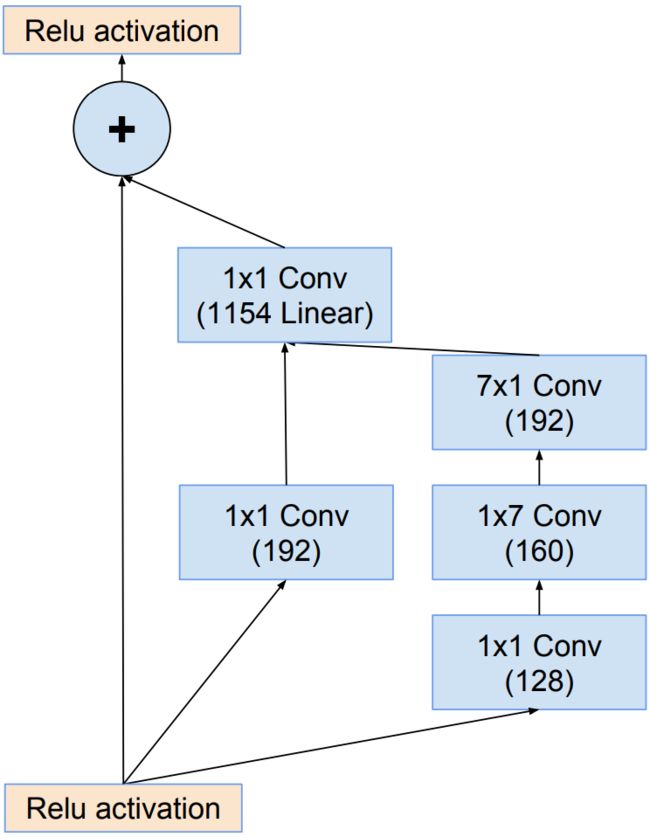
- Inception-resnet-C结构: InceptionV4网络中Inception-C结构的变体,1×1卷积的目的是为了保持主分支与shortcut分支的特征图形状保持完全一致。

- Redution-A结构: 与InceptionV4网络中Redution-A结构一致,区别在于卷积核的个数。
k和l表示卷积个数,不同网络结构的redution-A结构k和l是不同的。
- Redution-B结构:

- Redution-B结构:
残差模块的缩放(Scaling of the Residuals)
如果单个网络层卷积核数量过多(超过1000),残差网络开始出现不稳定,网络会在训练过程早期便会开始失效—经过几万次训练后,平均池化层之前的层开始只输出0。降低学习率、增加额外的BN层都无法避免这种状况。因此在将shortcut分支加到当前残差块的输出之前,对残差块的输出进行放缩能够稳定训练

通常,将残差放缩因子定在0.1到0.3之间去缩放残差块输出。即使缩放并不是完全必须的,它似乎并不会影响最终的准确率,但是放缩能有益于训练的稳定性。
Inception-ResNet的总体模型结构
下图是原论文给出的关于 Inception-ResNet-V1模型结构的详细示意图:

下图是原论文给出的关于 Inception-ResNet-V2模型结构的详细示意图:

读者注意了,原始论文标注的 Inception-ResNet-V2通道数有一部分是错的,写代码时候对应不上。
两个版本的总体结构相同,具体的Stem、Inception块、Redution块则稍微不同。
Inception-ResNet-V1和 Inception-ResNet-V2在图像分类中分为两部分:backbone部分: 主要由 Inception-resnet模块、Stem模块和池化层(汇聚层)组成,分类器部分:由全连接层组成。
GoogLeNet(Inception-ResNet) Pytorch代码
## Inception-ResNet-V1
卷积层组: 卷积层+BN层+激活函数
# 卷积组: Conv2d+BN+ReLU
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
Stem模块: 卷积层组+池化层
# Stem:BasicConv2d+MaxPool2d
class Stem(nn.Module):
def __init__(self, in_channels):
super(Stem, self).__init__()
# conv3x3(32 stride2 valid)
self.conv1 = BasicConv2d(in_channels, 32, kernel_size=3, stride=2)
# conv3*3(32 valid)
self.conv2 = BasicConv2d(32, 32, kernel_size=3)
# conv3*3(64)
self.conv3 = BasicConv2d(32, 64, kernel_size=3, padding=1)
# maxpool3*3(stride2 valid)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2)
# conv1*1(80)
self.conv5 = BasicConv2d(64, 80, kernel_size=1)
# conv3*3(192 valid)
self.conv6 = BasicConv2d(80, 192, kernel_size=1)
# conv3*3(256 stride2 valid)
self.conv7 = BasicConv2d(192, 256, kernel_size=3, stride=2)
def forward(self, x):
x = self.maxpool4(self.conv3(self.conv2(self.conv1(x))))
x = self.conv7(self.conv6(self.conv5(x)))
return x
Inception_ResNet-A模块: 卷积层组+池化层
# Inception_ResNet_A:BasicConv2d+MaxPool2d
class Inception_ResNet_A(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, ch1x1ext, scale=1.0):
super(Inception_ResNet_A, self).__init__()
# 缩减指数
self.scale = scale
# conv1*1(32)
self.branch_0 = BasicConv2d(in_channels, ch1x1, 1)
# conv1*1(32)+conv3*3(32)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, 1),
BasicConv2d(ch3x3red, ch3x3, 3, stride=1, padding=1)
)
# conv1*1(32)+conv3*3(32)+conv3*3(32)
self.branch_2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3redX2, 1),
BasicConv2d(ch3x3redX2, ch3x3X2_1, 3, stride=1, padding=1),
BasicConv2d(ch3x3X2_1, ch3x3X2_2, 3, stride=1, padding=1)
)
# conv1*1(256)
self.conv = BasicConv2d(ch1x1+ch3x3+ch3x3X2_2, ch1x1ext, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
x2 = self.branch_2(x)
# 拼接
x_res = torch.cat((x0, x1, x2), dim=1)
x_res = self.conv(x_res)
return self.relu(x + self.scale * x_res)
Inception_ResNet-B模块: 卷积层组+池化层
# Inception_ResNet_B:BasicConv2d+MaxPool2d
class Inception_ResNet_B(nn.Module):
def __init__(self, in_channels, ch1x1, ch_red, ch_1, ch_2, ch1x1ext, scale=1.0):
super(Inception_ResNet_B, self).__init__()
# 缩减指数
self.scale = scale
# conv1*1(128)
self.branch_0 = BasicConv2d(in_channels, ch1x1, 1)
# conv1*1(128)+conv1*7(128)+conv1*7(128)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch_red, 1),
BasicConv2d(ch_red, ch_1, (1, 7), stride=1, padding=(0, 3)),
BasicConv2d(ch_1, ch_2, (7, 1), stride=1, padding=(3, 0))
)
# conv1*1(896)
self.conv = BasicConv2d(ch1x1+ch_2, ch1x1ext, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
# 拼接
x_res = torch.cat((x0, x1), dim=1)
x_res = self.conv(x_res)
return self.relu(x + self.scale * x_res)
Inception_ResNet-C模块: 卷积层组+池化层
# Inception_ResNet_C:BasicConv2d+MaxPool2d
class Inception_ResNet_C(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, ch1x1ext, scale=1.0, activation=True):
super(Inception_ResNet_C, self).__init__()
# 缩减指数
self.scale = scale
# 是否激活
self.activation = activation
# conv1*1(192)
self.branch_0 = BasicConv2d(in_channels, ch1x1, 1)
# conv1*1(192)+conv1*3(192)+conv3*1(192)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch3x3redX2, 1),
BasicConv2d(ch3x3redX2, ch3x3X2_1, (1, 3), stride=1, padding=(0, 1)),
BasicConv2d(ch3x3X2_1, ch3x3X2_2, (3, 1), stride=1, padding=(1, 0))
)
# conv1*1(1792)
self.conv = BasicConv2d(ch1x1+ch3x3X2_2, ch1x1ext, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
# 拼接
x_res = torch.cat((x0, x1), dim=1)
x_res = self.conv(x_res)
if self.activation:
return self.relu(x + self.scale * x_res)
return x + self.scale * x_res
redutionA模块: 卷积层组+池化层
# redutionA:BasicConv2d+MaxPool2d
class redutionA(nn.Module):
def __init__(self, in_channels, k, l, m, n):
super(redutionA, self).__init__()
# conv3*3(n stride2 valid)
self.branch1 = nn.Sequential(
BasicConv2d(in_channels, n, kernel_size=3, stride=2),
)
# conv1*1(k)+conv3*3(l)+conv3*3(m stride2 valid)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, k, kernel_size=1),
BasicConv2d(k, l, kernel_size=3, padding=1),
BasicConv2d(l, m, kernel_size=3, stride=2)
)
# maxpool3*3(stride2 valid)
self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
# 拼接
outputs = [branch1, branch2, branch3]
return torch.cat(outputs, 1)
redutionB模块: 卷积层组+池化层
# redutionB:BasicConv2d+MaxPool2d
class redutionB(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3_1, ch3x3_2, ch3x3_3, ch3x3_4):
super(redutionB, self).__init__()
# conv1*1(256)+conv3x3(384 stride2 valid)
self.branch_0 = nn.Sequential(
BasicConv2d(in_channels, ch1x1, 1),
BasicConv2d(ch1x1, ch3x3_1, 3, stride=2, padding=0)
)
# conv1*1(256)+conv3x3(256 stride2 valid)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch1x1, 1),
BasicConv2d(ch1x1, ch3x3_2, 3, stride=2, padding=0),
)
# conv1*1(256)+conv3x3(256)+conv3x3(256 stride2 valid)
self.branch_2 = nn.Sequential(
BasicConv2d(in_channels, ch1x1, 1),
BasicConv2d(ch1x1, ch3x3_3, 3, stride=1, padding=1),
BasicConv2d(ch3x3_3, ch3x3_4, 3, stride=2, padding=0)
)
# maxpool3*3(stride2 valid)
self.branch_3 = nn.MaxPool2d(3, stride=2, padding=0)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
x2 = self.branch_2(x)
x3 = self.branch_3(x)
return torch.cat((x0, x1, x2, x3), dim=1)
Inception-ResNet-V2
Inception-ResNet-V2除了Stem,其他模块在结构上与Inception-ResNet-V1一致。
卷积层组: 卷积层+BN层+激活函数
# 卷积组: Conv2d+BN+ReLU
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
Stem模块: 卷积层组+池化层
# Stem:BasicConv2d+MaxPool2d
class Stem(nn.Module):
def __init__(self, in_channels):
super(Stem, self).__init__()
# conv3*3(32 stride2 valid)
self.conv1 = BasicConv2d(in_channels, 32, kernel_size=3, stride=2)
# conv3*3(32 valid)
self.conv2 = BasicConv2d(32, 32, kernel_size=3)
# conv3*3(64)
self.conv3 = BasicConv2d(32, 64, kernel_size=3, padding=1)
# maxpool3*3(stride2 valid) & conv3*3(96 stride2 valid)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv4 = BasicConv2d(64, 96, kernel_size=3, stride=2)
# conv1*1(64)+conv3*3(96 valid)
self.conv5_1_1 = BasicConv2d(160, 64, kernel_size=1)
self.conv5_1_2 = BasicConv2d(64, 96, kernel_size=3)
# conv1*1(64)+conv7*1(64)+conv1*7(64)+conv3*3(96 valid)
self.conv5_2_1 = BasicConv2d(160, 64, kernel_size=1)
self.conv5_2_2 = BasicConv2d(64, 64, kernel_size=(7, 1), padding=(3, 0))
self.conv5_2_3 = BasicConv2d(64, 64, kernel_size=(1, 7), padding=(0, 3))
self.conv5_2_4 = BasicConv2d(64, 96, kernel_size=3)
# conv3*3(192 valid) & maxpool3*3(stride2 valid)
self.conv6 = BasicConv2d(192, 192, kernel_size=3, stride=2)
self.maxpool6 = nn.MaxPool2d(kernel_size=3, stride=2)
def forward(self, x):
x1_1 = self.maxpool4(self.conv3(self.conv2(self.conv1(x))))
x1_2 = self.conv4(self.conv3(self.conv2(self.conv1(x))))
x1 = torch.cat([x1_1, x1_2], 1)
x2_1 = self.conv5_1_2(self.conv5_1_1(x1))
x2_2 = self.conv5_2_4(self.conv5_2_3(self.conv5_2_2(self.conv5_2_1(x1))))
x2 = torch.cat([x2_1, x2_2], 1)
x3_1 = self.conv6(x2)
x3_2 = self.maxpool6(x2)
x3 = torch.cat([x3_1, x3_2], 1)
return x3
Inception_ResNet-A模块: 卷积层组+池化层
# Inception_ResNet_A:BasicConv2d+MaxPool2d
class Inception_ResNet_A(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, ch1x1ext, scale=1.0):
super(Inception_ResNet_A, self).__init__()
# 缩减指数
self.scale = scale
# conv1*1(32)
self.branch_0 = BasicConv2d(in_channels, ch1x1, 1)
# conv1*1(32)+conv3*3(32)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, 1),
BasicConv2d(ch3x3red, ch3x3, 3, stride=1, padding=1)
)
# conv1*1(32)+conv3*3(48)+conv3*3(64)
self.branch_2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3redX2, 1),
BasicConv2d(ch3x3redX2, ch3x3X2_1, 3, stride=1, padding=1),
BasicConv2d(ch3x3X2_1, ch3x3X2_2, 3, stride=1, padding=1)
)
# conv1*1(384)
self.conv = BasicConv2d(ch1x1+ch3x3+ch3x3X2_2, ch1x1ext, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
x2 = self.branch_2(x)
# 拼接
x_res = torch.cat((x0, x1, x2), dim=1)
x_res = self.conv(x_res)
return self.relu(x + self.scale * x_res)
Inception_ResNet-B模块: 卷积层组+池化层
# Inception_ResNet_B:BasicConv2d+MaxPool2d
class Inception_ResNet_B(nn.Module):
def __init__(self, in_channels, ch1x1, ch_red, ch_1, ch_2, ch1x1ext, scale=1.0):
super(Inception_ResNet_B, self).__init__()
# 缩减指数
self.scale = scale
# conv1*1(192)
self.branch_0 = BasicConv2d(in_channels, ch1x1, 1)
# conv1*1(128)+conv1*7(160)+conv1*7(192)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch_red, 1),
BasicConv2d(ch_red, ch_1, (1, 7), stride=1, padding=(0, 3)),
BasicConv2d(ch_1, ch_2, (7, 1), stride=1, padding=(3, 0))
)
# conv1*1(1154)
self.conv = BasicConv2d(ch1x1+ch_2, ch1x1ext, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
# 拼接
x_res = torch.cat((x0, x1), dim=1)
x_res = self.conv(x_res)
return self.relu(x + self.scale * x_res)
Inception_ResNet-C模块: 卷积层组+池化层
# Inception_ResNet_C:BasicConv2d+MaxPool2d
class Inception_ResNet_C(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, ch1x1ext, scale=1.0, activation=True):
super(Inception_ResNet_C, self).__init__()
# 缩减指数
self.scale = scale
# 是否激活
self.activation = activation
# conv1*1(192)
self.branch_0 = BasicConv2d(in_channels, ch1x1, 1)
# conv1*1(192)+conv1*3(224)+conv3*1(256)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch3x3redX2, 1),
BasicConv2d(ch3x3redX2, ch3x3X2_1, (1, 3), stride=1, padding=(0, 1)),
BasicConv2d(ch3x3X2_1, ch3x3X2_2, (3, 1), stride=1, padding=(1, 0))
)
# conv1*1(2048)
self.conv = BasicConv2d(ch1x1+ch3x3X2_2, ch1x1ext, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
# 拼接
x_res = torch.cat((x0, x1), dim=1)
x_res = self.conv(x_res)
if self.activation:
return self.relu(x + self.scale * x_res)
return x + self.scale * x_res
redutionA模块: 卷积层组+池化层
# redutionA:BasicConv2d+MaxPool2d
class redutionA(nn.Module):
def __init__(self, in_channels, k, l, m, n):
super(redutionA, self).__init__()
# conv3*3(n stride2 valid)
self.branch1 = nn.Sequential(
BasicConv2d(in_channels, n, kernel_size=3, stride=2),
)
# conv1*1(k)+conv3*3(l)+conv3*3(m stride2 valid)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, k, kernel_size=1),
BasicConv2d(k, l, kernel_size=3, padding=1),
BasicConv2d(l, m, kernel_size=3, stride=2)
)
# maxpool3*3(stride2 valid)
self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
# 拼接
outputs = [branch1, branch2, branch3]
return torch.cat(outputs, 1)
redutionB模块: 卷积层组+池化层
# redutionB:BasicConv2d+MaxPool2d
class redutionB(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3_1, ch3x3_2, ch3x3_3, ch3x3_4):
super(redutionB, self).__init__()
# conv1*1(256)+conv3x3(384 stride2 valid)
self.branch_0 = nn.Sequential(
BasicConv2d(in_channels, ch1x1, 1),
BasicConv2d(ch1x1, ch3x3_1, 3, stride=2, padding=0)
)
# conv1*1(256)+conv3x3(288 stride2 valid)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch1x1, 1),
BasicConv2d(ch1x1, ch3x3_2, 3, stride=2, padding=0),
)
# conv1*1(256)+conv3x3(288)+conv3x3(320 stride2 valid)
self.branch_2 = nn.Sequential(
BasicConv2d(in_channels, ch1x1, 1),
BasicConv2d(ch1x1, ch3x3_3, 3, stride=1, padding=1),
BasicConv2d(ch3x3_3, ch3x3_4, 3, stride=2, padding=0)
)
# maxpool3*3(stride2 valid)
self.branch_3 = nn.MaxPool2d(3, stride=2, padding=0)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
x2 = self.branch_2(x)
x3 = self.branch_3(x)
return torch.cat((x0, x1, x2, x3), dim=1)
完整代码
Inception-ResNet的输入图像尺寸是299×299
Inception-ResNet-V1
import torch
import torch.nn as nn
from torchsummary import summary
# 卷积组: Conv2d+BN+ReLU
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
# Stem:BasicConv2d+MaxPool2d
class Stem(nn.Module):
def __init__(self, in_channels):
super(Stem, self).__init__()
# conv3x3(32 stride2 valid)
self.conv1 = BasicConv2d(in_channels, 32, kernel_size=3, stride=2)
# conv3*3(32 valid)
self.conv2 = BasicConv2d(32, 32, kernel_size=3)
# conv3*3(64)
self.conv3 = BasicConv2d(32, 64, kernel_size=3, padding=1)
# maxpool3*3(stride2 valid)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2)
# conv1*1(80)
self.conv5 = BasicConv2d(64, 80, kernel_size=1)
# conv3*3(192 valid)
self.conv6 = BasicConv2d(80, 192, kernel_size=1)
# conv3*3(256 stride2 valid)
self.conv7 = BasicConv2d(192, 256, kernel_size=3, stride=2)
def forward(self, x):
x = self.maxpool4(self.conv3(self.conv2(self.conv1(x))))
x = self.conv7(self.conv6(self.conv5(x)))
return x
# Inception_ResNet_A:BasicConv2d+MaxPool2d
class Inception_ResNet_A(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, ch1x1ext, scale=1.0):
super(Inception_ResNet_A, self).__init__()
# 缩减指数
self.scale = scale
# conv1*1(32)
self.branch_0 = BasicConv2d(in_channels, ch1x1, 1)
# conv1*1(32)+conv3*3(32)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, 1),
BasicConv2d(ch3x3red, ch3x3, 3, stride=1, padding=1)
)
# conv1*1(32)+conv3*3(32)+conv3*3(32)
self.branch_2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3redX2, 1),
BasicConv2d(ch3x3redX2, ch3x3X2_1, 3, stride=1, padding=1),
BasicConv2d(ch3x3X2_1, ch3x3X2_2, 3, stride=1, padding=1)
)
# conv1*1(256)
self.conv = BasicConv2d(ch1x1+ch3x3+ch3x3X2_2, ch1x1ext, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
x2 = self.branch_2(x)
# 拼接
x_res = torch.cat((x0, x1, x2), dim=1)
x_res = self.conv(x_res)
return self.relu(x + self.scale * x_res)
# Inception_ResNet_B:BasicConv2d+MaxPool2d
class Inception_ResNet_B(nn.Module):
def __init__(self, in_channels, ch1x1, ch_red, ch_1, ch_2, ch1x1ext, scale=1.0):
super(Inception_ResNet_B, self).__init__()
# 缩减指数
self.scale = scale
# conv1*1(128)
self.branch_0 = BasicConv2d(in_channels, ch1x1, 1)
# conv1*1(128)+conv1*7(128)+conv1*7(128)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch_red, 1),
BasicConv2d(ch_red, ch_1, (1, 7), stride=1, padding=(0, 3)),
BasicConv2d(ch_1, ch_2, (7, 1), stride=1, padding=(3, 0))
)
# conv1*1(896)
self.conv = BasicConv2d(ch1x1+ch_2, ch1x1ext, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
# 拼接
x_res = torch.cat((x0, x1), dim=1)
x_res = self.conv(x_res)
return self.relu(x + self.scale * x_res)
# Inception_ResNet_C:BasicConv2d+MaxPool2d
class Inception_ResNet_C(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, ch1x1ext, scale=1.0, activation=True):
super(Inception_ResNet_C, self).__init__()
# 缩减指数
self.scale = scale
# 是否激活
self.activation = activation
# conv1*1(192)
self.branch_0 = BasicConv2d(in_channels, ch1x1, 1)
# conv1*1(192)+conv1*3(192)+conv3*1(192)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch3x3redX2, 1),
BasicConv2d(ch3x3redX2, ch3x3X2_1, (1, 3), stride=1, padding=(0, 1)),
BasicConv2d(ch3x3X2_1, ch3x3X2_2, (3, 1), stride=1, padding=(1, 0))
)
# conv1*1(1792)
self.conv = BasicConv2d(ch1x1+ch3x3X2_2, ch1x1ext, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
# 拼接
x_res = torch.cat((x0, x1), dim=1)
x_res = self.conv(x_res)
if self.activation:
return self.relu(x + self.scale * x_res)
return x + self.scale * x_res
# redutionA:BasicConv2d+MaxPool2d
class redutionA(nn.Module):
def __init__(self, in_channels, k, l, m, n):
super(redutionA, self).__init__()
# conv3*3(n stride2 valid)
self.branch1 = nn.Sequential(
BasicConv2d(in_channels, n, kernel_size=3, stride=2),
)
# conv1*1(k)+conv3*3(l)+conv3*3(m stride2 valid)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, k, kernel_size=1),
BasicConv2d(k, l, kernel_size=3, padding=1),
BasicConv2d(l, m, kernel_size=3, stride=2)
)
# maxpool3*3(stride2 valid)
self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
# 拼接
outputs = [branch1, branch2, branch3]
return torch.cat(outputs, 1)
# redutionB:BasicConv2d+MaxPool2d
class redutionB(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3_1, ch3x3_2, ch3x3_3, ch3x3_4):
super(redutionB, self).__init__()
# conv1*1(256)+conv3x3(384 stride2 valid)
self.branch_0 = nn.Sequential(
BasicConv2d(in_channels, ch1x1, 1),
BasicConv2d(ch1x1, ch3x3_1, 3, stride=2, padding=0)
)
# conv1*1(256)+conv3x3(256 stride2 valid)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch1x1, 1),
BasicConv2d(ch1x1, ch3x3_2, 3, stride=2, padding=0),
)
# conv1*1(256)+conv3x3(256)+conv3x3(256 stride2 valid)
self.branch_2 = nn.Sequential(
BasicConv2d(in_channels, ch1x1, 1),
BasicConv2d(ch1x1, ch3x3_3, 3, stride=1, padding=1),
BasicConv2d(ch3x3_3, ch3x3_4, 3, stride=2, padding=0)
)
# maxpool3*3(stride2 valid)
self.branch_3 = nn.MaxPool2d(3, stride=2, padding=0)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
x2 = self.branch_2(x)
x3 = self.branch_3(x)
return torch.cat((x0, x1, x2, x3), dim=1)
class Inception_ResNetv1(nn.Module):
def __init__(self, num_classes = 1000, k=192, l=192, m=256, n=384):
super(Inception_ResNetv1, self).__init__()
blocks = []
blocks.append(Stem(3))
for i in range(5):
blocks.append(Inception_ResNet_A(256,32, 32, 32, 32, 32, 32, 256, 0.17))
blocks.append(redutionA(256, k, l, m, n))
for i in range(10):
blocks.append(Inception_ResNet_B(896, 128, 128, 128, 128, 896, 0.10))
blocks.append(redutionB(896,256, 384, 256, 256, 256))
for i in range(4):
blocks.append(Inception_ResNet_C(1792,192, 192, 192, 192, 1792, 0.20))
blocks.append(Inception_ResNet_C(1792, 192, 192, 192, 192, 1792, activation=False))
self.features = nn.Sequential(*blocks)
self.conv = BasicConv2d(1792, 1536, 1)
self.global_average_pooling = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.8)
self.linear = nn.Linear(1536, num_classes)
def forward(self, x):
x = self.features(x)
x = self.conv(x)
x = self.global_average_pooling(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = self.linear(x)
return x
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Inception_ResNetv1().to(device)
summary(model, input_size=(3, 229, 229))
summary可以打印网络结构和参数,方便查看搭建好的网络结构。
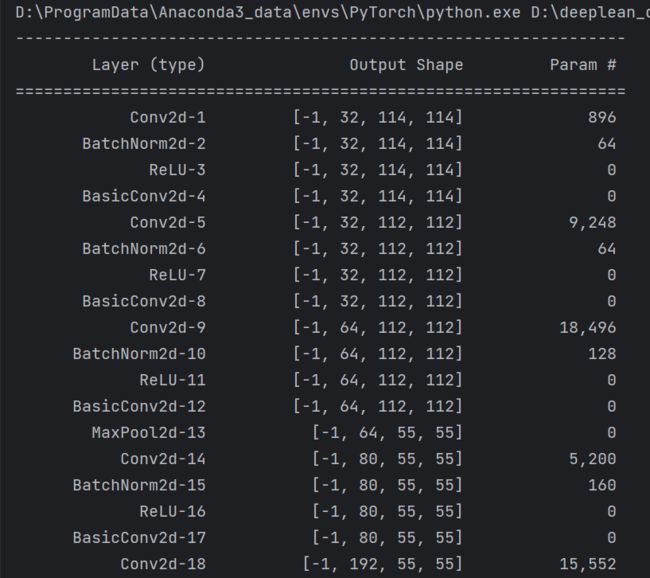
Inception-ResNet-V2
import torch
import torch.nn as nn
from torchsummary import summary
# 卷积组: Conv2d+BN+ReLU
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
# Stem:BasicConv2d+MaxPool2d
class Stem(nn.Module):
def __init__(self, in_channels):
super(Stem, self).__init__()
# conv3*3(32 stride2 valid)
self.conv1 = BasicConv2d(in_channels, 32, kernel_size=3, stride=2)
# conv3*3(32 valid)
self.conv2 = BasicConv2d(32, 32, kernel_size=3)
# conv3*3(64)
self.conv3 = BasicConv2d(32, 64, kernel_size=3, padding=1)
# maxpool3*3(stride2 valid) & conv3*3(96 stride2 valid)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv4 = BasicConv2d(64, 96, kernel_size=3, stride=2)
# conv1*1(64)+conv3*3(96 valid)
self.conv5_1_1 = BasicConv2d(160, 64, kernel_size=1)
self.conv5_1_2 = BasicConv2d(64, 96, kernel_size=3)
# conv1*1(64)+conv7*1(64)+conv1*7(64)+conv3*3(96 valid)
self.conv5_2_1 = BasicConv2d(160, 64, kernel_size=1)
self.conv5_2_2 = BasicConv2d(64, 64, kernel_size=(7, 1), padding=(3, 0))
self.conv5_2_3 = BasicConv2d(64, 64, kernel_size=(1, 7), padding=(0, 3))
self.conv5_2_4 = BasicConv2d(64, 96, kernel_size=3)
# conv3*3(192 valid) & maxpool3*3(stride2 valid)
self.conv6 = BasicConv2d(192, 192, kernel_size=3, stride=2)
self.maxpool6 = nn.MaxPool2d(kernel_size=3, stride=2)
def forward(self, x):
x1_1 = self.maxpool4(self.conv3(self.conv2(self.conv1(x))))
x1_2 = self.conv4(self.conv3(self.conv2(self.conv1(x))))
x1 = torch.cat([x1_1, x1_2], 1)
x2_1 = self.conv5_1_2(self.conv5_1_1(x1))
x2_2 = self.conv5_2_4(self.conv5_2_3(self.conv5_2_2(self.conv5_2_1(x1))))
x2 = torch.cat([x2_1, x2_2], 1)
x3_1 = self.conv6(x2)
x3_2 = self.maxpool6(x2)
x3 = torch.cat([x3_1, x3_2], 1)
return x3
# Inception_ResNet_A:BasicConv2d+MaxPool2d
class Inception_ResNet_A(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, ch1x1ext, scale=1.0):
super(Inception_ResNet_A, self).__init__()
# 缩减指数
self.scale = scale
# conv1*1(32)
self.branch_0 = BasicConv2d(in_channels, ch1x1, 1)
# conv1*1(32)+conv3*3(32)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, 1),
BasicConv2d(ch3x3red, ch3x3, 3, stride=1, padding=1)
)
# conv1*1(32)+conv3*3(48)+conv3*3(64)
self.branch_2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3redX2, 1),
BasicConv2d(ch3x3redX2, ch3x3X2_1, 3, stride=1, padding=1),
BasicConv2d(ch3x3X2_1, ch3x3X2_2, 3, stride=1, padding=1)
)
# conv1*1(384)
self.conv = BasicConv2d(ch1x1+ch3x3+ch3x3X2_2, ch1x1ext, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
x2 = self.branch_2(x)
# 拼接
x_res = torch.cat((x0, x1, x2), dim=1)
x_res = self.conv(x_res)
return self.relu(x + self.scale * x_res)
# Inception_ResNet_B:BasicConv2d+MaxPool2d
class Inception_ResNet_B(nn.Module):
def __init__(self, in_channels, ch1x1, ch_red, ch_1, ch_2, ch1x1ext, scale=1.0):
super(Inception_ResNet_B, self).__init__()
# 缩减指数
self.scale = scale
# conv1*1(192)
self.branch_0 = BasicConv2d(in_channels, ch1x1, 1)
# conv1*1(128)+conv1*7(160)+conv1*7(192)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch_red, 1),
BasicConv2d(ch_red, ch_1, (1, 7), stride=1, padding=(0, 3)),
BasicConv2d(ch_1, ch_2, (7, 1), stride=1, padding=(3, 0))
)
# conv1*1(1154)
self.conv = BasicConv2d(ch1x1+ch_2, ch1x1ext, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
# 拼接
x_res = torch.cat((x0, x1), dim=1)
x_res = self.conv(x_res)
return self.relu(x + self.scale * x_res)
# Inception_ResNet_C:BasicConv2d+MaxPool2d
class Inception_ResNet_C(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, ch1x1ext, scale=1.0, activation=True):
super(Inception_ResNet_C, self).__init__()
# 缩减指数
self.scale = scale
# 是否激活
self.activation = activation
# conv1*1(192)
self.branch_0 = BasicConv2d(in_channels, ch1x1, 1)
# conv1*1(192)+conv1*3(224)+conv3*1(256)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch3x3redX2, 1),
BasicConv2d(ch3x3redX2, ch3x3X2_1, (1, 3), stride=1, padding=(0, 1)),
BasicConv2d(ch3x3X2_1, ch3x3X2_2, (3, 1), stride=1, padding=(1, 0))
)
# conv1*1(2048)
self.conv = BasicConv2d(ch1x1+ch3x3X2_2, ch1x1ext, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
# 拼接
x_res = torch.cat((x0, x1), dim=1)
x_res = self.conv(x_res)
if self.activation:
return self.relu(x + self.scale * x_res)
return x + self.scale * x_res
# redutionA:BasicConv2d+MaxPool2d
class redutionA(nn.Module):
def __init__(self, in_channels, k, l, m, n):
super(redutionA, self).__init__()
# conv3*3(n stride2 valid)
self.branch1 = nn.Sequential(
BasicConv2d(in_channels, n, kernel_size=3, stride=2),
)
# conv1*1(k)+conv3*3(l)+conv3*3(m stride2 valid)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, k, kernel_size=1),
BasicConv2d(k, l, kernel_size=3, padding=1),
BasicConv2d(l, m, kernel_size=3, stride=2)
)
# maxpool3*3(stride2 valid)
self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
# 拼接
outputs = [branch1, branch2, branch3]
return torch.cat(outputs, 1)
# redutionB:BasicConv2d+MaxPool2d
class redutionB(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3_1, ch3x3_2, ch3x3_3, ch3x3_4):
super(redutionB, self).__init__()
# conv1*1(256)+conv3x3(384 stride2 valid)
self.branch_0 = nn.Sequential(
BasicConv2d(in_channels, ch1x1, 1),
BasicConv2d(ch1x1, ch3x3_1, 3, stride=2, padding=0)
)
# conv1*1(256)+conv3x3(288 stride2 valid)
self.branch_1 = nn.Sequential(
BasicConv2d(in_channels, ch1x1, 1),
BasicConv2d(ch1x1, ch3x3_2, 3, stride=2, padding=0),
)
# conv1*1(256)+conv3x3(288)+conv3x3(320 stride2 valid)
self.branch_2 = nn.Sequential(
BasicConv2d(in_channels, ch1x1, 1),
BasicConv2d(ch1x1, ch3x3_3, 3, stride=1, padding=1),
BasicConv2d(ch3x3_3, ch3x3_4, 3, stride=2, padding=0)
)
# maxpool3*3(stride2 valid)
self.branch_3 = nn.MaxPool2d(3, stride=2, padding=0)
def forward(self, x):
x0 = self.branch_0(x)
x1 = self.branch_1(x)
x2 = self.branch_2(x)
x3 = self.branch_3(x)
return torch.cat((x0, x1, x2, x3), dim=1)
class Inception_ResNetv2(nn.Module):
def __init__(self, num_classes = 1000, k=256, l=256, m=384, n=384):
super(Inception_ResNetv2, self).__init__()
blocks = []
blocks.append(Stem(3))
for i in range(5):
blocks.append(Inception_ResNet_A(384,32, 32, 32, 32, 48, 64, 384, 0.17))
blocks.append(redutionA(384, k, l, m, n))
for i in range(10):
blocks.append(Inception_ResNet_B(1152, 192, 128, 160, 192, 1152, 0.10))
blocks.append(redutionB(1152, 256, 384, 288, 288, 320))
for i in range(4):
blocks.append(Inception_ResNet_C(2144,192, 192, 224, 256, 2144, 0.20))
blocks.append(Inception_ResNet_C(2144, 192, 192, 224, 256, 2144, activation=False))
self.features = nn.Sequential(*blocks)
self.conv = BasicConv2d(2144, 1536, 1)
self.global_average_pooling = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.8)
self.linear = nn.Linear(1536, num_classes)
def forward(self, x):
x = self.features(x)
x = self.conv(x)
x = self.global_average_pooling(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = self.linear(x)
return x
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Inception_ResNetv2().to(device)
summary(model, input_size=(3, 229, 229))
summary可以打印网络结构和参数,方便查看搭建好的网络结构。

总结
尽可能简单、详细的介绍了Inception-ResNet将Inception和ResNet结合的作用和过程,讲解了Inception-ResNet模型的结构和pytorch代码。