centos7安装MongoDB,以及mongo的操作
MongoDB一览表
- 一、centos安装MongoDB
- 二、ubuntu的安装
- 三、 mongodb数据库操作
-
-
- mongodb数据操作
-
-
- 新增
- 查询
- 更新,之,如果存在则不创建,如果存在,则忽略,
- 删除
- mongodb高级查询
-
- mongodb逻辑运算符
- mongodb范围运算符
- mongodb使用正则表达式
- mongodb自定义查询
- mongodb排序
- mongodb计数
- mongodb去重
- mongodb索引
-
-
- 四、mongodb数据备份与恢复
- 五、dockers安装mongodb
-
-
-
-
- 搜索与拉取
- 启动
- 进入容器
-
-
-
- 六 mongo安全
-
-
-
-
- 创建admin用户
- MongoDB用户权限
- 创建具有读写权限的用户
- 认证用户并操作
- 查看已存在的用户
- 删除用户
- 重新初始化
-
-
-
- 七、mongodb与python交互
-
-
-
-
- 实例化
- 插入数据
- 查询数据
- 更新数据
- 删除数据
-
-
-
一、centos安装MongoDB
- 创建yum源
vim /etc/yum.repos.d/mongodb-org-3.4.repo
[mongodb-org-3.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.4/x86_64/
gpgcheck=0
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-3.4.asc
- 安装MongoDB
yum -y install mongodb-org
查看mongo安装位置:
whereis mongod
查看修改配置文件 :
vim /etc/mongod.conf
源文件:
# mongod.conf
# for documentation of all options, see:
# http://docs.mongodb.org/manual/reference/configuration-options/
# where to write logging data.
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod.log
# Where and how to store data.
storage:
dbPath: /var/lib/mongo
journal:
enabled: true
# engine:
# mmapv1:
# wiredTiger:
# how the process runs
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod.pid # location of pidfile
# network interfaces
net:
port: 27017
bindIp: 127.0.0.1 # Listen to local interface only, comment to listen on all interfaces.
#security:
#operationProfiling:
#replication:
#sharding:
## Enterprise-Only Options
#auditLog:
#snmp:
----------------------------------------------------------------
- 启动MongoDB
查到mongodb的状态:
systemctl status mongod.service
启动mongodb :
systemctl start mongod.service
设置开机启动:
systemctl enable mongod.service
#查看开机启动
systemctl list-unit-files
或
systemctl list-unit-files | grep mongo
停止mongodb :
systemctl stop mongod.service
- 设置mongodb远程访问并添加安全认证:
vim /etc/mongod.conf
修改 bind_ip:0.0.0.0
中间一定要加空格, 否则解析会报错:
security:
authorization: enabled
或者开启auth:
auth = true
- 可以通过查看日志文件
cat /var/log/mongodb/mongod.log
- 卸载移除mongo
yum erase $(rpm -qa | grep mongodb-org)
- 移除数据库文件和日志文件
rm -r /var/log/mongodb
rm -r /var/lib/mongo
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
二、ubuntu的安装
代码如下(示例):
sudo apt-get install -y mongodb-org
启动服务:sudo service mongod start
停止服务:sudo service mongod stop
重启服务:sudo service mongod restart
查看进程:ps ajx|grep mongod
配置文件的位置:/etc/mongod.conf
默认端口:27017
日志的位置:/var/log/mongodb/mongod.log
三、 mongodb数据库操作
查看当前的数据库:db
查看所有的数据库:show dbs /show databases
切换数据库:use db_name
删除当前的数据库:db.dropDatabase()
mongodb数据操作
新增
插入数据(字段_id存在就报错):db.集合名称.insert(document)
插入数据(字段_id存在就更新):db.集合名称.save(document)
举个栗子:
#插入文档时,如果不指定_id参数,MongoDB会为文档分配一个唯一的ObjectId
db.xianyu.insert({name:"xianyuplus",age:"3"})
#插入文档时,可以指定_id参数
db.xianyu.insert({_id:"10001",name:"xianyuplus",age:"30"})
#更新了上面_id为1001的文档
db.xianyu.save({_id:"10001",name:"xianyuplus",age:"40"})
查询
db.集合名称.find()
db.集合名称.update(<query> ,<update>,{multi: <boolean>})
参数query:查询条件
参数update:更新操作符
参数multi:可选,默认是false,表示只更新找到的第一条记录,值为true表示把满足条件的文档全部更新
# 将name为xianyuplus的值替换为xianyuplus1
db.xianyu.update({name:"xianyuplus"},{name:"xianyuplus1"})
# 将name为xianyuplus的值更新为xianyuplus1
db.xianyu.update({name:"xianyuplus"},{$set:{name:"xianyuplus1"}})
# 更新全部数据的name值为xianyuplus1
db.stu.update({},{$set:{name:"xianyuplus1"}},{multi:true})
注意:!multi update only works with $ operators 即multi只要和$搭配使用时才能起效。
update(条件,操作, upsert=True,multi=False)
upsert : 对于upsert(默认为false):如果upsert=true,如果query找到了符合条件的行,则修改这些行,如果没有找到,则追加一行符合query和obj的行。如果upsert为false,找不到时,不追加。
multi : 如果multi=true,则修改所有符合条件的行,否则只修改第一条符合条件的行,(默认为false)。
更新,之,如果存在则不创建,如果存在,则忽略,
当满足查询条件{"_id" : ObjectId("5dc2cd255ee0a3a2c2c4c384")}的记录存在,则只更新或新增其{ "a" : "e" }属性。如果不存在,将创建一条包含自动生成主键的记录:
{ "_id" : ObjectId("5dc2cd255ee0a3a2c2c4c384"), "a" : "e", "pon" : "a" }
db.getCollection('tt').update(
{"_id" : ObjectId("5dc2cd255ee0a3a2c2c4c384")},
{
"$setOnInsert": { "pon" : "a" },
"$set": { "a" : "e" }
},
{ upsert: true }
)
mongo更新语句使用$setOnInsert、$upsert和$set、$upsert的区别
对于查询到的记录。
使用$set、$upsert 存在则更新,不存在则新增
使用$setOnInsert、$upsert存在则不操作,不存在则新增
删除
# 把name值为xianyuplus的数据全部删掉
db.xianyu.remove({name:"xianyuplus"})
mongodb高级查询
等于:如上述栗子
大于:$gt ( greater than )
大于等于:$gte ( greater than equal )
小于:$lt ( less than )
小于等于:$lte ( less than equal )
不等于:$nt ( not equal )
# 查询age大于20的数据
db.xianyu.find({age:{$gt:20}})
# 查询age大于等于20的数据
db.xianyu.find({age:{$gte:20}})
# 查询age小于20的数据
db.xianyu.find({age:{$lt:20}})
# 查询age小于等于20的数据
db.xianyu.find({age:{$lte:20}})
# 查询age不等于20的数据
db.xianyu.find({age:{$ne:20}})
mongodb逻辑运算符
and:在find条件文档中写入多个字段条件即可
or:使用$or
#查找name为xianyuplus且age为20的数据
db.xianyu.find({name:"xianyuplus",age:20})
#查找name为xianyuplus或age为20的数据
db.xianyu.find({$or:[{name:"xianyuplus"},{age:20}]})
#查找name为xianyuplus或age大于20的数据
db.xianyu.find({$or:[{age:{$gt:20}},{name:"xianyuplus"}]})
#查找age大于等于20或gender为男并且name为xianyuplus的数据
db.xianyu.find({$or:[{gender:"true"},{age:{$gte:18}}],name:"xianyuplus"})
mongodb范围运算符
使用$in与$nin判断是否在某一范围内
#查询年龄为18、28的数据
db.xianyu.find({age:{$in:[18,28]}})
mongodb使用正则表达式
使用//或$regex编写正则表达式
# 查询name以xian开头的数据
db.xianyu.find({name:/^xianyu/})
db.xianyu.find({name:{$regex:'^xianyu'}})
mongodb自定义查询
使用$where自定义查询,这里使用的是js语法
//查询age大于30的数据
db.xianyu.find({
$where:function() {
return this.age>30;}
})
mongodb排序
#先按照性别降序排列再按照年龄升序排列
db.xianyu.find().sort({gender:-1,age:1})
mongodb计数
#查询age为20的数据个数
db.xianyu.find({age:20}).count()
#查询age大于20,且性别为nan的数据个数
db.xianyu.count({age:{$gt:20},gender:true})
mongodb去重
去重:db.集合名称.distinct('去重字段',{条件})
#去除家乡相同,且年龄大于18的数据
db.xianyu.distinct('hometown',{age:{$gt:18}})
mongodb索引
用法:db.集合.ensureIndex({属性:1}),1表示升序, -1表示降序
创建唯一索引:db.集合.ensureIndex({"属性":1},{"unique":true})
创建唯一索引并消除:
db.集合.ensureIndex({"属性":1},{"unique":true,"dropDups":true})
建立联合索引:db.集合.ensureIndex({属性:1,age:1})
查看当前集合的所有索引:db.集合.getIndexes()
删除索引:db.集合.dropIndex('索引名称')
四、mongodb数据备份与恢复
备份:
mongodump -h dbhost -d dbname -o dbdirectory
-h: 服务器地址,也可以指定端口号
-d: 需要备份的数据库名称
-o: 备份的数据存放位置,此目录中存放着备份出来的数据
数据恢复
mongorestore -h dbhost -d dbname --dir dbdirectory
-h: 服务器地址
-d: 需要恢复的数据库实例
--dir: 备份数据所在位置
五、dockers安装mongodb
搜索与拉取
docker pull mongo:latest
启动
docker run -itd --name mongo -v /my/own/datadir:/data/db -p 27017:27017 mongo --auth
(1)--name后面的参数为docker容器名;
(2)-p后面是端口映射,即宿主端口:容器端口;
(3)--auth是否开始鉴权,如果不想开启可以去掉;
默认数据是存在容器系统的/data/db目录下的,如果需要使用自定义的宿主机器目录,可以在启动命令加上参数:
-v /my/own/datadir:/data/db
进入容器
docker exec -it 容器名 bash
docker exec -it some-mongo mongo admin
mongo
指定用户名和密码连接到指定的MongoDB数据库
mongo 127.0.0.1:27017/admin -u user -p password
六 mongo安全
创建admin用户
use admin
db.createUser({ user:'admin',pwd:'123456',roles:[ { role:'userAdminAnyDatabase', db: 'admin'}]});
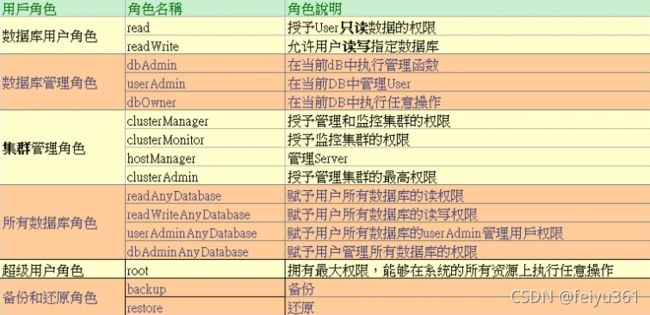
MongoDB用户权限
查看用户 : show users
数据库用户角色:read、readWrite;
数据库管理角色:dbAdmin、dbOwner、userAdmin;
集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager;
备份恢复角色:backup、restore;
所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
超级用户角色:root // 这里还有几个角色间接或直接提供了系统超级用户的访问(dbOwner 、userAdmin、userAdminAnyDatabase)
内部角色:__system
角色说明:
Read:允许用户读取指定数据库
readWrite:允许用户读写指定数据库
dbAdmin:允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile
userAdmin:允许用户向system.users集合写入,可以找指定数据库里创建、删除和管理用户
clusterAdmin:只在admin数据库中可用,赋予用户所有分片和复制集相关函数的管理权限。
readAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的读权限
readWriteAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的读写权限
userAdminAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的userAdmin权限
dbAdminAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的dbAdmin权限。
root:只在admin数据库中可用。超级账号,超级权限
创建具有读写权限的用户
db.auth('admin','123456');
db.createUser({ user:'user',pwd:'123456',roles:[ { role:'readWrite', db: 'testdb'}]});
认证用户并操作
db.auth('user','123456')
use testdb
db.person.insert({name:'Larry',age:18})
db.person.find({})
查看已存在的用户
show users
db.system.users.find()
删除用户
先切换admin库 ,然后进行删除
db.system.users.find()
db.dropUser("jyck")
重新初始化
修改conf,禁止到那个验证,这里略写,然后重启服务
use admin
db.system.users.find()
db.system.users.remove({})
删除所有用户
然后再次创建你需要的库,以及用户
use score
db.createUser({ user:'jyck',pwd:'eHxjxdfdfdddE',roles:[ { role:'readWrite', db: 'score'}]});

七、mongodb与python交互
安装:
pip install pymongo
导入模块:
from pymongo import MongoClient
实例化
from pymongo import MongoClient
class clientMongo:
def __init__(self):
client = MongoClient(host="127.0.0.1", port=27017)
#使用[]括号的形式选择数据库和集合
self.cliention = client["xianyu"]["xianyuplus"]
插入数据
def item_inser_one(self):
ret = self.cliention.insert({"xianyu":"xianyuplus","age":20})
print(ret)
插入多条数据:
def item_insert_many(self):
item_list = [{"name":"xianyuplus{}".format(i)} for i in range(10000)]
items = self.cliention.insert_many(item_list)
查询数据
def item_find_one(self):
ret = self.cliention.find_one({"xianyu":"xianyuplus"})
print(ret)
复制代码
查询多条数据:
def item_find_many(self):
ret = self.cliention.find({"xianyu":"xianyuplus"})
for i in ret:
print(i)
更新数据
更新一条数据:
def item_update_one(self):
self.cliention.update_one({"xianyu":"xianyuplus"},{"$set":{"xianyu":"xianyu"}})
更新全部数据:
def item_update(self):
self.cliention.update_many({"xianyu":"xianyuplus"},{"$set":{"xianyu":"xianyu"}})
删除数据
删除一条数据:
def item_delete_one(self):
self.cliention.delete_one({"xianyu":"xianyuplus"})
删除符合条件的数据:
def item_delete_many(self):
self.cliention.delete_many({"xianyu":"xianyuplus"})