深度学习入门:自建数据集完成花鸟二分类任务
自建数据集完成二分类任务(参考文章)
1 图片预处理
1 .1 统一图片格式
找到的图片需要首先做相同尺寸的裁剪,归一化,否则会因为图片大小不同报错
RuntimeError: stack expects each tensor to be equal size,
but got [3, 667, 406] at entry 0 and [3, 600, 400] at entry 1
pytorch的torchvision.transforms模块提供了许多用于图片变换/增强的函数。
1.1.1 把图片不等比例压缩为固定大小
transforms.Resize((600,600)),
1.1.2 裁剪保留核心区
因为主体要识别的图像一般在中心位置,所以使用CenterCrop,这里设置为(400, 400)
transforms.CenterCrop((400,400)),
1.1.3 处理成统一数据类型
这里统一成torch.float64方便神经网络计算,也可以统一成其他比如uint32等类型
transforms.ConvertImageDtype(torch.float64),
1.1.4 归一化进一步缩小图片范围
对于图片来说0~255的范围有点大,并不利于模型梯度计算,我们应该进行归一化。pytorch当中也提供了归一化的函数torchvision.transforms.Normalize(mean,std),
- 我们可以使用
[0.5,0.5,0.5]的mean,std来把数据归一化至[-1,1] - 也可以手动计算出所有的图片
mean,std来归一化至均值为0,标准差为1的正态分布, - 一些深度学习代码常常使用
mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]的归一化数据,这是在ImageNet的几百万张图片数据计算得出的结果 BN等方法也具有很出色的归一化表现,我们也会使用到
Juliuszh:详解深度学习中的Normalization,BN/LN/WN
Algernon:【基础算法】六问透彻理解BN(Batch Normalization)
我们这里使用简单的[0.5,0.5,0.5]归一化方法,更新cls_dataset,加入transform操作 ,作为图片裁剪的预处理。
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
关于transforms的操作大体分为裁剪/翻转和旋转/图像变换/transform自身操作,具体见余霆嵩:PyTorch 学习笔记(三):transforms的二十二个方法,这里不进行详细展开。
1.2 数据增强
当数据集较小时,可以通过对已有图片做数据增强,利用之前提到的transforms中的函数 ,也可以混合使用来根据已有数据创造新数据
self.data_enhancement = transforms.Compose([
transforms.RandomHorizontalFlip(p=1),
transforms.RandomRotation(30)
])
2 创建自制数据集
2.1 以Dataset类接口为模版
class cls_dataset(Dataset):
def __init__(self) -> None:
# initialization
def __getitem__(self, index):
# return data,label in set
def __len__(self):
# return the length of the dataset
2.2 创建set
2.2.1定义两个空列表data_list和target_list
2.2.2遍历文件夹
2.2.3读取图片对象,对每一个图片对象预处理后,分别将图片对象和对应的标签加入data_list和target_list中
2.2.4将data_list和target_list加入h5df_ile中
import os
from tqdm import tqdm
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import h5py
from torchvision.io import read_image
train_pic_path = 'test-set'
test_pic_path = 'training-set'
def create_h5_file(file_name):
all_type = ['flower', 'bird']
h5df_file = h5py.File(file_name, "w") #file_name指向比如"train.hdf5"这种文件路径,但这句话之前file_name指向路径为空
#图片统一化处理
transform = transforms.Compose([
transforms.Resize((600, 600)),
transforms.CenterCrop((400, 400)),
transforms.ConvertImageDtype(torch.float64),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
]
)
#数据增强
data_list = [] #建立一个保存图片张量的空列表
target_list = [] #建立一个保存图片标签的空列表
#遍历文件夹建立数据集
'''
文件夹组成
| —— train
| | —— flower
| | | —— 图片1
| | —— bird
| | —— | —— 图片2
| —— test
| | —— flower
| | —— bird
'''
dataset_kind = file_name.split('.')[0]
#先判断缺失的文件是训练集还是测试集
if dataset_kind == 'train':
pic_file_name = train_pic_path
else:
pic_file_name = test_pic_path
#再循环遍历文件夹
for file_name_dir, _, files in tqdm(os.walk(pic_file_name)):
target = file_name_dir.split('/')[-1]
if target in all_type:
for file in files:
pic = read_image(os.path.join(file_name_dir, file)) #以张量形式读取图片对象
pic = transform(pic) #预处理图片
pic = np.array(pic).astype(np.float64)
data_list.append(pic) #将pic对象添加到列表里
target_list.append(target.encode()) #将target编码后添加到列表里
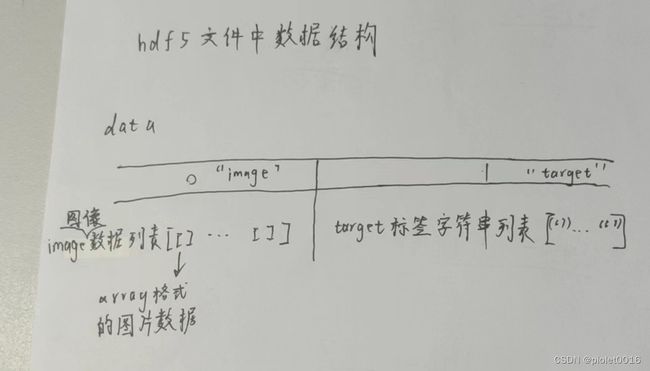
h5df_file.create_dataset("image", data=data_list)
h5df_file.create_dataset("target", data=target_list)
h5df_file.close()
class h5py_dataset(Dataset):
def __init__(self, file_name) -> None:
super().__init__()
self.file_name = file_name #指向文件的路径名
#如果file_name指向的h5文件不存在,就新建一个
if not os.path.exists(file_name):
create_h5_file(file_name)
def __getitem__(self, index):
with h5py.File(self.file_name, 'r') as f:
if f['target'][index].decode() == 'bird': #如果在f文件的target列表中查找到index下标对应的标签是bird
target = torch.tensor(0)
else:
target = torch.tensor(1)
return f['image'][index], target
def __len__(self):
with h5py.File(self.file_name, 'r') as f:
return len(f['target'])
def h5py_loader():
train_file = 'train.hdf5'
test_file = 'test.hdf5'
train_dataset = h5py_dataset(train_file)
test_dataset = h5py_dataset(test_file)
train_data_loader = DataLoader(train_dataset, batch_size=4)
test_data_loader = DataLoader(test_dataset, batch_size=4)
return train_data_loader, test_data_loader
2.3 创建loader
实例化set对象后利用torch.utils.data.DataLoader
3 搭建网络
3.1 网络结构

3.2 参数计算
卷积后,池化后尺寸计算公式:
(图像尺寸-卷积核尺寸 + 2*填充值)/步长+1
(图像尺寸-池化窗尺寸 + 2*填充值)/步长+1
参考文章
3.3 不成文规定
池化参数一般就是(2, 2)
中间的channel数量都是自己设定的,二的次方就行
kernelsize一般3或者5之类的
4 训练
加深对前面数据集组成理解
for _, data in enumerate(train_loader):
if isinstance(data, list):
image = data[0].type(torch.FloatTensor).to(device)
target = data[1].to(device)
elif isinstance(data, dict):
image = data['image'].type(torch.FloatTensor).to(device)
target = data['target'].to(device)
else:
print(type(data))
raise TypeError
for 循环中data的组成来源于构建set时,
h5df_file.create_dataset("image", data=data_list)
h5df_file.create_dataset("target", data=target_list)
写入了h5df文件中两个dataset,但在文件中是以嵌套列表形式保存,其中data[0]等价于引用image这个dataset,data[1]等价于引用target这个集合
5 测试
6 保存模型
改进
投影概率放到网络里面