爬取《悲伤逆流成河》猫眼信息 | 郭敬明五年电影最动人之作
一、我的感受
知道《悲伤逆流成河》上映还是在qq空间看见学弟发了说说,突然想起初中追小四的书,每天看到晚上10点多,昨天看了枪版的《悲伤逆流成河》,整个故事情节几乎和小说一模一样,当然缩减是避免不了的,最大的不一样的是原著里的易遥是跳楼自杀的,而电影里路遥是在众人的"舌枪唇剑"、幸灾乐祸的眼睛下,带着不甘与怨恨跳河自杀的,最后竟然…我就不剧透了,整部剧大概一个小时四十分钟下来全程无尿点,昨天就是枪版的我都看了两遍…(正打算找人去电影院再看一遍),也是看了第一遍,才让我想写这篇充满技术+情感的文章。
二、技术搞事情(爬一爬)
1.猫眼电影短评接口
http://maoyan.com/films/1217236
我们直接访问这个,在web端只能看到最热的10条短评,那怎么获取到所有短评呢?
(1) 访问上面的链接,按下F12,然后点击图片上的图标,把浏览模式(响应式设计模式,火狐快捷键Ctrl+Shift+M)改为手机模式,刷新页面。
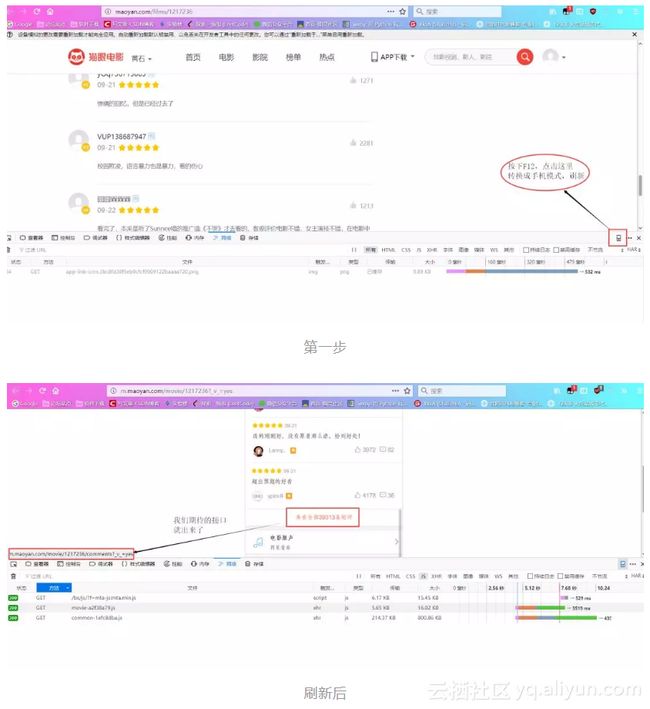
(2)换用谷歌浏览器,F12下进行上面操作,加载完毕后下拉短评,页面继续加载,找到含有offset和startTime的加载条,发现它的Response中包含我们想要的数据,为json格式。
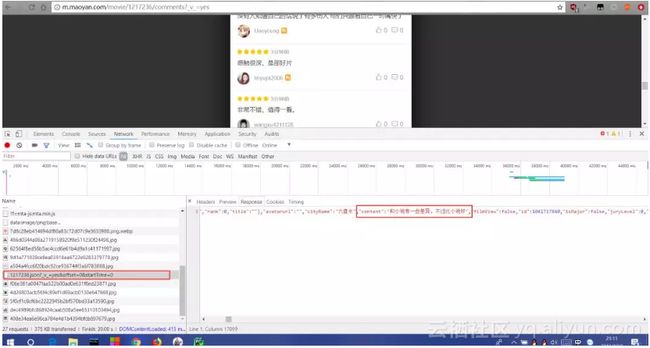
获取到真正的评论接口
2.获取短评
(1)简单分析
通过上面分析
Request URL: http://m.maoyan.com/mmdb/comments/movie/1217236.json?v=yes&offset=0&startTime=0%2021%3A09%3A31
Request Method: GET
下滑了几次次,我发现了下面规律:

测试表
分析上面数据变化,可以大致猜测出:offset表示该接口显示评论开始位置,每个页面15条,比如:15,则显示15-30这中间的15条评论; startTime表示当前评论的时间,固定格式(2018-10-06)。
另外接口最后的%2021%3A09%3A31是不变的。
(2)代码获取
'''
data : 2018.10.06
author : 极简XksA
goal : 爬取猫眼《悲伤逆流成河》影评,词云可视化
'''
# 猫眼电影介绍url
# http://maoyan.com/films/1217236
import requests
from fake_useragent import UserAgent
import json
headers = {
"User-Agent": UserAgent(verify_ssl=False).random,
"Host":"m.maoyan.com",
"Referer":"http://m.maoyan.com/movie/1217236/comments?_v_=yes"
}
# 猫眼电影短评接口
offset = 0
# 电影是2018.9.21上映的
startTime = '2018-09-21'
comment_api = 'http://m.maoyan.com/mmdb/comments/movie/1217236.json?_v_=yes&offset={0}&startTime={1}%2021%3A09%3A31'.format(offset,startTime)
# 发送get请求
response_comment = requests.get(comment_api,headers = headers)
json_comment = response_comment.text
json_comment = json.loads(json_comment)
print(json_comment)
返回数据:

json数据
(3)数据简单介绍

数据介绍表
(4)数据提取
# 获取数据并存储
def get_data(self,json_comment):
json_response = json_comment["cmts"] # 列表
list_info = []
for data in json_response:
cityName = data["cityName"]
content = data["content"]
if "gender" in data:
gender = data["gender"]
else:
gender = 0
nickName = data["nickName"]
userLevel = data["userLevel"]
score = data["score"]
list_one = [self.time,nickName,gender,cityName,userLevel,score,content]
list_info.append(list_one)
self.file_do(list_info)
3.存储数据
# 存储文件
def file_do(list_info):
# 获取文件大小
file_size = os.path.getsize(r'G:\maoyan\maoyan.csv')
if file_size == 0:
# 表头
name = ['评论日期', '评论者昵称', '性别', '所在城市','猫眼等级','评分','评论内容']
# 建立DataFrame对象
file_test = pd.DataFrame(columns=name, data=list_info)
# 数据写入
file_test.to_csv(r'G:\maoyan\maoyan.csv', encoding='gbk', index=False)
else:
with open(r'G:\maoyan\maoyan.csv', 'a+', newline='') as file_test:
# 追加到文件后面
writer = csv.writer(file_test)
# 写入文件
writer.writerows(list_info)
4.封装代码
点击阅读原文获取封装好的爬取猫眼电影数据代码。
猫眼短评的反爬可以说几乎没有,中间断了两次,更改数据,重新运行即可,不封ip。
5.运行结果显示

获取数据显示
三、技术搞事情(数据分析可视化)
1.提取数据
● 代码:def read_csv():
content = ''
# 读取文件内容
with open(r'G:\maoyan\maoyan.csv', 'r', encoding='utf_8_sig', newline='') as file_test:
# 读文件
reader = csv.reader(file_test)
i = 0
for row in reader:
if i != 0:
time.append(row[0])
nickName.append(row[1])
gender.append(row[2])
cityName.append(row[3])
userLevel.append(row[4])
score.append(row[5])
content = content + row[6]
# print(row)
i = i + 1
print('一共有:' + str(i - 1) + '条数据')
return content
● 运行结果:一共有:15195条数据
2.评论者性别分布可视化
● 代码:
# 评论者性别分布可视化
def sex_distribution(gender):
# print(gender)
from pyecharts import Pie
list_num = []
list_num.append(gender.count('0')) # 未知
list_num.append(gender.count('1')) # 男
list_num.append(gender.count('2')) # 女
attr = ["其他","男","女"]
pie = Pie("性别饼图")
pie.add("", attr, list_num, is_label_show=True)
pie.render("H:\PyCoding\spider_maoyan\picture\sex_pie.html")

性别分布
从数据上看,大多数评论者在注册猫时个人信息栏没有标注性别,而且男女中,评分者主要是女生,也好理解,这本来就是一部比较文艺、小众的青春篇,女生可能更为喜爱,而男生可能更加喜欢动作大片。
3.评论者所在城市分布可视化
● 代码:# 评论者所在城市分布可视化
def city_distribution(cityName):
city_list = list(set(cityName))
city_dict = {city_list[i]:0 for i in range(len(city_list))}
for i in range(len(city_list)):
city_dict[city_list[i]] = cityName.count(city_list[i])
# 根据数量(字典的键值)排序
sort_dict = sorted(city_dict.items(), key=lambda d: d[1], reverse=True)
city_name = []
city_num = []
for i in range(len(sort_dict)):
city_name.append(sort_dict[i][0])
city_num.append(sort_dict[i][1])
import random
from pyecharts import Bar
bar = Bar("评论者城市分布")
bar.add("", city_name, city_num, is_label_show=True, is_datazoom_show=True)
bar.render("H:\PyCoding\spider_maoyan\picture\city_bar.html")
# 地图可视化
def render_city(cities):
点击阅读原文查看该函数完整代码
● 运行结果:
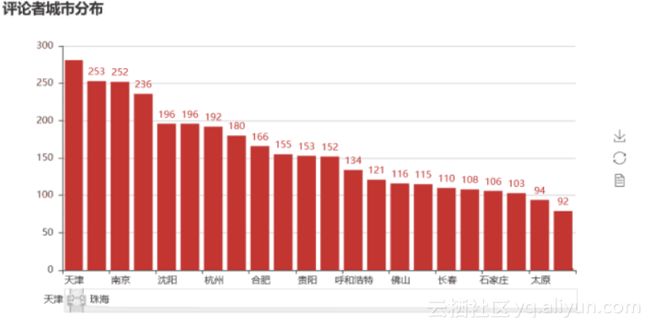
柱状图城市分布

地理位置分布
从中可以看出,大多数观影评分者位于我国东南部分,城市分布上,深圳、成都、北京、武汉、上海占据前五,因为图标里还有很多地级市,所以数据不集中(最大的也只有几百),还是可以看出,这些人大多分布在一二线城市,有消费能力,也愿意在节假日消费,有钱,就是好。
4.每日评论总数可视化分析
● 代码:# 每日评论总数可视化分析
def time_num_visualization(time):
from pyecharts import Line
time_list = list(set(time))
time_dict = {time_list[i]: 0 for i in range(len(time_list))}
time_num = []
for i in range(len(time_list)):
time_dict[time_list[i]] = time.count(time_list[i])
# 根据数量(字典的键值)排序
sort_dict = sorted(time_dict.items(), key=lambda d: d[0], reverse=False)
time_name = []
time_num = []
print(sort_dict)
for i in range(len(sort_dict)):
time_name.append(sort_dict[i][0])
time_num.append(sort_dict[i][1])
line = Line("评论数量日期折线图")
line.add(
"日期-评论数",
time_name,
time_num,
is_fill=True,
area_color="#000",
area_opacity=0.3,
is_smooth=True,
)
line.render("H:\PyCoding\spider_maoyan\picture\c_num_line.html")
● 运行结果:
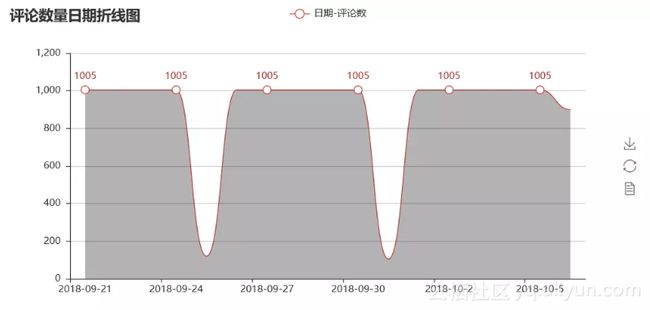
每日评论数折线图
由于数据显示不完整,不能很好的看出评论数量变化,但基本可以看出每天的评论数都为1005,我估计是猫眼限制了每天评论数的显示,或者我获取的时候被限制了,从9.21开始到10.6的16天里,每天新增评论数均达到最大值,可以说明其热度不减。
5.评论者猫眼等级、评分可视化
● 代码:# 评论者猫眼等级、评分可视化
def level_score_visualization(userLevel,score):
from pyecharts import Pie
userLevel_list = list(set(userLevel))
userLevel_num = []
for i in range(len(userLevel_list)):
userLevel_num.append(userLevel.count(userLevel_list[i]))
score_list = list(set(score))
score_num = []
for i in range(len(score_list)):
score_num.append(score.count(score_list[i]))
pie01 = Pie("等级环状饼图", title_pos='center', width=900)
pie01.add(
"等级",
userLevel_list,
userLevel_num,
radius=[40, 75],
label_text_color=None,
is_label_show=True,
legend_orient="vertical",
legend_pos="left",
)
pie01.render("H:\PyCoding\spider_maoyan\picture\level_pie.html")
pie02 = Pie("评分玫瑰饼图", title_pos='center', width=900)
pie02.add(
"评分",
score_list,
score_num,
center=[50, 50],
is_random=True,
radius=[30, 75],
rosetype="area",
is_legend_show=False,
is_label_show=True,
)
pie02.render("H:\PyCoding\spider_maoyan\picture\score_pie.html")
● 运行结果:

从数据可视化结果可以看出,评论者中有47.08%为猫眼二级用户,31.5%为猫眼三级用户,四级及以上用户占11.82%,0级或1级(可以认定为新注册用户)占9.6%,可以看出评分的人中水军是很少的,基本都是猫眼老用户,评分和评论都不会有任何客观色彩。
从评分上看,五星的满分,评分在3星及以上的占93.8%,评分在4星及以上的占87.7%,评分在5星的(满分)占62.82%,可以看出大家对该电影是一致好评。
6.评论者评论内容可视化分析
● 代码:#定义个函数式用于分词
def jiebaclearText(text):
点击阅读原文查看该函数完整代码
# 生成词云图
def make_wordcloud(text1):
text1 = text1.replace("悲伤逆流成河", "")
bg = plt.imread(d + r"/static/znn1.jpg")
# 生成
wc = WordCloud(# FFFAE3
background_color="white", # 设置背景为白色,默认为黑色
width=890, # 设置图片的宽度
height=600, # 设置图片的高度
mask=bg,
# margin=10, # 设置图片的边缘
max_font_size=150, # 显示的最大的字体大小
random_state=50, # 为每个单词返回一个PIL颜色
font_path=d+'/static/simkai.ttf' # 中文处理,用系统自带的字体
).generate_from_text(text1)
# 为图片设置字体
my_font = fm.FontProperties(fname=d+'/static/simkai.ttf')
# 图片背景
bg_color = ImageColorGenerator(bg)
# 开始画图
plt.imshow(wc.recolor(color_func=bg_color))
# 为云图去掉坐标轴
plt.axis("off")
# 画云图,显示
# 保存云图
wc.to_file(d+r"/picture/word_cloud.png")
● 人物图
真的超级喜欢,电影里够手机那一笑,初恋的感觉
● 运行结果:

词云图
整体来看,是一部良心剧,好看,挺好看的,非常好看,超级好看,看哭了,感人,值得一看…几乎100%的好评,主题鲜明,校园暴力,险恶嘴脸,事不关己高高挂起的腐烂心态的显露,展示,很好的凸显了现在浮躁的社会,浮躁的气氛。
四、我想说的话
首先,在我的感受中把我想说的写的差不多了,极力推荐大家去影院看一看,《悲伤逆流成河》这部剧除了反应校园暴力,当代中、高、大学生,乃至成年人心浮气躁外,还有意无意的反应着那个时代友谊的可贵,甚至还有像《我不是药神》一样凸显医药品的短小细节,至少路遥去找那个 小诊所的男医生,那个男医生说的”一次100,10次下来你的这个痛苦就就可以彻底解脱了“,我依然记得路遥迷茫的眼神,还有路遥的妈妈,做的也不是肮脏的生意,就是普通的给那些"腐朽"的人按按摩而已,还有很多情节,路遥妈妈说的”我每次做生意的时候都刻意的把你的内衣收着就是怕那些垃圾知道你“,路遥急着找钱时发现妈妈给她存的报名费,从一元的到一百的,那么厚厚一沓,路遥妈妈知道路遥染上那个病是因为自己后,打自己的那个耳光,齐铭妈妈看见路遥妈妈拉着路遥的惊讶眼神…太多了,最后路遥说出那句”杀死顾森湘的凶手,我不知道是谁,但杀死我的凶手,你们知道是谁“,转身往大海奔去,我不知道是解脱还是傻,只怪我们都胆小怕事,别人做什么我们就跟着做什么。
世间向来不缺乏温暖,只是大家都太过于,真的,太过于想要得到温暖,搞小团体,建’四人帮‘,”送礼“…我觉得不只是小孩在闹着玩玩,很多大人也在闹着”玩“。
无论你是小孩,初中生,高中生,大学生,成年人,工作的,当官的…还是什么,请多多关爱身边的弱势群体,请记得给你的后辈做好榜样,请记得不要“因为需要所以掠夺”,我相信,世间的邪恶虽不能完全消除,但是,我们可以尽量多的发现善良和美。